
基于多模态特征融合的身份识别研究与实现∗
2021-06-28 07:03胡正豪姜兆祯周川川
舰船电子工程 2021年6期
胡正豪 翟 昊 姜兆祯 周川川
(陆军炮兵防空兵学院信息工程系 合肥 230031)
1 引言
现实生活中,身份识别技术在很多行业已经广泛推广开来,成为一个产业智能发展的标志,其中大多数使用的都是人脸识别[1]、指纹掌纹识别[2]或者语音识别[3]等单一的识别技术,但是在光照、噪声等恶劣条件下,单一的模态识别容易引起误判,造成不可估量的损失。
目前,社会上也有对多模态融合识别的研究[4~5],比如匹配层融合、决策层融合;但是,基于音视频特征层的融合识别研究甚少,主要因为特征融合的难度较大,不同模态不同维度不易融合。针对此类情况,本文提出一种将声音匹配值作为特征值与人脸图像主成分提取特征融合进行支持向量机分类的算法。首先,提取声音训练信号的梅尔特征值构建高斯混合模型[6],然后利用测试语音获取匹配值,进行归一化处理,结果作为语音特征值;然后将人脸图像依次进行小波变换、主成分分析获得特征值;最后,将两个特征值进行融合,得到整体特征向量,放入支持向量机进行分类识别。通过实验证明,该方法取得了较理想的实验结果,对于单一噪声的影响具有较高的抗噪能力,并且在一定条件下,具有更高的识别率。
2 语音特征提取
语音特征的提取方式有许多[7~8],但是考虑要与图像特征相融合,本文采用的方法是基于Mel频率倒谱系数的高斯混合模型得分归一化作为语音特征。经过多次实验检验,未进行归一化的数据不能进行SVM的分类识别,更不能进行融合。具体方法如下。
1)将语音训练信号进行预处理后,通过20维的Mel三角滤波器组进行滤波,Mel频率转换公式可表示为
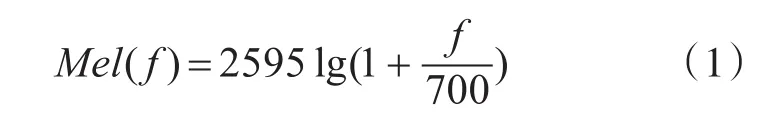
2)进行DCT(离散余弦)变换,得到MFCC特征参数,并计算一阶差分得ΔMFCC,组成混合特征参数[MFCC,ΔMFCC]。
3)利用混合特征参数构建16阶GMM(高斯混合模型)模型库Mi(i=1,2,3…n,n为说话人类别数)。
4)提取测试语音特征代入模型库计算匹配分数,可得Sn={s1,s2,s3…sn}(n为模型数)。
5)对所得匹配分数采用Min-Max方法进行归一化处理
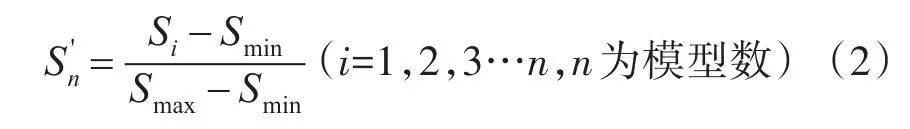
6)对所有测试语音进行以上方法处理,最终得到所有测试语音的分数集合,即所求得语音特征数组 Ym×n。
3 人脸特征提取
人脸识别技术[9]已经广泛应用于人们生活当中,相应的算法也非常成熟。本文采用经典的小波与PCA相结合的方法[10~11]提取人脸面部特征,得到数组Fm×k(m为测试样数,k为PCA降低维度),用于下步的数据融合。具体流程如图1。
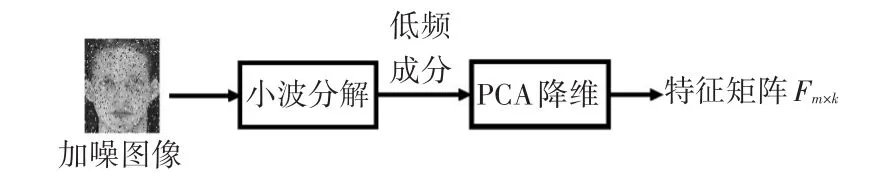
图1 人脸特征提取流程图
小波是指一种能量在时域非常集中的波,与傅里叶波一样属于正交波。它的多分辨分解能力可以通过低通与高通滤波器将图片信息一层一层分解剥离开来,从而可以获得原始图像在水平和垂直方向上的低频分量LL、水平方向上的低频和垂直方向上的高频LH、水平方向上的高频和垂直方向上的低频HL以及水平和垂直方向上的高频分量HH。在本文中使用的是二维小波变换的一级水平和垂直方向上的低频分量LL。
PCA(Principal Component Analysis)是一种常用的数据分析方法,可以将原始数据变换为一组各维度线性无关的表示,提取数据的主要特征分量。它的算法步骤可表示如下。
假设总共有m张p*q大小的照片,则:
1)将所有图片信息整理成p*q行m列矩阵Xp*q×m={x1,x2,x3…xm}。
2)将X的每一行进行零均值化,即减去这一行的均值μ。
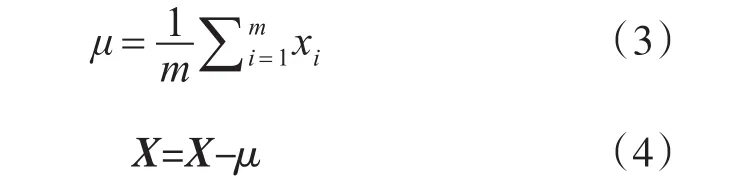
3)求出协方差矩阵

4)求出协方差矩阵的特征值λi及对应的特征向量vi。
5)将特征向量按对应特征值大小从左往右排列,取前k个特征向量组成矩阵P。
6)Y=XP即为降维后得到的k维特征矩阵。
4 特征融合识别方法
为了得到特征融合的最佳效果,特征的融合方法至关重要。本文将以上提取得到的语音特征矩阵Ym×n与人脸特征矩阵Fm×k分别进行了串联和并联两种融合方式[12],求得特征融合矩阵Rm×h(h大小由融合方法与特征维度决定),再进行支持向量机的训练识别,计算识别率。
支持向量机[13](Support Vector Machine)主要是建立一个最优决策的超平面,使得该平面两侧距离平面最近的两类样本之间的距离最大化,从而对分类问题提供良好的泛化能力,其本质上属于线性分类器。为了更好地应用于非线性样本的分类,根据cover定理:将复杂的模式分类问题非线性地投射到高维度空间中可能是线性可分的,因此只要特征维度足够高,在高维空间中将以较高的概率线性可分。因此,研究人员通过设计非线性的核函数,将原特征向量投影到更高维空间,实现支持向量机对非线性样本的分类处理。目前常用的核函数主要有:
1)多项式核函数
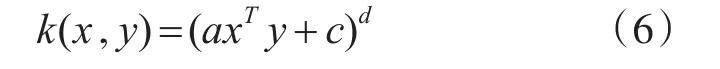
2)径向基核函数

3)Sigmoid核函数
5 实验结果与分析
本文实验主要在Spyder编译环境下使用Py⁃thon3语言完成的,并利用了内部的sklearn库函数完成了相应数据的处理。人脸图片来自ORL数据库,共有400张,40个人各10张不同角度的照片组成。声音数据来自40名工作人员,每个人10段不同文本的语音,总共400段语音,与图片样本相对应,由电脑Audacity软件以单声道16kHz频率录制完成。在实验时,采用十折交叉验证法[14](将数据随机分为10组,9组作为训练,1组作为识别,共进行10次)对数据集分开训练测试,最后,计算得到识别率。
5.1 声音噪声实验
人脸数据不做处理,PCA降维至8维(经过多次实验测得,降至8维时效果最好),声音数据加以信噪比10~30的白噪声(如图2(a)、(b),信噪比为10的数据对比),对比串联、并联两种特征融合方式,支持向量机采用多项式核函数进行试验,Voice结果如图2(c)所示。
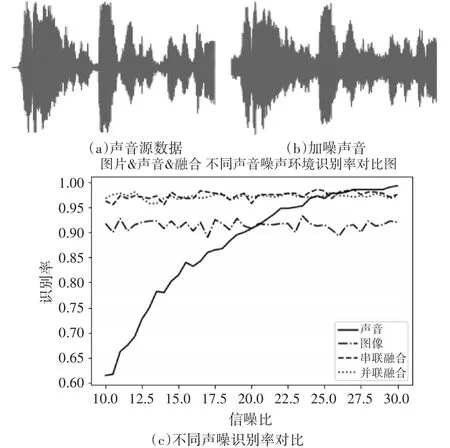
图2 声音噪声实验结果
由图1(c)可见,随声音信噪比的提高,声音识别率不断提高,两种方式融合后的识别率也会有所提高,并且在信噪比低时,高于任意一种单模态识别率。当信噪比提升到27时,声音识别率大幅高于图像识别率,特征融合下的识别率受图像特征的影响,会比声音识别率略低,但也仅次之。由此可得,对于声音噪声的影响,两种方法融合后具有非常强的抗噪性。
对比两种融合方法,串联融合后的识别率会略高于并联融合后的识别率,但并不明显,主要原因是特征串联融合后维度升高,两种特征在更高维的空间中更加易于聚集分类,但是影响并不大。
5.2 图像噪声实验
人脸数据加以0~0.5比例椒盐噪声(如图3(a)(b),噪声比例为0.1的对比),PCA降维至8维,声音数据不做处理,采用串联特征融合方式,支持向量机采用多项式核函数进行试验,结果如图3(c)所示。

图3 图像噪声实验结果
由图3(c)可以看出,在没有声音噪声的情况下,声音识别的准确率非常高,受其影响,融合后的识别率也一直比图像识别率要高。随图像噪声不断增强,图像的识别率逐渐降低,两种特征融合后的识别率也会随之降低,但一直在0.92以上。由此可得,在图像噪声条件下,两种融合方法具有较强的抗噪性和稳定性。
对比两种融合方法,会发现具有相同的变化趋势,都受图像特征的影响而降低。另外,同样会发现串联融合的识别率会略高于并联融合的识别率。
5.3 不同核函数实验
分别采用径向基核函数与Sigmoid核函数进行以上实验进行对比,结果图4所示。
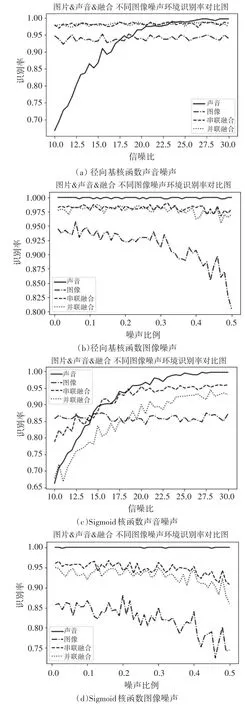
图4 不同核函数实验结果
由图4可以看出:在该两种特征条件下,使用径向基核函数的支持向量机对所有特征的分类识别效果要优于多项式核函数。且在任何一种噪声环境下,融合算法识别率都能达到0.96以上。采用Sigmoid核函数的支持向量机对数据的分类,会导致融合特征受声音特征的影响较大,声音识别率低时,融合识别率也会很低,尤其是并联后的特征,识别率出现大幅降低;融合特征也会受到图像特征的影响,图像噪声增强时,识别率出现一定的下降,串联特征效果优于并联特征的效果。
在本文算法提取的特征下,对比三种核函数的效果,可以得到,径向基核函数的分类识别效果最好,Sigmoid核函数的支持向量机整体分类识别效果要低于另外两种核函数的效果,
6 结语
本文针对单一模态身份识别率易受噪声影响的问题,提出将语音与声音特征进行融合的方法,并结合理论进行了实验验证。经实验证明,在本文选取的两种特征下,串联融合效果要比并联融合效果好一点,同时也存在缺点:由于维度较高,占用存储内存会增大,分类识别时间会较长。但在当今硬件设备下,该影响并不会构成应用上的矛盾。同时也验证了在该特征下,径向基核函数的分类识别效果要优于多项式核函数与Sigmoid核函数。最后,身份特征融合的方法具有较强的抗噪性,并且识别率也较高,可以满足实际的需要,具有一定的实用价值。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
舰船科学技术(2021年12期)2021-03-29
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
劳动保护(2019年3期)2019-05-16
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
饮食科学(2016年7期)2016-07-27
高中生学习·高三版(2016年9期)2016-05-14
