
基于深度学习的学生画像选课系统研究
2021-06-28 19:10李沁颖易豪
电脑知识与技术 2021年10期
关键词:深度学习
李沁颖 易豪

摘要:目前,深度学习利用自身优势,已在语音识别、图像处理等方面取得了重大的突破与成就。然而,深度学习在选课推荐系统领域的研究与应用还处于早期阶段。考虑传统的选课系统难以考虑到影响学生选课的多因素,本文基于深度学习,结合协同过滤技术在选课系统中的应用,实现对学生的多方面画像,构建出一个实时感知学生喜好变化,且对其进行智能推荐选课的平台,实现从学生到课程的无误差匹配。
关键词: 用户画像技术;深度学习;协同过滤技术;学生选课系统
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2021)10-0184-03
Abstract: At present, deep learning has made great breakthroughs and achievements in speech recognition and image processing by taking advantage of its own advantages. However, the research and application of deep learning in the field of course selection recommendation system is still in the early stage. Considering the traditional course selection system is difficult to consider the many factors influencing students' course selection, based on the deep learning, combining the application of collaborative filtering technology in the course system, realize to the students' various portraits, construct a real-time perception student preferences change, and carries on the intelligent recommended course platform, from students to the course of matching error.
Key words: User Portrait Technology; Deep learning; Collaborative Filtering Technology; Course selection recommendation system
1 引言
随着互联网技术的迅猛发展与人们物质生活水平的日益提升,移动终端设备普及度上升,各种移动应用也竞相进入人们的日常生活中,导致互联网信息呈爆炸式增长。面对海量信息及当下社会不断加快的生活节奏,人们正面临着信息筛选困难,信息处理效率低下,信息交流冗杂等的困扰,不可避免地使企业由于对用户的营销不够细化,继而推送一些不合时宜、不符偏好的信息为用户带来骚扰,甚至引起客户流失。因此,如何处理、利用与用户各方面相关的信息,构建实时标签化体系,并实现在用户及其信息需求之间精准地自动化匹配,成为现今各大企业主要研究的目标,用户画像及其相关技术就在这种背景下诞生并发展。
目前针对用户画像的研究方法大多基于“收集信息-行为建模-构建画像”技术,以构建浅显的用户画像。这一方法未将用户行为信息、偏好信息等特征之间的联系进行更深层挖掘。此外,用户信息处理也面临着数据信息量大、纬度高、相互独立等问题,使得基于浅层构建方法的预测效果较差。
2 用户画像技术
用户画像(Persona)是一种研究用户的系统化偏重类方法,也被称为用户角色。该技术通过收集用户的统计信息、偏好信息、行为信息,对大量目标用户群的真实信息进行处理,构建用户标签化体系,针对产品或服务的目标用户群做典型特征描述,从而让产品经理更直观地了解用户,设计出更符合需求的产品原型。因此,用户画像成为用户需求与产品设计之间联系的枢纽。
加利福尼亚大学的Syskill和Webert通过显式地收集网站用户对网页的满意度信息,再通过信息统计分析和逐层学习,构建出用户兴趣模型[1]。CUM 大学开发的Web Watcher 以及后來的 Personal Web Watcher[2],可以通过数据采集器,采集并统计互联网上用户的浏览行为和浏览偏好,成功构建出用户的兴趣模型,并随着各项数据信息的积累实现系统模型更新。不同研究领域的用户画像研究方法也会有所差异,常用的有决策树[3-4]、逻辑回归[5]、支持向量机[6]及神经网络[7-8]等模型。在使用传统方法对用户画像构建时,数据来源局限于个人收集、业务收集、关系收集等,其中的部分信息不全面或者鱼龙混杂,导致对用户画像的勾勒较为粗糙且片面。随着现在大数据技术的发展与成熟,用户数据的来源愈加广泛,可获取用户的社交、兴趣、属性、环境等多方面信息,进而细化出精准的用户画像。精准用户画像技术广泛应用于多个领域中,其中有用户画像在电商领域中的应用、网络安全用户行为画像安全设计。
3 学生画像选课系统
3.1 学生选课系统
信息化时代的发展使得线上教学变得更加便捷,为了调动学生自主学习,自主选择的热情,各种学生在线选课系统应运而生。基C#的学生系统[9]主要运用了Microsoft SQL Sever2000, Microsoft SQL Sever及C#等工具,优化了程序代码、避免数据冗余,执行高效,便于统筹管理。随着互联网技术的进一步发展和移动终端设备普及度的提升,使得各种以在线选课系统为功能的手机App也被开发出来,基于Andriod平台的校园选课系统成为主流,利用C/S架构,客服端通过JSON和服务端进行交互,而JSON数据体积小,这种轻量化的传输模式,更加易于解码,与XML相比减少了解码难度、运行时的兼容问题以及传输速度更快。目前,选课系统大都在使用网页B/S的模式,这种模式对服务器要求高,传输速度慢。所以学校服务器可能在选课高峰期崩溃,使得部分学生无法第一时间选择自己喜欢的课程,并考虑到现在的选课系统大都只由学生片面的第一主观意识选择,并未综合学生的自身情况与学校培养计划两者考虑,可能导致学生在选课后对所选课程并无兴趣,缺少对该课程学习的热情,学生学而未学,老师教而未教。因此,基于深度学习的学生画像选课系统的研究便十分重要,通过深度学习建立学生用户模型,能实时感知到学生对课程的喜好并准确、精细地对学生用户画像个性化标签,使得学生有目的了解和选上自己合适、喜爱的课程。
3.2 学生画像技术
学生画像技术是用户画像技术的一个分支,通过对学生进行数据收集,行为、偏好分析再建立准确且细致的学生标签模型,这些模型就是学生画像。在数据收集,行为、偏好分析这个过程中所总结出的学生特征,就是学生标签。学生画像技术将在下一阶段教育信息化建设中起到重要引导方向。
3.3 学生画像的构建过程
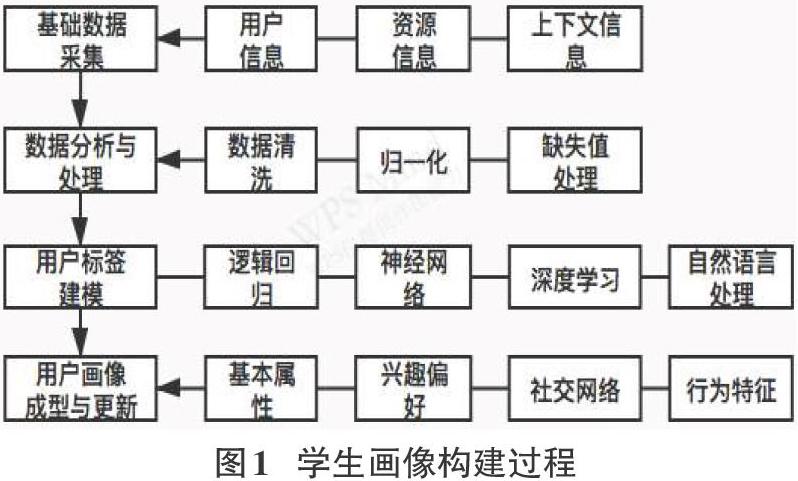
通过用户画像技术的概述我们不难发现,学生用户画像的构建主要通过以下四个步骤来实现,如图1所示。
3.3.1 学生数据采集
在学生数据的采集过程中,主要通过三个方面去收集。第一项是学生基本数据信息,此项信息可以从教务系统中获取,获取方式简单且信息准确。第二项是学生行为数据信息,包含了学生自己的一些主观喜好及想法,在学生自主选课过程中有主导作用。第三项是大数据信息,包括学生的浏览、消费、社交等方面偏好的数据记录,此项信息量较大,故需通过算法生成学生的部分标签。在学生数据采集的过程中,应该联系各项信息之间的关系来联动采集。
3.3.2 数据分析处理
经初步采集得到的原始数据,多数情况下会有数据差异,数据缺失,以及格式不统一的问题出现,所以要对数据进一步清洗筛选及分析等处理。最关键的是对所得的数据探究性分析和处理,包含了对数据的理解、过滤、补充、纠正,最后实现数据的归一化,提高信息的价值相对性,输出后成为用户标签建模的基础。
3.3.3 学生标签建模
在数据分析处理完成后,就要着手构建标签模型。通过每个学生的具体化标签,推算出符合学生潜在偏好的课程,完成数据可视化。在学生标签模型构建的过程中需要多种算法支持,经计算后得到每个学生的个性化标签,例如用来神经网络算法和决策树算法来计算出学生的时空标签、基本特征及其延展;通过TF-IDF算法可计算出学生标签权重。处理不同的数据,所需的算法模型一般不相同,处理一项具体信息时要使用对应的算法,才能提高数据分析及特征处理工作的效率。
3.3.4 学生画像成型及分类
结合上述步骤,学生系统就可以依据每个学生全面的信息实现个性标签化,并可以依据学生间的关联与差异进行不同的归类。再加以上深度学习的支持,能在分析学生基础标签后计算产生新的标签,进一步更新并扩充学生标签,使学生画像更为生动,流程图如图2所示。
4 深度学习在学生画像选课系统中的应用
深度学习通过构建具有很多隐层的機器学习模型和训练数据,能够提高分类的准确性,加之大数据技术的强大计算能力,通过对现有的标签模型分析,可提前较为准确推测出学生将产生的新行为和新标签,在学生选课系统中的作用必不可少。
4.1学生标签的建模
标签建模的方法主要分为两大类,人工建模和机器建模,两种建模方式各有优劣势。深度学习机器建模在学生标签建模过程中作用非常广泛,机器建模通过机器对学生标签样本的多维度学习,然后建立机器自学习的标签模型,调整学生样本数据、标签模型结构及参数可逐步完善模型。
将学生的多方面信息作为模型训练的数据,并通过对信息筛选和过滤出学生偏好方面的信息,以学生标签就可以完成简单的深度学习建模。
4.2 多元化模型
因为学生标签受多方面的影响,所以模型中需要考虑其他影响因素,比如说学生借阅的图书的种类,以及查询学习资料的记录等。要通过深度学习将简单的模型多元化。
在模型的特征维度上按影响因素展开,将影响因素放在一个轴上,这样可以让模型获取更立体的训练数据,这样就利于模型准确推测出学生的偏好标签。比如学生某门选修课成绩为优秀,并不能断定该学生对这门课很感兴趣,但如果同时借阅相关书籍并且在上网查找了该方面的学习资料时,和标签结果就有一定相关性了。就是加上学生前后学习行为的来龙去脉,而让数据更立体,更丰富,让学生模型对标签的判断更准确。
4.3 嵌入矩阵技术
采用嵌入矩阵技术,其包含多维信息及影响因素,以学生标签影响因素为例,同上文两个因素的判断嵌入矩阵。可能出现这两个因素对于选课的影响情况,某些情况下这些影响因素可以对应多种事物,而且这种嵌入式的机制通常包含很多因素,在训练模型时就需要不断更新这些矩阵,使用MovieLens数据集示例,标准协同过滤技术,将为学生和学生偏好提供嵌入矩阵,矩阵的大小是由选择的因素数量决定的,关于选择嵌入矩阵中的因子数量,这需要一些反复试验。
4.4 基于协同过滤技术的选课推荐
协同过滤其通常分为两类:分别是Memory-based与Model-based。其中Memory-based可以分为Item-based方法与User-based方法。Item-based方法是根据用户对相似项目的评分数据预测目标项目的评分。所以可以将评分数据视为学生的喜好,收集学生以往行为来获得学生对课程喜好的显隐信息,利用Item-based方法,根据学生一些喜好信息,发现喜好之间的相关性,我们可以基于这些相关性对其他学生进行推荐。
Memory-based推荐方法通过运行最近搜索,将每一个User或Item看成一个向量,计算其他所有User或者Item与它的相似度。得到User或Item之间的两两相似度后,即可进行预测与推荐。
5结论
现今,大多主流的学生选课系统功能较为单一,缺乏对学生显隐性爱好的分析和发掘。而本文研究了基于深度学习从学生画像到选课系统上的应用,通过多元化模型、嵌入矩阵、基于协同过滤技术深度学习搭建学生用户标签模型,提供一个既可实时感知学生喜好变化,又能显示学生显隐爱好信息,并且为对象进行智能推荐选课的多元化平台。
参考文献:
[1] Mladenic, D. Machine learning for better Web browsing. In: Rogers, S., Iba, W., eds. AAAI 2000 Spring Symposium Technical Reports on Adaptive User Interfaces. Menlo Park, CA: AAAI Press, 2000. 82-84.
[2] Chen P M, Kuo F C. An information retrieval system based on a user profile[J]. Journal of Systems & Software, 2000, 54(1):3-8.
[3] 杨晓峰, 严建峰, 刘晓升,等. 深度随机森林在离网预测中的应用[J]. 计算机科学, 2016, 43(6):208-213.
[4] 王靖, 王兴伟, 赵悦. 基于变精度粗糙集决策树垃圾邮件过滤[J]. 系统仿真学报, 2016, 28(3):705-710.
[5] 徐建民, 粟武林, 吴树芳,等. 基于逻辑回归的微博用户可信度建模[J]. 计算机工程与设计, 2015(3):772-777.
[6] Dong L, Wesseloo J, Potvin Y, et al. Discrimination of Mine Seismic Events and Blasts Using the Fisher Classifier, Naive Bayesian Classifier and Logistic Regression[J]. Rock Mechanics & Rock Engineering, 2016, 49(1):183-211.
[7] 李翠停. 基于神经网络模型的苹果手机预约数据的分析[D].南京:东南大学, 2016.
[8] 陈巧红, 孙超红, 余仕敏,等. 基于递归神经网络的广告点击率预估研究[J]. 浙江理工大学学报, 2016,35(6):880-885.
[9] 曾伟洪,周军城.基于C#的学生选课系统[J]. 2016,3(2):7-8.
【通联编辑:王力】
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
考试周刊(2016年64期)2016-09-22
