
基于本体的孔子世家谱知识图谱*
2021-06-22 01:57张政平倪建成
通信技术 2021年6期
张政平,倪建成
(曲阜师范大学,山东 济宁 273165)
0 引言
家谱是一种表谱形式的特殊文献,记载了以血缘关系为主体的家族世系繁衍信息和重要人物的相关事迹信息等。它不仅包含了整个家族可追溯的家族来源、迁徙轨迹以及人物描述等结构化数据,还隐含了独有的文化传承、族规家约等历史文化信息。《孔子世家谱》(2009 版)作为“世界最长家谱”[1],全谱共分108 卷,首次收录了女性族人、少数民族和外籍后裔的资料,增加了性别、配偶等个人信息,且已于2016 年实现了孔子世家谱的数字化续修系统[2],使用关系型数据库存储世家谱数据。然而,随着家谱数据的不断丰富,家谱信息的复合查询、语义推理与分析等需求急剧扩增,导致传统的家谱数据管理方式[3]已经无法满足上述需求所需要的实时、自动推理和可视化等特性。
知识图谱是一种能够可视化的信息表达方法,便于人们准确、清晰地获取数据。本体作为一种语义数据模型,用于定义特定领域的概念、属性及其相互关系,实现领域建模和推理。因此,将知识图谱和本体有效结合可以更准确地分析家谱领域知识之间的逻辑关联。
知识图谱的构建一般采用自顶向下和自底向上两种方式[4]。自顶向下的方法通常用于领域知识图谱,先定义本体与数据模式,再填充实体形成完整的知识图谱,如FreeBase。自底向上的方法则先从开放连接数据中提取实体,再选择置信度超过阈值的实体-关系对加入知识库,最后构建顶层的本体结构和数据模式[5]。
在知识图谱构建过程中,数据层的填充需要使用实体识别技术。实体识别大致可分为基于规则[6]、基于统计学习[7]和基于机器学习[8-10]3 种方法。基于统计学习的方法对人工特征选择要求较高,对语料库的依赖较大。基于机器学习的方法虽在预测过程中无需过多的人工干预,但在训练模型时仍需大量的人工标注信息。基于规则的方法需要领域专家的支持,难以移植到新领域,但是准确率高、直观性好,更加接近人类的思考方式。对于孔子世家谱原始数据,从零开始标注数据的任务量较大。某些实体类型的数据量比较稀疏,使用统计学习、机器学习方法会导致模型欠拟合或训练不充分。此外,孔子世家谱的结构比较单一,有一定的规律性。因此,使用基于规则的实体识别是最佳选择。
目前,家谱领域本体的研究工作屈指可数。夏翠娟等人[11]设计了基于书目框架(Bibframe)的上海图书馆家谱本体。该本体以一个家族为最小单位进行资源描述,无法描述家族中的具体人物及其关系和属性。陈艳[12]构建了中国家谱知识本体,本体面向多宗族家谱,规模较为庞大。孔子世家谱记载了孔子后人详细的人物信息,包括人物的名、字、号、性别、世系代数、支派、出嗣情况以及生平事迹等。对于孔子世家谱数据而言,现有的本体结构规模冗余且粒度过粗。
此外,相对于关系数据库而言,图数据库更适合处理大规模数据,可以避免关系数据库涉及多表的复合查询时的表联接复杂性和低效性,从而提升用户体验。Neo4j 是一个开源的图数据库管理系统,以面向图的存储格式将数据存储在本地文件,具备完全事务特性,能够高效执行结构化数据的各项操作。另外,Neo4j 使用声明式的模式匹配查询语言Cypher。相对于SPARQL,它更加易于理解和操作,对大规模的数据库应用至关重要。
综上,目前构建孔子世家谱知识图谱存在两方面的问题。一方面,当前领域本体建模方法不完善,现有家谱本体无法准确描述世家谱数据。另一方面,基于关系型数据库存储的孔子世家谱续修系统数据存取效率低,且无法挖掘家谱数据之间的语义关联。
针对以上问题,本文采用自顶向下的方式构建孔子世家谱知识图谱:
(1)在孔子世家谱原始数据的基础上,提出一种世家谱本体构造方法,并依据此方法建立世家谱本体结构;
(2)根据世家谱本体的约束,抽取非结构化数据中的实体,并将实体数据整合为知识三元组;
(3)将知识三元组存储至Neo4j 图数据库,完成初始的孔子世家谱知识图谱构建。
1 孔子世家谱知识图谱构建流程
本文在构建孔子世家谱知识图谱时,按照知识图谱的生命周期,将构建流程分为本体构建、知识抽取和知识存储等3 个步骤。构建流程如图1 所示。

图1 孔子世家谱知识图谱构建流程
首先,提出融合骨架法和七步法的世家谱本体构造方法,并据此构建本体。其次,采用基于规则的实体识别方法抽取实体,并整合完成知识抽取。最后,利用图数据库Neo4j 存储知识图谱。
2 世家谱本体建模
七步法[13]和骨架法是现有构建领域本体的常用方法。骨架法分为确定知识本体应用的目的和范围、本体分析、本体表示、本体评价和本体建立5个环节。当本体不符合评价标准时,重新进行本体分析。骨架法虽然工程周期完整,但领域本体的设计过程较为笼统,缺乏考虑现有本体的共享和复用。七步法包含确定本体的专业领域和范畴、考查复用现有本体的可能性、列出本体中的重要术语、定义类和类的等级体系、定义类的属性、定义属性的分面和创建实例7 个步骤。虽有较为完整的本体分析环节,但是缺少本体的质量评估步骤。事实上,我们无法保证一次性得出的本体结构就是最恰当的模型。本体的构建过程应该是迭代进行的,即先构造基础本体,再根据实际应用需求不断完善。因此,本文融合骨架法和七步法设计了世家谱本体构造方法,具体的构造流程如图2 所示。
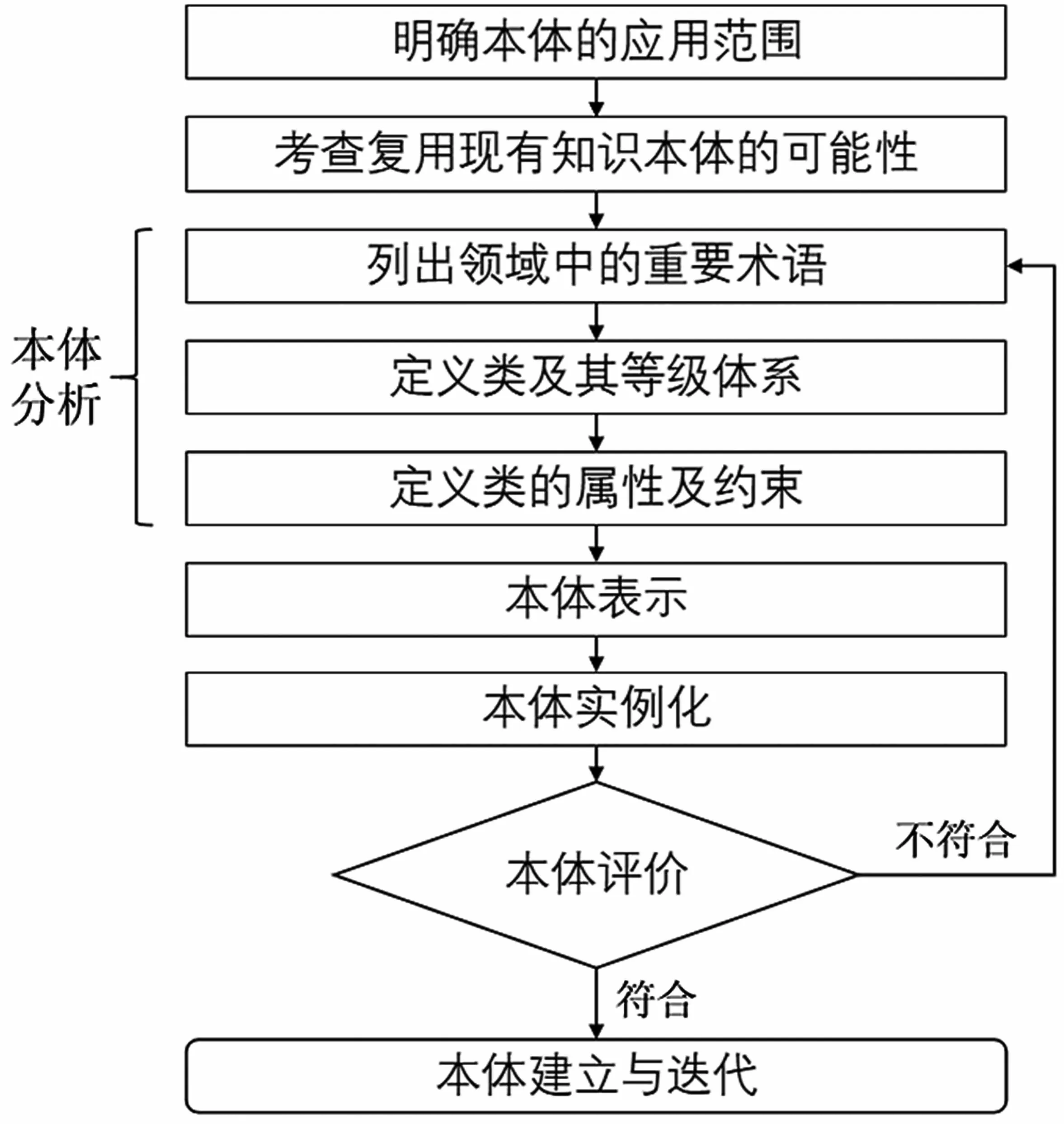
图2 世家谱本体构造流程
2.1 明确本体的应用范围
作为孔子世家谱知识图谱的模式层,世家谱本体用于描述孔氏家族的世系、人物概念及其之间的关系。因而,世家谱本体应该准确描述记载家谱的书籍信息、家族支派信息和人员详细信息,由此才能够清晰反映出各人物及其之间的关系,以便进行人物分类,进而避免形成超级节点。
2.2 考查复用现有知识本体的可能性
通过调研已有的家谱领域本体模型,对夏翠娟等人[11]的上海图书馆家谱本体和陈艳[12]的中国家谱知识本体进行分析复用。
2.3 列出领域中的重要术语
本文从孔子世家谱中析取出相应的重要术语,如表1 所示。

表1 孔子世家谱重要术语
2.4 定义类及其等级体系
为满足知识图谱的应用需求,从术语中提取出集次、卷次、支派、世系代数和人物5 个核心类。Protege 中最顶层的类为Thing 类,5 个核心类均为该类的子类,其等级体系如图3 所示。
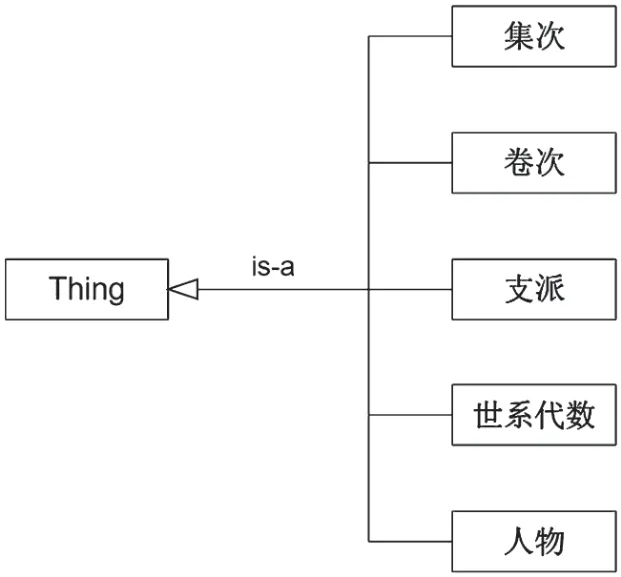
图3 世家谱本体的核心类
2.5 定义类的属性及约束
将核心类之外的术语进行归纳整理,作为属性划分给对应的类,且明确类与类之间的关联。类的属性包括对象属性和数据属性。世家谱本体的5 个核心类共包含11 个对象属性和若干数据属性。使用Protege 表示的对象属性和数据属性分别如图4和图5 所示。

图4 世家谱本体的对象属性
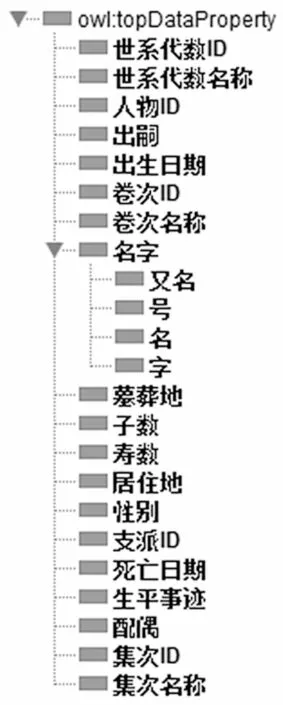
图5 世家谱本体的数据属性
2.6 本体表示
应用本体建模工具Protege进行本体建模表示,且存储为OWL 格式文件。
世家谱本体OWL 文件部分内容如下。

2.7 本体实例化
建立本体是为了解决实际问题,因此要为本体填充实例。一方面,填充实例可以使得知识更加丰富;另一方面,在本体实例化过程中,可以利用填充的实例评估本体结构,初步判断该本体是否符合应用需求。图6 展示了Protege 中的部分世家谱本体实例。
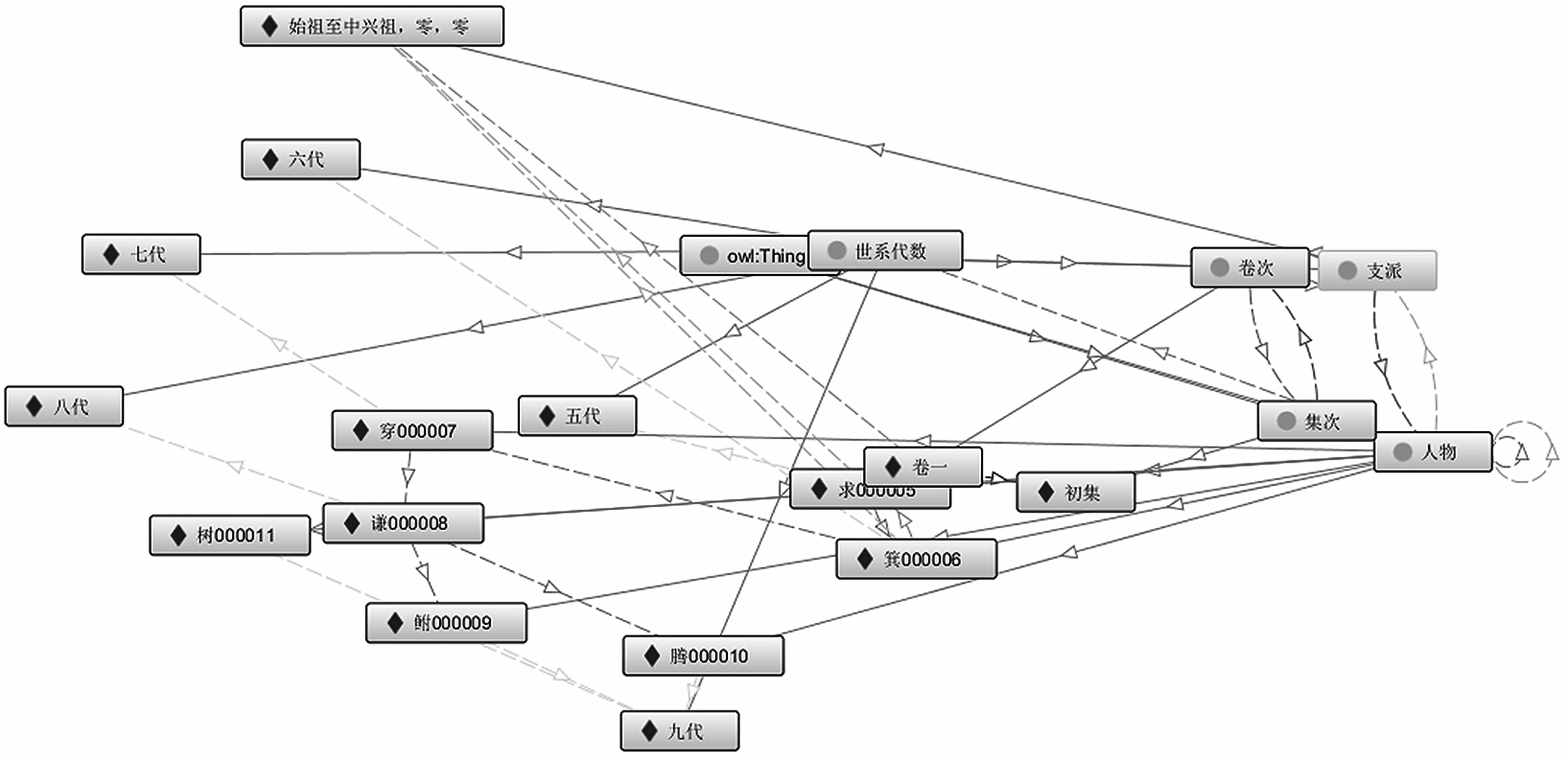
图6 本体实例化示意
2.8 本体评价
通过咨询家谱领域和儒家文化领域的专家意见,以Thomas 提出的5 条本体构建原则[14]为评价准则,证明了本文构建的世家谱本体符合客观事实和评价标准,遵循本体构建原则,具有可行性,能够满足实际应用需求。
2.9 本体建立
通过迭代第2.3~2.8 章节的相关步骤,最终建立了符合本体评价要求的世家谱本体,模型如图7所示。
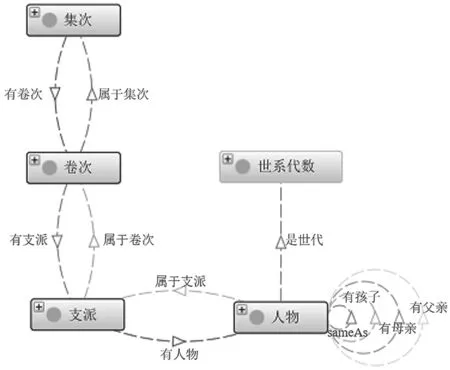
图7 世家谱本体模型
3 基于规则的家谱实体识别
在世家谱本体中,大量的又名、字、号、居住地、墓葬地以及配偶等数据属性蕴含于人物的生平事迹中,可以使用基于规则的实体识别技术进行提取。
基于规则的实体识别中,首先对要抽取的某个实体类型进行数据分析和统计。其次,迭代制定、测试分析和更新规则,直到识别出更多更准确的实体为止。最后,将规则应用于全部数据,完成该实体类型的识别。
下面以又名、号和寿数3 个数据属性为例,诠释实体的具体识别过程。
3.1 又名的实体识别
通过统计,又名的前缀一般包括本名、一名、初名、改名、后名、又名、原名、学名、官名以及庠名等,且可以先将又名的字数默认与名的字数相同,然后根据以下条件更改字符串长度。
条件1:若取2 个汉字超出字数范围,则只取1 个汉字。
条件2:按照生平事迹的书写格式,“又名”后一般紧跟“字”的描述。因此,当“名”的字数为1 时,且“名”后的第3 个字为“字”时,“又名”取2 个汉字;否则,当“名”的字数为2,且提取的又名第二个字为“字”字时,则只取1 个汉字。
另外,每个人只存在一个又名,因此只取匹配到的第一个字符串为人物的又名。
综上所述,又名实体的识别规则如下:
(本名|一名|初名|改名|后名|又名|原名|学名|官名|庠名)<人物的又名>(字)?
将以上规则应用于全部数据中,共识别出又名29 626 例。识别效果如图8 所示。

图8 “又名”实体识别示例
3.2 号的实体识别
从《孔子世家谱》原始数据中随机抽取出1 000 条存在号的数据作为测试数据,用以规则的制定。通过对测试数据的统计和分析发现,古人的号通常由两个汉字组成,但也有例外,如有些人会使用特定名词另起一个别号。比如,3 个汉字号的形式通常为“号+{两个汉字}+(子|翁|叟|人)”,4 个汉字的形式通常为“号+{两个汉字}+(先生|老人|居士|外史|山人|散人|道人)”等。因此,号的识别规则可以表示为:
号<人物的号>(先生|老人|居士|外史|山人|散人|道人|渔|樵|翁|叟|人)?
将以上规则应用于全部数据中,共识别出号2 332 例,其中有9 例存在别号。识别效果如图9 所示。

图9 号实体识别示例
3.3 寿数的实体识别
寿数在数据中的形式比较统一,描述为“年XXX 卒,卒年XXX,年XXX 薨,薨年XXX”,因此规则描述如下。
规则1:年<人物寿数>(卒|薨)
规则2:(卒年|薨年)<人物寿数>
将以上规则应用于全部数据中,共识别出寿数175 例。识别效果如图10 所示。
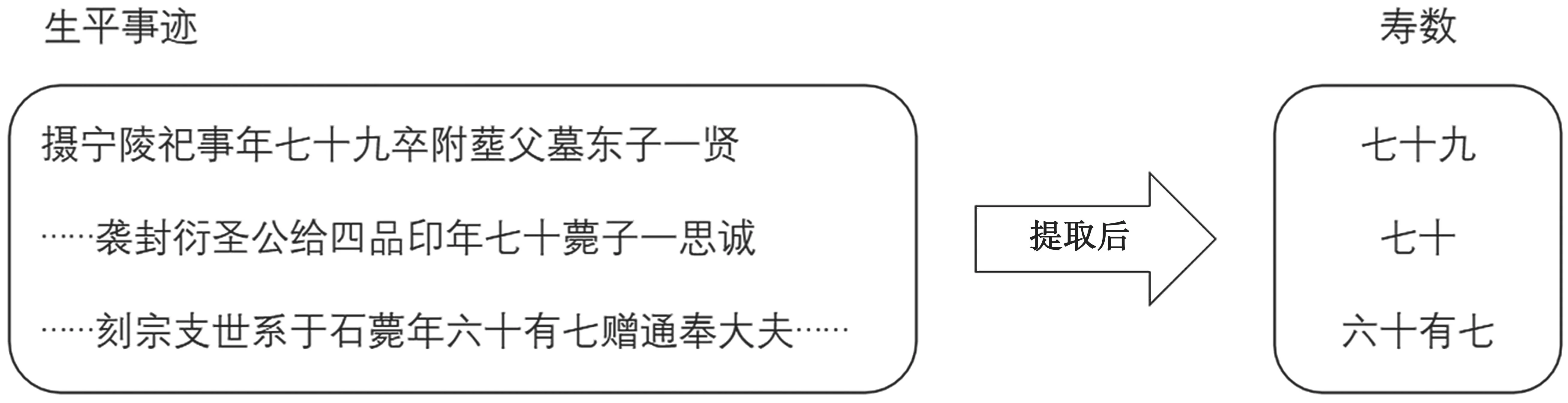
图10 “寿数”实体识别示例
此外,从生平事迹中提取出“字”实体7 644 例,“出生日期”实体327 694 例,“死亡日期”实体22 132 例,“配偶”实体222 716 例,“居住地”实体84 019 例,“墓葬地”实体94 例。
4 孔子世家谱知识图谱持久化与可视化
在《孔子世家谱》中,仅初集卷就包含了65万余节点实例、325 万余关系实例和325 万余属性实例。考虑到孔子世家谱数据量大、知识图谱图结构本质和世家谱应用实时性需求,本文使用Neo4j图数据库实现知识图谱的持久化与Web 可视化。
4.1 知识图谱持久化
采用neo4j-admin import 工具将家谱数据导入图数据库Neo4j,具体操作步骤如下。
4.1.1 节点CSV 文件
使用Neo4j-admin import 工具存储知识图谱,需要先建立图谱节点的CSV 文件。每个节点必须有一个全局唯一的ID,从而在创建节点之间关系时便于引用。
为集次等5 个核心类单独建立了CSV 节点文件,每个节点文件都有对应的头文件(Header File),且头文件与数据文件分开保存。
设置的数据节点文件如下:
(1)jici_data.csv:集次节点文件;
(2)juanci_data.csv:卷次节点文件;
(3)zhipai_data.csv:支派节点文件;
(4)shixi_data.csv:世系代数节点文件;
(5)person_data.csv:人物节点文件。
上述5 个数据文件中的每一行代表一个实例,每一列描述该实例的不同属性,且属性名与头文件中的内容一一对应。
例如,人物节点文件部分内容如图11 所示。其中,ID(personID)为“0100004”的人物名(Given Name)是“白”,性别(Gender)为“男”,没有出嗣(Adopting),寿数(Age)为“四十七”,子数(Number of Children)为“1”,墓葬地在“祖墓西北”。

图11 人物节点文件示例
4.1.2 关系CSV 文件
Neo4j-admin import 工具通过连接节点ID 创建关系(relationships)。如前所述,核心类本体共涉及11 个关系,具体包括:
(1)集次→卷次(有卷次);
(2)卷次→集次(属于集次);
(3)卷次→支派(有支派);
(4)支派→卷次(属于卷次);
(5)支派→人物(有人物);
(6)人物→支派(属于支派);
(7)人物→世系(是世代);
(8)人物→人物(有孩子);
(9)人物→人物(有父亲);
(10)人物→人物(有母亲);
(11)人物→人物(相同人物sameAs)。
与上述11 个关系对应,分别创建相应的CSV文件。例如,“有父亲”关系的CSV 文件部分内容如图12 所示。

图12 人物关系文件示例
可以看出,节点ID 为“01000005”和“01000004”的人物间存在“有父亲”的关系。两节点分别对应图11 中的人物,“01000005”指代名为“求”的人,“01000004”指代名为“白”的人,“01000005,01000004,有父亲”表明“求→有父亲→白”,即“求”的父亲是“白”。
4.1.3 批量导入Neo4j
使用Neo4j-admin import 命令批量导入数据,需要先把所有CSV 文件置于导入目录(.import),然后 在Neo4j-admin 的同级目录中执行import 命令。导入结果如图13 所示。可以看出,本文共导入了650 864 个节点实例、3 251 812 个关系和9 757 851 个属性。导入过程仅用了9.764 s,内存使用峰值为1.04 GB。
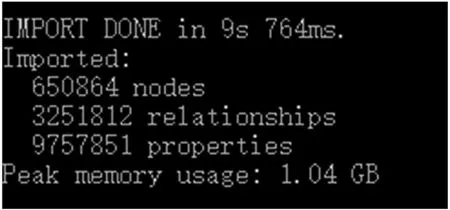
图13 批量导入结果指标
4.2 知识图谱可视化
Neo4j 启动完毕后,打开浏览器输入Neo4j 的本地网址(默认为http://localhost:7474),即可看到知识三元组的可视化视图,如图14 所示。
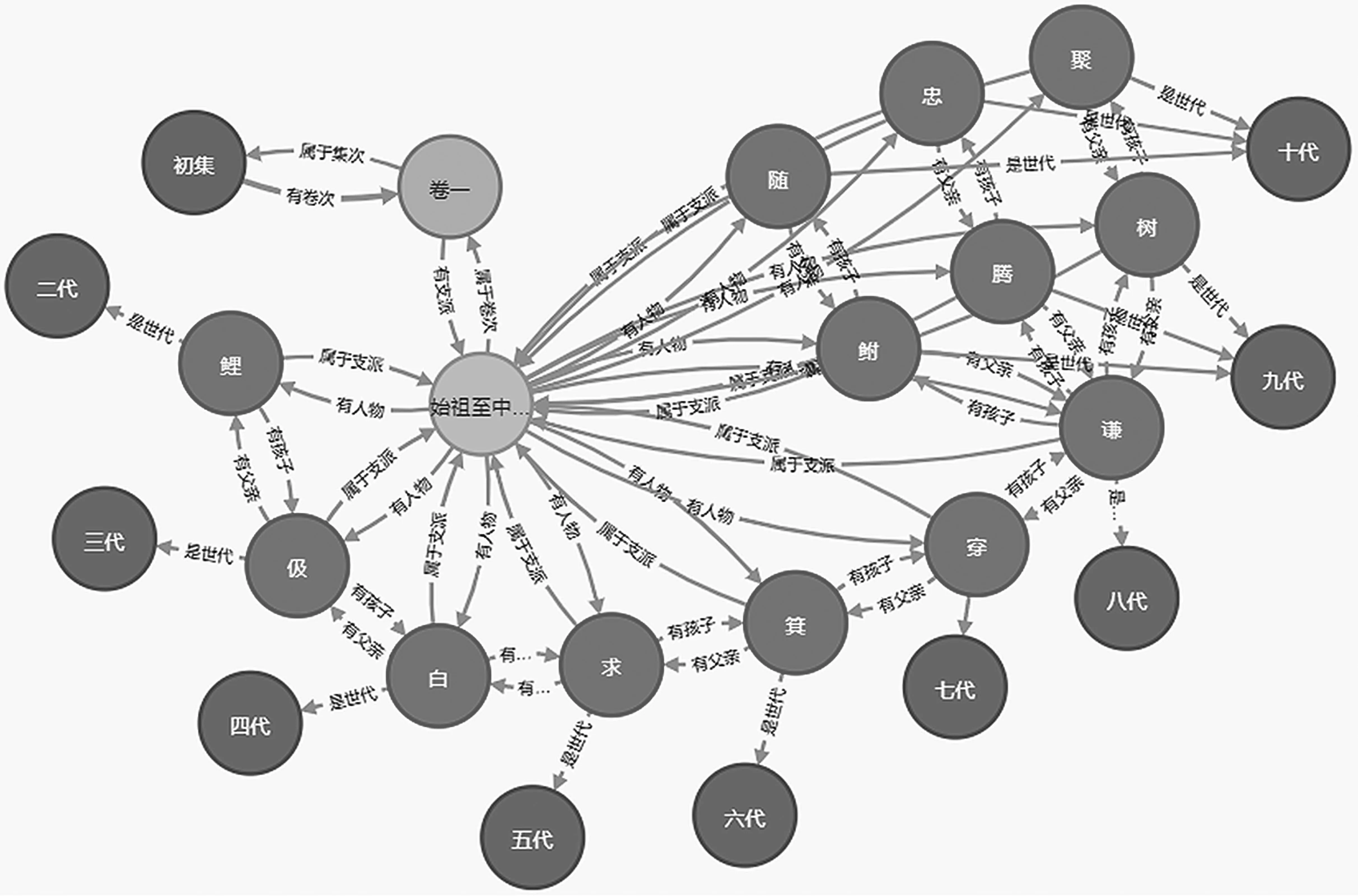
图14 孔子世家谱知识图谱可视化效果示例
5 结语
本文以《孔子世家谱》为基础,提出了世家谱本体构造方法,并使用该方法构建了世家谱本体模型。此外,使用基于规则的实体识别进行信息抽取,将数据存储在Neo4j 图数据库中,实现了孔子世家谱知识图谱的构建。孔子世家谱图谱化便于挖掘孔子世家谱中的隐藏关联,有助于儒家文化的研究学习。本文对孔子世家谱知识图谱构建进行了探索,但由于主要考虑使用《孔子世家谱》原始数据构建知识图谱,对其他相关文献利用不充分,在未来工作中将进一步挖掘蕴含在其他文献中的家谱知识,用以更新世家谱本体和孔子世家谱知识图谱。
猜你喜欢
华人时刊(2022年15期)2022-10-27
钟表(2021年5期)2021-11-10
景德镇陶瓷(2021年1期)2021-03-24
哈哈画报(2021年10期)2021-02-28
小型微型计算机系统(2019年6期)2019-06-06
文史春秋(2017年9期)2017-12-19
宁夏画报(2016年5期)2016-06-28
小天使·六年级语数英综合(2015年4期)2015-04-20
读者(乡土人文版)(2015年11期)2015-03-01
图书与情报(2013年1期)2013-11-16
