
基于YOLOv3 的视频场景行人检测研究*
2021-06-22 01:57王明吉倪子颜
通信技术 2021年6期
王明吉,张 政,倪子颜,张 勇,刘 斌
(东北石油大学,黑龙江 大庆 163000)
0 引言
目标检测是计算机视觉的重要内容[1],是图像信息处理研究中至关重要一步。行人检测作为目标检测其一重要分支,结合目标跟踪技术,在行为分析、交通监控、无人驾驶技术、智能服务领域有着广泛的应用[2]。基于卷积神经网络提取特征的检测方法逐渐替代了传统手工提取的检测方法,依靠其强大的特征提取和自学能力成为检测技术领域的主流方法,并取得了阶段性突出的成果,尤其在稀疏大尺度目标上有很好的检测效果。但当面向实际应用场景时,摄像头与行人的距离较远会导致尺度不均,且小目标居多,更易收到环境噪声及遮挡影响,使得检测效果并不理想,进一步针对小目标检测进行深入研究具有重要的理论意义和实际的应用价值。
1 深度学习的目标检测算法
主流的深度学习目标检测算法结构均基于深度学习的卷积神经网络构建,按流程主要分为twostage 和one-stage 两个系列。two-stage 将检测任务分为两个阶段,首先通过在图片上遍历滑框选取感兴趣的候选区域框映射到特征图(feature map)区域上,再重新输入到全连阶层分别进行分类和回归处理得到检测结果。该系列在2015 年发表的更快的基于区域的卷积神经网络(Faster Region-Based Convolutional Network,Faster R-CNN)[3]通 过 引 入区域生成网络(Region Proposal Network,RPN)[4]替代搜索框选择,同时增加锚点机制应对目标形状的变化,从而减小了空间消耗,实现了高精度,但远远达不到实时检测。
为了满足实际场景应用对目标检测的要求,检测的研究方向逐渐转向速度为主的检测网络,以YOLO[5]系列,半离散矩阵分解(Semi-Discrete Matrix Decomposition,SDD)[6]为代表的基于回归的单阶段网络应运而生。此系列主要将图片网格划分区域得到数据块,每块区域独立预测一次性得到全部边界框,同检测任务统一视作回归问题,形成了端对端的训练流程,速度可达到45 fps,Faster-RCNN 只有7 fps。然而,由于取消了RPN 网络使得网格定位模糊,降低了检测目标精度。YOLOv2[7]引入二阶段类似的anchor 机制动态的调整网络使其能够预测不同大小的图片,一定程度上平衡了检测的速度和精度。但面向目标密集的自然场景时,主要以大目标为主导神经网络学习检测机制对于分辨率较小的小目标特征不敏感,需要更细腻的特点进行特征学习,并且YOLO 对图片的缩放操作与多次下采样进一步缩小了小目标的分辨率导致了小目标检测性能的不稳定。现有的通用检测网络无法避免小目标检测效果相对大目标较差的问题,但仍可以结合网络结构特点改进或优化。常通过引入注意力机制,上下文信息或者强化特征提取网络等优化举措提高小目标检测性能。宦海[8]等人通过利用空洞卷积捕捉大感受野,并使用多卷积核尺寸和膨胀率的卷积,构建多层并行的空洞感受野模块(Atrous Receptive Module,ARM),提高对小目标的检测能力。任宇杰[9]等人基于单次多尺度检测器(Single Shot MultiBox Detector,SSD)提出一种与MobileNet结合的轻量级深层神经网络结构,并通过使用focal loss 损失函数动态调整交叉熵平衡正负样本,提高检测性能。
2 密集行人检测网络结构
2.1 YOLOv3
YOLOv3[10]是性能较好的代表性检测网络之一,其结构如图所示,Yolov3 使用darknet53 作为主干网络,并使用步幅为2 的卷积层替代了网络中的池化层进行特征图降采样,有效地阻止了池化层带来的低层级特征信息损失。其最主要的特点是拥有以Resnet 为灵感的5 个残差模块,能够进行更深层次信息的传播。YOLOv3 结构如图1 所示,残差模块由残差单元resX 和DBL 单元组成,X代表模块中残差单元的数量,每个DBL 都由一个卷积层、归一化层和LeakyRelu 激活函数组成,除此之外YOLOv3 还使用了多个tricks 来提升检测性能,比如在原始YOLO 基础上增加了anchor 机制和类似于特征金字塔(Feature Pyramid Network,FPN)[11]的多尺度预测。

图1 YOLOv3 网络结构
YOLOv3 首先将特定尺寸的图像数据输入模型,通过卷积操作得到特征图并划分网格,特征图的每一个网格需要预测3 个目标框,每个预测得到S×S×3 ×(5+C)维度的输出,其中S 是划分的网格数量。x、y、w、h、confidence5 个参数分别表示检测框的横、纵坐标,宽度和高度以及置信度,还包含一个类别概率C。YOLOv3 为了使检测能够适应大小不一的物体,分别使用步幅32、16 和8 进行下采样操作,并为每种下采样尺度设定3 种先验框进行预测聚类分析,总共9 种尺寸的先验框,得到三个不同检测尺度的输出。最后通过阈值筛选确定图中目标最终的坐标信息和类别的预测值。
2.2 位置增强特征金字塔
卷积神经网络中的大尺度特征图由于经过较少的下采样,感受野较小包含更多的细节位置信息;小尺度特征图则感受野大包含更多的语义信息。因此,通过由浅及深地特征融合才能获得更丰富的特征信息。原始的特征金字塔结构为,同一特征层级逐层进行步幅为2 的特征映射得到新特征图,并将阶段性最强信息作为输出进行横向连接,但同一层级传播会压缩细节位置信息,对小特征表达能力差的小目标不敏感,且传播过程中仍存在细节的丢失。于是延续了多尺度融合特征的优越性,提出一种横向拓展的位置特征增强金字塔模型FPLN(Feature Pyramid Location Network),通过全连接堆叠信息后再自适应特征创建特征信息流的方式,修复特征候选区域和特征层次之间的损坏路径,使模型能够学习到更多的有效特征,进一步提高小目标的检测精度。
位置特征增强金字塔模型直接采用主干网络后的预测分支的三个不同尺寸检测头{c1,c2,c3}作为第一阶段的特征图,将输入608 尺寸的通过32、16、8 倍下采样得到的76、38、19 尺寸特征图的直接进行自下而上的采样,再用1×1 的卷积核将三个尺度特征图进行通道的纬度变化,接着较深层特征图上采样放大2 倍应对相邻层级特征图尺寸统一后像素级的加法迭代得到{d1,d2,d3},实现第一阶段底层语义信息的增强结构。为了最大化丰富D层特征,保留低语义层包含的位置细节信息,如图2 左侧对C 列YOLOv3 检测头的三个尺度特征图谱与一次自上而下的特征图D 列特征进行全连接(FC,Full Connect)操作,同样通过采样统一尺寸的方式再一次传播原始信息并通过堆叠方式弥补传播过程中丢失的信息。
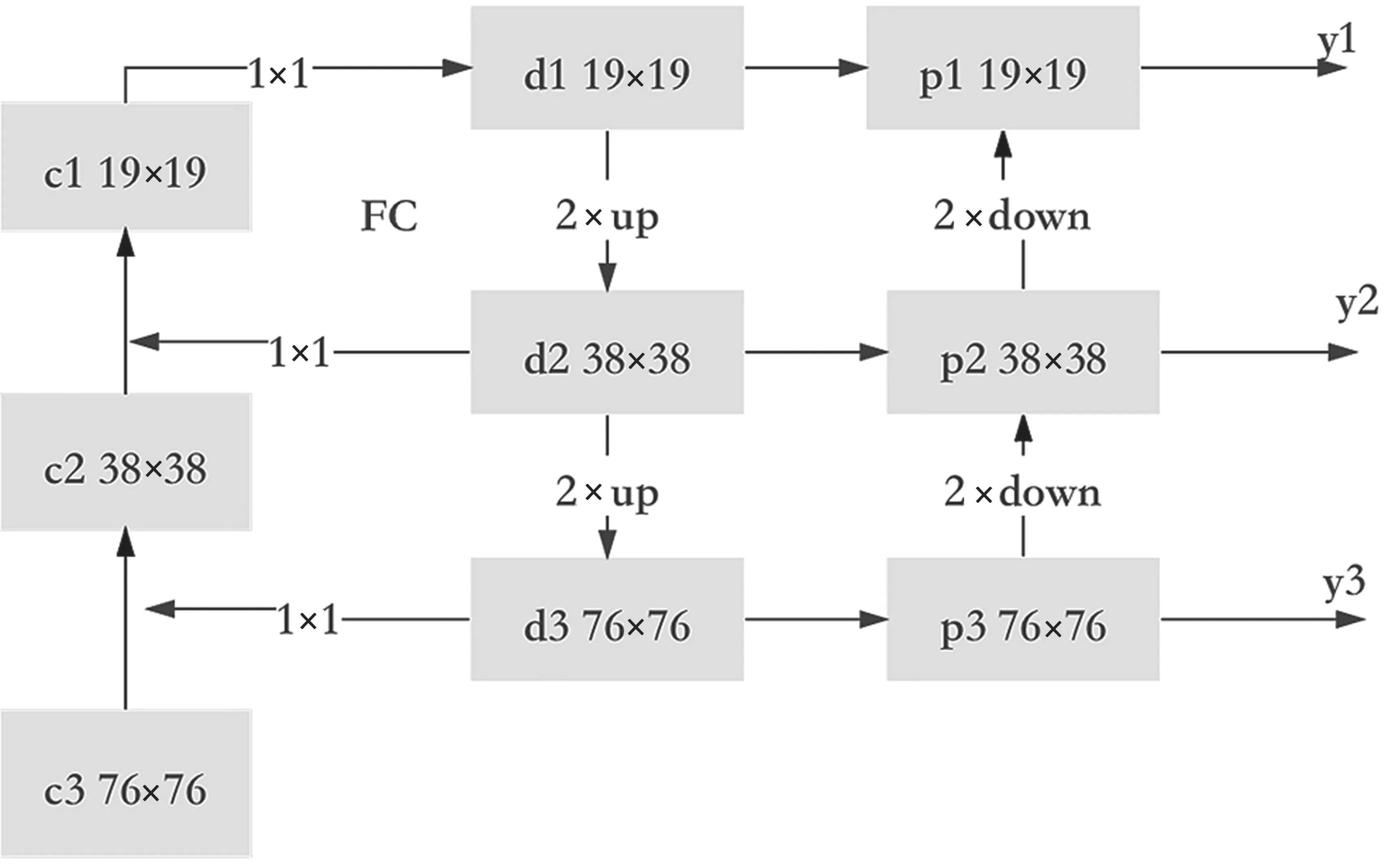
图2 FPLN 网络结构
除此之外,如图2 右侧所示,以相同的融合策略又增加了一组二倍下采样叠加,构建自下而上的位置特征增强,并与D 层通过1×1 融合得到{p1,p2,p3},形成了特征图的闭环结构,在尺度融合中丰富信息,融合特征图谱信息和自顶向下传达强语义特征堆叠,最后附加层则自底向上传达强定位特征,综合的提升了网络对小目标的识别能力。

图3 广义交并比与DIoULoss 回归对比流程
2.3 损失函数
为了使预测框与真实框之间的对齐程度实现更好的表征,获得更精准边框度量,以迎合更为密集行人框互相堆叠易发生漏检的数据特征,针对YOLOv3 对预测框的中心及横纵坐标使用LossDIoU为目标定位损失函数,进行计算偏移的优化,提升网络对目标位置的定位的准确性。考虑重叠面积的广义交并比原基础上增加了基于中心点归一化距离,在损失函数中引入惩罚项,提出了DIoU(Distance Intersection over Union)损失函数如下:

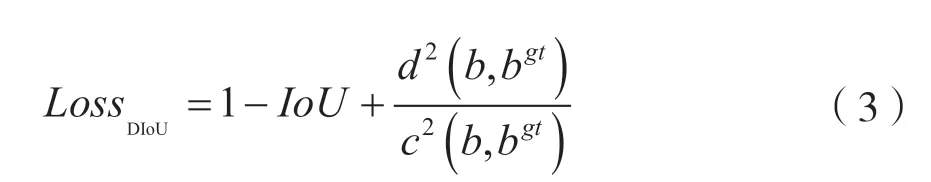
式中,B为检测框,Bgt为真实框,d为计算两者的欧式距离函数,c为覆盖两框间最小框中心的对角线距离。下图回归过程中可以看出广义交并比损失会通过扩大预测盒与寻找目标框并与之重叠,相比交并比损失更关注中心点距离并逐步通过惩罚项缩小距离。两者同时引导边界框移动方向的过程中,相比优化的是两个目标框间重叠面积的损失,DIoU 损失直接最小化两个目标框中心点距离的回归过程收敛更快且网络更稳定,DIoU 还可以避免在两框无交集时,广义交并比损失退化为零的情况,更加符合目标框回归的机制。
2.4 锚点框选择
选择尺寸合适的锚点框以及Anchor 个数更有利于提高检测的准确率,并可以根据检测数据集差异做出相应调整。原始YOLOv3 算法锚点框个数以及宽高比是基于包含行人在内的80 类的目标的COCO 数据集[12]上进行聚类得到的。获得的聚类不能精准的代表单类行人框的特征,本文针对复杂场景下单类行人检测,采用密集行人数据Human Crowd[13],通过以IoU 为度量的K-mean 聚类[14]分析方法重新聚类,度量公式如下:
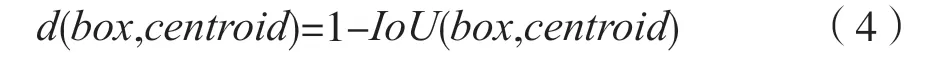
得到行人特征对应的三个尺度的9 组锚点框聚类结果:(19,12) (14,29) (30,26) (40,59) (55,78) (60,132) (122,178) (146,238) (303,340)。
3 模型训练与实验分析
3.1 实验环境及训练参数
实验使用的硬件:CPU(处理器)型号为Inteli7,GPU 为英伟达2080Ti R,内存为11 GB。
实验使用的软件:操作系统为Ubuntu 16.04,深度学习框为PyTorch 1.6,另外安装软件环境Cuda 10.1+OpenCV。
实验过程使用COCO 作为训练集,输入图像并进行mix up 数据增强,平台搭建网络模型进行训练。训练过程中的batch尺寸设为64,权重衰减为0.000 5,动量值为0.9,学习率衰减策略采用指数衰减策略。首先采用初始化学习率0.01,保持此学习率到第40个epoch,从40 个epoch 使用gamma=0.9 来衰减学习率,一共训练200 轮,训练时间为两天时间最终得到密集行人检测模型。训练过程中,使用自适应动量优化(Adaptive Moment Estimation,ADAM)算法[15]根据训练数据迭代自主地完成神经网络的权重更新,优化模型的参数。保存完整训练模型后,以人流聚集视频场景作为测试数据集,应用训练好的模型测试本文网络在面对遮挡以及摄像距离导致的尺度多样性问题时,对行人目标的检测性能。
3.2 评估标准
实验中采用平均精度均值(mean Average Precision,mAP)和检测速度(单位为fps)作为评价标准检验模型的有效性。其中Precision 表示正确预测数占总真实标签数的比例,Recall 表示正确预测数占目标预测总数的比例,mAP 平均精度为计算两者曲线下的面积的综合指标。其中mAPs 指标代表目标尺度小于322的小目标。
3.3 实验数据及分析
视频场景下,同一帧检测效果对比如图4 和 图5 所示。图4 为原算法检测结果图,未检测出被遮挡的行人,尤其是在远处和背景相连的小行人处呈现了检测空白。图5 为本文视频行人检测算法结果图,能够成功检测到被遮挡较大的行人和远处的小目标。

图4 YOLOv3 算法视频帧检测结果

图5 本文算法密集行人检测效果
实验第一阶段,将本文算法与SSD 以及YOLOv3 算法做对比实验,相同算法的前提下,输入的分辨率越大得到检测的精度越高,证明了丰富图片特征对目标检测结果的重要性。结果如表1 所示,本文算法的小目标平均精度达到了92.25&,较SDD 与原始YOLOv3 分别提高了8.89&和4.25&,证明了模型的有效性。
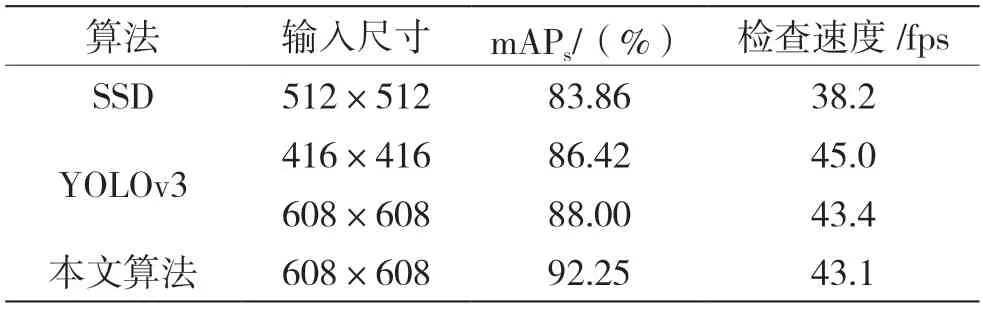
表1 本文算法与原算法性能对比
实验第二阶段基于YOLOv3 算法针对改进的每一步进行消融实验的对比。验证本文的位置增强网络结构和损失函数的优化都能为算法争取到精度的提高,结果如表2 所示,在数据预处理的基础上,位置增强的金字塔网络结构能有效获取丰富特征,在尺寸小于322的情况下目标精度提高了2.15&,增加的基于中心点距离的损失函数通过精细定位使精度提高了1.78&,在多尺度目标上的平均精度达到了94.15&。增添模型一定程度上增加了网络的计算,但仍满足实时性的要求,以上证明本文基于YOLOv3 的视频场景网络模型在密集行人场景下是行之有效的。
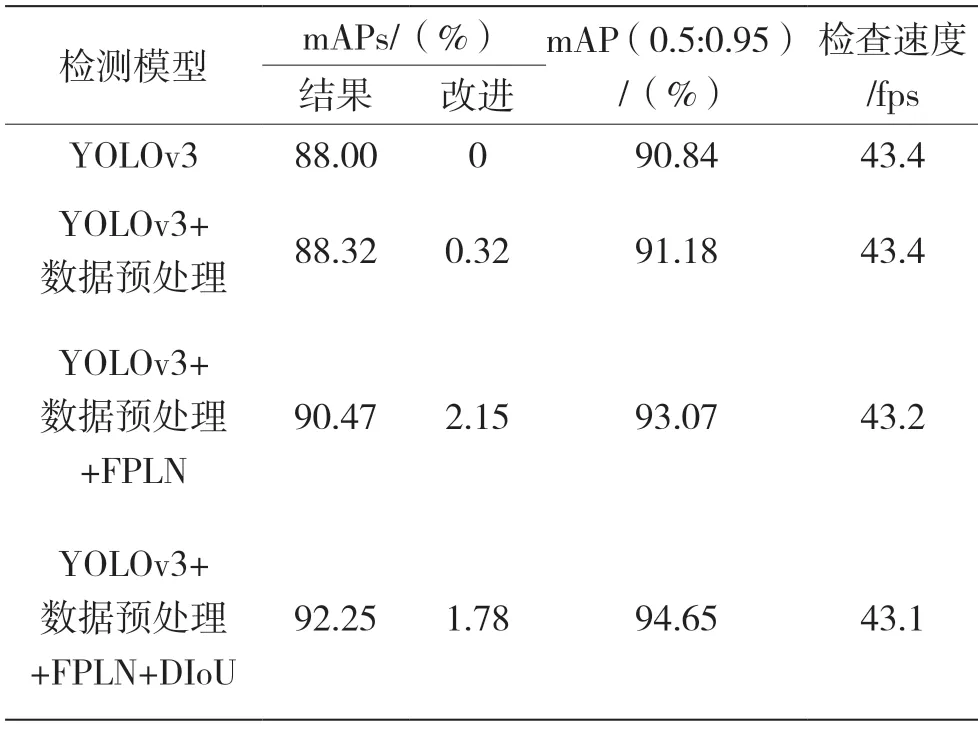
表2 本文算法增益实验
4 结语
针对视频中的密集人群检测中小目标定位差精度较低的问题,提出了一种基于YOLOv3 的位置增强金字塔模块行人检测模型。在视频数据集上的实验结果表明,在保证了实时性的情况下,本文算法在面对小目标行人和普通尺度行人的检测精度都有所提高,在智能检测领域具有一定的前景。通过对YOLOv3 三个尺度特征图下采样后,与进行全连接再双向的创建信息流进行特征融合,增强特征提取能力,同时结合DIoULoss缩近边框偏移获得更精准的预测框和符合行人特征的锚点框预选,提高了密集行人检测性能。未来考虑使用更加轻量的网络结构,降低复杂度,寻求更加高效精准的检测思路。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
意林(2021年5期)2021-04-18
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
扬子江(2019年1期)2019-03-08
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
太空探索(2016年5期)2016-07-12
