
督促司乘双方双重履约的博弈模型和奖惩机制
2021-06-24 06:24石超峰
科技和产业 2021年6期
罗 娇,石超峰
(1.重庆交通大学 交通运输学院,重庆 400074;2.重庆交通大学 经济与管理学院,重庆 400074)
根据中国互联网络信息中心(CNNIC)的统计,截至2020年6月,中国网约车用户规模达到3.4亿,日均完成网约车订单超过2 000万单。网约车平台每天要完成上千万的订单的派单工作,有一部分乘客与司机会选择违约,其根本原因是网约车司机与乘客选择违约所获得的利益要比履约所获得的利益要大,这不仅浪费了平台的运力还降低了平台的派单效率。那么如何促进司机与乘客的履约行为呢?就是要保证违约带来的收益要小于履约所带来的收益,比如对选择履约的一方进行奖励(如补贴、减免车费等方式);对于选择违约的司机或乘客,平台则对其进行一定的惩罚措施(如罚款、降低其派单权重等方式),并对被违约的一方进行补偿(如补贴、免单等方式),这在一定程度上可以抑制双方的违约行为,且当奖惩力度足够大时,会有双方同时选择履约策略的理想状态出现。
1973年,Smith和Price[1]首次提出演化稳定策略(evolutionary stable strategy,ESS)。1978年Taylor和Jonker[2]研究稳定演化均衡和动力学之间的关系,其标志着演化博弈论的正式诞生。Yamamoto和Okada[3]通过演化博弈的复制动态模型回答了网约车中顺风车的运营问题。而国内学者直到21世纪后才开始逐渐关注演化博弈。谢识予[4]论述了演化博弈的思想、理论方法、意义和发展前景,这对后面的学者就演化博弈展开研究打下坚实的基础。卢珂等[5]在系统分析网约车出行市场多方主体构成的基础上构建了网约车出行市场规制的三方演化博弈模型。毛文娟等[6]将买方纳入平台社会责任治理体系中,通过构建平台、卖方与买方三者的演化博弈模型,深入挖掘平台“类政府”的特有优势,充分发挥平台的社会资源配置能力,探究如何实现平台内各主体之间的社会责任良性互动。金振广等[7]以网约车平台的补贴政策和乘客选择的服务类型为研究对象,建立了演化博弈模型,并进行了相应的演化路径分析。雷丽彩等[8]建立了新政实施背景下网约车平台和司机间的演化博弈模型,并对其博弈行为演化过程及演化稳定策略进行探讨。王章岑[9]从公共选择理论与演化博弈视角出发,在理论与现实分析的基础上,先后构造了网约车平台公司与平台司机之间的演化博弈,以及网约车平台公司内部的演化博弈等两组演化博弈模型;最后,从政府角度出发,根据事前、事中、事后3个监管阶段分别为网约车行业监管提出了策略建议。王人仙[10]构建了网约车平台与司机演化博弈模型,然后又引入了政府部门,构建了三方博弈模型,并运用系统动力学理论构建动力学模型,最后进行了网约车监管的SD模拟仿真。吕煜昊[11]根据演化博弈论建立出行者与网约车平台、出行者与政府、网约车平台与政府之间的3个模型,并针对政府、网约车平台和出行者提出相应的政策建议。贺钰淇[12]以网约车平台的政策规制为主要研究内容构建了政府与网约车平台的二维演化博弈模型。高尚[13]从网约车平台管理角度构造4个补偿-惩罚控制变量,运用演化博弈的分析方法,对如何规避网约车司机和乘客的双重违约行为进行探讨。
基于上述文献分析可以发现,当前研究多集中于对网约车行业的监管和规制两个方面展开,仅有一篇文献是利用司机与乘客间的演化博弈来规避司乘双方的违约行为,没有通过平台、司机与乘客的三方演化博弈来督促司机与乘客的双重履约行为的研究。但它又有其现实意义:一方面司乘双方的双重履约行为可以提高网约车平台的利益,另一方面,司乘双方的利益也可通过网约车平台的奖惩机制来保障。最后通过平台的奖惩机制来促进司乘双方的履约行为。
1 模型构建
1.1 问题描述与假设
促进司乘双方双重履约的博弈模型中博弈参与主体为网约车平台、司机与乘客。
假设1:假设博弈参与主体网约车平台、网约车司机、乘客均具有有限理性。参与人的理性会根据博弈局势的变化而不断演化,他们只能追求在他们的能力范围内的有限理性,在策略上并不能找到最优策略。
假设2:平台实行奖惩机制所需的成本Q,此处成本只包含对乘客、司机的履约/违约进行奖励、惩罚与补偿的成本;与平台实行奖惩机制对平台的有利影响W二者之间必须满足W>Q,否则平台将没有动力选择实行奖惩机制;平台不实行奖惩机制所带来的不利影响为K,同样二者之间必须满足W>K。乘客与司机同时违约时,平台不会对任何一方进行补偿,但仍会对司乘双方的违约行为进行惩罚,且此时双方的收益均为0,这样可以增加司乘双方的违约成本,从而降低双方违约的概率。
假设3:网约车平台对履约司机的奖励为T,司机履约所需付出的成本为N,司机的正常收益为D(乘客选择履约后网约车才有这个收益),且二者之间需满足T+D>N,否则司机将没有履约的动力;对于乘客而言网约车平台对履约乘客的奖励为t,乘客履约所需付出的成本为n,乘客在完成订单后的收益为d,同样这二者之间需满足t+d>n,否则乘客将没有履约的动力。
假设4:司机/乘客只会在违约收益大于履约收益时才会选择违约。
本文涉及的主要参数见表1。
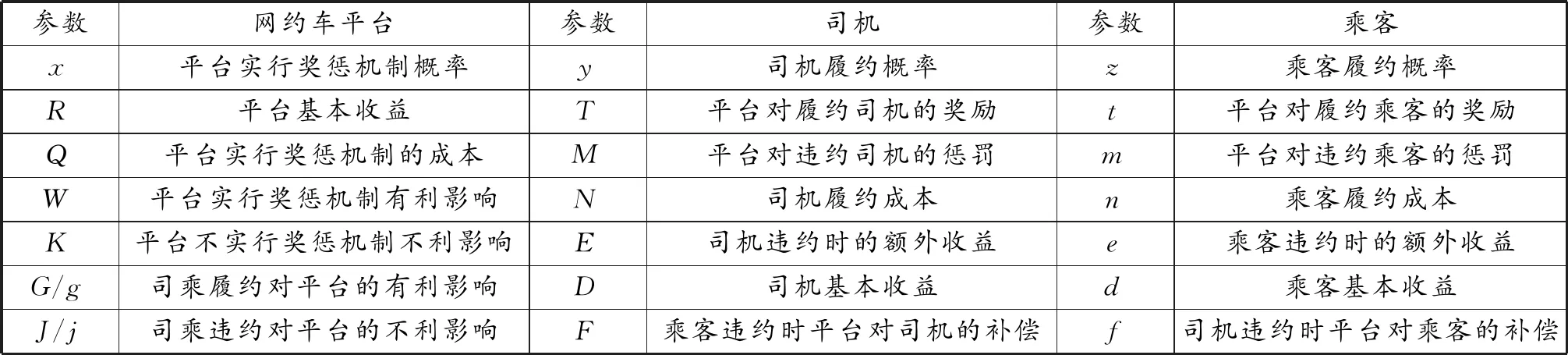
表1 主要参数
1.2 平台、司机与乘客三方博弈支付矩阵
上述假设以及参数情况可以得到网约车平台、司机和乘客博弈的支付矩阵见表2。
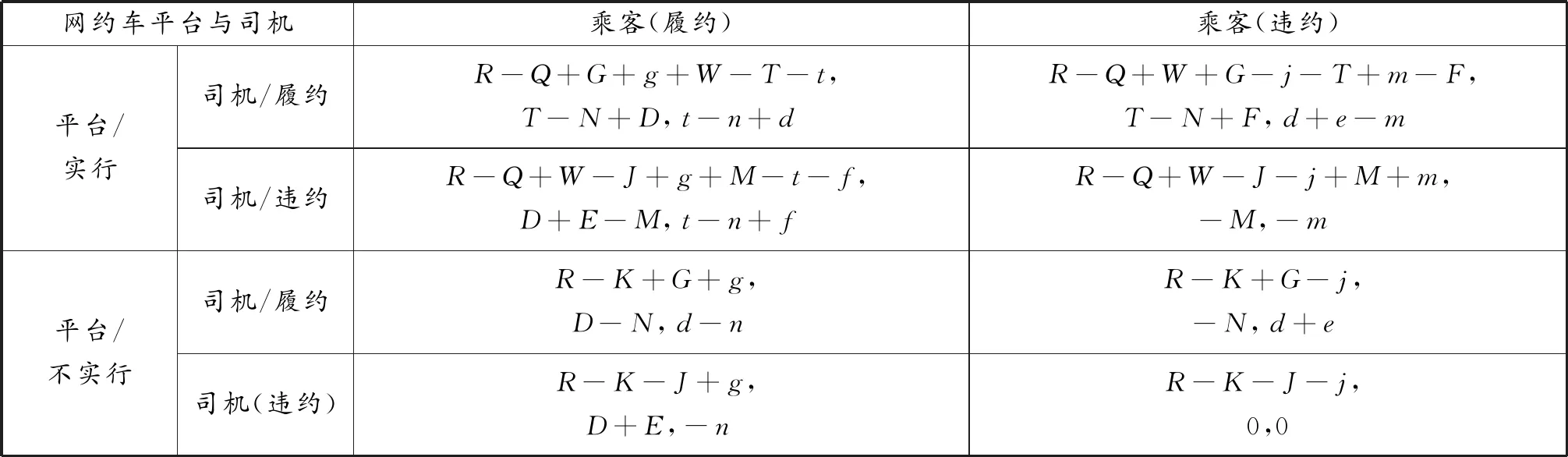
表2 网约车平台、司机和乘客三方的支付矩阵
2 模型稳定性分析
假设网约车平台选择“实行奖惩机制”策略的概率为x,选择“不实行奖惩机制”策略的概率为1-x;网约车司机选择“履约”策略的概率为y,选择“违约”策略的概率为1-y;乘客选择“履约”策略的概率为z,选择“违约”策略的概率为1-z。
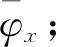
2.1 网约车平台演化路径及稳定性分析
φx1=yz(R-Q+G+g+W-T-t)+y(1-z)(R-Q+W+G-j-T+m-F)+(1-y)z(R-Q+W-J+g+M-t-f)+(1-y)(1-z)(R-Q+W-J-j+M+m)
(1)
φx2=yz(R-K+G+g)+y(1-z)(R-K+G-j)+(1-y)z(R-K-J+g)+(1-y)(1-z)(R-K-J-j)
(2)
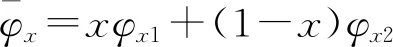
(3)
网约车平台选择实行奖惩机制策略的复制动态方程为
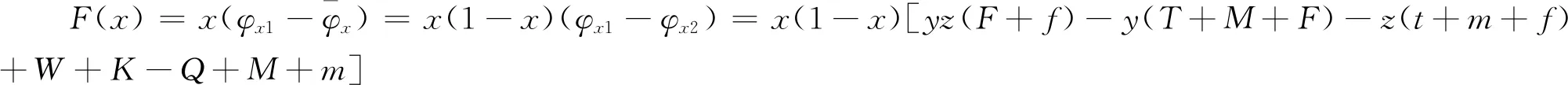
(4)
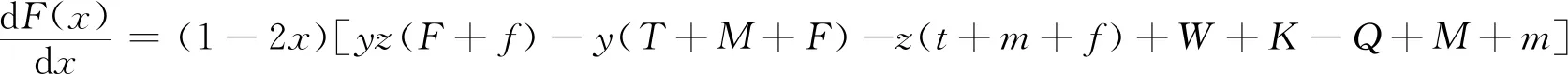
(5)
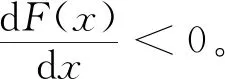
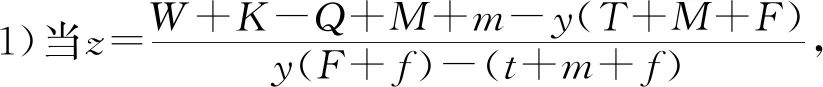
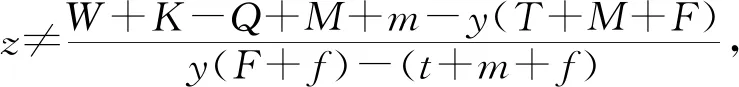
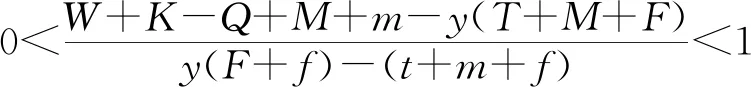
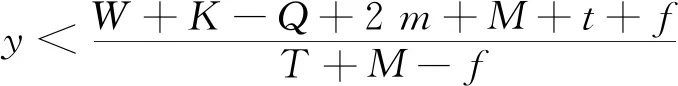
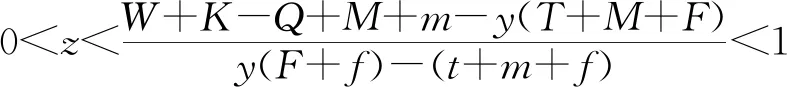
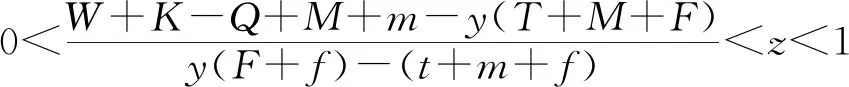
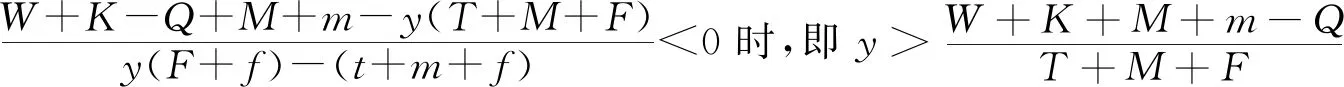
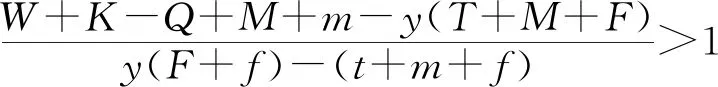
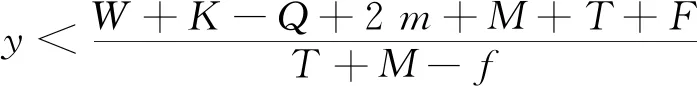
2.2 司机演化路径及稳定性分析
ωy1=xz(T-N+D)+x(1-z)(T-N+F)+(1-x)z(D-N)+(1-x)(1-z)(-N)
(6)
ωy2=xz(D+E-M)+x(1-z)(-M)+(1-x)z(D+E)+(1-x)(1-z)
(7)
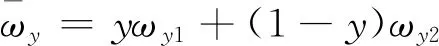
(8)
网约车司机选择履约策略的复制动态方程为
H(y)=y(ωy1-)=y(1-y)(ωy1-ωy2)=y(1-y)[-xzF+x(T+M+F)-zE-N]
(9)
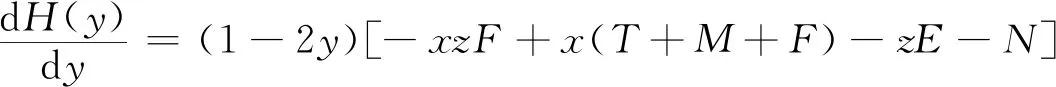
(10)
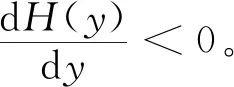
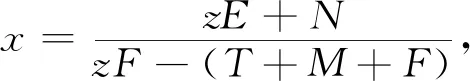
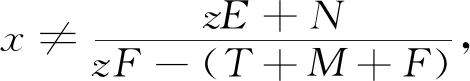
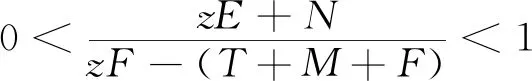
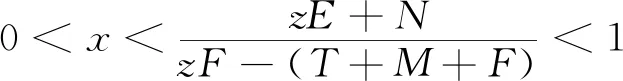
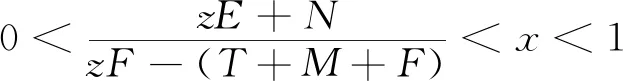
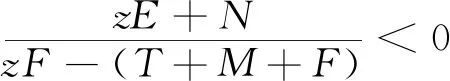
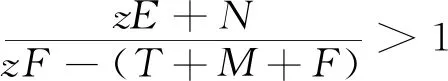
2.3 乘客演化路径及稳定性分析
τz1=xy(t-n+d)+x(1-y)(t-n+f)+(1-x)y(d-n)+(1-x)(1-y)(-n)
(11)
τz2=xy(d+e-m)+x(1-y)(-m)+(1-x)y(d+e)+(1-x)(1-y)
(12)
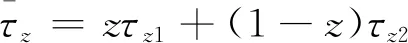
(13)
乘客选择履约策略的复制动态方程为
P(z)=z(ωy1-)=z(1-z)(ωy1-ωy2)=z(1-z)[-xyf+x(t+m+f)-ye-n]
(14)
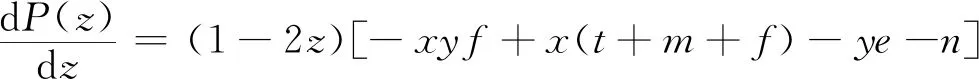
(15)
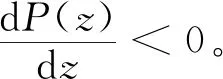
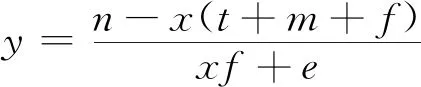
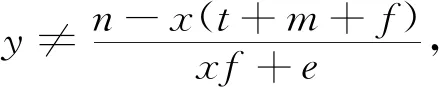
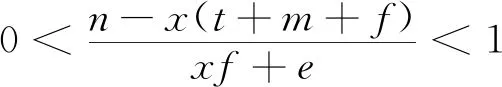
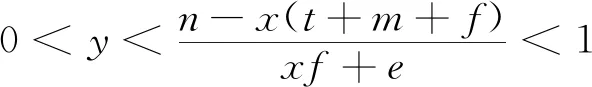
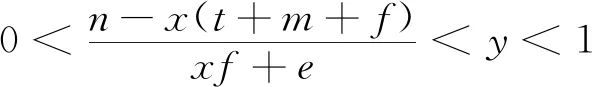
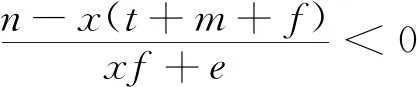
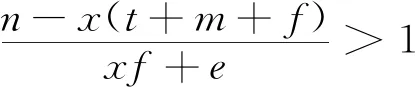
2.4 三方共同作用的演化策略稳定性分析
由李雅普诺夫稳定性理论可知,系统在均衡点的渐进稳定性可以通过分析雅克比矩阵的特征值的符号来判断,而该系统的雅可比矩阵可由3个博弈主体的复制动态方程得到,即
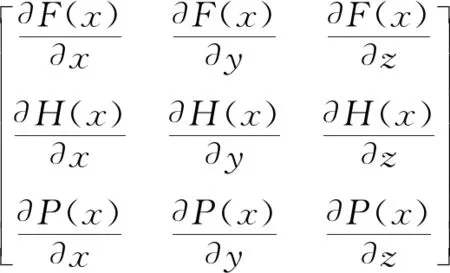
(16)
式中:
F)-z(t+m+f)+K+W-Q+M+m]
(17)
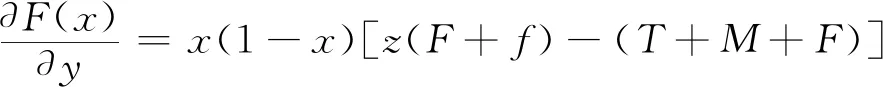
(18)
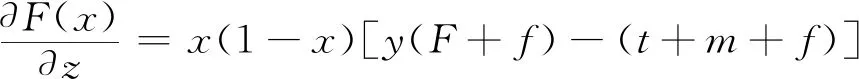
(19)
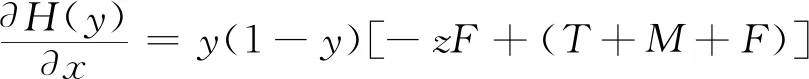
(20)
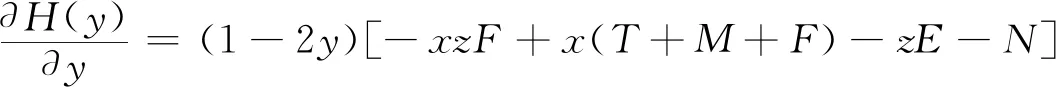
(21)
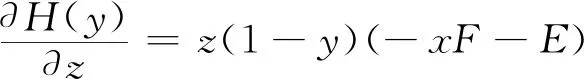
(22)
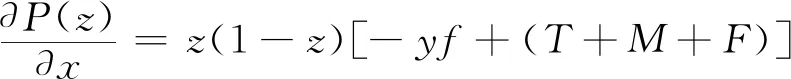
(23)
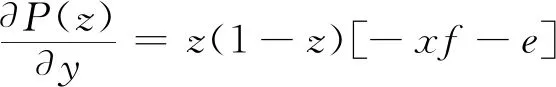
(24)
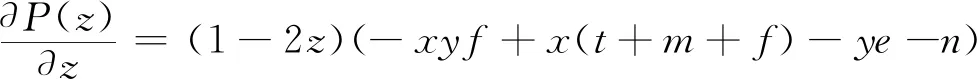
(25)
多群体演化博弈复制动态系统的渐进稳定解一定是严格的纳什均衡[14],只需要分析E1(1,1,1)、E2(1,1,0)、E3(1,0,1)、E4(0,1,1)、E5(1,0,0)、E6(0,1,0)、E7(0,0,1)、E8(0,0,0)这8个均衡点,因为其他的均不是渐进稳定状态。将上述8个点分别代入雅克比矩阵,求解其矩阵特征值,结果见表3。

表3 雅克比矩阵的特征值
由李雅普诺夫第一法则可知,可以根据雅可比矩阵的稳定性判定方法对均衡点的渐进稳定性进行分析,因为本文想要达到的目的是通过网约车平台的奖惩机制促进司机与乘客的双重履约行为,所以主要对均衡点E1(1,1,1)的稳定性进行分析,由李雅普诺夫第一法则可知,若需满足E1(1,1,1)为稳定点则需同时满足
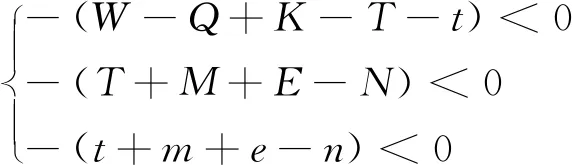
(26)
当式(26)成立时,网约车平台倾向于选择“实行奖惩机制”策略,司机倾向于选择“履约”策略、乘客倾向于选择“履约”策略。
3 算例仿真分析
假定平台实行奖惩机制给平台带来的有利影响W=10,平台不实行奖惩机制给平台带来的不利影响K=6,平台实行奖惩机制所需的成本Q=3,平台对履约司机/乘客的奖励(T,t∈[0,2])相等,T=t=1.8表示强奖励,T=t=0.5表示弱奖励;平台对违约司机/乘客的惩罚(M,m∈[0,2])相等,M=m=1.8表示强惩罚,M=m=0.5表示弱惩罚;司机履约所需付出的成本N=2,乘客履约所需付出的成本n=2,司机违约时的额外收益E=1,乘客违约时的额外收益e=1,司机的正常收益D=6,乘客的正常收益d=6,乘客/司机违约时平台对司机/乘客的补偿(F,f∈[0,1])相等,F=f=0.8表示强补偿,F=f=0.3表示弱补偿。
首先令网约车平台的实行奖惩机制的初始策略x=0.1,然后随机给定5组y与z的值,即司机和乘客履约的概率,由此分析司机和乘客选择的策略对网约车平台演化策略的影响,如图1所示。通过分析可知,当网约车平台的初始策略为0.1时,随着时间的变化,网约车平台的演化稳定策略均会收敛于1,即网约车平台会采取“实行奖惩机制”策略。
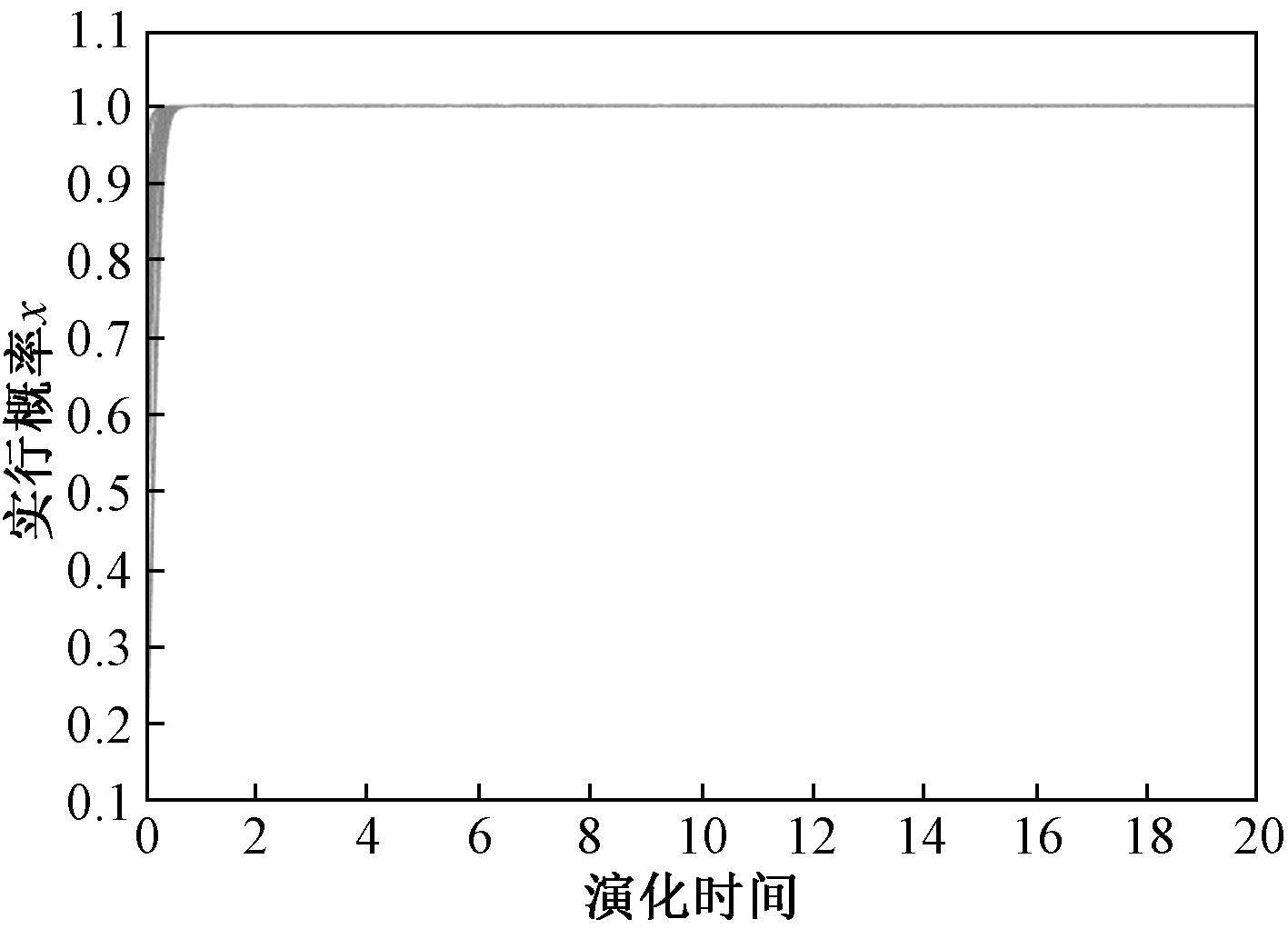
图1 网约车平台演化策略分析
司机与乘客的演化策略与网约车平台的奖惩力度有关,分为强奖励、强惩罚和强补偿;强奖励、强惩罚和弱补偿;强奖励、弱惩罚和强补偿;弱奖励、强惩罚和强补偿;强奖励、弱惩罚和弱补偿;弱奖励、强惩罚和弱补偿;弱奖励、弱惩罚和强补偿;弱奖励、弱惩罚和弱补偿等8种情形。利用MATLAB 对这8种情况分别进行仿真分析,演化仿真结果如图2所示。
由图2(a)与图2(b)可知,在情形1与情形2中随着时间的变化,司机和乘客的演化策略均会收敛与1,即司机与乘客均会趋向于选择履约策略。
由图2(c)与图2(d)可知,在情形3和情形4中随着时间的变化,40%的司机与乘客的演化策略会收敛与1,40%的司机与乘客的演化策略会收敛与0,还有20%的司机与乘客的演化策略会收敛与0.6。
由图2(e)与图2(f)可知,在情形5和情形6中随着时间的变化,40%的司机与乘客的演化策略会收敛与1,40%的司机与乘客的演化策略会收敛与0,还有20%的司机与乘客的演化策略会收敛与0.4。
由图2(g)与图2(h)可知,在情形7与情形8中随着时间的变化,司机和乘客的演化策略均会收敛与0,即司机与乘客均会趋向于选择违约策略。
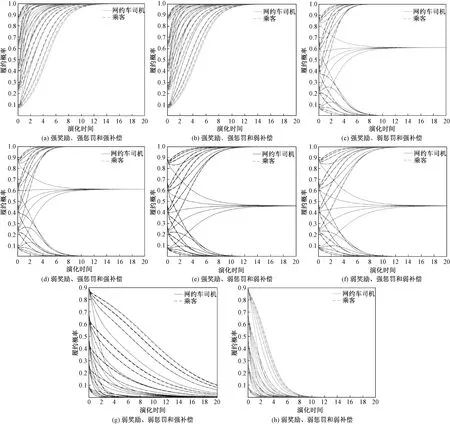
图2 演化仿真结果
综上,在网约车平台选择“实行奖惩机制”策略时,督促司乘双方的履约行为主要通过提高网约车平台对司乘双方的奖励力度和惩罚力度,而补偿力度的强弱对司乘双方的稳点策略的影响较弱。当平台对司乘双方的奖励力度、惩罚力度均较大时,司乘双方均会选择履约策略;当平台对司乘双方的奖励力度、惩罚力度中有一者较弱时,司机和乘客的演化策略不会趋向一个稳定的值,即此时司乘双方的选择策略不稳定;当平台对司乘双方的奖励力度、惩罚力度均较小时,司乘双方均会选择违约策略。平台的补偿力度对司乘双方的演化策略的影响很弱,而奖励力度与惩罚力度对司乘双方的演化策略的影响很大,且只有当网约车平台对司乘双方实施高强度的奖惩力度时才能达到督促司乘双方选择履约策略的目标。
4 结论
通过构建网约车平台、司机和乘客三方的演化博弈模型,分析了网约车平台、司机与乘客三方各自的演化策略,发现单个主体的演化策略会受到另外两个主体的影响,并在此基础上对三方共同作用下的演化策略的稳定性进行分析。最后利用MATLAB进行算例仿真分析,在网约车平台实行奖惩机制策略时,分析平台的奖励力度、惩罚力度和补偿力度对于司乘双方的演化策略的影响,得出结论:平台的补偿力度对司乘双方演化策路的影响很弱,而奖励力度与惩罚力度对司乘双方的演化策略的影响很大,且只有当平台对司乘双方实施高强度的奖惩力度时才能起到督促司乘双方选择履约策略的作用。
猜你喜欢
法律方法(2022年2期)2022-10-20
数字技术与应用(2022年3期)2022-04-14
山西青年(2020年3期)2020-12-08
小读者(2020年2期)2020-03-12
活力(2019年19期)2020-01-06
活力(2019年17期)2019-11-26
阅读(快乐英语高年级)(2019年11期)2019-09-10
长江丛刊(2017年10期)2017-11-24
赤峰学院学报·哲学社会科学版(2016年12期)2017-03-20
学苑创造·A版(2015年6期)2015-07-01
