
多策略汉英平行语料的过滤方法研究
2021-06-22 08:32张国成王颖敏钟恩俊江秋怡朱宏康陈毅东史晓东
厦门大学学报(自然科学版) 2021年4期
张国成,王颖敏,钟恩俊,江秋怡,江 舫,章 栋,朱宏康,陈毅东,史晓东
(厦门大学信息学院,福建 厦门 361005)
主流的神经机器翻译系统需要大量的语料进行模型训练,而语料的质量很大程度影响了翻译模型的性能[1],因此对语料进行过滤来确保语料质量尤为重要.语料过滤的主流方法一般是采用规则方法、统计方法和神经网络方法相结合的策略,其中统计方法和神经网络方法非常多,如Junczys-Dowmunt[2]提出对偶条件交叉熵(dual conditional cross-entropy),Snchez-Cartagena等[3]从各种打分函数中学习权重的方法,还有不少研究者试图从词嵌入(word embedding)[4-6]角度衡量句对平行程度.
为了解决汉英平行语料中带噪声的问题,本文设计了两种不同的模式:单系统模式和多系统融合模式.其中单系统分为规则系统、Zipporah系统、词对齐系统、语言模型系统、翻译模型系统和双语预训练模型系统.多系统融合则是在单系统的基础上,将表现优异的系统的打分加权融合,融合的方式有两种:一种是将得分相加,另一种是将得分相乘,以期获得优异的翻译性能.
1 系统描述
本文提交的系统所使用的方法可分为3类:规则方法、统计方法和神经网络方法,系统的整体架构如图1所示.其中规则方法主要通过设计一系列规则来过滤质量明显不符合要求的语料;统计方法包括Zipporah系统、词对齐模型和语言模型,通过在大量干净的语料上统计特征信息达到过滤目的;神经网络方法包括翻译模型和双语预训练模型,在干净的语料上训练得到泛化能力较强的模型,然后对带噪声的语料进行过滤.最后,根据不同方法的成绩,将表现优异的方法加权融合,得到最终的干净语料.

图1 系统架构图Fig.1 System architecture diagram
1.1 规则方法
Pinnis[7]提出利用句子长度比例、最大句子长度、唯一句子对等过滤方法对语料进行过滤.借鉴其工作,本文制定了4条规则:
1) 长度过滤规则,源端或目标端句子长度超过80个单词的句对记0分,否则记1分;
2) 长度比限制规则,源端与目标端句子长度比超过1.7的句对记0分,否则记1分;
3) 语种识别规则,用langid(https:∥github.com/saffsd/langid.py)识别源端和目标端语种,语种不正确的句对记0分,否则记1分;
4) 去重规则,重复的句对第一次出现记1分,否则记0分.
借助上述4条规则,针对给定的句对可以得到一个四维特征,每一维的值为0或1.
1.2 统计方法
1.2.1 Zipporah系统
Chaudhary等[8]尝试将Zipporah(https:∥github.com/hainan-xv/zipporah)作为融合系统的一部分,取得了不错的成绩.Zipporah系统是一种快速且可扩展的系统,可以从大量嘈杂的数据池中选择任意大小的“好数据”,用于神经机器翻译模型的训练.其原理是:首先将句子映射到特征空间,特征空间包含充分性得分和流利度得分两个特征;然后使用逻辑回归进行二分类,类别分别是“好数据”和“坏数据”;最后采用式(1)进行归一化,得到平行程度得分
(1)
其中x为Zipporah系统的得分.
1.2.2 词对齐模型
Zarina等[9]认为非平行句对的词对齐很少,因此本文考虑利用词对齐进行语料过滤.首先用fast_align(https:∥github.com/clab/fast_align)词对齐工具在第16届全国机器翻译大会(CCMT 2020)提供的不带噪声的汉英平行语料上训练,然后对带噪声的语料进行预测,可直接得到句对的词对齐分数.由于在fast_align工具中,词对齐分数的计算方法是将词对齐概率进行对数求和,所以句子越长,词对齐分数越小,意味着系统偏好短句子.为了减少句子长度对词对齐分数的影响,本文中采用式(2)计算平行程度得分:
(2)
其中,salign为句对的词对齐分数,lsource和ltarget分别为源端和目标端句子的长度.
在将句对的词对齐分数按照式(2)处理后,按照分数从高到低进行排序,经过统计发现词对齐分数大于等于-4.5的句对数量约为400万,大约1亿个单词.本文中认定这些句对的质量较好,它们在归一化后的分数应该较高,于是设计了式(3)进行分数的归一化:
(3)
1.2.3 语言模型
因为语言模型可以过滤掉不合语法的数据,所以本文中考虑使用语言模型对语料进行过滤.本文选择不带噪声的语料库生成语言模型,并利用该语言模型计算待过滤数据集的困惑度(perplexity,p)分数.
具体地,在不带噪声的双语语料上使用SRILM(https:∥github.com/BitSpeech/SRILM)工具,为汉英语料分别训练一个5元语法(5-gram)语言模型,并使用这个语言模型分别计算待过滤双语语料中汉英句子的困惑度分数.对于得到的汉英句子困惑度分数,本文使用了两个打分策略:句子级困惑度分数和单词级困惑度分数.
为了便于后续处理,将困惑度分数进行归一化处理.在归一化操作中,本文基于经验设计了一系列分段函数.
对汉语待过滤语料句子级困惑度分数,本文设计的归一化的分段函数如式(4)所示:
(4)
对英文待过滤语料句子级困惑度分数,设计的归一化分段函数如式(5)所示:
(5)
另外本文考虑了单词级的困惑度分数,分别计算了汉英数据集上每句话的词平均困惑度分数与整体数据集上的词平均困惑度分数,并设计了两个分段函数对两者的差值进行归一化处理.由于数据中存在句子很短但困惑度值非常大的现象,所以本文在计算整体数据集的词平均困惑度分数的时候,忽略了困惑度超过1万的句子.
对汉语待过滤语料单词级困惑度分数,设计的归一化分段函数如式(6)所示:
(6)
对英文待过滤语料单词级困惑度分数,设计的归一化分段函数如式(7)所示:
(7)
最终,每个平行句对将得到4个特征分数.
1.3 神经网络方法
1.3.1 翻译模型
基于以下设想:如果句子a与b是平行句对,那么a与b的语义相似,则将a翻译成a′时,a′与b的语义仍然相似.Parcheta等[10]先对目标端句子进行翻译,然后计算译文与参考译文之间的相似度,这种方法得到了更好的翻译效果.
为实现上述设想,首先应训练一个英汉翻译模型,然后利用翻译模型将英文句子翻译成对应译文,最后计算译文与参考译文之间的相似性.对于相似度计算,本文采用了两种指标:基于词的编辑距离和基于预训练词向量的余弦相似度,最终形成2维相似度特征.
1) 模型设计
根据上述简介,若想计算翻译译文与参考译文之间的相似度,首先应得到翻译译文,因此需要一个翻译模型.本文采用了清华大学开源的神经机器翻译工具THUMT(https:∥github.com/THUNLP-MT/THUMT.git),该系统依赖较少,训练简便,适合快速训练神经机器翻译系统.
训练集数据来源于CCMT 2020汉英翻译任务提供的平行语料,对其进行分词和小写化,并过滤掉长度超过150个单词的句对,形成约1 000万对的训练数据.开发集为CCMT 2020汉英平行语料过滤任务指定的开发集.
主要的训练参数选择默认,并运行约20轮,保存开发集上双语互译评估结果(BLEU)最高的5个模型,然后做模型平均,融合成一个最终模型,方向为英→汉,将其记为M0.接着利用M0对带噪声的平行句对中的英文句子进行解码,得到对应的汉语译文.
2) 基于词的编辑距离
该指标本质上是编辑距离,不过计算两个句子匹配程度的粒度为词,而不是单个字符.设a′与b为两个分词后的汉语句子,其中a′为英文源句a的翻译译文,那么编辑距离La′,b(|a′|,|b|)可以通过式(8)迭代计算得到.
(8)
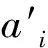
在计算过程中,a′看作翻译译文,b看作参考译文,考虑在带噪声的数据中,作为目标端的b不一定与源端相对应.当a与b不对应时,a′和b距离较大,认为此句对a和b平行程度较差,可以将句对过滤;反之距离较小则意味着翻译模型给出的译文和实际参考之间相似度较高,源句与目标端句子的平行程度较高.根据编辑距离,最终句对的平行程度得分如式(9)所示:
(9)
3) 余弦相似度
由于翻译模型M0可以将英文源句a翻译成对应汉语译文a′,所以可以仅借助汉语词向量计算a′和b之间的语义相似度.本文中之所以不用汉语和英文两套单独的词向量,是因为语种差异会造成语义空间的偏差,导致语义相似度计算不准确.训练汉语词向量使用的数据与机器翻译训练集中的汉语端数据相同,训练工具采用gensim(https:∥radimrehurek.com/gensim/models/word2vec.html)工具包,训练窗口取5,去掉词频低于5的词,并且考虑到相似计算压力较大,因此维度取128维,训练10轮,最终保存模型记为M1.
对于a和b句对,a′是a的汉语译文,那么利用M1,使用余弦函数即可得到该句对平行程度得分,如式(10)所示:
sa,b=cos(a′,b|M1).
(10)
1.3.2 双语预训练模型
考虑到预训练模型包含大量的语义知识,因此本文利用sentence-BERT(sentence bidirectional encoder representations from Transforment)模型[11]在CCMT 2020给定的汉英单语语料上进行微调,分别获得汉语与英语的句向量.但是通过该方式获得的句向量可能存在不同语种间向量空间未对齐的问题,即不同语种中意义相同的句子被映射到向量空间中的不同位置.因此评估两个不同语言的句子之间的平行度时,本文采用马氏距离平方之比作为度量指标.
马氏距离表示数据的协方差距离,是一种计算两个未知样本集相似度的有效方法.使用马氏距离等同于通过数据转换的方法,消除样本中不同特征维度间的相关性和量纲差异,使得欧式距离在新的分布上能有效度量样本点到分布的距离.假设向量x表示均值为μ、协方差矩阵为Σ的多变量随机向量,则其到中心的马氏距离计算式如(11)所示:
d2(x)=(x-μ)TΣ-1(x-μ)=
(11)
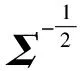
在本文系统中,首先将每个句向量进行标准化,使得其服从均值为0的随机分布.对于每个已经重新中心化的汉英句子向量对(l1,l2),考虑变化空间中的3种情况:
(12)
(13)
(14)
其中e1,e2,e分别表示拼接向量[l1,0],[0,l2],[l1,l2]在马氏空间中的向量.通过以上3种情况,可以利用下面的马氏距离平方之比来度量两种语言句子之间的平行度:
(15)
如果两个句子具有相同的含义,则该句对在马氏空间中的向量e的可能性不应小于孤立的单个句子e1、e2在马氏空间中向量的概率,m值越大,两个句子之间的平行度越高.
最后,将m值进行归一化,利用式(16)来衡量两个句子之间的平行度:
m′=1-m,
(16)
即m′越小,两个句子之间的平行度越高.
2 实验与结果
2.1 数据处理
本文语料过滤系统的开发集、训练集和测试集分别为来自WMT 2018和WMT 2019的汉英新闻测试集(分别包含3 981句及2 000句原文和对应参考译文)、CCMT 2020不带噪声的汉英平行语料(902万汉英句对)和CCMT 2020带噪声的平行语料(3 432万汉英句对).
其中对汉语语料使用jieba(https:∥github.com/fxsjy/jieba)分词工具进行分词,对英语语料使用Moses(http:∥statmt.org/moses/)脚本分词和小写处理.由于数据量过大,防止在解码时出现显存溢出问题,所以将小写后的噪声数据进行截断处理,每一个句子最多保留前256个单词.同时为了缓解未登录词(out of vocabulary,OOV)问题,提高模型对稀有词和OOV的处理能力,本文中使用基于子词切分的方法,对汉语语料和英语语料使用字节对编码(BPE,https:∥github.com/rsennrich/subword-nmt)进行切分.此外,为防止一次性加载并解码3 400万句对造成的内存紧张和解码时间过长等问题,本文对带噪声的数据进行切分,每份包含200万条数据.最后,去掉长度大于150个单词的句子,再去掉语种错误的句子.
2.2 评测方法
在对带噪声的语料打分后,按照得分从高到低进行排序从而实现语料过滤。本文选择约含1亿个词的平行句对,使用CCMT 2020主办方指定神经机器翻译工具Marian,将前面所选择的平行句对作为训练集,在Marian上进行训练,然后在CCMT 2020主办方指定测试集上进行测试,使用机器翻译领域常用的BLEU指标作为评价指标以评测过滤语料的质量(结果见2.3和2.4节)。
最终参赛者需向CCMT 2020主办方提供1亿个词和5亿个词的两份过滤后的语料,CCMT 2020主办方将参赛者提交的语料作为训练集,使用Marian工具训练,保证训练过程中所有参数一致,在指定测试集上进行测试,以此作为参赛者最终成绩(结果见2.5节)。
2.3 单系统实验
由于各个系统之间无依赖关系,所以可以并行进行各个系统的实验.具体地,选定规则系统、Zipporah系统、词对齐系统、翻译模型系统、语言模型系统、双语预训练模型系统这6个作为基础系统,分别依据每个系统对带噪声数据的打分从高到低进行排序.需要注意的是,若有些系统有多个打分,则各个分数相加或各个分数相乘求综合得分,权重均是1.0.再使用CCMT 2020提供的机器翻译工具Marian训练神经机器翻译系统,计算开发集上的翻译结果与参考译文之间的BLEU值.根据每个系统对应BLEU值的高低选择优势特征,尝试在优势特征之间组合,得到更优的排序.
受计算资源限制,本文对每个系统只训练10轮,取开发集上最高的BLEU值作为该系统的最终成绩.每个系统的成绩参考表1.其中,随机系统将数据随机打乱,同样采样1亿个单词的平行语料,随机系统0只对数据随机打乱1次,随机系统1对数据随机打乱5次.此外,为探究领域对成绩的影响,本文从不带噪声的平行语料中采集了1 409条汉语新闻样本和1 434 条汉语非新闻样本,从中划分出200条新闻和200条非新闻作为开发集,训练一个基于卷积神经网络(CNN)的领域二分类器.从表1可以看出,各系统成绩相差较大.随机系统1的结果甚至超过了大部分的系统;最好的是基于翻译模型的译文与参考的相似度指标;领域分类器效果最差,这是因为领域分类器主要用来选择新闻语料,而结果表明测试集中新闻语料占比可能不高,从而导致表现较差.注意到翻译模型过滤后的语料中排名靠前的句子对句长并不是非常敏感,因此大量长度适中的句子都有希望排到前面,而其他系统得分都倾向于短句优先.规则系统虽然能无差别对待长句和短句,但由于无法衡量平行程度,所以在独自发挥作用时效果并不突出.

表1 各单系统对应的BLEU值Tab.1 BLEU values for each system %
将领域分类器用于带噪声数据的测试,并将新闻数据的预测概率作为得分.其中领域二分类器性能参考表2,可以看到该分类器性能较高,但从表1中可以看到,基于该分类器的翻译性能很低,因而可以认为在此任务中,领域对翻译模型的影响并不大.因此该分类器仅用做验证,本文并未将其纳入到最终的系统中.
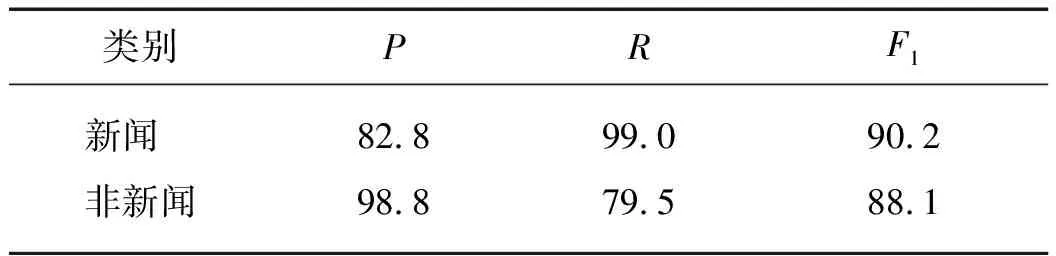
表2 基于CNN的领域二分类器性能Tab.2 Performance of two field classifier based on CNN %
2.3 多系统融合实验
结合表1的结果,本文中认为翻译模型系统、词对齐模型系统、语言模型系统以及双语预训练模型系统是潜力相对较大的系统,因此优先对这些系统之间的组合进行融合测试.多系统融合的方法相对比较简单,即将各系统的打分进行融合,然后再重新排序.融合的方法有2种:按权重相乘、按权重相加.大部分情况下,仅尝试了权重均为1.0的融合.表3展示了部分实验结果,可以看到融合系统总体上成绩超过单系统成绩,而且相乘的方法总体优于加法.融合系统成绩更好的主要原因是因为不同系统从不同出发点对句对平行程度进行度量,所以多系统融合后能对句对有更全面评价,这也表明了方法融合的有效性.

表3 部分系统融合的结果Tab.3 Partial system integration results %
2.4 提交系统
实验发现并不是集成的系统越多成绩就越好,经过大量测试,发现“1,3,4”组合的鲁棒性和BLEU值都较高,考虑到系统复杂性,本文选择“1,3,4”组合作为主系统,又因规则方法在WMT 2018和WMT 2019语料过滤任务中被证明为提升翻译性能的有效手段,且预训练模型在语义提取上具有优势,因此选择“1,2,3,4,6”组合作为副系统.最终评测结果见表4,可见本文提交的主系统system2综合排名第二,在除IWSLT2020数据集外均排名第一.由于IWSLT2020数据集是口语语料,新闻语料和口语语料有一定领域差异,导致该系统在IWSLT2020数据集上表现不佳,这也表明训练领域会影响过滤结果.

表4 最终评测结果Tab.4 Final evaluation result %
3 总结与展望
本文设计并实现了规则方法、统计方法和神经网络方法三类方法对汉英平行语料进行过滤,并将多种方法融合来对噪声语料进行过滤.最终实验结果表明:相比于单系统,改进的按权重相乘的多系统融合方法在测试集上取得了较好的结果,同时,在最终的5组评测结果中,本文提交的系统综合排名第二,在多个数据集上排名第一,对语料过滤研究具有一定的参考价值.
在未来的工作中,可以从两个方向做进一步尝试:一是挖掘更可靠的特征来区分高质量和低质量的语料;二是将针对特征组合方式做进一步的优化调整,如引入机器学习模型自动学习最优权重组合.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
思维与智慧·上半月(2022年4期)2022-04-08
小哥白尼(神奇星球)(2021年4期)2021-07-22
英语世界(2021年13期)2021-01-12
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
新高考·高一物理(2017年7期)2018-03-06
长江学术(2016年3期)2016-08-23
体育科研(2016年2期)2016-02-28
外语教学理论与实践(2014年2期)2014-06-21
