
基于经验模态分解的时间序列预测方法
2021-06-30 03:47刘丹丹
上海电力大学学报 2021年3期
刘丹丹
(上海电力大学 电子与信息工程学院, 上海 200090)
时间序列就是将不同时间上的某个指标的不同数值按照时间顺序排列而成的数列,是一种现实生活中常见的数据形式。研究时间序列的发展趋势能够帮助人们合理规划生活需求,如研究某栋大楼的能耗发展趋势,可以为楼宇节能管理提供理论依据;研究金融数据时间序列的发展趋势,有助于人们把握宏观市场的运营规律。各行各业的运行数据几乎都可以被视为时间序列,因此建立准确有效的时间序列预测模型一直是相关领域的研究热点。
经典的时间序列预测模型以随机过程理论和数理统计学为理论基础,主要包括自回归滑动平均模型(Auto-Regressive Moving Average model,ARMA)和自回归积分滑动平均模型(Auto Regressive Integrated Moving Average model,ARIMA)。这两种经典的时间序列预测方法在很多领域取得了较好的预测效果[1-5]。然而,有一些文献指出,经典方法用于线性、平稳的时间序列时,预测精度较高,但不适用于非线性非平稳时间序列。因此,近年来,一些研究将机器学习算法应用于非线性非平稳时间序列预测领域,取得了更好的效果[6-8]。这些方法多利用神经网络算法、支持向量机(Support Vector Machine,SVM)算法等,建立有效的时间序列预测模型,其中又以SVM算法效果最为良好,在各个领域都得到了广泛的验证[9]。
在实际应用中,针对一些非线性非平稳时间序列来建立预测模型时,以SVM为代表的机器学习算法仍然难以满足人们对预测精度的要求[10]。因此,研究人员提出使用经验模态分解法(Empirical Mode Decomposition,EMD)对序列进行预处理,而后再使用机器学习算法,可以获得更高的预测精度[11-14]。基于此,本文建立了基于EMD-SVM联合算法的时间序列预测模型,同时针对能耗时间序列的特点,构建了模型输入输出数据集,从而获得了较好的预测效果。
1 算法研究
1.1 经验模态分解算法
EMD方法由HUANG N E等人[15]于1998年提出。该方法在对信号进行分解时无需设定基函数,完全根据数据自身的时间尺度特征处理信号。因此,EMD方法在理论上适用于任何类型的信号分解,尤其是处理非平稳非线性时间序列数据。该方法一经面世,即在不同工程领域得到了有效的应用。EMD方法分解序列的基本步骤如下。
假设信号x(t),确定该信号的所有极值。在最小值(最大值)之间进行差值计算,得到包络smin(t)(smax(t)),且计算包络的均值为
(1)
计算本征模函数(Intrinsic Mode Function,IMF)c1(t)为
c1(t)=x(t)-m1(t)
(2)
根据IMF的计算结果迭代残差r1(t)为
r1(t)=x(t)-c1(t)
(3)
重复以上步骤,直到分解结果满足停止条件。此时,原始序列被分解为多个IMF和一个对应残差。该原始序列可表示为
(4)
这里,残差rN(t)可以表示为
(5)
由分解过程可知,与短时傅立叶变换、小波分解等方法相比,EMD分解过程较为简单、直观。同时,由于这种方法是基于信号序列时间尺度的局部特性进行分解,因此具有自适应性。
1.2 支持向量机算法
SVM算法由VAPNIK V[16]提出,是一种机器学习方法,已广泛应用于各个领域。当SVM应用于数据建模和预测时,被称为支持向量回归(Support Vector Regression,SVR)。核函数和优化器算法是SVM的两个重要部分。使用非线性函数可以将非线性数据从原始的特征空间映射至更高维的希尔伯特空间(Hilbert space),并使其线性可分;而优化器算法用于解决优化问题。SVM算法基于结构风险最小化(Structural Risk Minimization,SRM)原理,因此它力求将由训练误差和置信度之和组成的泛化误差的上限最小化,优于仅将训练误差最小化的训练模型。
1.3 EMDSVR时间序列预测算法
EMD-SVR联合算法的基本原理主要包括3个部分:利用EMD算法,将非线性非平稳原始数据序列分解为各个子序列;针对各个子序列,重构数据集,建立SVR时间序列预测模型,计算预测结果;计算子序列预测和,即为原始序列预测结果。
2 实验方法及结果分析
2.1 数据集重构方法


(6)
式中:d——步长。

(7)
2.2 预测精度验证标准
一般使用均方误差(Mean Square Error,MSE)及决定系数R2评价预测模型的优劣。这两个参数的总体目标为测量预测值与实际值之间的距离,比如R2越接近于1,同时MSE越小,则证明模型的预测结果越精确。 其公式分别为
(8)
R2=
(9)
式中:l——时间序列中的数据个数;
f(·)——时间序列的预测值。
2.3 算法流程
整个算法的完整流程描述如下。
(1) 使用EMD算法将原始时间序列分解为一些子序列。
(2) 对于每个子序列,假设预测步长为d,根据序列特性确定d。如建筑能耗数据多以24 h为一个周期,则对于此类序列d可取2~24之间的数值;
(4) 应用SVR算法建立子序列预测模型,并计算MSE及R2。
(5) 重复步骤(2)到步骤(4),根据MSE及R2的计算结果选取最佳步长d,记录该子序列的最佳预测结果。
(6) 对每个子序列重复步骤(2)到步骤(5)。
(7) 将各个子序列的预测结果之和作为最终预测结果。
若序列步长可以确定,则可以省去搜索最佳步长的步骤,大大减小算法的复杂程度。一般来说,可选择使MSE较小,而R2更接近1的步长值。同时,选择步长d时,应综合考量测试集和训练集的预测精度,在针对训练集预测精度差异不大的情况下,应优先选择针对测试集预测精度更高的步长值。
2.4 实验结果
将算法应用于某幢楼的能耗数据。随机选择某周工作日的能耗数据共120个。使用单位根检验法检验后,确认其为非平稳时间序列。经过EMD分解后的原始序列与平稳子序列如图1所示。
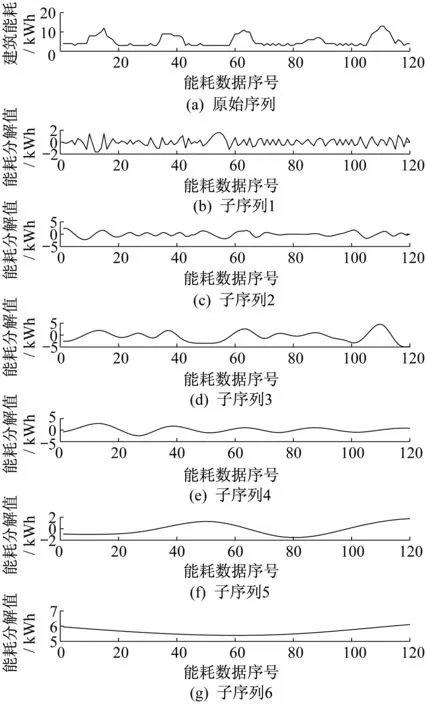
图1 EMD算法分解后的子序列示意
对每个子序列建立基于SVR算法的预测模型。选取步长d为(2,9)之间的整数,根据MSE及R2的计算结果选取最优步长。同时,对原始序列针对不同步长直接使用SVR算法建立预测模型,并对比EMD-SVR算法和SVR算法的预测精度。不同步长时两种算法的MSE和R2值对比结果如表1所示。由表1可以看出,选择任意步长值时EMD-SVR算法针对非平稳时间序列的预测结果都明显优于SVR算法。此外,综合EMD-SVR算法对测试集和训练集的预测结果可选取步长8作为最优步长,选择该步长的情况下训练集的R2值为0.967 739,测试集的R2值为0.926 781。

表1 不同步长下两种算法的预测性能
步长为8时,EMD-SVR算法的能耗序列预测结果如图2所示。其中,序列数据总数为120,算法将预测序列中第9到第120共112个数据。由图2可以看出,预测数据与原始数据非常接近,可以满足用户对于预测精度的要求。
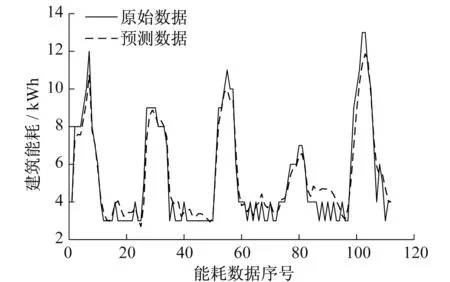
图2 EMDSVR联合算法在数据集上的预测结果
3 结 语
本文以非线性非平稳能耗数据时间序列为研究对象,重点研究了EMD-SVR联合算法在建立能耗数据预测模型上的应用。首先,将能耗数据视为时间序列数,使用EMD算法将非平稳时间序列分解为不同频率分量的平稳时间子序列;然后,根据能耗数据的特点选择合适的步长,构建适合算法的数据集;最后,应用SVR算法建立子序列预测模型,子序列模型预测结果之和即为EMD-SVR算法对该时间序列的预测结果。从实验结果可以看出,预测非平稳时间序列时EMD-SVR算法较SVR算法的精度更高。
猜你喜欢
肇庆学院学报(2022年5期)2022-09-29
昆钢科技(2022年2期)2022-07-08
一重技术(2021年5期)2022-01-18
当代水产(2021年10期)2022-01-12
成都信息工程大学学报(2021年5期)2021-12-30
西安邮电大学学报(2021年1期)2021-04-19
建材发展导向(2021年23期)2021-03-08
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
华人时刊(2018年15期)2018-11-10
