
结合三帧差分法和混合高斯模型的运动目标检测
2021-06-30 03:47:26余长生秦伦明
上海电力大学学报 2021年3期
余长生, 秦伦明
(上海电力大学 电子与信息工程学院, 上海 200090)
近几年,机器视觉领域发展尤为迅速,而运动目标检测作为机器视觉研究的一个不可分割的重要分支,有着十分广阔的应用前景。文献[1]最早提出了用于背景建模的混合高斯模型(Gaussian Mixture Model,GMM),在运动目标检测领域应用广泛。文献[2]通过结合codebook模型和GMM来确定合适的参数值,改进了GMM的效率。文献[3]将帧间差分图像与视觉背景提取差分图像进行逻辑运算来去除鬼影。文献[4]在文献[1]的基础上,将每帧图像区分为背景区域、背景显露区域和运动物体区域,在快速变换的场景下有较好的检测效果。文献[5]提出了一种非参数模型,通过粒子滤波更新参考数据的位置,可以加快处理速度。
运动目标检测最经典的方法包括帧间差分法、背景差分法和光流法。三帧差分法(Three-frame Difference Method,TFDM)是帧间差分法的一种。该方法相较于其他几种算法有着计算量小、抗干扰能力强等优点,但是该方法目标检测不完整,检测结果存在空洞现象。为了改进检测效果,考虑将TFDM和一些好的建模方法相结合,其中最典型的就是混合高斯背景建模法,从而可以有效地提取出完整目标。本文采用两种算法相结合(TFDM& GMM算法)来改善TFDM固有的检测目标不完整的问题。
1 三帧差分法
TFDM是一种通过对视频图像序列的连续几帧图像做差分运算以获取运动目标轮廓的方法。当监控场景中有目标运动时,相邻帧图像之间会出现较为明显的差别,两帧相减,可求得图像对应位置像素值差的绝对值,判断其是否大于某一阈值,如果该绝对值大于预先设置的阈值,则该像素点属于前景,否则属于背景。
TFDM就是取连续的3帧图像进行2次差分运算,再将2次差分得到的结果进行与运算即可得到运动目标[6]。TFDM的具体计算公式如下。
第k帧和第k-1帧的差分为
Dk(x,y)=
(1)
式中:fk(x,y)——第k帧图像;
fk-1(x,y)——第k-1帧图像;
T——预先设置好的阈值,若差分结果大于T就取1,否则取0。
第k+1帧和第k帧的差分为
Dk+1(x,y)=
(2)
式中:fk+1(x,y)——第k+1帧图像。
将Dk(x,y)和Dk+1(x,y)取与运算即可得到检测结果,即
Mk(x,y)=Dk(x,y)∩Dk+1(x,y)
(3)
2 混合高斯模型
GMM最早是在1999年由SRAUFFER C和GRIMSON W提出的。其算法的核心思想是:在一段时间的视频图像中,对于每一个像素点,用一个混合高斯分布模型来描述其样本灰度值序列的分布情况是合理的。因为每一个像素点的GMM参数都是不同的,所以GMM能准确反映各个像素点不同的分布情况[7]。
2.1 模型定义
图像中每一个像素点的像素值不同,对于每一个像素点,可以用K(一般为3~5)个高斯分布的加权和来模拟该点的像素值[4]。t时刻的像素值xt属于背景的概率p(xt)为
式中:ωi,t——t时刻第i个高斯分布的权重;
η(xt,μi,t,τi,t)——t时刻第i个高斯分布;
μi,t,τi,t——均值和协方差矩阵;
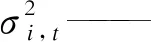
I——像素的颜色值。
2.2 模型学习
算法运行时,每读入一帧样本,都要对样本进行模型匹配,其目的是能更好地对前景和背景进行判定。其匹配的公式为
xt∈[μi,t-1-2.5σi,μi,t-1+2.5σi]
(7)
式中:σi——第i个高斯分布的标准差,1 xt代表t时刻的像素值,如果该像素值满足式(7),则更新该分布的ωi,t;若不满足,则增加一个新的分布来代替原来权值最小的高斯分布。 权值更新公式[8]为 ωi,t=(1-α)ωi,t-1+αMi,t (8) 式中:α——学习速率; Mi,t——第i高斯分布在t时刻的偏置。 用户可以根据不同的应用场景来设定不同的学习速率。对于环境复杂、背景变化快的场景,α的取值可以大一点。此外,当满足式(7)时,Mi,t=1,否则Mi,t=0。 一般而言,背景像素值变化不大。反映时间占有率的指标主要有权重ω与标准差σ。首先需要计算出ω/σ2的值[9-10],然后根据其结果的大小来进行排序,权重大的靠前,再选取大于阈值T前B个高斯模型作为背景模型。其中B的计算公式为 (9) 阈值T一般根据经验选取0.85,但如果场景发生变化,0.85的阈值就不再适用,需要通过实验来选取合适的阈值。得到用来匹配的背景模型后,可将像素值代入式(10)进行匹配,匹配成功的像素则判断为背景,否则判断为前景。 |Xt-μi,t-1|≤2.5σi,t-1 (10) 其中,1 利用TFDM可以快速地检测出运动目标,对环境变化也有较好的适应能力[11];混合高斯模型可以检测到较为完整的运动目标。将两者的优点相结合,可以使检测到的运动目标更加完整,检测效果受噪声的影响较小。具体算法流程如图1所示。 图1 TFDM& GMM算法流程 输入视频序列后,分别采用TFDM和GMM算法将两种算法得到的结果进行逻辑或运算,通过先膨胀后腐蚀[11]的处理方式,可以填充细小的空洞,连接临近物体,就能得到较为完整的运动目标。 本文分别用传统的TFDM和GMM算法以及TFDM& GMM算法对同一视频文件进行测试。其中:图2为第412帧图像采用传统TFDM和GMM算法以及TFDM& GMM算法得出的检测效果图;图3为第575帧图像采用传统TFDM和GMM算法以及TFDM& GMM算法得出的检测效果。图4是对检测结果进行的描边处理效果图。视频流帧速率为10帧/s。本次测试的结果均用二值化[12]表示,白色表示检测到的目标,黑色即为背景,便于观察。 图2 采用3种算法对第412帧图像的检测效果 图2(a)中,传统TFDM能准确地检测到行人,但检测到的运动目标出现断裂,不连续且有空洞现象。图2(b)是采用GMM算法的检测结果,相比于传统的TFDM,GMM算法能较好地获取到完整的运动目标,但8个目标中有3个目标内部存在空洞。图2(c)是采用TFDM& GMM算法得到的结果,可以明显看到,所得到的检测结果相比于传统TFDM有了很大的改进,检测结果右上角的3个运动目标信息完整,轮廓清晰,8个目标内部均无空洞现象。 图3(b)中,能明显观察到图中有许多噪点影响检测效果,这些噪点是外界的噪声所引起的,这也是GMM算法的一个缺点,抗外界的干扰能力较差。而图3(a)采用传统TFDM则可以很好地抑制外界噪声的干扰。由图3(c)可以看到,TFDM& GMM算法既能获取到较为完整的运动目标,且噪点明显减少,故本文算法可以较好地抑制外界噪声的干扰。 图3 采用3种算法对第575帧图像的检测效果 图4是对检测到的运动目标进行的描边处理,主要运用了OpenCV里的findContours函数和cvtColor函数[13]。findContours函数可以从二值图像中找出运动目标的轮廓,再利用cvtColor函数对检测到的轮廓进行颜色转换,从而可以更加清晰地看到运动目标。 图4 描边效果示意 根据测试结果来看,本文算法还存在一些问题,如图3(c)中,除了检测到的运动目标外,还可以看到一条白色的虚影。这是微风吹动其他物体所引起的误检测。可以通过设置动态阈值来减小外部因素对检测效果的影响[14],这是今后的工作重点和研究方向。 本文提出了一种将TFDM与GMM相结合的算法。该算法将TFDM和GMM算法得到的结果进行或运算,最后通过形态学处理即可得到较为完整的运动目标。将本文算法与单独使用其中一种方法得到的检测结果进行了对比,结果表明,相较于单独使用两种算法,本文算法的检测效果好,优化了检测目标不完整的问题以及检测目标出现空洞的现象,同时也减少了噪声的干扰。2.3 前景提取
3 混合高斯模型结合三帧差分法
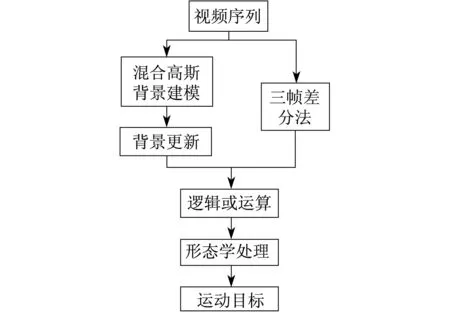
4 实验结果及分析



5 结 语
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30汽车工程师(2021年12期)2022-01-17 02:29:54数字通信世界(2021年3期)2021-04-09 02:05:00当代陕西(2020年14期)2021-01-08 09:30:42湖北理工学院学报(2020年4期)2020-08-22 06:43:26红领巾·萌芽(2019年8期)2019-08-27 15:30:15计算机应用与软件(2017年4期)2017-04-24 10:39:07贵州师范学院学报(2016年4期)2016-12-01 03:54:07CHIP新电脑(2016年3期)2016-03-10 14:22:03
