
基于RCNN的问题相似度计算方法*
2021-06-25 09:46杨德志柯显信余其超杨帮华
计算机工程与科学 2021年6期
杨德志,柯显信,余其超,杨帮华
(上海大学机电工程与自动化学院,上海 200444)
1 引言
自然语言处理NLP(Natural Language Processing)技术是当今最前沿的研究热点之一,文本语义相似度计算作为NLP的基础,得到了广泛的关注。文本语义相似度计算,不像机器翻译MT(Machine Translation)、问答系统QA(Question Answering System)等属于端到端(end-to-end)型任务,通常以文本匹配、文本相关性计算的形式,在某应用系统中起核心支撑作用,比如搜索引擎、智能问答、知识检索和信息流推荐等[1]。在检索系统中计算查询项和文档的匹配度、问答系统中计算问题与候选答案的匹配度、对话系统中计算对话和回复的匹配度等,都是基于文本语义相似度计算技术,所以对文本语义相似度计算进行研究具有重要的意义。
然而文本语义相似度计算是一项具有挑战性的任务,由于人类语言学是一门非常深奥的学问,简短的几个字就能包含复杂、微妙的内容,表面看起来不同的问句可以表达非常相似的含义,以至于不仅要从不同的文本处理粒度(字粒度或词粒度)对文本语义进行分析,还要结合具体的语言环境进行更深层次的语义分析。以往的研究局限于使用传统模型进行文本相似度计算,如基于字面匹配的TF_IDF模型、BM25(Best Match)模型和基于语义匹配的潜在语义分析LSA(Latent Semantic Analysis)模型等[2]。但是,这些模型基于关键词信息进行匹配,只能提取到一些浅层的语义信息,并不能提取深层语义信息。近些年来,基于深度学习的方法在文本语义相似度计算中取得了很大的成功,是现在文本语义相似度计算技术的主流研究方法。
当前比较2个问句相似性的方法主要分为3种:孪生网络框架SNF(Siamese Network Framework)、交互型网络框架INF(Interactive Network Framework)和微调预训练语言模型PLM(Pre-trained Language Model)[3]。使用孪生网络框架处理句子相似度任务的相关研究[4,5],将待比较的2个句子通过同一个编码器映射到相同的向量空间中。这种利用孪生网络共享参数的方法可以大幅度降低在线计算耗时,但是没有考虑问句编码向量之间的交互关系,失去了语义焦点,易发生语义漂移,难以衡量词的上下文重要性,往往准确率不佳。使用交互型网络框架处理问句相似度任务的相关研究如ESIM(Enhanced Sequential Inference Model)[6]、BiMPM(Bilateral Multi-Perspective Matching)[7]和DIIN(Densely Interactive Inference Network)[8]等,首先将2个问句用神经网络编码进行语义表示,再通过一些复杂的注意力机制计算文本的词序列之间的相似度构造出交互矩阵,最后进行交互信息的整合。这种方法利用注意力机制来捕捉2个问句编码向量之间交互的信息,能对上下文重要性进行更好的建模,更好地把握语义焦点,但是忽略了句法、句间对照等全局信息。使用微调预训练语言模型的方法处理文本相似度任务也可以取得很好的效果,相关的研究如BERT(Bidirectional Encoder Representations from Transformers)[9]和XLNet(Transformer-XL Network)[10]等, 在大规模语料上训练好的语言模型放到特定领域的目标数据集上微调,这种方法效果显著,但是模型参数庞大,在线上应用时耗时较长。
本文基于Siamese网络结构提出了一种CNN和LSTM结合的RCNN问题相似度计算方法,利用双向的LSTM网络来提取问句的上下文信息;然后使用1D卷积神经网络将词嵌入信息与上下文信息融合;接着用全局最大池化来提取问句的关键特征信息,得到问句的语义特征表示;最后通过余弦相似度计算两问句的语义相似度。实验结果表明,本文提出的RCNN问句相似度计算方法相比于其他使用孪生网络框架计算问句相似度的方法,性能有所提升。
2 网络框架
本文采用孪生网络框架来计算两问句间的语义相似度,首先将两问句以序列的形式输入到网络中,然后通过RCNN模型完成问句的语义编码,最后利用余弦相似度来度量两问句之间的语义相似度,网络框架如图1所示

Figure 1 Siamese network structure based on RCNN
2.1 输入层与嵌入层
输入层对2个问句进行预处理,包括词元化、去除标点、拼写矫正、缩写改写和删除停止词。预处理后得到干净的词序列,然后将问句整理成相同的长度L,长度不足在句首补零,问句长的截断。
嵌入层将输入文本在低维空间进行向量化表示。即通过一个隐藏层,将One-hot编码的词投影到一个低维空间中,在指定维度中编码语义特征。嵌入层将预处理后的词序列在低维空间进行向量化表示。即通过一个隐藏层,将one-hot编码的词向量投影到一个低维空间中,在指定维度中编码语义特征。本文对比了谷歌开源的word2vec预训练的词向量[11]、斯坦福开源的GloVe预训练的词向量[12]和本文基于实验数据集训练的词向量3种不同词向量表示方式对实验效果的影响。实验结果表明,基于实验数据集训练的词向量表示的实验效果更好。
本文使用的词嵌入模型是word2vec,训练方法是Skip_gram,向量维度为300,窗口大小为5,采用负采样优化算法进行加速训练。
2.2 RCNN层
循环神经网络是处理序列问题最常用、最有效的方法。通过隐藏层节点之间的相互连接,将前面的信息记忆应用到当前的输出中,以实现捕捉上下文信息的目的。但是,训练过程中会出现梯度消失和梯度爆炸的问题,因此只能捕捉少量的上下文信息。LSTM网络利用不同的函数处理隐藏层的状态,实现对重要信息的筛选,能很好地解决梯度问题,捕捉更多的上下文信息,是当前文本处理的主流方法。
卷积神经网络通过固定大小的卷积核提取文本局部信息,用池化层减少数据处理量并保留关键的信息。因为卷积核是一个固定的窗口,所以同时可能会丢失一些重要的信息,虽然可以通过多个不同大小的窗口来弥补信息缺失,但是会增大计算量,并且不能捕捉上下文信息。
本文方法结合LSTM网络能捕捉更多上下文信息和CNN网络能保留关键信息的特点,首先利用双向LSTM网络提取单词的上下文信息;然后利用1D卷积神经网络将上下文信息与词嵌入信息进行信息融合;最后通过全局最大池化提取关键信息。具体实现过程如下所示:
(1)双向LSTM网络提取上下文信息。
通过嵌入层得到等长的问句序列S=(w1,w2,…,wL),其中,L为问句词序列长度,wi,i∈[1,L]表示问句中第i个词。
用cL(wi)表示词wi左侧的上下文信息,cR(wi)表示词wi右侧的上下文信息,cL(wi)的特征表示是通过前向单层的LSTM训练得到的,cR(wi)的特征表示是通过后向单层的LSTM训练得到的,如式(1)和式(2)所示:
cL(wi)=tanh(WL*cL(wi-1)+WSL*e(wi-1))
(1)
cR(wi)=tanh(WR*cR(wi-1)+WSR*e(wi+1))
(2)
其中,e(wi-1)表示单词wi-1的词嵌入,cL(wi-1)是单词wi-1的左侧上下文信息向量表示,WL是将上一个上下文信息向量转化成下一个上下文信息向量的转化矩阵,WSL是将当前单词向量与下一个单词的左侧上下文向量进行结合的矩阵,cR(wi)的计算反之。实现过程如图2所示。

Figure 2 Processing of bidirectional LSTM extracts context information
其中,通过双向LSTM网络提取上下文信息之后,将上下文信息与词嵌入信息进行拼接得到此时问句词序列中第i个词wi的语义表示为[cL(wi);e(wi);cR(wi)]。
(2) 1D卷积进行信息融合。
接着利用1D卷积神经网络对拼接后的词序列语义表示进行信息融合,其计算过程如式(3)所示:
yi=CNN(xi),i∈[1,L]
(3)
其中,yi表示1D卷积处理后xi对应的特征表示,具体处理过程如图3所示。
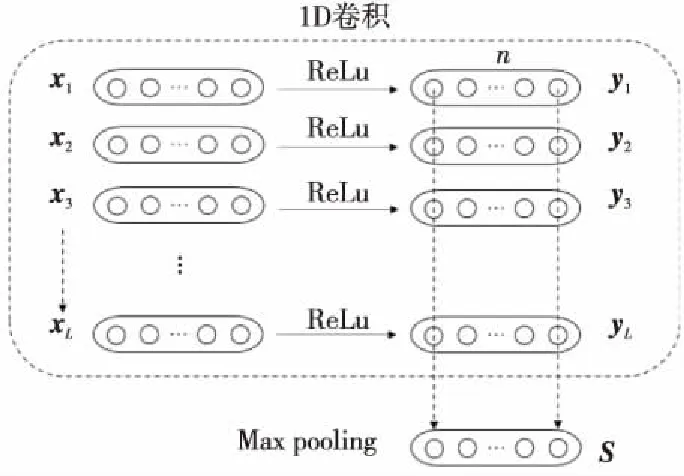
Figure 3 1D convolution and global maximum pooling
图3中,n为卷积核的个数。
(3)最大池化提取关键特征信息。
为提取问句中的关键特征信息,本文对比了平均池化与最大池化,实验结果表明最大池化效果更优。池化层采用的是全局最大池化,即取每个序列特征在单个维度上的最大值,提取出关键特征信息,即得到整个句子的语义特征表示。具体计算过程如式(4)所示:
(4)

2.3 相似度计算层
得到问句对的语义表示后,在问句的语义空间中计算2个向量的相似度,从而判断2个文本是否语义相同。本文选取余弦相似度作为评价函数,如式(5)所示:
(5)
其中,sL和sR是问句对的语义向量,n表示语义向量的维度。相似度的值域为[0,1]。
3 实验
3.1 数据集及评价指标
本文选取Quora Question Pairs数据集[13]进行验证与测试,数据来源于Quora网站,包含404 351个问句对,具有相同语义的2个问句的标签为1,反之为0。通过分析数据集可知,问句对中具有相同语义比例的有36.92%,单词个数为68 469,98%的问句长度分布在50以下,所以本文取问句统一长度L=50。
评价指标采用准确率(Accuracy)和F1-score,F1-score的计算如式(6)所示:
(6)
其中,P表示精确度(Precision),R表示召回率(Recall)。
3.2 实验参数设置
为了验证本文提出的问题相似度计算方法的有效性,分别与常见的几种使用孪生网络框架的方法进行了对比实验。
(1)对比方法参数设置。
基于CLSTM网络[14]的方法:卷积核大小分别设置为1,2,3,滤波器数量设置为256,每一个卷积层后接单层的LSTM网络,隐藏层节点个数设置为256,只保留最终的语义向量,将3个网络的语义向量拼接,经过全连接层,全连接节点数设置为256。
LSTM与CNN组合网络[15]:CNN网络卷积核大小设置为3,卷积核个数设置为256,采用全局最大池化;LSTM网络隐节点个数设置为256,只保留最终的语义特征向量;然后将2个网络的语义特征向量进行拼接传入全连接层,全连接层节点数设置为256。
(2)本文方法参数设置。
词嵌入是基于实验数据集训练的300维向量表示,循环网络采用单层LSTM,隐藏层节点数量设置为256,激活函数用tanh函数;1D卷积神经网络的卷积核个数设置为128,激活函数为ReLU函数优化算法选取Adam(Adaptive moment estimation)[16],学习率为0.01,损失函数用均方误差MSE(Mean Squared Error),训练过程批处理参数设置为512,训练轮数设置为6。
3.3 实验结果与分析
将数据集按照8∶2比例分割成训练集与测试集,将训练集按照9∶1分出验证集。不同方法对比实验的结果如表1所示。

Table 1 Experimental results of different methods
从表1的序号1,2和3,4可以看出,使用多视角的CNN或LSTM方法比使用单一的CNN或LSTM方法的准确率要高;从序号1,3可以看出,在本实验的数据集上采用LSTM网络的方法表现能力更强;从序号1,2,3,4,7可以看出,本文提出的RCNN问题相似度计算方法的准确率是最高的,准确率为83.57%。所以,使用CNN网络和LSTM网络结合的方法可以提取更多的文本语义特征信息,对文本的表示能力更强。
另外,本文对比了CNN网络与LSTM网络不同的结合方式对实验效果的影响,分别使用串联和并联的结合方式进行了实验对比。从序号5,6,7可以看出,本文采用的先使用双向LSTM提取上下文信息并与词嵌入信息结合,然后使用1D卷积进行信息融合的方式相较于串联和并联的结合方式具有更好的实验效果。同时,在实验中发现1D卷积进行特征信息融合还起到了降维的作用,使得本文提出的方法在使用时具有更好的实时性。
4 结束语
本文基于Siamese网络框架,提出了一种基于RCNN的问题相似度计算方法,首先利用双向的LSTM网络提取问句的上下文信息;然后使用1D卷积将上下文信息和词嵌入信息进行融合;接着采用全局最大池化提取问句的关键信息,完成问句的语义特征表示;最后通过余弦相似度计算两问句在语义空间上的相似度。相比于其他使用Siamese网络框架的文本相似度计算方法在Quora Question Pairs数据集的表现,本文提出的方法具有较高的准确率和F1-score。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
软件导刊(2022年3期)2022-03-25
新一代信息技术(2021年22期)2021-12-29
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
