
一种改进的谱减法语音增强算法*
2021-06-22 01:57郭莉莉陈永红
通信技术 2021年6期
郭莉莉,陈永红
(南通大学杏林学院,江苏 南通 226000)
0 引言
在语音信号传输过程中,由于环境和传输信道等因素的影响,收到的语音信号中往往夹杂着噪声,使语音信号产生失真。语音信号增强算法主要是研究如何对失真的带噪语音信号进行有效的降噪处理,尽可能提取出纯净语音信号[1]。在语音增强算法中,基于短时谱估计的增强算法因效率高、计算简单、易于处理等特点而应用广泛。基于短时谱估计的语音增强算法可分为谱减法[2]、最小均方误差算法[3]和维纳滤波算法[4]等,其中基于谱减法的语音增强算法得到了广泛研究。文献[5]将压缩感知应用于谱减法语音增强算法,提高了语音的可懂度;文献[6]提出一种基于噪声谱估计的谱减法语音增强算法,通过端点检测和噪声估计,提高了语音信号的信噪比和清晰度。本文首先分析传统的谱减法语音增强算法的基本原理,针对传统的谱减法中存在的“音乐噪声”问题,引入过减因子和补偿因子两个参数对传统的谱减法进行改进,得到引入参数的改进形式谱减法语音增强算法。最后,仿真结果验证了改进算法的语音增强效果。
1 传统的谱减法
谱减法语音增强的基本原理是在语音信号和噪声通过加性模型构成带噪语音信号且语音信号与噪声之间互不相关的前提假设下,将带噪语音信号转化到频域进行“短时处理”,从带噪语音的短时谱中减去估计出的噪声短时谱,从而获得增强处理后的纯净语音信号的估计短时谱,最后通过傅里叶逆变换将其恢复回时域信号。
假设纯净语音的时域采样信号为s(n),噪声的时域采样信号为d(n),则带噪语音的时域信号y(n)可表示为:

由于谱减法是基于短时谱的估计算法,故首先对信号y(n)、s(n)和d(n)进行分帧、加窗处理,得到:

式中,yw(n)、sw(n)和dw(n)分别为y(n)、s(n)和d(n)经过分帧、加窗处理以后的结果。
对式(2)两边同时做傅里叶变换,得到:

式中,Yw(ω)、Sw(ω)和Dw(ω)分别为yw(n)、sw(n) 和dw(n)的傅里叶变换。
对式(3)等式两边同时求平方,可得带噪语音信号的功率谱为:
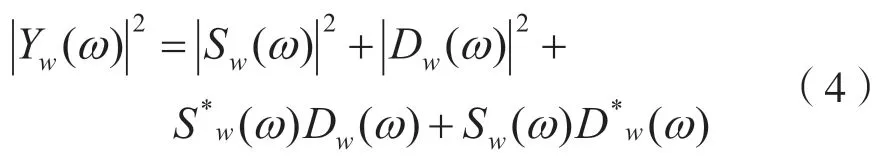
式中,S*w(ω)Dw(ω)+Sw(ω)D*w(ω)表示Sw(ω)和Dw(ω) 在相关性作用下产生的分量,也可写为交叉项2Re[Sw(ω)D*w(ω)],故式(4)变为:

基于前提假设了s(n)和d(n)之间互不相干的统计特性,可认为交叉项为2E{Re[Sw(ω)D*w(ω)]}=0。式(6)中噪声谱是未知的,可用前导无语音段获得的估计值来代替。一般采用平均法对噪声谱进行估计,即:
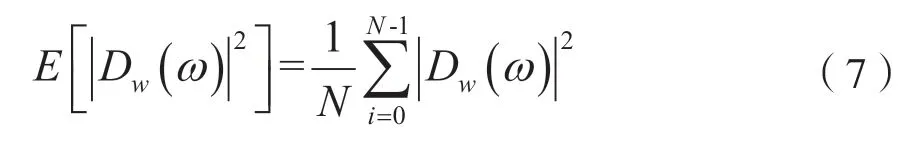
式中,N为前导无语音帧的帧数。基于语音的短时平稳特性,式(6)可以变为:

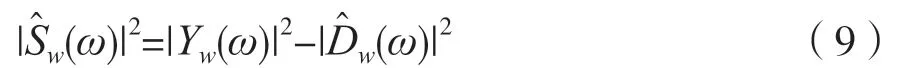

根据以上的分析和推导过程,谱减法语音增强过程的原理如图1 所示。
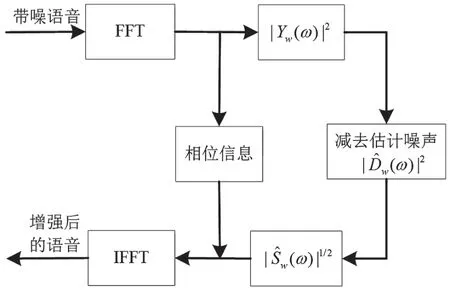
图1 谱减法语音增强原理
2 引入参数的改进形式谱减法
由传统的谱减法分析过程可以看出,谱减法是在整个语音段中减去相同程度的噪声功率谱估计值来获得增强后的纯净语音信号。在现实中,这种方法往往会带来很多不足。由于语音信号的能量分布不均匀,在频谱上语音的能量通常聚集在某一频段之内,特别是处于共振峰段的语音信号幅度比起噪声往往要高出很多。所以,单一地使用同一个标准去处理噪声分量无法使纯净语音的成分更为突出,也无法增加纯净语音的清晰度。加上噪声的随机性及复杂性,使得噪声的频域值与前导无语音段的噪声估计值往往存在较大差距,单一使用同一个处理标准会有大量的噪声残留下来,带来“音乐噪声”[8]。另外,在式(10)中,传统的谱减法使用了一种非线性方式,将功率谱相减后产生的负值设置为零,实际上是采用了一种调整选择法来进行处理,但把负值直接设置为零,待语音恢复到时域后可能会有明显的多频音颤音,影响人耳的听觉感受。针对上述不足,对谱减法进行优化,在式(10)的调整机制中引入参数a、b进行人为的控制选择。谱减法的改进形式如下:
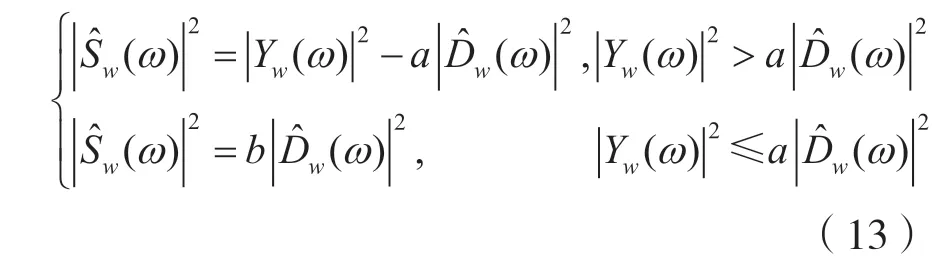
引入的两个参数a、b,其意义分别如下。
(1)a是过减因子,取值范围为a≥1。增大a的值,可以在带噪语音频谱上减去更多的噪声分量。噪声分量减小,会提高输出信噪比,且使得残留在频谱上的“音乐噪声”的窄带谱幅度减小,对残留噪声有很好的抑制作用,同时可以有效突出纯净语音的成分。
(2)b是补偿因子,取值范围为0 ≤b<<1。增大b的值,可以在频谱上保留极少的部分加性噪声分量,实则是为了减少毛刺而人为地为增强后的纯净语音信号填充入部分背景噪声。一是可以利用人耳的听觉掩蔽特性来弱化残留噪声;二是可以对残余的噪声有听觉上的平缓作用,降低人耳对残留噪声的感知度,且在一定程度上提高人耳的接受度。
参数a、b的取值在不同噪声环境下会带来不同的降噪结果。若a=1、b=0,就是传统的谱减法表达式。倘若参数a取值过大,从带噪语音信号的功率谱中减去过多的噪声估计功率谱可能会导致语音失真;如果参数b取值过大,可能会混合叠加入过量的背景噪声,不仅输出信噪比会下降,人耳的接受度也会降低。因此,引入参数a、b实则是一种基于谱减法的折中改进方式。
3 仿真结果与分析
本文在MATLAB 软件中对传统的谱减法和改进形式谱减法的语音增强效果进行仿真,其中采样频率fs=8 000 Hz,前导空白语音段长度为0.25 s,帧长为25 ms,帧移为10 ms。a=1、b=0 即为传统谱减法的仿真结果,对参数加以人为控制选择以a=4、b=0.001 作为改进形式谱减法的一组数据。仿真流程如图2 所示。

图2 仿真流程
以高斯白噪声作为背景噪声,输入信噪比分别取-5 dB、0 dB、5 dB,谱减法和引入参数的改进形式谱减法对语音信号的增强效果分别如图3、图4 和图5 所示。图3~图5 主要是从时域波形图的角度来观察。可以看出,输入信噪比越低,纯净语音被噪声湮没的程度越强。当输入信噪比为 -5 dB 时,几乎看不出存储纯净语音信号的波形段。但是,谱减法和改进形式的谱减法对不同输入信噪比的带噪语音处理后都减少了其中的噪声分量,尤其是改进形式的谱减法相比于谱减法,纯净语音成分的时域波形更加突出,降低了波形失真程度,使得语音信号的增强效果更为明显。
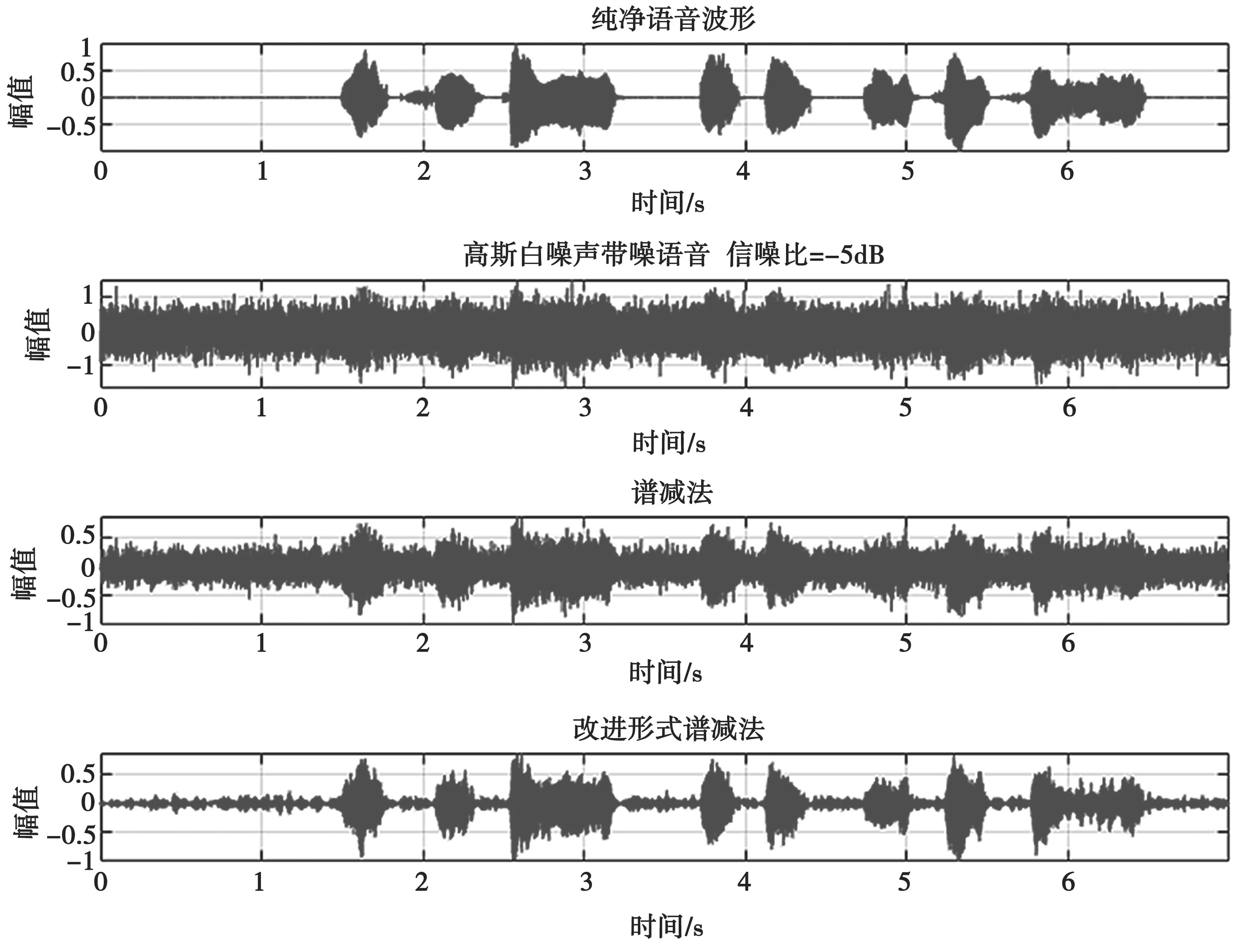
图3 输入SNR=-5 dB 时谱减法与改进形式谱减法语音增强效果对比
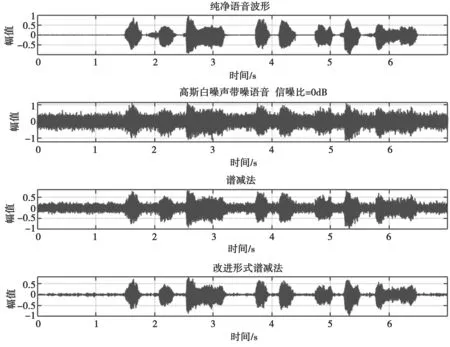
图4 输入SNR=0 dB 时谱减法与改进形式谱减法语音增强效果对比
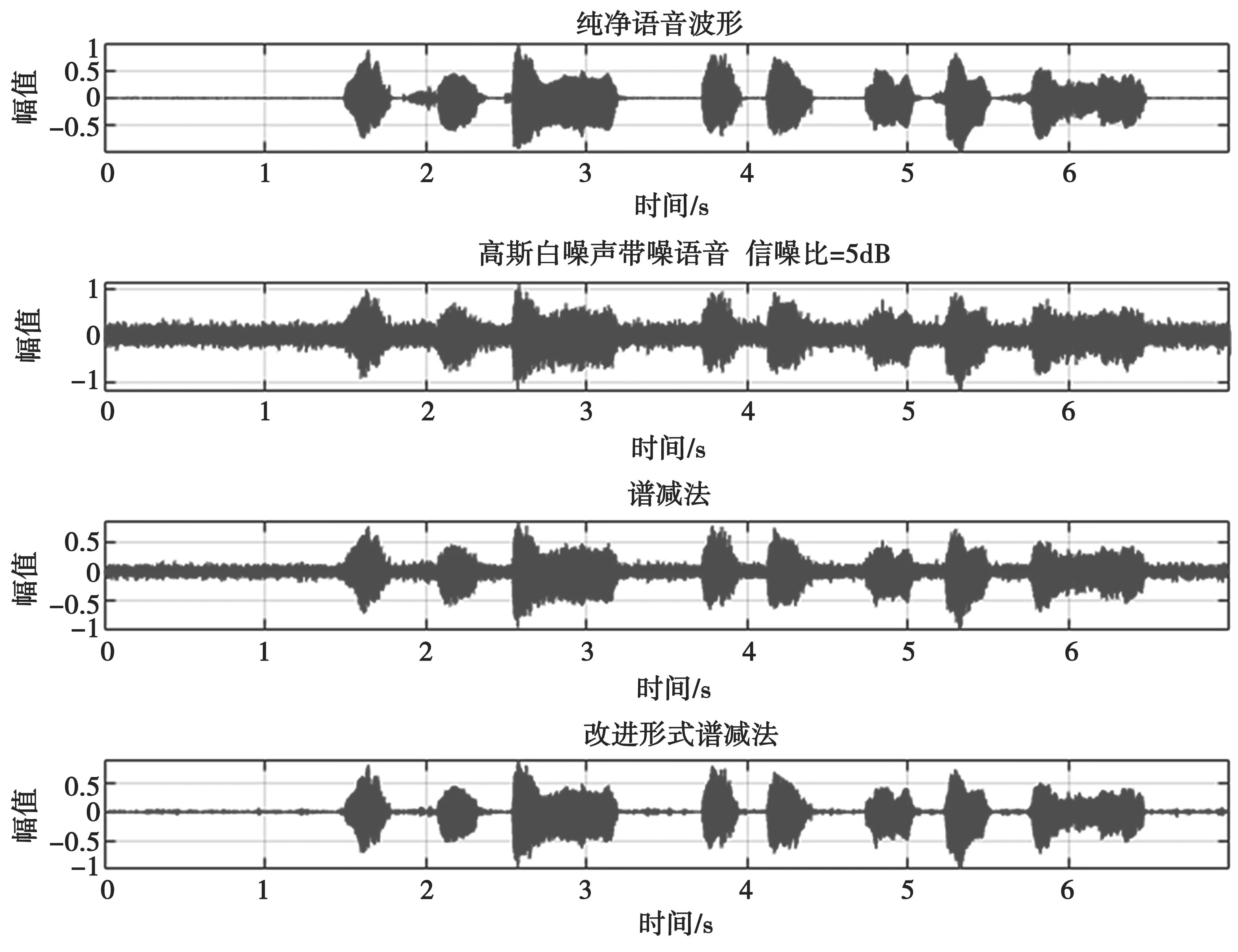
图5 输入SNR=5 dB 时谱减法与改进形式谱减法语音增强效果对比
信噪比改善(Signal-to-Noise Ratio Improvement,SNRI)定义为最终SNR 减去原始SNR。谱减法和改进形式谱减法的SNRI,如表1 所示。从表1 可知,随着输入信噪比的提高,谱减法和改进形式谱减法对应的输出信噪比随之增加,但改进形式的谱减法输出信噪比总体比谱减法提高5 dB 左右。在输出信噪比递增的同时,SNRI 的值却逐渐降低,说明基于谱减法的增强算法在低输入信噪比时对带噪语音的信噪比改善更明显。
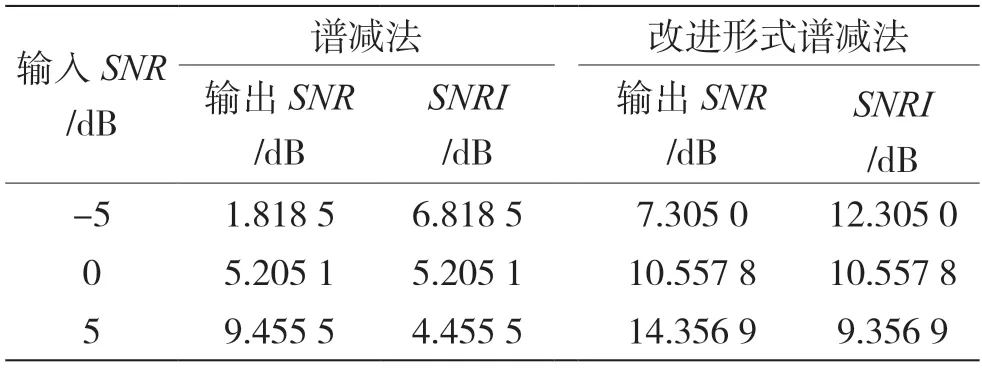
表1 不同强度噪声环境下的信噪比改善
谱减法和改进形式谱减法的MOS 评分结果,如表2 所示。从表2 可知,相比于谱减法,带噪语音在改进形式的谱减法处理后所获得的MOS 评分得到了更显著的提高。每组实验中,谱减法处理后的语音信号都可以听见不同程度的类似水流一般的间歇性的残留噪声,而经改进形式谱减法处理后的语音信号相比于谱减法来说,可以明显感受到残留噪声得到了减弱,语音听起来更加清晰,也较为流畅,减小了失真度,改善了人耳的接受度。
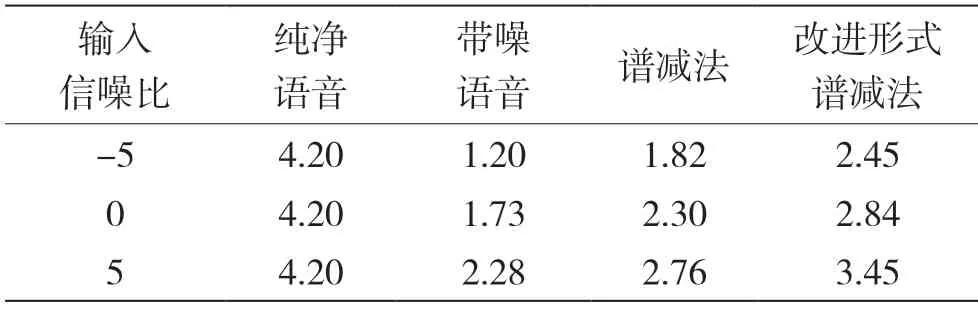
表2 MOS 评分
4 结语
经过传统的谱减法处理后的语音信号可以获得一定程度的增强效果,但会产生“音乐噪声”。本文提出引入参数的改进形式谱减法,引入过减因子和补偿因子两个参数。在这两个参数的共同作用下,算法可以在抑制“音乐噪声”的同时使语音信号更为突出。仿真结果表明,改进形式的谱减法语音信号波形的失真程度降低,信噪比改善更明显,语音增强效果更好。
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19
哈尔滨工程大学学报(2021年10期)2021-11-05
舰船电子对抗(2020年1期)2020-04-27
北京航空航天大学学报(2019年9期)2019-10-26
军事运筹与系统工程(2019年4期)2019-09-11
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
宇航计测技术(2019年1期)2019-03-25
小说界(2018年5期)2018-11-26
