
基于掩码机制的非自回归神经机器翻译
2021-06-22 08:32:36季佰军段湘煜
厦门大学学报(自然科学版) 2021年4期
贾 浩,王 煦,季佰军,段湘煜,张 民
(苏州大学计算机科学与技术学院,江苏 苏州 215006)
机器翻译[1-2]的主要研究目的是通过计算机实现一种语言到另一种语言的自动翻译,传统的统计机器翻译(statistic machine translation,SMT)[3]系统性能提升缓慢,但是近年来,随着神经机器翻译(neural machine translation,NMT)[4]的提出,机器翻译性能大幅度提升,再次得到了广泛的关注.
NMT模型一般采用编码器-解码器[5]结构,使用编码器学习源端单词的上下文表征,之后再通过解码器来预测目标端的单词.2014年,Bahdanau等[6]第一次将注意力机制引入自然语言处理领域,进一步提升了NMT的性能.之后Luong等[7]拓展了注意力机制在机器翻译领域的运用,提出了全局注意力与局部注意力的概念.2017年,Vaswani等[8]通过自注意力机制(self-attention)将输入序列中不同位置的信息相互联系起来,提出了完全基于注意力机制的翻译模型Transformer,与递归结构、卷积结构相比,取得了更好的翻译效果.
虽然在翻译效果上取得了较大进步,但相关模型也越来越复杂,并且编码器与解码器分开设计,进一步增加了模型的复杂度.目前已经有一些工作尝试缩小编码器与解码器之间的差异,将它们简化为一个模块.Bapna等[9]尝试将编码器所有层的信息传给解码器.He等[10]将编码器与解码器参数共享,取得了不错的效果.Fonollosa等[11]则在He等[10]的基础上对注意力层添加了局部约束.这些方法都尝试将编码器与解码器在注意力层面上统一,但是在编码过程中这些模型只能依靠源端句子.
非自回归NMT近几年在NMT领域逐渐受到关注.传统的自回归NMT在解码过程中逐次以已知单词为条件预测下一个单词,而非自回归NMT则通过并行计算一次性生成所有预测单词.虽然在配置相同的情况下非自回归NMT效果往往没有自回归NMT好,但是相对而言,其翻译速度有大幅提高.2018年,Gu等[12]首次提出了非自回归NMT,与传统Transformer模型相比,多了一个繁殖预测(fertility predictor)模块,使用外部的快速对齐工具(fast align)来生成繁殖信息以决定输出句子长度,之后并行地生成目标语句的各个单词.Lee等[13]则通过编码器隐状态直接生成句子长度,并且采用多次迭代的方法,直接取上一轮翻译的结果作为下一轮的解码器输入,从而提升翻译效果.Ghazvininejad等[14]则在Lee等[13]的基础上采用掩码机制,随机对解码器的输入进行掩码处理,输出这些被掩码的单词.为了得到更合适的翻译结果,Wei 等[15]将自回归模型作为教师模型,指导模型的训练.Shao等[16]则引入了强化学习的训练方法.但是,这些方法仍然需要使用编码器-解码器结构.
为了简化传统的NMT模型框架,本研究提出了基于掩码机制的非自回归NMT模型.该模型只使用一个带有自注意力机制的编码器,并且运用了类似于Devlin等[17]在其掩码语言模型(masked language model,MLM)中使用的掩码机制.这个方法最先被用于单语言预训练中,之后Lample等[18]将其运用到跨语言预训练中,他们将源端语句和目标端语句拼接作为输入,并且在源端语句和目标端语句中都随机掩盖一部分词进行训练,最终的训练目标是预测出被随机掩盖的单词.本研究在训练过程中,使用类似于Lample等[18]的方法,将平行源端句子与目标端句子拼接输入,但是只对目标端的单词进行掩码处理.在训练时,模型依靠自注意力层学习源端句子和目标端未被掩码处理的句子信息,来预测目标端被掩码处理的单词.并且通过这个模型,可以同时实现非自回归NMT,与传统的自回归NMT相比,可以大大提高翻译的速度.
1 模型结构
1.1 基础结构
受MLM[17]的启发,将带有双向自注意力机制的Transformer的编码器作为实验的基本模型结构,如图1所示.该模型结构融合了掩码机制、非自回归NMT、遮掩-预测解码机制等思想.模型由一个Transformer编码器和一个单层循环神经网络(recurrent neural network,RNN)组成,RNN模块用来预测目标语言的句子长度l,Transformer编码器用来预测目标语言的句子内容.相比于传统的自回归NMT,该模型能减少近一半的参数,大大减少了模型的参数规模.其中,Transformer编码器由6个编码器层堆叠而成,每个编码器层包含2个子层(多头自注意力子层和前馈神经网络子层),每个子层都有1个残差连接和1个层标准化.

图1 本模型结构Fig.1 Structure of our model
1.2 掩码机制
MLM实质上是一个带有双向自注意力机制和掩码机制的Transformer编码器,在此结构基础上,模型能够在每一层中学习到上下文的双向表示.因此,本研究采用类似于MLM的方法来优化输入文本的上下文表示.具体地,将输入文本中的词随机替换为特殊标记[mask],实现对输入文本的部分遮掩,然后模型通过学习文本的上下文信息来预测被遮掩的词.
在模型训练时,对目标语句进行随机遮掩之后,将双语平行句对用隔开,作为一个序列,进入Transformer编码器进行自注意力的计算.如图2所示:其中,对于源语句部分,在进行自注意力运算时,将目标语句的权重设置为-∞,即让模型在进行源语句注意力计算时,感知不到目标语句;而在进行目标语句的自注意力运算时,不对源语句的权重进行任何的操作,即让模型在目标语句注意力计算时,能够感知到整个句对.
1.3 非自回归NMT
非自回归NMT对目标语言的每个词独立地进行预测,不依赖于预测词前面位置的单词,因此能一次性地预测出整个目标语言句子.给定一个源语言句子SI=[s1,…,si,…,sI],生成正确的目标语言句子TJ=[t1,…,tj,…,tJ]的概率

箭头表示注意力的传递.图2 每个编码器层之间的注意力计算参与方式Fig.2 Participating method of attention calculation between each encoder layer
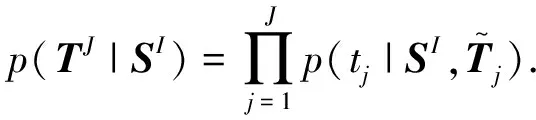
(1)

本研究随机对目标端句子中的N个词进行遮掩,N服从于均匀分布U(1,l),其中l为目标端句子长度.模型的遮掩和生成部分的损失函数可表示为
(2)

1.4 长度预测模块
在传统的自回归NMT中,从左往右逐词解码,直到预测出代表句子结束的特殊标识符,作为句子解码结束的标志.而在非自回归NMT中,由于同时预测出整个句子的内容,所以在预测句子内容之前,需要提前知道句子长度.因此,本研究采用了一个单层的RNN来提前预测句子的长度.
假设目标语言句子的最大长度为lmax,对于源语言句子的第t个词st,可以通过如下公式得到隐状态Ht:
Ht=tanh(WHt-1+Ust),t=1,2,…,I,
(3)

(4)
因此,在模型训练阶段,将目标端句子的真实长度编码成一个lmax维的独热向量(one-hot vector)Y,长度预测模块的训练目标为最小化交叉熵(cross entropy,ec)损失:
(5)
1.5 损失函数
结合长度预测模块和目标端句子预测模型,本研究在模型训练过程中,最小化损失函数为
L=L1+L2.
(6)
1.6 遮掩-预测解码机制
非自回归NMT虽然能够提高解码的速度,但是如何提高解码的效果至关重要.因此,在模型解码阶段,本研究采用“遮掩-预测”解码机制[16]进行逐步优化,提高模型解码出的句子效果.
解码的算法思路如下:首先根据源语言的句子,通过长度预测模块得到目标语言句子的长度l;然后将目标语言句子置为l个特殊标记[mask],与源语言句子拼接在一起进入模型,预测出目标语言句子中的所有词;最后进入T轮的迭代优化,每一轮的优化迭代包含遮掩和预测两部分.

(7)
其中[]表示取整.

(8)
(9)
其中,Vj为模型词表中的各个词.而对于那些没有被遮掩的词,其预测概率保持不变.
2 实 验
2.1 数据集
选择非自回归NMT任务中常用的WMT 2016英语-罗马尼亚语(http:∥www.statmt.org/wmt16/translation-task.html)语料进行实验,训练集含有61.3 万对平行句对,验证集newsdev2016和测试集newstest2016各含有2 000对平行句对.使用工具MOSES[19]对数据进行分词,对英语语料和罗马尼亚语语料进行联合字节对编码[20](byte pair encoding,BPE),共享约6万的词汇表,其余低频词用
2.2 实验设置
在实验中,对于长度预测模块,使用一个单层RNN对源端信息进行编码,目标端句子最大长度设为256,并用一个Softmax层对目标端句子长度进行预测.对于目标端句子内容预测部分,使用一个Transformer编码器,含有6个编码器层,每一层多头注意力机制均使用了8个头,词嵌入(word embedding)维度为1 024.
训练时,使用Adam优化器[21],初始学习率设为0.000 5,批大小(batch size)为5 200个词,对于所有的隐藏层,都有0.1的随机失活率(dropout),标签平滑(label smoothing)参数=0.1.随机将目标端句子的N个词用[mask]代替,其中N服从均匀分布U(1,l).解码时,将迭代优化的轮数设为10.
2.3 翻译系统的评测指标
以双语互译评估(BLEU)分数来作为本研究模型性能的评测指标,使用WMT数据集评测常用的SacreBLEU[22]工具(SacreBLEU的设置为: BLEU+case.mixed+numrefs.1+smooth.exp+tok.13a+version.1.2.17).
2.4 实验结果
基准系统选取了近年来非自回归NMT领域比较有影响力的几个工作.分为两类,第一类解码阶段不需要进行迭代优化,解码的时间复杂度为O(1);另一类解码阶段需要进行迭代优化,解码的时间复杂度为O(T),其中,T为迭代优化的轮数.这些方法都是基于编码器-解码器结构,具有更多的参数、更复杂的模型结构,会消耗更多的训练时间.
表1展示了各系统在WMT 2016英语-罗马尼亚语任务的测试集newstest2016上的性能,可以看出本研究的模型尽管结构很简单,但是取得了最好的实验性能(英语→罗马尼亚语的BLEU值为30.2%,罗马尼亚语→英语的BLEU值为31.2%).与解码阶段不需要迭代优化的方法相比,虽然本研究的方法在解码时具有更高的时间复杂度,但是其参数更少,翻译性能更好.而和解码阶段需要迭代优化的方法相比,虽然解码复杂度相同,但是本研究的方法翻译性能有了大幅的提升,而且完全是端到端的训练方式.

表1 各系统在WMT 2016英语-罗马尼亚语任务的测试集newstest2016上的性能Tab.1 Performances of systems on the test set ofWMT 2016 English-Romanian task(newstest2016)
3 实验分析
3.1 不同迭代优化轮数的影响
根据1.6节介绍的遮掩-预测解码机制可知,迭代优化的轮数T可能会对解码结果产生一定的影响.而在本研究的实验中,迭代优化的轮数T已经预先设定,因此,本节将分析不同迭代优化轮数对解码结果的影响.
从图3可以看出,在迭代优化轮数T小于12时,迭代的轮数越多,模型解码的效果越好,而在T大于12时,模型解码的效果趋于平稳,不会因为迭代轮数的增多而产生较大的影响.

图3 不同迭代优化轮数对解码结果的影响Fig.3 Effect of different iteration optimization rounds on the decoding result
3.2 模型不同初始化参数的影响
由于本研究使用基于掩码机制的Transformer编码器,和MLM类似,本研究用预训练的英语-罗马尼亚语MLM(https:∥dl.fbaipublicfiles.com/XLM/mlm_enro_1024.pth)参数初始化本模型中的Transformer编码器,分析不同初始化参数对模型性能的影响.
由表2可知,将本模型中的Transformer编码器用预训练的MLM参数初始化之后,英语→罗马尼亚语和罗马尼亚语→英语两个语向上的BLEU都取得了很大的提升,与Lample等[18]使用预训练的MLM参数初始化Transformer编码器和解码器得到的自回归NMT模型性能相当,同时参数约减少了一半,模型更轻量.

表2 不同的参数初始化方式下模型的性能以及参数量Tab.2 Performance and parameter quantity of the modelwith different parameter initialization methods
3.3 给定目标端长度的结果
本研究使用一个单层RNN作为长度预测模块,在解码时首先通过长度预测模块预测出目标语言句子的长度,再进行目标语言句子内容的预测.为了分析RNN这个长度预测模块的效果,本研究改变解码的方式,即给定目标语言句子的真实长度,然后再用本研究模型预测目标语言句子的内容.
表3给出了相关实验性能的数据,在解码阶段给定目标语言句子的真实长度,即不再使用长度预测模块后,解码效果并没有很大的提升(英语→罗马尼亚语方向的BLEU值提升0.2个百分点,罗马尼亚语→英语方向的BLEU值提升0.3个百分点),说明长度预测模块在整个模型中起到了不错的效果.

表3 模型在给定目标端长度情况下的解码效果Tab.3 Decoding performance of the modelwith the given target-side length
3.4 不同源端信息的影响
如图2所示,在本研究模型的Transformer编码器中,在对源语言端进行注意力计算时,将目标端的信息全部进行了遮掩,此时,源语言端每一层的隐状态都只跟源语言端的信息相关.为了研究不同源端信息的影响,本研究直接用Transformer编码器对源语言句子进行独立编码,然后将编码器最终输出的隐状态作为源端信息,参与每一层目标端注意力的计算.
从表4可以看出,独立编码源端注意力信息并参与每一层目标端注意力计算的效果不及本研究将每一层的源端注意力信息仅用来参与该层目标端注意力计算.这是因为每一层的源端隐状态都关注到了不同的信息,参与该层目标端注意力计算能让目标端注意到该层的信息;而独立编码源端注意力信息,将最终输出的隐状态作为源端信息参与每一层目标端注意力的计算,会使目标端失去这部分信息,导致效果不佳.

表4 目标端的不同源端注意力输入方式的结果对比Tab.4 Result comparison of different sourceattention input methods on target side
3.5 模型解码速度
本研究采用了基于迭代的解码方式,解码速度会随着迭代轮数增加而变慢,其解码时间复杂度为O(T),T为迭代优化轮数.而基于自回归的从左往右的解码方式复杂度为O(N),N为目标端句子长度.通常来说,T≪N,因此本研究模型在性能上是优于自回归解码的.
在一台TITANXP上分别使用两种解码方式对10万句输入进行解码测试.如图4所示,随着迭代轮数增加,本研究模型解码速度确实会有降低,但还是优于基于自回归的解码,解码速度是自回归的1.3~3.6倍.

图4 不同解码方式之间的速度对比Fig.4 Speed comparison between different decoding methods
4 结 论
本研究针对传统自回归NMT结构复杂、参数过多的问题,提出了基于掩码的非自回归NMT.本研究采用类似MLM中的掩码机制,对Transformer编码器部分修改并使其同时实现编码器与解码器功能.最终实验结果表明本研究基于掩码的非自回归NMT模型相比于其他非自回归翻译模型,取得了更好的翻译性能;相比于传统自回归NMT模型,结构更简单、参数更少,并且使用跨语言预训练语言模型初始化之后,本研究取得了和自回归NMT模型相当的结果.
在未来的工作中,将进一步探索非自回归NMT方法,同时对本研究模型在其他语言对和其他生成任务中的作用进行探索.
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
中国外汇(2019年19期)2019-11-26 00:57:32
中文信息学报(2019年8期)2019-09-05 12:33:36
通信学报(2019年5期)2019-06-11 03:05:56
数码世界(2019年4期)2019-05-10 09:52:54
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
通信技术(2018年3期)2018-03-21 00:56:37
科技视界(2016年22期)2016-10-18 15:53:02
浙江大学学报(工学版)(2015年4期)2015-03-01 01:17:53
