
多注意力机制的藏汉机器翻译方法研究
2021-06-28 17:10刘赛虎珠杰
电脑知识与技术 2021年10期
刘赛虎 珠杰

摘要:互联互通时代了解和掌握不同语言的区域文化和信息十分重要,机器翻译是目前广泛应用的交流媒介。本文以藏汉机器翻译为研究对象,利用Transformer框架和模型,研究了基于Transformer多注意力机制的藏汉机器翻译方法。经过实验,评估了多语料融合实验、语料双切分实验对比效果,得到了BLEU值 32.6的实验结果。
关键词:藏汉;Transformer;机器翻译;注意力机制;多语料
中图分类号:TP399 文献标识码:A
文章编号:1009-3044(2021)10-0004-04
Abstract: It is very important to understand and master regional culture and information in different languages in the age of interconnection. Machine translation is a widely used communication medium. This paper takes Tibetan-Chinese machine translation as the research object, and uses the Transformer framework and model to study the Tibetan-Chinese machine translation method based on Transformermechanism. Through experiments, the comparison effect of multi-corpus fusion experiment and corpus double-segmentation experiment was evaluated, and the experimental results of BLEU 32.6 were obtained.
Key words: Tibetan-Chinese; Transformer; machine translation; attention mechanism; multilingual corpus
机器翻译(Machine Translation,MT)是借助机器的高计算能力,自动地将一种自然语言(源语言)翻译为另外一种自然语言(目标语言)[1]。藏文机器翻译技术经过了数十年的发展,已从传统基于规则、统计等机器翻译技术转变成基于神经网络架构的新技术,藏文机器翻译技术发展可分为基于规则的藏文机器翻译、基于统计的藏文机器翻译、基于神经网络的藏文机器翻译3个阶段。
早在21世纪初期就开始了藏文机器翻译技术,以基于规则的方法中,才藏太[2]结合词项信息和藏文语法规则,提出了以动词为中心的二分语法分析技术,基于此技术开发的藏文机器翻译系统具有词典、公文、科技三个方面翻译功能,其词典量达18.6万条,经评测分析,译文的可读性高达80%。
近年来基于统计方法的藏文机器翻译技术也得到了一定的发展,臧景才等[3]基于短语统计模型利用翻译训练工具Moses实现了藏汉的在线翻译系统。群诺等[4]提出了对基于中介语言词语翻译模型进行改进,融合基于中介语言的统计翻译模型和直接翻译模型到现有的训练过程中,改善统计机器翻译模型训练过程的盲目性、低效性、冗余性和表面性等缺陷的方法。
目前主流的藏文机器翻译技术集中在基于神经网络的方法研究中,仁青东主等[5]采用50万藏汉平行语料结合基于双向RNN的LSTM(长短时记忆网络)神经网络模型开发出的藏汉机器翻译技术取得了BLEU值31的效果;李亚超等[6]提出采用迁移学习解决藏汉语料稀缺问题的方法,并通过对比短语统计机器翻译实验得出该方法可提高3个BLEU值。目前尼玛扎西团队、东北大学“小牛翻译在线开放平台”以及腾讯公司等开发的藏汉机器翻译系统均采用了基于神经网络的方法。
2017年,Google发表论文《Attention Is All You Need》[7]正式提出了完全基于注意力机制的Transformer,并在两项拉丁语系机器翻译任务中取得了最高BLEU值41.8的成绩,2019年,桑杰端珠[8]采用Transformer模型研究了稀缺资源条件下的藏汉机器翻译回译方法,通过93万藏汉平行语料取得了BLEU值最高为27.6的效果。相较之下藏文机器翻译效果提升还有很大的进步空间,因此本文从Transformer理论架构出发,利用多注意力机制,研究多种语料融合、两种不同藏汉文切分方法下的藏漢机器翻译效果。
1 Transformer机器翻译模型
目前主流基于NMT任务的模型均采用Seq2Seq(编码器-解码器)[9]框架,在Seq2Seq下编码器将表征输入序列X=(X1,X2,…,Xn)映射到连续表征Z=(Z1,Z2,…,Zm),解码器从连续表征Z生成输出序列Y=(Y1,Y2,…,Ym)。Transformer框架的设计是通过注意力机制将序列上下文关联,并行处理序列中的单词。Transformer对比LSTM以及Fairseq不同之处是它完全基于注意力机制,没有使用RNN或CNN进行序列对齐操作。完全基于注意力机制使得Transformer不仅可以做到训练上并行化,并在实际翻译效果上相较LSTM更胜一筹。
1.1 Transformer注意力模型
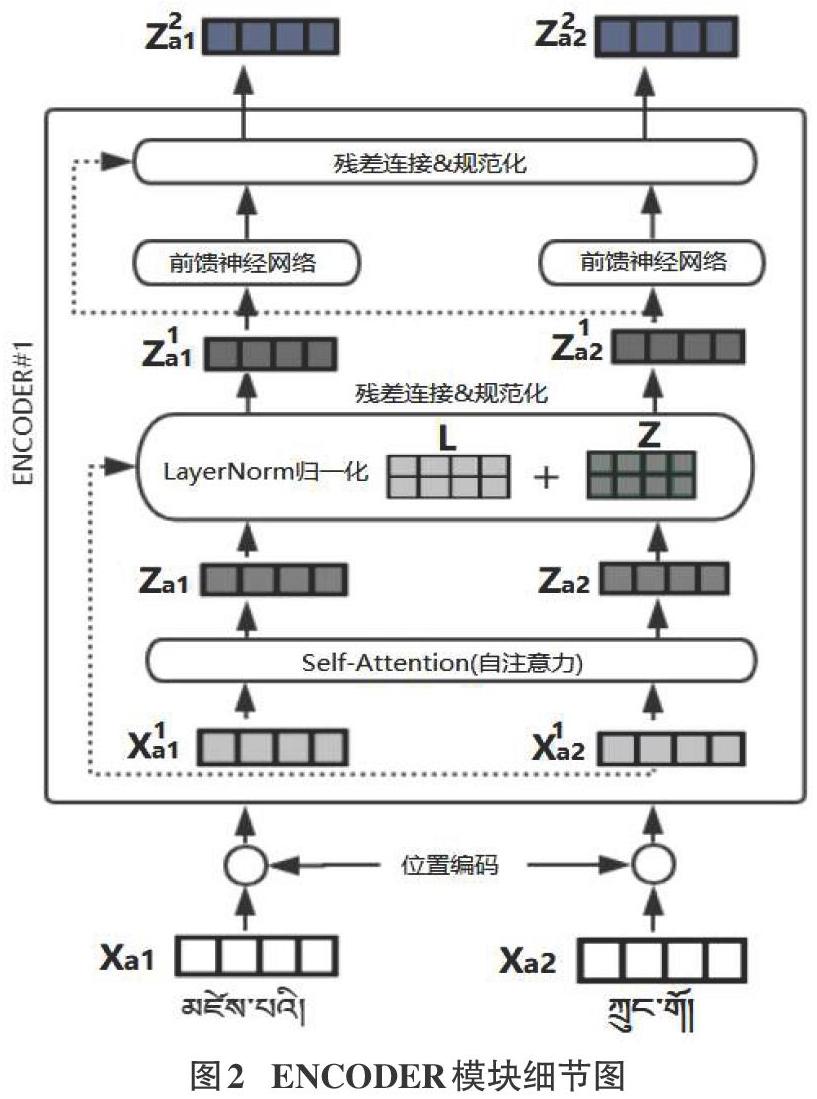
Transformer模型中采用了经典的Encoder-Decoder架构,结构相比于其它Attention更加复杂,初始Transformer采用了由6个Encoder、Decoder层堆叠在一起,单个Encoder和Decoder的内部结构如图1所示。
猜你喜欢
客联(2022年4期)2022-07-06
黄河之声(2022年4期)2022-06-21
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
智能计算机与应用(2017年5期)2017-11-08
考试周刊(2017年2期)2017-01-19
考试周刊(2017年2期)2017-01-19
西藏科技(2015年12期)2015-09-26
西藏科技(2015年10期)2015-09-26
