
基于整体特征的河系匹配方法研究
2021-06-23 08:30金诗程李伊黎
热带地貌 2021年2期
金诗程,李伊黎,3
(1.广东省国土资源测绘院,广州510700;2.自然资源部华南热带亚热带自然资源监测重点实验室,广州510700;3.广东省自然资源科技协同创新中心,广州510700)
1 引言
河系数据作为庞大空间数据库中必不可少的部分,是地图和地理信息分析中的基础概念,在反映区域地理特征方面具有标志性作用,对居民点、交通网和工农业生产的分布和布局有显著的影响作用,同时也是城市空间结构的重要制约因素[1]。河系作为一种广泛存在的自然要素,是地图的基础结构内容,在空间数据集成和融合中占有较大的比例,合适的河系匹配方法对数据更新、集成与融合具有重要的意义。
线群目标可以分为包括等高线等呈线簇状的目标和包括道路、水系、境界线等呈网状分布的目标。刘涛等从空间关系和几何特征建立了线群目标相似度计算模型,其中空间关系包括拓扑、方向和距离关系,几何特征包括线群长度、平均长度、密度和曲折度[2]。Yang 等以stroke 表达道路网,结合概率松弛法基于全局寻优的策略实现道路网的分级匹配[3]。刘海龙等以stroke 为单元将离散的道路弧段构建为完整的道路,采用分类分级策略完成了整个道路网的匹配[4]。刘闯等在运用stroke 技术对道路网分级的同时,顾及道路的邻域关系,以上下级空间关系相似性为约束条件实现了相近比例尺道路网匹配[5]。余梦娟提出基于Voronoi 图的多尺度道路网匹配方法,将待匹配道路与邻域道路作为一个整体进行整体的一致性相似性评价[6]。线群匹配多是结合实际地物来研究,以道路网匹配最为典型,应用较多的是stroke 分级表达,很少有河系等其他线群地物的匹配研究。本文从线群整体特征考虑,构建树状河系的树结构,提出河系整体的相似性匹配方法。
2 河系匹配方法
2.1 河系树的构建
河系数据需要经过一定的数据组织才能交给计算机处理,所以要选择合适的数据结构将人眼识别的地图语言转化为计算机的数字语言。
2.1.1 河系实体处理 在河系数据重新存储之前,需要对原始数据进行预处理,使得杂乱无章的数据变得有规律可循。将所有河段从交汇处分裂(如图1虚线框1、2),从而形成标准的弧段-端点结构,然后将位于正常弧段线上的端点(如图1虚线框3、4)连接起来,从而形成完整连续的河段,在进行这一步操作时,可以将河系视为有向图,根据度(与端点相连的弧段数)将各个端点进行分类:(1)如果端点的度为1,表示该端点只连接一条弧段,为河系末端,不做任何处理;(2)如果端点的度为2,表示该端点连接两条弧段,则将该端点相邻的两条弧段连接成一条弧段;(3)如果端点的度为3 及以上,表示该端点连接3 条以上的弧段,为正常端点,不做处理。
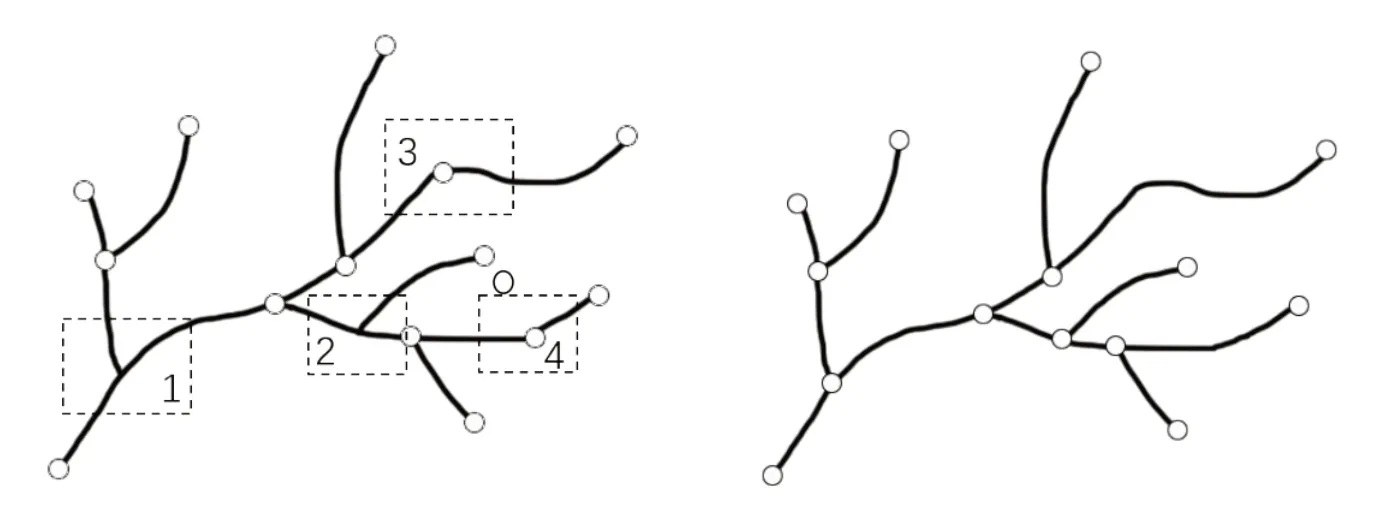
图1 河系原始数据及处理后数据
2.1.2 河流方向判断 河系是由不同源头的河流汇聚而成的,河流的流向是从地势高的地方流向地势低的地方,并最终流入海口或湖泊,一个河系可以有多个河源,但只有一个河口。将河系数据按照有向图的数据结构存储时,可以得出河系结构的一系列重要特性[8]:(1)一个顶点可有多个上游河段,即入度大于等于1,但只能有一个下游河段,即出度等于1;(2)度为1 的顶点为河源河段的起点或河口河段的终点;(3)在单元化处理后,度大于等于2的顶点为河流的交汇点。
张青年等在人工识别河源的基础上,自上游向下游追踪各个河段,使河段上游指向下游,以此来判断河流的方向[7]。一般情况下,河系的河源与河口存在多对一的数量关系,根据河系只有一个河口的特性,可以根据河口的位置,逆向寻找河系的河源,并逐段判断河流的方向,构建主支流关系[8]。
2.1.3 河系树建立 本文以主流为根结点,其支流为子结点构建河系的树结构,每个结点为一个类,包含该结点河流的编号、级别(树的深度)、长度、组成序列(顶点)、父亲结点(根节点的父亲为空)、孩子结点集合。
根据河系树结构的特点,从河源到河口,只能找到一条路径,因此可以从河源出发,遍历各个河源,搜索各个河源到河口的路径,并计算路径的长度,得到河系的最大长度,确定为主流。之后再以主流上各个交汇点为河口,以相同的思路遍历河源,得到支流的最大长度,以此类推,最后得到如图所示的树结构。
2.2 河系匹配
2.2.1 河系特征指标 本文从河系的空间特征出发,选取几何相似性指标,对河系进行匹配。
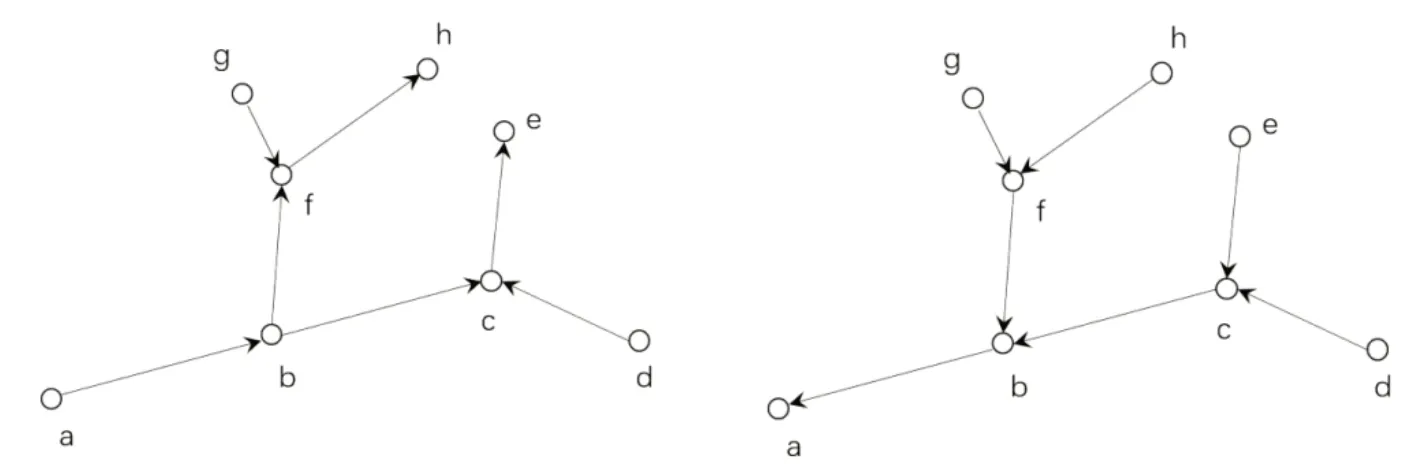
图2 河系方向处理前及处理后

图3 河系及河系树存储结构
(1)中心位置 以河系主流及其支流首尾端点的中心坐标的平均值作为河系的中心坐标。设E1(X1,Y1),E2(X2,Y2)分别为两个河系的中心点,则两个河系中心距离为:
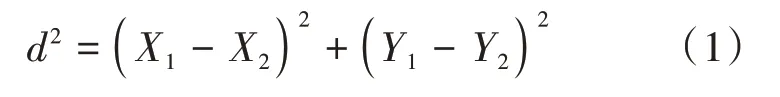
其中d≥0,d的值越小,两河系的中心距离越近,匹配的可能性越大。
(2)空间范围 以重叠面积的比例来作为河系空间位置相似度。这里设两个待匹配的河系空间范围面积分别为S1,S2,重叠面积为S,则河系空间位置相似度为:

其中S≤S1+S2-S,故0 ≤R≤1,两河系空间范围重叠度越高,空间范围相似度约接近于1。
(3)主方向 主流的线性回归趋势线与横坐标的夹角α作为河系的主方向,设α1,α2分别为两个河系主流与横坐标的夹角值,则它们的方向相似度定义为:
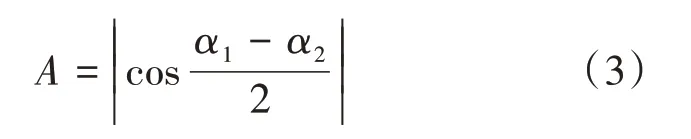
两河系主方向越相近,方向相似度越趋近于1。
(4)河系形状 以凸包长宽的比值来衡量河系的形状,即河系的形状特征值M为:

其中,length表示河系凸包的长度,width表示河系凸包的宽度。
设M1,M2分别为两个河系的形状特征值,则它们的形状相似度定义为:

两河系形状越相似,河系形状相似度越趋近于1。
2.2.2 匹配方法 在河系匹配中,通过河系中心位置这一特征筛选出匹配候选集后,再根据空间范围、主方向、河系形状三个特征指标作为综合相似度来衡量整个河系的相似性。
设河系L的匹配候选集为L′= {L1,L2,…,Lk},L与候选集河系空间范围相似度为R= {R1,R2,…,Rk},L与候选集河系主方向相似度为A={A1,A2,…,Ak},L与候选集河系形状相似度为S={S1,S2,…,Sk}。在计算综合相似度时,设空间范围相似度的权重为γ,主方向相似度权重为β,则形状相似度权重为1-γ-β,综合相似度(SIM)函数表达式为:
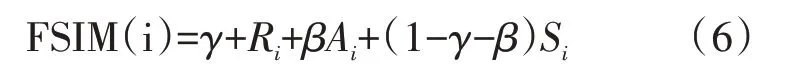
其中i=1,2,…,k。
3 实验分析
3.1 数据源
本文以云南省树状或格状河系为实验对象,如图所示。匹配矢量数据分别来源于网站openstreetmap.org/(OSM)以及从地理空间数据云获取的DEM 数据提取的河系网,以下分别称为OSM数据和DEM数据。
3.2 实验结果
实验中OSM 数据和DEM 数据分别标记出30 和29 个河系的河口,经实验测试,将两河系中心位置距离大于65 km视为不匹配,同样设置系数γ、β分别为0.4、0.3。
图4 云南省树状河系示意图
计算结果如表1所示。无论是以OSM数据为匹配集,DEM 数据为候选集,还是以DEM 数据为匹配集,OSM 数据为候选集,部分河系的候选集中只有一个候选匹配河系,且综合相似度接近1,如OSM 数据中2、3、8、12 号等河系,DEM 数据中2、3、7、12 号等河系,可以直接认定为匹配河系。另外部分河系的候选集中有多个候选匹配河系,如OSM 数据中1、4、5、6 号等河系,DEM 数据中1、4、5、6 号等河系,需要通过比较综合相似度大小来判断匹配河系。经过中心距离阈值的筛选,OSM 数据中30 号河系无候选集,DEM 数据中所有河系均有候选集。

表1 河系匹配综合相似度
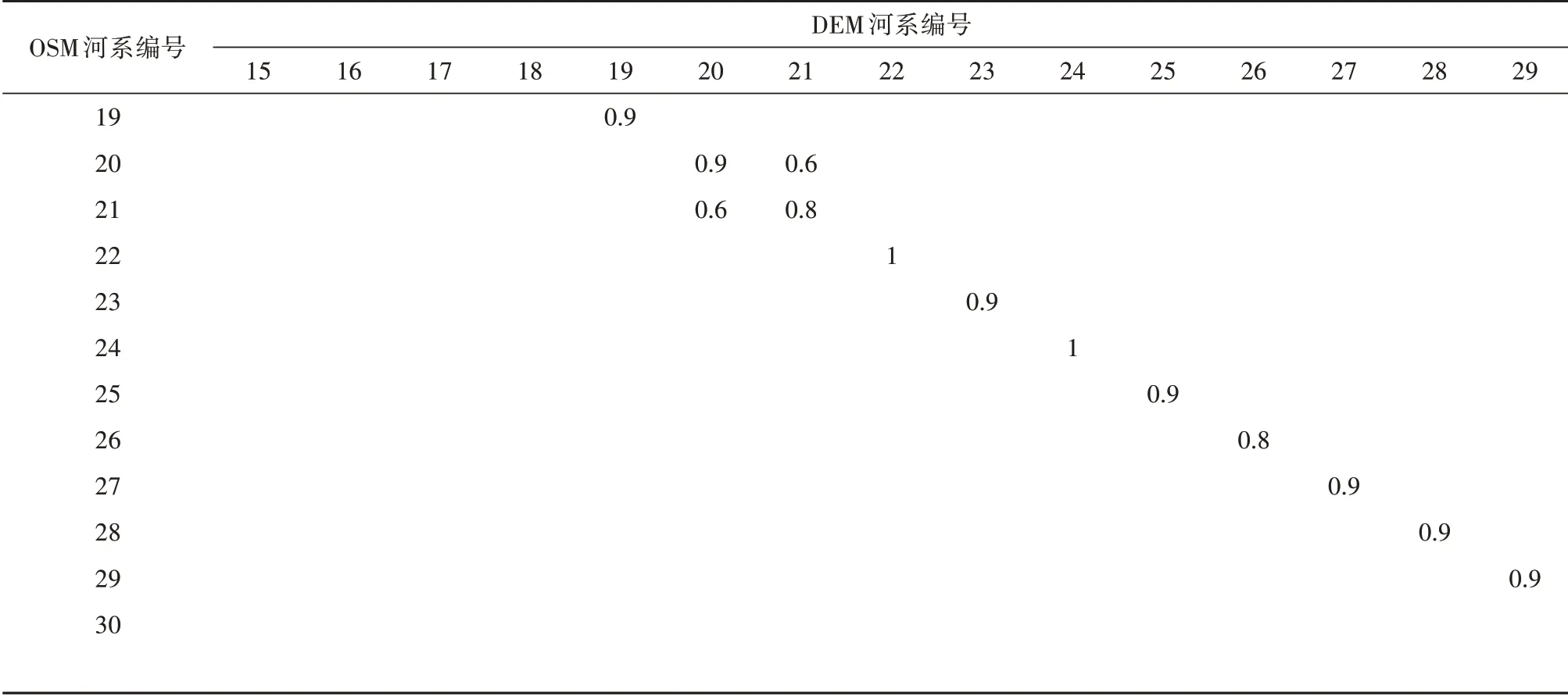
续表
如表1所示的综合相似度计算结果中,OSM数据中的14 号河系与DEM 数据中的14 号河系综合相似度为0.53,也小于阈值0.7,从各个特征指标来看,两者的空间范围相似度、主方向相似度、河系形状相似度分别为0.55、0.23、0.91。如图5所示,人工判别下,两河系具有相似的形状,在空间位置上能较大程度的对应,但计算得到的方向相似度过小,主要是两河系主流存在一定的差别。如图中显示的两河系主流,下侧末端河流段方向的差异,引起两河系主方向上的差异,导致主方向相似度过小。河系的主流是根据“主流长度最大”的原则进行判别的,由于不同数据的同一河系存在或大或小的差异,该原则判断的主流可能存在一定的误差,因此需要对河系的主流进行修正。这里以DEM 数据的14 号河系为主,将OSM 数据的14 号河系下侧末端河段原来的支流更改为主流上的河段,原主流上的小段河段更改为支流,经过修正后计算得到的两河系主方向相似度为1.00,综合相似度为0.84,可以判断为匹配河系。
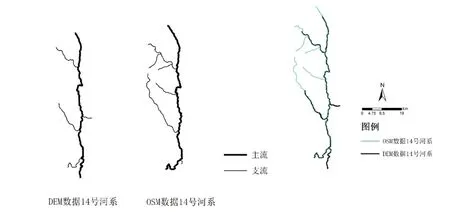
图5 OSM数据和DEM数据中的14号河系
除了上述情况,其他匹配河系的综合相似度均在0.7 以上,较多的匹配河系相似度能达到0.9,部分匹配河系相似度为1.0,符合阈值范围,也比较合理。综上所述,在本次河系匹配实验中,成功匹配的有28 对,OSM 数据中10、30 号河系无匹配河系,DEM数据中10号河系无匹配河系。
4 结论与讨论
本文根据常见水系结构确定了树状河系研究对象,并从河系的几何结构特征出发,根据实体河流水系的特点,确定了河系方向及河流等级的判断方法,建立了河系树存储结构。在此基础上进行河系整体匹配,实验发现,河系的中心距离不能完全确定相互匹配的河系,河系的空间范围、主方向和形状三个方面的相似性对判断河系整体性相似均有一定的贡献意义,通过计算比较本文提出的综合相似度可以有效地对同名河系进行识别和匹配。
猜你喜欢
电子设计工程(2022年24期)2022-12-23
现代工业经济和信息化(2022年9期)2022-11-03
历史教学问题(2021年4期)2021-11-05
山西林业(2021年2期)2021-07-21
客家文博(2021年1期)2021-04-06
应用科学学报(2020年6期)2021-01-04
中华建设(2020年5期)2020-07-24
电加工与模具(2020年2期)2020-04-29
散文诗(2017年17期)2018-01-31
西藏科技(2016年9期)2016-09-26
