
一种基于端到端模型的中文句法分析方法
2021-06-22 03:03:32邵帮丽奚雪峰付保川
苏州科技大学学报(自然科学版) 2021年2期
杨 颢,徐 清,邵帮丽,奚雪峰*,付保川
(1.苏州科技大学 电子与信息工程学院,江苏 苏州 215009;2.苏州市虚拟现实智能交互及应用技术重点实验室,江苏 苏州 215009;3.苏州市公安局,江苏 苏州 215131)
句法分析作为自然语言处理中的一项核心任务,对信息抽取、自动问答及机器翻译等自然语言处理上游任务起着重要的作用。句法分析就是识别出句子中所包含的句法单位以及句法单位之间的相互关系,并将分析结果自动表示成句法树结构。其主要工作可看作是从连续的句子线性序列到具有形式化树结构的转换任务[1]。
句法分析工作最早开始于20 世纪50 年代,人们在进行机器翻译任务研究时发现必须找到一种更深层次的句子表达方法,便开始了自然语言句法结构分析任务的研究。目前的句法分析方法主要分为基于规则和基于统计两大类[2]。英文句法分析任务开始较早,同时有认可度较高的数据集支持,其中具有代表性的如美国宾夕法尼亚州大学标注的宾州树库[3],因此新的算法往往首先在英文数据集上进行实验,最终延伸到其他语言的研究。Cross 等人[4]结合LSTM 神经网络基于句子成分的跨度(span)提出了一个移进归约的系统,在英文宾州树库上的实验结果F1值为91.30%,法语上F1值为83.31%;Socher 等人[5]则使用了一个结构递归的神经网络(Recursive Neural Network,RNN)来学习句法树中的递归结构,也取得了一些成果;Hall 等人[6]提出直接从句法树表层提取有效特征而不是通过分析句法树内部标记关系,将句法分析工作的难点转化成了特征工程,从而不需要考虑句法问题,大大降低了句法分析算法的复杂度,其F1值达到了89.2%。
相对于英文句法分析,中文句法中语义关系更加复杂,同时因为缺乏较为成熟的标注理论,标准汉语树结构语料库的建设也相对滞后,这使得汉语的句法分析技术发展缓慢[2]。Fung P 等人[7]采用转换学习的方法进行分词/词性标注,用极大熵模型识别短语,在第一版CTB 上测试F1值达到了75.09%;徐润华[8]首先自行构建了一个具有百万级别搭配型的词语搭配知识库,将词语搭配知识和基于句法功能匹配的句法分析算法相结合,构建了一个基于词语搭配知识和语法功能匹配的句法分析器(CGFM),在新华社新闻语料开放数据集上F1值约80%。
因为中文相对复杂的语法结构,中文的句法结构分析大都聚焦于对句子进行分词和词性标注,分词和词性标注的好坏直接决定了分析器的好坏。基于这一现状,笔者尝试采用双向LSTM 神经网络,并引入注意力机制[9],提出一种深度的端到端模型,将分词、词性标注及句法结构放在一起分析,简化了句法分析任务,降低了研究人员在分词和词性标注上的专业性要求。在中文标准数据集CTB9 上的实验表明,具有一定可行性和较好的识别率。
1 任务描述
1.1 CTB 理论
CTB 项目1998 年开始于宾夕法尼亚州大学,自2001 年发布Chinese Treebank 2.0 以来,16 年发布的最新版Chinese Treebank 9.0 已经成为了一个具有多样化数据来源且数量庞大的中文句法结构数据集。宾州英文树库(PTB)的建立,验证了英文词性标注及语法分析器English Part-Of-Speech(POS)Taggers 和Parsers的可用性,为中文树库的发展奠定了基础[3]。中文树库建设团队借鉴英文树库经验并寻求专业的中文语言学家的帮助,最终将树库的标注任务划分为分词、词性标注和切分短语结构三个子任务,以实现对不同层次的句法成分组合特点进行细致的描述[10]。其标注策略沿用了英文骨架分析(skelton parsing)的思想,形成比较扁平的句法结构树,并对短语的功能进行了标记[11]。CTB 结构如图1 所示。

图1 CTB 数据集结构
1.2 任务说明
人工将大量的普通中文语句标注成标准化的句法结构树,将耗费巨大的人力物力。同时即便有统一的标注存在,但其中仍然存在着标注人员个人的主观色彩,不可避免的使得最终的标注标准化结果间存在差异。该文的主要任务是借用深度神经网络,完成从自然语句到标准化句法结构树的自动生成标注工作。
2 模型
2.1 预处理
中文树库的数据集分为raw、segmened、postagged、bracketed 四个部分,文中选取了其中raw 和bracketed两部分作为原始数据来源。利用word2vec 模型对原句进行词向量转换[12],并将原数据转换成包含原句及其对应的树结构的二元组作为神经网络的输入来训练模型。最终实现输入原句得到相应的树结构的效果。
2.2 算法流程
如图2 所示,文中所采用的方法,首先,将CTB 数据集原始数据转换成标准的二元组作为输入,该二元组包括原始句子及其对应的句法分析树;然后,通过Tuple2Instance 方法,将标准二元组转化成模型的输入Instance,每一个Instance 包括句法树中的句子关系、短语关系、词性标注、分词四个部分;接着,将Instance 作为输入,训练下文所提到的Encoder-Decoder 模型;最后,经过调参及训练得到最优模型。
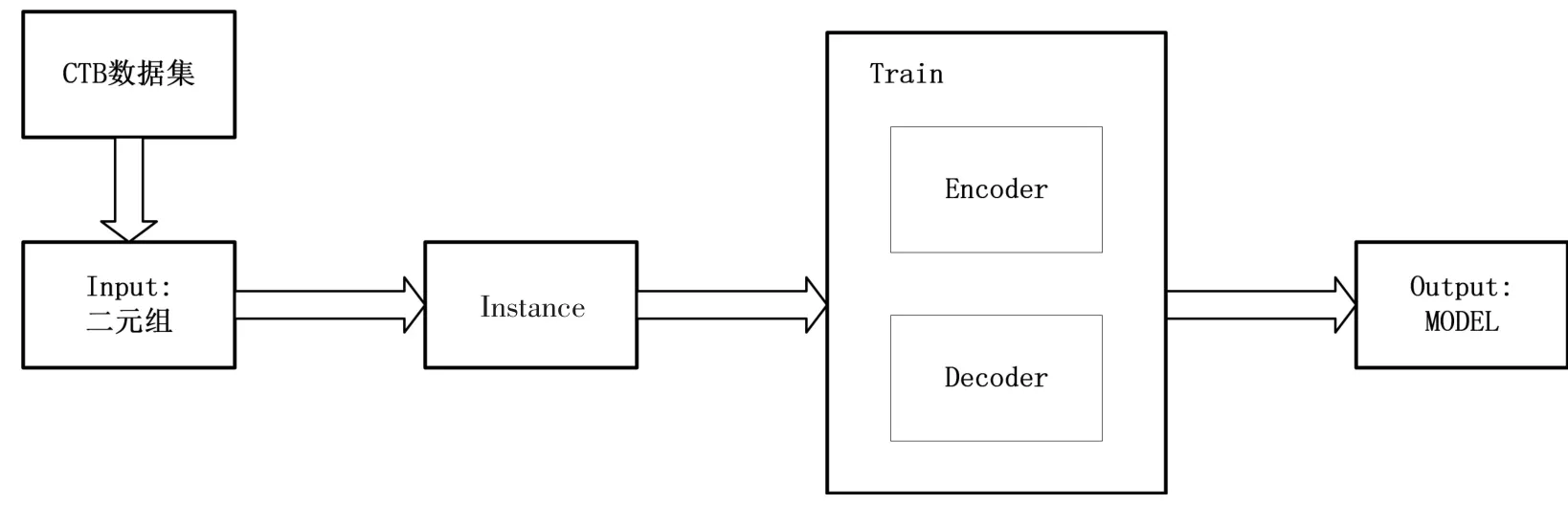
图2 算法流程图
2.3 模型结构
将树结构的自动生成看作一个Seq2Seq 任务[13],输入中文自然语句X=(x1,x2,…,xn),其中xi表示句子中的第i 个单词,n 表示句子长度;输出序列Y=(y1,y2,…,ym),其中m 表示得到的树结构序列长度。希望由给定的输入序列X 得到语义解析树Y 的条件概率p(Y|X)

其中yj表示输出序列中的第j 个token,Y1j-1表示输出序列中的第1 个到第j-1 个序列,表示输出的自然语句。笔者针对这个Seq2Seq 任务,结合CTB 的结构[10]表示和Liu 等人[14]相关工作提出了一种Encoder-Decoder 模型。模型结构如图3 所示。

图3 文中模型结构
2.3.1 编码结构
文中采用双向的长短时记忆网络(bi-LSTM)作为编码器[15],意在通过该编码器将输入的中文句子Χ 转化成向量表示。首先,将句子中的每一个token xi都转化成一个向量表示,其中表示随机初始化的词嵌入,表示预训练的词嵌入,W1表示(dw+dp)×dinput维度的矩阵,其中w、p 和input 分别表示分词的词向量、预训练的词向量和输入分词的维度,b1是一维n 列的随机向量,“+”表示将横向拼接在一起。最终通过该编码器得到句子的隐层单元表示

2.3.2 深层解码结构
实验证明,输入序列的长度将对神经网络的预测结果产生一定影响,而自然汉语语句标注成标准的CTB 树结构后,其长度增加了不少。在文中的测试集上统计显示,自然语句的平均长度为30,标注过后的树结构平均长度为99。笔者对CTB 树结构分析发现,每个树结构序列中包含Syntactic Brackets、POS tags、分词三个部分。基于此结构,文中提出了一种深层解码结构,将CTB 树结构序列拆分成以下三个层次,分别为分词,其中p、u、v 分别表示对应的个数。每个部分在端到端框架下分开进行解码预测,其概率分布可表示为

①Syntactic Brackets 预测
在这里采用了一个序列解码器如图3 第一层上所示,预测结构中的每一个token 对应树结构中的父节点,词条间关系及词条词性当作其子节点,以插入的机制插入合适的位置,该解码器的隐层单元如下

结构中的token 的概率分布表示如下



其中权重βji为

②POS tags 预测
POS tags 的预测与之前所做的Syntactic Brackets 预测密切联系,在每个Syntactic Bracket 中可能包含着k 个分词和k 个POS tags,因此,可以将POS tags 表示为,其中表示第k 个中的第mk个POS tags。
其词向量表示

故该解码器的隐层单元表示如下

POS tags 预测的概率分布如下

③分词预测
分词的预测基于Syntactic Brackets 和POS tags 预测,每一个关系内仅对应一个分词。故分词序列可表示为;词向量表示为。POS tags 的隐藏单元的输出作为分词预测的输入,其解码单元隐藏层如下

分词预测的概率分布如下

3 实验
3.1 实验选取的数据
中文树库共包含来自于报刊新闻、杂志文章、广播会话等八个大类的3 726 条数据(见表1)。该次实验分别选取了新闻、杂志文章及微博三个大类的1 155 篇文章作为数据的原始输入。此外笔者对这1 155 篇文章进行了简单的数据清洗,选取了其中句子长度在20 到80 之间的句子,并且去除掉了其中含有特殊符号及网址的句子,最终得到了10 012 条数据,共包含23 198 个字符。并通过word2vec 将数据训练得到100 维的词向量。文中选取了10 012 条数据中的7 288 条数据作为训练集,1 724 条数据作为验证集,1 000 条数据作为测试集进行实验。

表1 CTB 数据来源及分布
3.2 参数设置及实验设备
笔者的实验软件采用Python(2.7.12 版本)、Pytorch(1.1.0 版本)、CUDA(10.1 版本),实验操作系统为Ubuntu16.04;硬件计算平台采用英特尔I5、16G 内存、英伟达GTX2080TI、11G 显存。实验模型在J.M.Liu[14]模型基础上,经过预处理等代码修改后形成该系统模型代码(模型开源代码地址:https://github.com/dressnotycoon/Chinese-syntactic-analysis/)。
3.3 算法对比系统
与文中实验模型相比对的系统有如下五类:
①HMM+中心驱动模型[16]采用传统机器学习方法,首先,应用基于隐马尔科夫模型(HMM)的方法进行一体化的分词/词性标注;然后,利用中心驱动模型进行短语识别。在宾州中文树库CTB1 数据集上取得了F1值76.4%的成果。
②K-best 句法分析器融合算法[17]提出了一个基于线性模型的通用框架,以结合来自多个解析器的k 个最佳解析输出。通过将当时表现最好的头部驱动的词法化模型和基于潜在注释的非词法化模型相结合,在宾州中文树库CTB5 上F1值为85.5%。
③向上学习方法改进的移进-归约算法[18]在传统的移进-归约句法分析系统上进行改进,首先利用伯克利句子分析器对大规模的无标注数据进行自动标注,将标注的结果再作为改进分析器的额外训练数据,在宾州中文树库CTB5 上F1值为82.4%。
④基于条件随机场模型的分块算法[2]将汉语句法分析分为三个阶段:首先,基于条件随机场模型将句子分块;其次,对各句子块进行句法分析得到句子块级别的句法树;最后,将各句子块句法树整合成完整的句子结构树。在宾州中文树库CTB8 上F1值为75%。
⑤抽取lookahead 特征的移进-归约算法[19]利用一个快速的神经模型来提取前向特征,并构建了一个双向的LSTM 模型,该模型利用完整的句子信息来预测每个单词的开头和结尾的成分的层次结构,在宾州中文树库CTB5 上F1值为85.5%。
3.4 实验结果
这里笔者使用精确率、召回率、F1值[20]来评价文中模型的优劣,其中精确率表示预测的结果中正确的短语结构个数,计算公式为

召回率表示我们预测结构的全面性,计算公式为

精确率和召回率通常情况下相互制约,因此,笔者按照评价习惯引入了F1值来平衡两者关系,即

首先对在验证集上得到的F1值分布进行了统计,如图4 所示。其中F1值超过0.9 的数据占总测试数的13.6%,且这部分平均的F1值为0.956;F1值超过0.8 的数据占总测试数据的47.3%,且平均F1值为0.876;F1值超过0.7 的数据占总测试数据的82.1%,且平均F1值为0.826。

图4 F1 值分布
此外,该文也对验证集上不同长度的语句的F1值进行了统计分析。文中验证集的句子长度在5 到60 之间,平均长度为29,如图5 所示,发现当句子长度增大的时候不管是精确率还是召回率都缓慢的降低,其中在句子长度小于20 的时候表现较好,但是整体上维持在一个不错水平,F1值保持在0.70 以上。

图5 不同长度的语句的F1 值、召回率及精确率
最后选取了同样使用宾州中文树库CTB作为数据集的算法系统,与文中所提到的方法进行了对比。由表2 可见,模型1 由于宾州中文树库CTB1 发布较早、数据量较少,因此结果相对较差。模型2 由于融合了当时表现极为优秀的句法分析系统,因此也有较好的结果。模型3和模型5 均针对移进-归约算法做出了一定的修改,其中模型3 将其他句法分析器得到的分析结果作为自己分析器额外的训练数据,其他分析器的精度也将影响其分析器本身的结果,故其F1值略低于模型5。模型4 将句子分块操作,再整合各块句法子树的方法,在一定程度上影响了句子的完整性,其在CTB5 上的结果较差,但针对其文中提到的特定信息检索系统有一定帮助。由表2 可知,模型6 具有可行性且具有一定分析效果,但仍然有进一步提升的空间。未来继续增加训练数据,相信将得到更好效果。

表2 算法系统对比
4 结语
深度学习及神经网络算法给句法分析任务提供了新的方法和可能,但完全的中文句法结构分析任务仍然是中文信息处理中的一个难题。目前还面临着诸多的难题,比如:缺少相关的树结构数据集、照搬英文的标注理念是否完全适合中文的语法习惯等。文中采用的深度学习算法,直接提供了一种序列到序列的转换方法,使研究人员不需要再对中文分词及词性标注做太多的工作,但是仍然需要依赖庞大的数据量。未来将逐步扩大训练的数据量,并探索新的方法,能够更好的适应中文特有的句法结构,以期望进一步提高分析器的性能。
猜你喜欢
智富时代(2019年6期)2019-07-24 10:33:16
浙江大学学报(理学版)(2017年1期)2017-02-07 09:53:45
山西青年(2017年7期)2017-01-29 18:25:26
国际汉语学报(2016年1期)2017-01-20 08:21:35
高中生·天天向上(2016年9期)2016-11-22 09:10:34
电脑知识与技术(2015年14期)2015-07-24 11:30:20
浙江大学学报(工学版)(2015年6期)2015-03-01 01:18:24
河南科技(2014年11期)2014-02-27 14:17:57
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
当代修辞学(2011年4期)2011-01-23 06:40:52
