
基于深度学习的道路表面裂缝检测方法
2021-06-25 11:38张世瑶贺玉彬周新志
科学技术与工程 2021年15期
张世瑶, 贺玉彬, 周新志*
(1.四川大学电子信息学院, 成都 610065; 2.国能大渡河大数据服务有限公司, 成都 610041)
随着中国基础建设的大力践行,道路建设发展迅速,目前中国公路通车总里程已经位居世界前列[1]。在快速进行道路建设的同时,道路得高效保养、维护以及安全性检测成为了一项亟待解决得问题。其中裂缝作为道路的常见病害,对道路安全构成了潜在的威胁,同时在裂缝早期做好及时的健康评测能大幅减少道路维护成本,延长道路使用寿命,保障行车安全,具有重要的现实意义。传统的裂缝检测主要依靠人工使用度量工具进行测量,耗费大量人力物力,同时存在劳动强度大、效率低下、测量结果存在人的主观误差等问题,因此对裂缝进行准确、高效、自动地检测成为了当下研究的热点。
目前中外学者对道路表面裂缝检测做了许多的研究,如基于传统的图像处理方法进行道路表面裂缝检测,此类研究主要方向有基于形态学的识别与灰度差异的阈值分割[2-6],但这些研究中存在对于复杂背景下或裂缝与背景灰度差异小的场景下只能给出裂缝的大体位置, 准确度不高, 易受背景杂波影响, 误检和漏检率较高。随着计算机技术的发展,机器学习技术被提出,一些基于机器学习技术实现对裂缝的自动提取的研究被提出,如使用K均值进行裂缝提取[7-9],使用布谷鸟搜索算法优化K均值的裂缝提取算法[10],使用聚类算法的桥梁裂缝提取[11],此类算法相较于传统的图像处理的方法,精度有所提升,但其本质仍然是对图像的灰度特征的提取,使用的图像特征有限,容易受到杂物、油污、阴影及光照等因素影响,且检测速度慢,对设备硬件性能要求高。近些年随着深度学习技术在图像识别领域的广泛的应用,像素级的目标检测的方法上取得了比较大的进展。一系列优秀的网络模型被提出,例如FCN(fully convolutional network)、U-Net、NestNet、U-Net++等卷积神经网络[12-16],它们在医疗图像分割上都表现处理良好的分割效果,同时被应用到多个领域。在裂缝检测领域,如基于U-Net的桥梁裂缝检测[17],基于FCN的大坝裂缝检测[18],基于DenseNet的隧道裂缝检测[19]等,这些研究表明基于深度学习的裂缝检测方法可以在复杂背景下仍然能取得很好的分割效果,较好地保留了裂缝的纹路信息,并具有更好的鲁棒性。因此深度学习在裂缝检测领域具有极大的应用前景,值得继续深入研究。
在道路表面裂缝检测的研究中,如基于Faster R-CNN 的道路裂缝识别[20],BP(back propagation)改进算法的路面裂缝检测[21],此类方法侧重于对于裂缝位置的标记或者分类,未实现对裂缝的分割提取以及定量衡量裂缝;此外基于张量投票法的裂缝分割[22],此类研究实现了裂缝像素级的分割,可以实现对于裂缝像素尺寸的计算,但未转化为实际的物理尺寸,缺乏现实意义。
针对现有的道路表面裂缝检测研究存在的问题,现提出一种基于卷积神经网络的像素级道路表面裂缝检测方法。
1 图像数据获取
对于图像数据的获取,为了计算得到裂缝的实际物理尺寸,在采集拍摄裂缝图像的样本的同时,需要得到像素尺寸与实际物理尺寸的比例尺。采用放置绿色标志物在裂缝旁的方式,每一张样本图像,都会包含裂缝与标志物块。绿色的正方形物块方便于分割出标志物的二值化图像,通过标志物实际面积与像素面积比就可以较为简单的计算出比例尺。
共计拍摄得到36张原始裂缝图像,图像大小为1 280×1 711,并对其进行像素级的标注,对每一张原始裂缝图像分成24张320×320大小的子块,按照2∶1划分为训练数据集和测试数据集,样本统计情况如表1所示。部分样本示例如图1所示。

表1 样本数量统计

图1 数据集样例Fig.1 sample of dataset
2 系统结构
本文所提系统的结构可划分为裂缝分割模块与比例尺计算模块,系统结构如图2所示。

图2 系统结构Fig.2 System structure
在裂缝分割模块中,输入图像尺寸会影响卷积神经网络中隐藏层的参数数量,图像尺寸越大对显存和内存需求也越大,为了降低系统对计算机设备硬件资源的消耗,以及对设备硬件性能的要求,将原始的大尺寸(1 280×1 711)裂缝图像和本文标注图像划分为小尺寸(320×320)的子块图像作为数据集。采用卷积神经网络模型对裂缝进行分割提取,各个子块图像经过卷积神经网络模型得到子块区域像素分割结果的概率值,对于子块中存在的重叠区域,本文采用分割结果的概率平均的策略对子块进行拼接合成,最终得到大尺寸图像的裂缝分割结果。
在比例尺计算模块中,对于绿色标志物采用(HSVCC Hue, Saturation, Value)颜色模型进行颜色特征的分割,HSV颜色型对颜色特征十分敏感,能快速且准确地分割出绿色标志物。通过计算标志物的像素数与标志物实际物理面积的比值即可得到像素比例尺。
2.1 裂缝图像分割方法
基于深度学习的主要像素级图像分割模型有FCN、U-Net、NestNet、U-Net++等,此类卷积神经网络模型均由编码网络和解码网络组成,在编码网络中,卷积层用来提取输入图像的特征,池化层用来减小特征图像大小,降低运算量并且提高网络的鲁棒性。在解码网络中,使用反卷积层将特征映射并且恢复到原始图像的大小,并输出预测结果。编码网络和解码网络的高度对称性,既利用了稀疏的特征映射,又利用了密集的特征映射。
在本文所提系统中卷积神经网络的分割精度很大程度决定了最终的测量精度,因此对于神经网络模型的选择与优化对于整个系统尤为重要。选用公共数据集CRACK500对FCN、U-Net、NestNet和U-Net++卷积神经网络进行训练与测试,并且通过Precision、Recall、IoU、F1-score对网络模型进行评估,将训练好的模型使用本文标注的数据集再次进行训练与测试,根据测试结果选择较优的模型,作为系统中的裂缝分割模型。
精确率(Precision)就是被准确分类为正类的样本数与所有被分类为正类的样本数之比,即

(1)
式(1)中:TP(true positive)表示将正样本预测为正样本;FP(false positive)表示将负样本预测为正样本;FN(false negative)表示将正样本预测为负样本。
F1分数(F1-score)同时考虑了精确率和召回率(Recall),是精确率和召回率的调和平均数,表示精确率与召回率同样重要。
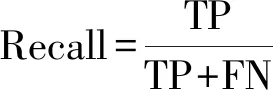
(2)
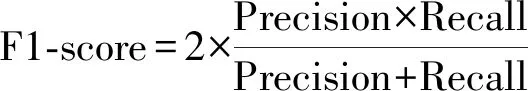
(3)
交并比(intersection-over-union, IoU)是指实际类别样本和预测类别样本的交集和并集之比,即分类准确的正类样本数和分类准确的正类样本数与被错分类为负类的正类样本数以及被错分类为正类的负类之和的比值。

(4)
使用VGG16作为这些网络的backbone,Focal Loss为loss函数得到结果如表2所示。
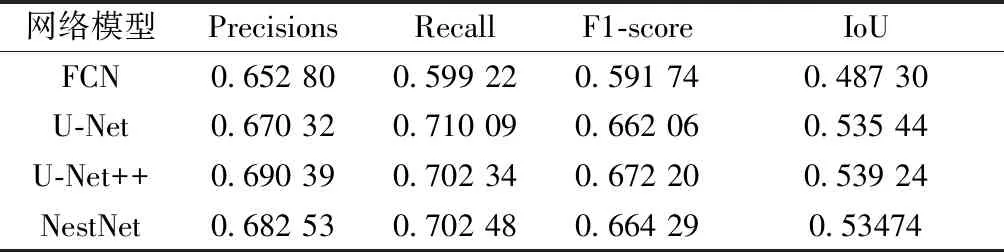
表2 公共数据集CRACK500测试结果
在此基础上进行迁移学习,使用本文所标注的数据集对模型继续进行训练。使用测试集对训练得到的网络模型进行测试得到测试结果如表3所示。
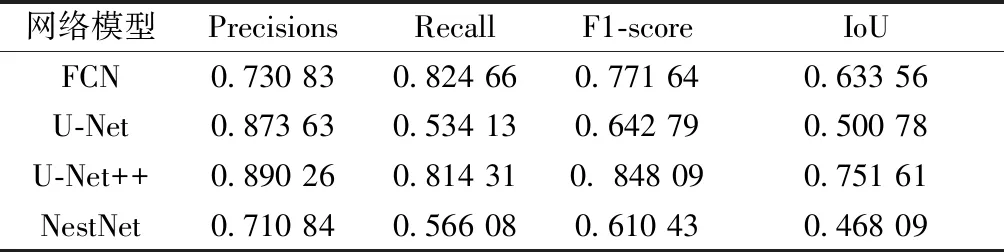
表3 本文数据集测试结果
根据实验结果可以发现,U-Net++在CRACK500公共数据集以及本文标注的数据集的实验结果都相较于其他模型拥有更好的数据指标,表明U-Net++模型能克服数据集变化所引入的干扰,如光照、遮挡以及路面材料不同等干扰,反映了U-Nnet++相较于其他模型具有更好的鲁棒性,故选用U-Net++作为图像分割网络,来提取裂缝图像。裂缝分割效果如图3所示。

图3 裂缝图像分割结果Fig.3 Crack image segmentation results
2.2 标志物图像分割方法
通过标志物的颜色特征来对标志物进行提取,目前的颜色模型可分为面向硬件的与面向对象的颜色模型。其中面向硬件的颜色模型适合计算机对图像数据的存储和显示系统的显示,直观且容易理解。面向对象的颜色模型,如HSV是根据颜色的直观特性来创建的一种颜色模型,会从颜色的类别、颜色的深浅、明暗方面来获取信息,所以在HSV颜色空间中,其对颜色的表述更加符合人类对一种颜色的认知与判定。因此本文采用HSV颜色模型对标志物进行分割。标志物分割效果如图4所示。

图4 标志物分割结果Fig.4 Marker segmentation result
2.3 分割结果优化
分别得到裂缝与标志物的分割结果后,由于所采用的分割方法为像素级的分割,也就是对每个像素进行判定分割,分割错误的像素会形成孔洞或者背景杂波。如图5(a)和图6(a)所示,分割结果背景中存在一些散落的背景杂波,分割对象内部也存在一些孔洞。然而实际的裂缝和标志物在空间上具有连续的特征,这些背景杂波和孔洞是由于光照、遮挡等干扰因素所导致的错误分割,因此需要对分割后的图像进行优化处理,去除背景杂波和孔洞。
根据分割结果可以看出背景杂波与孔洞在空间上具有连续性差并且其像素面积较小等特征。依据这些特征采用基于计算机图像处理技术的形态学处理方法中的开操作和闭操作[23]来进行优化处理。采用5×5大小的窗,对分割后的图像先进行开操作处理,消除细小、孤立的背景杂波,再进行闭操作处理填补分割对象内部孔洞。如图5(b)和图6(b)所示,采用形态学的处理方法后取得了较好的优化效果。

图5 裂缝图像分割结果优化Fig.5 Optimization of crack image segmentation results

图6 标志物分割结果优化Fig.6 Optimization of marker segmentation results
3 裂缝量化计算
3.1 量化方法
分别得到裂缝与标志物的二值图像后,需要对裂缝进行定量的评估,采用计算裂缝的面积、长度和平均宽度的方式来定量评估裂缝。对于像素比例尺的计算,采用的标志物大小为296 mm×227 mm的绿色矩形卡纸,通过计算实际标志物面积与标志物二值图像中的像素面积S的比值得到像素比例尺。计算公式为
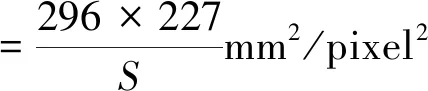
(5)
分别统计裂缝像素数量与骨架像素数量,得到裂缝像素面积与裂缝像素长度,再与比例尺相乘就可以得到实际面积与长度,平均宽度为面积与裂缝长度的比值。
采用K3M[24]算法提取裂缝骨架,提取效果如图7所示 。

图7 骨架提取Fig.7 Skeleton extraction
3.2 结果
为了验证本文测量方法的性能,在不考虑因人为标记数据集存在的误差情况下,以人工标记的裂缝图像尺寸为真实的物理尺寸。
本文所提系统在测试集的测试结果如表4所示,测试结果表明本文的裂缝检测系统具有较高的精度,其中测试样本面积测量平均精度达到0.93,长度测量平均精度0.92,平均宽度测量精度0.89。详细样本误差占比情况如图8所示。
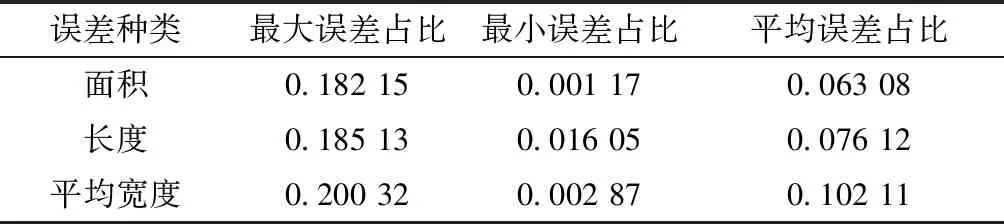
表4 各项指标结果

图8 误差占比柱状图Fig.8 Error percentage histogram
4 结论
针对现有道路检测中存在的精度低,未能定量衡量裂缝等问题,文中构建的基于深度学习的道路表面裂缝检测系统,分别通过U-Net++卷积神经网络模型与HSV颜色模型分割得到像素级的裂缝分割图像与像素比例尺,使用裂缝面积、长度、平均宽度等指标对裂缝量化测量,并转化为实际的物理尺寸。经实验验证本文所提方法对裂缝面积测量准确率达到93%,长度测量准确率达到92%,平均宽度测量准确率达到89%,拥有较高的测量精度,并且大幅提高了裂缝检测效率。
猜你喜欢
中国现代医生(2022年21期)2022-08-22
小哥白尼(军事科学)(2022年2期)2022-05-25
健康体检与管理(2022年2期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
天津医科大学学报(2021年2期)2021-03-29
电子制作(2019年13期)2020-01-14
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
CHIP新电脑(2016年3期)2016-03-10
