
基于双路径残差网络的虹膜图像超分辨率重建
2021-06-30 03:07:50王鹤铭沈文忠
上海电力大学学报 2021年3期
王鹤铭, 沈文忠
(上海电力大学 电子与信息工程学院, 上海 200090)
虹膜识别是一种可靠的身份认证方式,虹膜纹理具有高度的稳定性、唯一性和鉴别能力[1]。在不可控的应用场景中,如监控和移动生物识别中,由于设备或采集距离的限制,采集的虹膜图像缺失像素分辨率,导致虹膜定位错误甚至无法定位,严重影响了虹膜识别性能。图像超分辨率(Super Resolution,SR)重建技术为解决这一问题提供了方法。
超分辨率重建技术[2-3]是指根据一幅或多幅低分辨率(Low Resolution,LR)图像,重建一幅高分辨率(High Resolution,HR)图像,可大致分为基于插值、基于重构和基于学习3种方法。基于插值的方法,如最近邻插值和双三次插值法,具有算法简单、计算速度快等特点,但重建图像精度不高。基于重构的方法,如邻域嵌入和锚点邻域回归,是利用图像先验信息作为约束条件生成锐利的纹理细节,但当缩放因子较大时,重建效果迅速退化。近几年,随着机器学习和计算机视觉的迅猛发展,基于卷积神经网络(Convolutional Neural Network,CNN)的超分辨技术成为研究热点。SRCNN[4]是最早的3层CNN网络,将SR任务分为特征提取、非线性映射和图像重建3部分,具有优于插值法和重构法的重建效果。但由于网络结构简单,所以重建图像存在模糊现象。深度超分辨率(Very Deep Super Resolution,VDSR)[5]拓展了SRCNN的非线性映射部分,改用20层卷积层的VGG-Net为基本架构,并采用小尺寸卷积核,取得了良好的重建效果。深度递归卷积网络(Deeply Recarsive Convolution Network,DRCN)[6]为减少网络参数量,堆叠16层递归卷积层,并采用递归监督和跳跃连接加速网络收敛,稳定训练过程,提升网络性能。残差密积网络(Residual Dense Network,RDN)[7]结合残差块和密集块的独特优势,设计残差密集块提取特征,并充分融合图像上下文信息,进一步提高了重建精度。
上述工作主要针对自然图像的超分辨任务。虹膜图像有其独特的属性,结构信息较少,虹膜纹理具有随机性、复杂性和极大的变异性,就使得在开放的数据集中进行超分辨任务变得尤为困难。此外,自然图像关注重建的视觉效果,注重优化保真度指标,如峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似度(Structual Similarity,SSIM)。虹膜图像的超分辨除保证视觉感受外,还应考虑其识别效果。已有少量超分辨率研究围绕虹膜图像展开。文献[8]探讨了CNN在虹膜识别应用中的可行性,将5个预训练好的网络作为虹膜关键信息提取器,使用支持向量机作为分类器,发现CNN擅长表达虹膜图像,并可有效提高虹膜分类准确度。文献[9]采用不同类别的数据集(纹理、自然以及虹膜图像数据集)分别训练SRCNN和VDSR,使用虹膜图像微调,发现重建图像保真度及识别效果均优于传统方法。本文在以上工作的基础上,结合虹膜图像细节纹理差异,设计了适用于虹膜图像的超分辨率重建的双路径结构,能准确重建高保真度的高分辨率虹膜图像;对超分辨率主体网络、特征提取模块、上采样策略进行了优化设计,进一步提高重建图像的PSNR和SSIM;进行了虹膜匹配实验,取得了优异的识别效果。
1 双路径残差网络
为了获取虹膜图像的结构和纹理特征,本文采用双路径网络结构,由不同的支路网络完成不同的特征提取任务,具体如图1所示。与SRCNN类似,双路径残差网络将整个网络分为浅层特征提取、非线性映射和图像重建3部分。
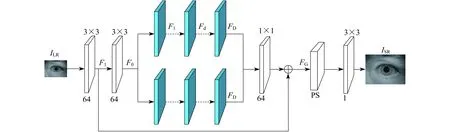
图1 双路径残差网络
1.1 浅层特征提取
早期的SRCNN和VDSR等超分辨网络采用前置放大策略,先将原始低分辨率图像ILR通过插值法放大为目标尺寸,随后送入网络。提取的特征包含插值法引入的误差信息,故而重建精度不高。本文采用后放大策略,与上采样模型配合,直接从ILR提取浅层特征F-1和F0。F-1用于全局残差学习,F0作为两个支路网络的输入。
1.2 非线性映射
虹膜内外圆是重要的结构信息,用于虹膜的精确定位,虹膜纹理细节是匹配的唯一依据。针对这两种不同的特征,本文采用双路径结构[10],支路1提取细节特征,支路2提取结构特征。在双路径均引入残差密集块(Residual Dense Block,RDB),用于提取深层虹膜特征,具体如图1中蓝色卷积块所示。各支路采用RDB提取深层信息,原始RDB如图2所示。
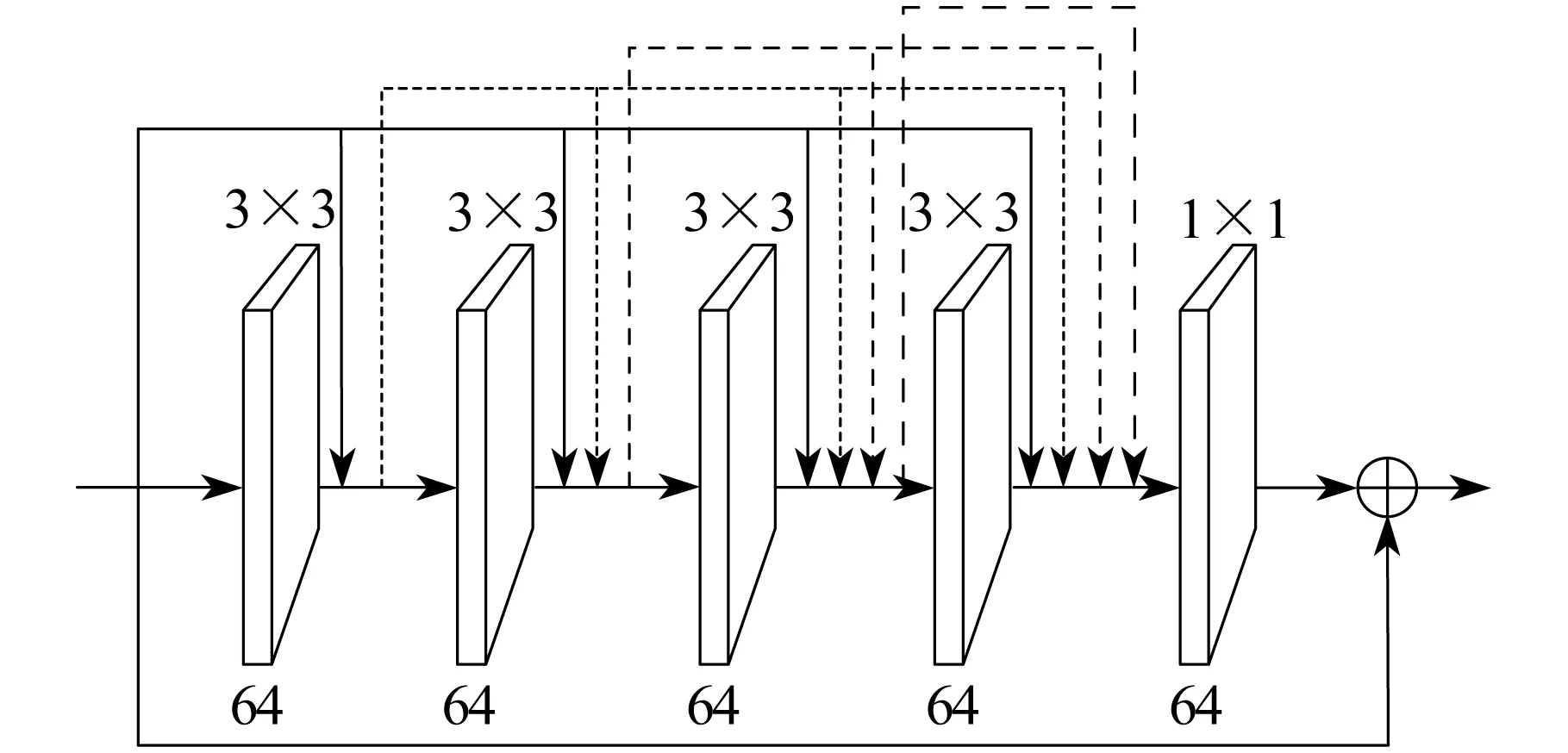
图2 原始RDB
RDB由一组3×3卷积层、密集连接、通道约束层以及局部残差学习组成。密集连接和局部残差学习能充分利用各级分层特征,相当于高通滤波器,不断地将前向特征向后传递。在保留高频分量的同时,避免了卷积过深而造成的信息丢失。
假设第d个RDB内有C层3×3卷积层,则第C层卷积层的输出表示为
FC=WC[Fd-1,F1,F2,…,FC-1]
(1)
式中:WC——第C层卷积;
[Fd-1,F1,F2,…,FC-1]——C层前面所有层的输出及RDB输入的密集连接。
第d个RDB的输出表示为
Fd=Wd([Fd-1,F1,F2,…,FC])+Fd-1
(2)
式中:Wd——通道约束。
本文改进原始RDB,设计两条使用不同尺寸的卷积核支路的RDB。卷积核越大,其对图像的感受范围越大,能提取更为全局、语义层次更高的特征。支路1使用的卷积核尺寸为3×3,有较小的感受野,对于细微的纹理信息比较敏感,可捕捉相邻像素间上下、左右之间的关系,并提取细节特征[11]。支路2卷积核尺寸为5×5,对于图像的形状轮廓较为敏感,因有大的感受野,故能从原图中提取丰富的结构特征。但大尺寸卷积核会增加参数量和计算复杂度。卷积核数量相同时,一个5×5卷积层的参数量和计算量是3×3卷积层的2.78倍。由于两个3×3卷积核感受野与一个5×5卷积核感受野相同,因此将5×5卷积核替换为两个3×3卷积核,既可以保证感受野和网络性能不变,又可以减小计算复杂度和参数量。这样,支路2的卷积层数量是支路1的2倍。
支路1提取的纹理特征FD表示为
(3)
式中:W1,W2,W3,…,WD——D个RDB的特征提取;
F1,F2,F3,…,FD——RDB提取的特征。
支路2提取的结构特征用F′D表示。
1.3 图像重建
图像重建包含特征融合、全局残差学习和上采样模型。结构特征和纹理特征融合可以更好地表达虹膜图像。跳跃连接是对特征的并行排列,特征本身大小不会改变,可以有效减少网络中要求准确承载信息的负担,缓解网络模型模拟非线性映射的难度。本文采用跳跃连接集成结构和纹理特征,为减少计算复杂度,采用1×1的卷积核约束通道数量。全局残差学习能够加快网络收敛,降低训练难度。最终提取的特征FG可表示为
FG=WG([FD,F′D])+F-1
(4)
式中:WG——通道约束;
[FD,F′D]——跳跃连接。
FG是直接从原始低分辨虹膜图像上提取的低维度特征,需通过上采样将特征图映射为目标大小。本文采用文献[12]提出的亚像素卷积层,具体如图3所示。
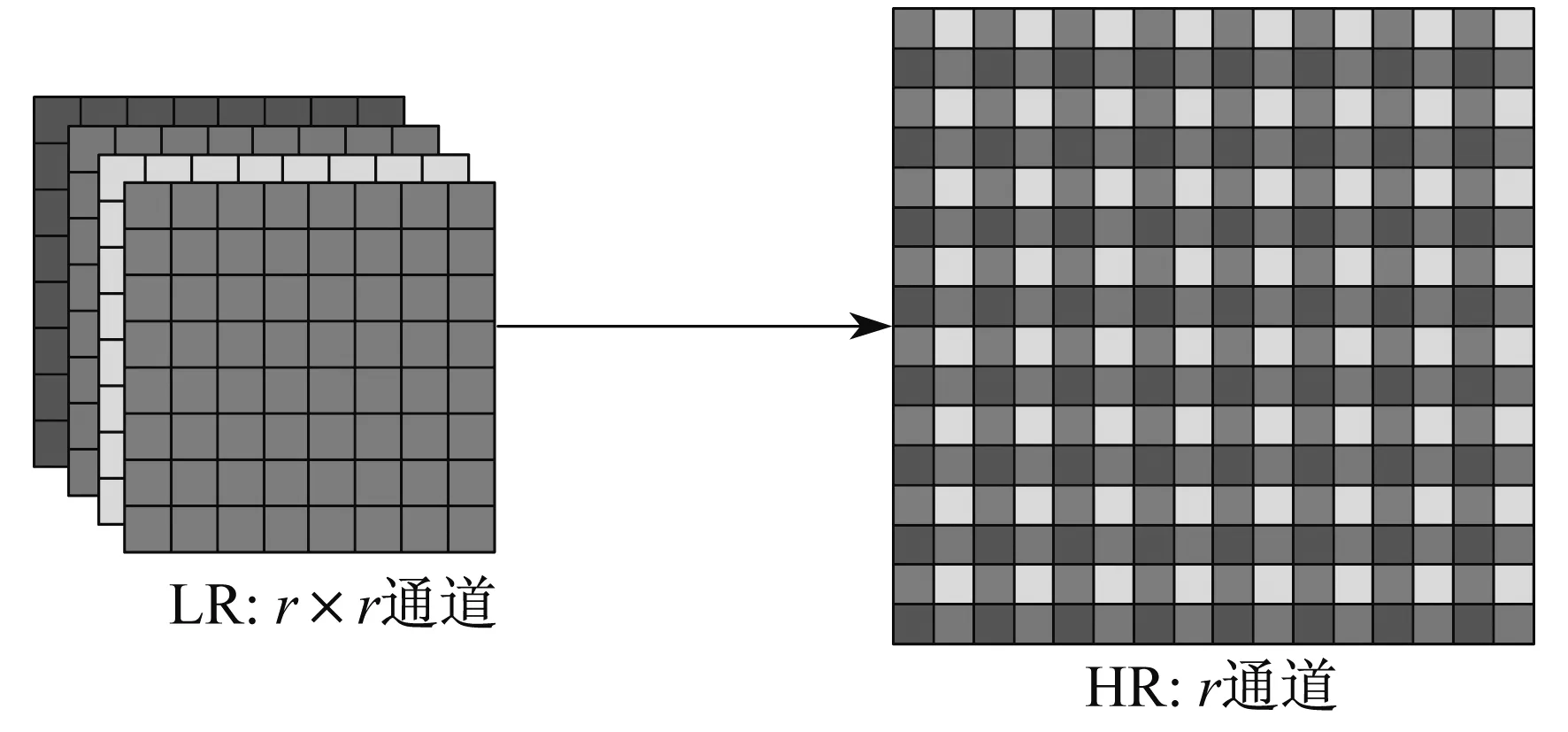
图3 亚像素卷积层
首先,亚像素卷积层采用后放大策略,不会引入错误信息。其次,亚像素卷积层使用手工固定卷积核,而是通过训练得到一组周期移动卷积核,这些卷积核切合当前超分辨任务,能有效保证重建质量。周期移动卷积核(Periodic Shuffling,PS)可表示为
PS(T)x,y,c=T[x/r],[y/r],C·r·mod(y,r)+C·mod(x,r)+c
(5)
式中:T——网络中的张量;
x,y——HR空间中的像素坐标;
r——用于重建的上采样因子;
c——最终通道数。
这些滤波器可以将r×r通道的LR特征图映射为r通道的HR。重建的高分辨率图像ISR可表示为
ISR=PS(FG)
(6)
2 实验结果与分析
2.1 数据集
本文使用中科院CASIA-IrisV4/CASIA-Iris-Lamp虹膜图像库训练网络。该图像库是在不同光照条件下采集的,瞳孔会随光照变化而弹性变形,使得相应的SR任务难度增加。选用Lamp模拟真实采集的应用场景。Lamp共计16 212张图像,411人。随机选择300人,挑选结构清晰、纹理丰富的左右眼各10幅图像,共计6 000幅图像作为训练集。随机选择300人,左右眼各6幅图像,共计3 600幅作为测试集。
Lamp图像视为HR,本文采用双三次插值法(Bicubic)作为退化模型,对Lamp下采样,模拟实际的LR。在网络训练之前,首先对原始HR图像按照步长(设为16)进行裁剪,得到一系列48×48 HR图像块,然后根据缩放因子(例如4倍)的大小,进行下采样,得到对应图像块LR(12×12)。LR和HR组成图像对,相当于将input和label送入网络进行训练。
2.2 实验设置
在Windows 10系统中搭建的Tensorflow框架下进行训练,电脑硬件参数为Inter Core i7-8700K,显卡为Nvidia Geforce RTX 2080Ti。初始化学习率为10-4,学习率更新策略为Adam,动量参数β设置为0.9,激活函数统一设置为Relu,训练周期为100。
超分辨率的目的是重建高分辨率图像ISR,使其尽量接近原图IHR。网络训练是在寻找LR和HR之间的非线性映射,也在不断更新和优化各层网络参数W和b。本文选用平均绝对误差(Mean Absolute Error,MAE)作为损失函数,则为
(7)
式中:W,b——卷积核参数和偏差;
M,N——图像的宽和高;
I(x,y)——图像坐标(x,y)处的像素值。
Bicubic,VDSR,DRCN,RDN等算法的训练采用与本文相同的训练集和测试集,训练设置均与其对应开源代码一致。本文算法在实验过程中对其进行了2倍、4倍和8倍的重建。采用主观可视化比较(PSNR)和客观评价指标(SSIM)对这5种算法进行评估。考虑到虹膜图像的实际应用,设计了虹膜匹配实验,将等错误率(EER)作为另一评价指标。
2.3 网络优化
网络中RDB数量(D)及RDB内卷积层数(C)对网络深度、参数量以及重建质量等影响较大。本文在缩放因子为4时,改变D和C,训练不同深度的网络,寻找最优化网络模型。首先,拟定C为4,改变D的大小训练网络,并统计各项评估指标。RDB数量优化如表1所示。

表1 RDB数量优化
由表1可知,PNSR和SSIM值越高、EER值越小意味着较好的重建质量。当D=9时,PSNR和SSIM的值最高,EER值最小,达到了最佳的视觉感受和识别效果。然而此时网络最深,参数量最多,测试时间最长,计算中消耗大量内存,不可视为最优网络。考虑到虹膜图像的超分辨率重建侧重于识别准确率,因此根据EER与计算速度的折中,选定D为5。随后,改变C的大小训练网络,卷积层数量优化如表2所示。

表2 卷积层数量优化
由表2可知,随着卷积层数的增加,PSNR和SSIM仅有较小的波动,C=8时,其EER最优,但其参数量为123 MB,测试时间最长。C=2时,EER显示最差结果。C=6时EER值比C=4时小0.005%,但其参数量多出2倍多,测试时间也较长。因此,根据EER与计算速度的折中,选定C=4。
2.4 实验结果及分析
不同超分辨率算法重建图像的PSNR和SSIM实验结果如表3所示。

表3 不同超分辨率重建算法的PSNR与SSIM
由表3可以发现,不同缩放因子下,CNN重建虹膜图像的PSNR与SSIM普遍高于Bicubic,效果显著,表明CNN在虹膜图像超分辨率任务中的巨大潜力。本文算法在8倍重建时,取得了最优的PSNR和SSIM,分别比RDN高0.34 dB和0.003 dB,在4倍重建时,取得最优的PSNR,表明本文算法在较大缩放因子时虹膜图像超分辨率重建中优势显著。
不同超分辨率算法重建可视化比较如图4所示。
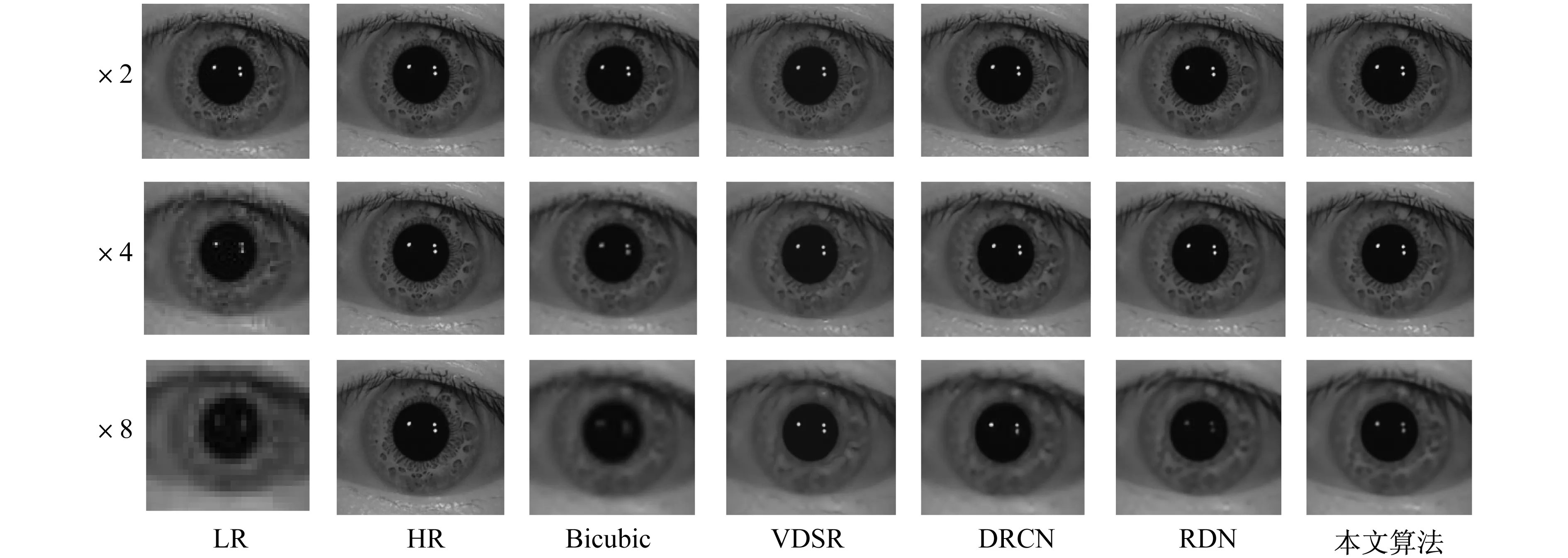
图4 不同超分辨率算法重建虹膜图像的可视化比较
在2倍重建时,各个算法都表现出接近原图的重建效果,随着缩放因子增加,部分网络重建性能下降。4倍重建时,Bicubic出现朦胧的视觉感受,VDSR和DRCN出现虹膜图像纹理模糊,细节丢失的现象,而RDN和本文算法始终有着清晰的结构和纹理。8倍重建时,Bicubic的虹膜区域已经完全模糊,甚至出现可见的像素粒,VDSR和DRCN也由于过度平滑而丢失大量纹理,RDN和本文算法虽然也有细节丢失,但是保留了虹膜区域的部分块状结构性纹理。相比之下,本文算法的纹理亮度较深,观察光斑、睫毛、瞳孔边缘等可以发现,其对微小细节的恢复更加准确,展现出优越的重建质量。
本文同时进行了虹膜匹配实验,并根据EER评估各超分辨率重建算法的重建质量。原始图像的EER为1.394%,其他算法的EER如表4所示。
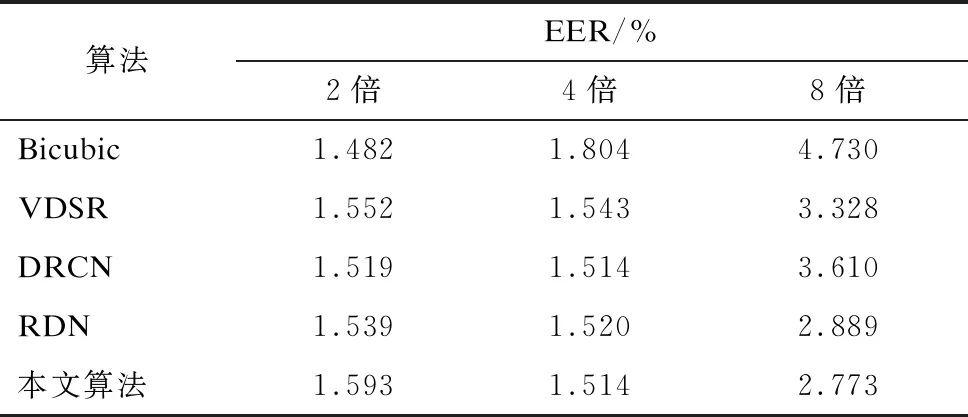
表4 不同超分辨率算法的EER
由表4可以发现,在2倍重建时,Bicubic的 EER为1.482%,最接近原图,且优于其他网络。因此,当采集的低分辨率虹膜图像不需要大的上采样因子时,相比基于CNN的算法,采用传统插值法足以完成超分辨率任务,其识别效果仅有少量退化。在4倍重建时,DRCN和本文算法取得最佳识别效果。在8倍重建时,本文算法的识别效果最佳,且远高于其他算法,表现出优异的重建性能。此外,结合表3可以发现,较高PSNR和SSIM并不会带来较好的虹膜识别效果,在2倍重建时,DRCN的PSNR和SSIM分别比Bicubic高2.83 dB和0.014,而EER低于Bicubic。这表明虹膜图像的视觉效果与识别效果没有明显的相关性,虹膜图像的超分辨率任务更应该注重提升识别的准确率,而非视觉效果。
3 结 语
本文提出基于虹膜图像的双路径残差网络,将低分辨率虹膜图像作为网络输入,设计双支路,利用不同深度的残差密集块分别提取细节特征和结构特征,引用全局残差学习融合特征,最后经亚像素卷积层将提取的低维度特征放大,重建出高分辨率虹膜图像。实验结果表明,本文所提算法能高效准确重建高分辨率虹膜图像,尤其在缩放因子较大的情况下,其领先的PSNR和SSIM及清晰的可视化效果表明重建图像具有较高的保真度。同时,与其他算法相比,本文算法的EER表现更好。由于在虹膜图像采集过程中会出现低分辨率美瞳图像,因此实际虹膜识别过程中需即时侦测美瞳图像,考虑将图像超分辨率技术用于重建高分辨率美瞳图像,以提高其侦测准确率。
猜你喜欢
中国典型病例大全(2022年11期)2022-05-13 17:54:50
能源工程(2020年6期)2021-01-26 00:55:22
软件(2020年3期)2020-04-20 01:45:18
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:00
文萃报·周二版(2018年51期)2018-08-04 06:05:18
Coco薇(2017年8期)2017-08-03 15:23:38
电信科学(2016年9期)2016-06-15 20:27:30
电测与仪表(2016年13期)2016-04-11 11:21:20
Coco薇(2015年5期)2016-03-29 23:22:15
警察技术(2015年3期)2015-02-27 15:37:15
