
融合篇章上下文有效识别的篇章级机器翻译
2021-06-22 08:32:36贡正仙李军辉
厦门大学学报(自然科学版) 2021年4期
汪 浩,贡正仙,李军辉
(苏州大学计算机科学与技术学院,江苏 苏州 215006)
近些年来,神经机器翻译(NMT)飞速发展[1-2].相较于传统的统计机器翻译,NMT展现出更加优越的性能和更强的适应性,使得NMT的应用和影响越来越广.NMT通过搭建神经网络模型,使用序列到序列的翻译方法[3],极大地提升了翻译的性能.2017年,Vaswani等[4]提出全新的模型架构Transformer,该模型采用经典的编码器-解码器结构,使用新颖的多头注意力机制来进行建模,达到了非常卓越的性能,在自然语言处理研究中得到广泛应用.
NMT研究对于句子级的翻译,取得了非常卓越的效果,在中英新闻翻译方面取得了巨大的成功,已经达到接近人类的水平[5].然而,相较于句子级翻译研究,篇章级NMT受到的关注较少.由于难以有效地利用篇章上下文信息,篇章级机器翻译的研究仍然具有挑战性,即使是Transformer模型性能也有待提高.Bawden等[6]指出利用篇章级上下文来处理与上下文相关的现象是非常关键的,例如共指、词法衔接和词法歧义化等现象,对于机器翻译的性能有着重要的影响.翻译过程中出现的语句不通顺和不连贯的现象,很有可能就是没有考虑篇章级信息而造成的.
近年来,篇章级别的NMT研究越来越受到关注[7-13].Zhang等[7]提出了一种基于Transformer的篇章翻译模型,通过使用两个编码器分别计算当前句的表示和篇章级上下文的表示,再将篇章级别上下文信息分别融入到当前句子的编码器和解码器中,显著地提高了篇章翻译的性能.多层注意力网络模型[11]是第一个使用分层注意力机制以结构化和动态的方式来捕捉篇章上下文信息的模型.Yang等[10]提出了一种以查询为导向的胶囊网络,将上下文信息聚类到目标翻译可能涉及的不同角度.Chen等[13]利用卷积神经网络将句子级上下文表示为潜在主题,并将句子级主题上下文信息集成到NMT模型中.但是,篇章上下文的选取存在着很多问题,Zhang等[7]分别选取前1、前2、前3句作为当前句子的上下文,多层注意力网络模型选取了前3句作为上下文,Yang等[10]同样是选取了前3句作为上下文.而Chen等[13]利用卷积神经网络处理句子之间的信息,不涉及上下文长度的选取.然而在实际翻译场景中,当前句的前句所蕴含的篇章信息并非总能对翻译当前句发挥作用,因此,如何让模型能够充分利用有效的篇章信息是一个值得研究的问题.
为了让模型能够学习到更多有价值的篇章上下文信息,本文提出一种基于联合学习的篇章翻译结构.其核心思想是利用一个共享的编码器分别对当前句及其上下文进行编码,同时引入分类任务,分类器用于判断当前句的上下文编码表征是否蕴含有效的篇章信息.本文对分类器的数据生成设计了多种方案,在努力提高分类性能的同时帮助模型提升编码器对句子的表示能力.本文描述的篇章翻译系统建立在通用的句子级Transformer模型之上,除了联合分类器,模型进一步引入门控机制,通过改进基准模型的残差连接,使得编码端识别出来的上下文信息能够在解码端得到充分利用.
1 融合篇章上下文有效识别的篇章级机器翻译
1.1 系统模型架构
受Zhang等[7]工作的启发,本文采用了如图1所示的系统模型架构,基本思想是使用多头自注意力机制计算篇章级上下文的表示,并将编码得到的上下文信息集成到解码器中.与Zhang等[7]不同,出于计算成本和注意力负担的考量,本文对上下文和当前句采用的是共享编码器,即在Transformer的原始模型基础上使用同一个编码器来对源端句的上下文句进行编码.为了有效利用篇章级别的上下文信息,系统加入了分类模块,对两个编码器的输出隐藏状态进一步处理.从经过编码的信息中,判断上下文与当前句是否存在关联,本文一方面通过分类任务来提升句子的表示能力,另一方面将联合上下文注意力和门控机制来指导模型对上下文的有效利用.为了指导解码器有效使用篇章上下文信息,将篇章上下文注意力层置于解码器的自注意子层和上下文注意力子层之间;为了进一步控制上下文信息在目标端的利用,引入门控机制.下面将详细描述分类器的设计和门控机制.

图1 融合篇章上下文有效识别的Transformer模型Fig.1 Transformer model fused effective context recognition
1.2 篇章上下文有效识别
1.2.1 分类器设计
句子级的Transformer模型在翻译时不需要考虑上下文,因此经过编码器编码的句子表示在体现句间关系上能力较弱;与此相对,篇章翻译的编码输出应该在句间关系的判断上更具优势.因此,存在这样一个假设:性能越好的篇章翻译编码器,它的编码输出(即句子表示)在句间关系判断上应该能力越强(本文3.4节的实验结果验证了该假设的合理性).根据这一假设,本文的翻译系统增加了一个联合分类任务:利用编码器输出判断当前句子的上下文是不是真正有效的上下文.分类性能的提升,一方面说明系统内的句子表示得到增强,另一方面也说明模型在学习过程中更能有效关注到上下文信息.

(1)
在KL_div策略中,利用训练好的BERT(bidirectional encoder representations from Transformers)预训练模型将句子转化为特征向量,计算句子表征之间的KL距离.KL_div策略的相似度计算如式(2)所示:
(2)
1.2.2 分类器结构
分类器的结构如图2所示,记h∈Rnt×d和s∈Rnc×d分别表示当前句x(t)和当前句上下文c(t)经编码器后的输出,nt表示源端当前句包含的单词数,其中nc表示对应上下文包含的单词数,d表示隐藏状态的大小.将隐藏状态h和s进一步通过最大池化和平均池化操作,分别表示为向量u和v,即:
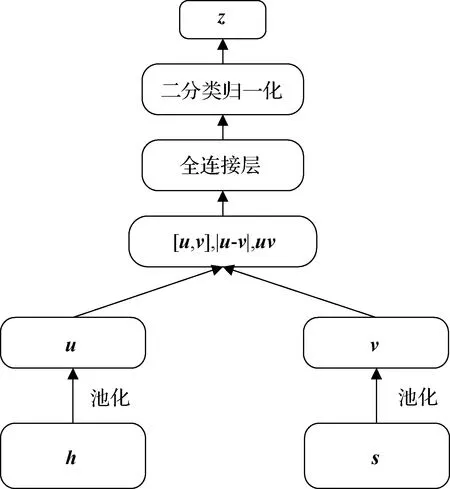
图2 处理篇章信息的分类器结构图Fig.2 Structure diagram of classifier processing document-level information
u=[hmax-fP(h),hmean-fP(h)],
(3)
v=[smax-fP(s),smean-fP(s)],
(4)
其中u,v∈R2d,fP为池化函数.为了捕获u和v之间的关系,系统为分类器构建了如下输入,即
o=[u,v,|u-v|,uv],
(5)
其中,o∈R8d,由u,v的拼接向量[u,v]、逐个元素乘积uv和逐元素的绝对差|u-v|构成.最后,通过全连接层和二元分类softmax层判断上下文c(t)是否为当前句x(t)的有效上下文:
z=softmax(σ(oW1+b1)W2+b2),
(6)
其中,W1∈R8d×d,W2∈Rd×2,b1∈R1×d,b2∈R2为模型参数,σ为sigmoid函数.
1.3 带门控机制的残差网络
在图1所示的解码器端,引入的上下文注意力子层用于融合篇章上下文信息.为方便起见,记解码端自注意力层的输出为p∈Rmt×d,mt为目标端当前句的单词数,上下文注意力层通过多头注意力模型,融入篇章上下文信息s∈Rnc×d,即
q=fMH(p,s,s),
(7)
其中q∈Rmt×d,fMH为多注意力机制函数.为了获取篇章的上下文信息,一般通过残差网络与上下文注意力子层的输入进行融合,即
r=q+p.
(8)
不难看出,式(8)所示的残差网络将采用全盘接收的方式融合获取的篇章上下文q.为了区别篇章上下文是否有效,受Zhang等[7]的启发,本文引入带门控机制的残差网络,即通过门控层按一定比例α融合获取的篇章上下文,如式(9)所示:
r=αq+p.
(9)
α为衡量该篇章上下文信息重要程度的指标,可表示为
α=σ(Wpp+Wqq),
(10)
其中Wp和Wq为权重参数.一般来讲,当篇章上下文有效时,希望通过训练使权重α接近于1,反之接近于0.
2 训练方式
2.1 联合学习
与第1节内容相对应,本文联合学习的损失函数分为三部分,分别涉及传统NMT目标端的预测、有效篇章上下文的识别和带门控机制的残差网络中篇章上下文的重要程度α.
记模型参数为θ,NMT目标端预测相关损失函数为
L1=

(11)
其中,N为训练集中平行篇章数,Tn为第n个平行篇章的句子数,mn,t为第n个平行篇章当前句子的词数.
篇章上下文有效识别相关损失函数为
(1-ki)log(1-p(ki|θ)).
(12)
其中:M为有效篇章上下文识别训练样例数,即为机器翻译训练集中句子总数;ki∈{0,1}为第i个句子的篇章上下文有效性标签.
带门控机制的残差网络中篇章上下文重要程度α相关的损失函数为
(13)
其中,αi,j表示第i个句子在解码器第j层中的带门控机制的残差网络中篇章上下文的重要程度,6为解码器的层数.
最终,本文的联合学习的训练目标如式(14)所示:
θ*=arg min
θ(L1+L2+L3).
(14)
2.2 两步训练法
由于大规模篇章级平行语料库通常无法获取,即便是对于语料丰富的语言(如英语和中文)也是如此.在语料库规模很小的条件下,篇章级NMT模型的表现往往不及句子级模型性能.本文采用Zhang等[7]提到的两步训练方式.该训练方式额外使用了一个比篇章级语料数据Dd更大的句子级平行语料数据Ds,具体训练步骤如下:
1) 在组合的句子级平行语料库Dd∪Ds上训练句子级参数.训练句子级参数时,模型与原始Transformer模型相同,篇章级模块不参与训练,如图1所示,进行该步训练时只有实线模块参与训练.
2) 仅在篇章级平行语料库Dd上训练篇章级参数.如图1所示,在此步中虚线模块和实线模型同时参与训练.
值得注意的是,本模型在训练篇章级参数时,并没有固定第一步句子级参数,这主要是因为分类器模板需要两个编码器同时参与训练.
3 实 验
3.1 实验设置
本文在中英、英德翻译任务上验证本文提出的模型.
在中英翻译任务上,训练集包含200万个中英平行句子对,训练集包括句子级平行语料LDC2002E18、LDC2003E07、LDC2003E14、LDC2004T08的新闻部分;篇章级平行语料包括LDC2002T01、LDC2004T07、LDC2005T06、LDC2005T10、LDC2009T02、LDC2009T15、LDC2010T03.篇章级平行语料包括4.1万个篇章,由94万个句子对组成.本文选择NIST 2006数据集作为开发集,包含1 664个句子,将NIST2002、NIST2003、NIST2004、NIST2005、NIST2008作为测试集,分别包含878,919,1 788,1 082,1 357个句子.翻译任务的评估指标为对大小写不敏感的双语互译评估值(BLEU),由mteval-v11b.pl脚本计算得出.中英翻译中对源语言和目标语言都使用字节对编码(BPE)[15],以减少未登录词的数量,操作数为4×104.
在英德翻译任务上,训练集包括News Commentary v11 corpus(http:∥www.casmacat.eu/corpus/news-commentary.html),并且从WMT14英德数据集(http:∥www.statmt.org/wmt14/translation-task.html)中抽取30万个句子对用来训练句子级参数.开发集为news-test2015,测试集为news-test2016.对于该翻译任务数据,为了提高训练效率,本文将长篇章分成最多30个句子的子篇章,而且同样对源端和目标端语言使用了BPE,操作数为3万.
本文配置的Transformer模型来源于OpenNMT[16](https:∥github.com/OpenNMT/OpenNMT-py).本文将编码器与解码器的层数设置为6层,多头注意力机制中含有8个头,同时设置失活率为0.01,隐层维度和前馈神经网络中间层单元数分别为512和2 048.本文实验只使用一个GTX1080Ti显卡训练模型,训练时批处理大小为4 096个标记(token)以内.进行解码时,设置集束大小为5,其他的设置使用Vaswani系统中的默认设置.本实验中,第一步句子级模型的训练时间为28 h,第二步篇章级模型的训练时间为12 h.
3.2 实验结果
为了验证本文提出模型的性能,分别在中英和英德翻译任务中进行实验.表中TF-IDF策略表示在本文提出的模型下使用TF-IDF方法生成的负例训练数据进行篇章级翻译实验,总体数据的正负例比为1∶3;KL_div策略为通过计算KL距离生成的训练数据进行实验,生成的正负例比为1∶1.这两种策略选出来的篇章上下文均为一句.
表1为中英翻译任务上本文提出模型与基准系统在各测试集上的翻译性能.可以看出本文提出的两种方法均能够提高系统的翻译性能.与基准系统相比,本文模型使用TF-IDF策略的BLEU值提高了1.6 个百分点,使用KL_div策略的BLEU值提高了1.45个百分点.

表1 本文模型与基准系统在中英翻译任务的BLEU值Tab.1 The BLEU values of our model and the baseline in the Chinese-English translation task %
表2为在英德翻译任务上本文提出模型与基准系统在各测试集上的翻译性能.可以看出在英德任务上,本文提出的模型与基准系统相比也同样有显著提升,尤其使用TF-IDF策略构造上下文信息的方法在测试集上的BLEU值提高了0.53个百分点.
这充分表明了本文提出的融合篇章上下文有效识别的篇章翻译模型能够有效地提升机器翻译模型的效果.
3.3 与相关工作的对比
本文复现了篇章机器翻译中非常经典的工作[7]的模型代码,并在本文中英数据集上测得实验结果.对于Zhang等[7]的模型Doc-NMT的设置,本文采用了前一句作为上下文,上下文编码器的层数为6层,跟文献[7]中设置保持一致.除此之外,本文模型与模型Doc-NMT都是在同一个句子级模型参数上微调得到.表3展示了在中英数据集上Doc-NMT和本文模型采用TF-IDF策略的BLEU值比较,本文提出的模型具有更优的性能,在BLEU均值上提升了0.32个百分点,进一步证明本文提出的基于联合学习的篇章翻译模型具有一定的优势.

表3 本文模型与前人工作的BLEU比较Tab.3 BLEU value comparison of our model with previous work %
3.4 上下文有效识别探究
本文中通过引入分类器模块,对篇章上下文进行有效识别,使得源端编码表征能学习到更加有效的信息.因此,本文做了两组实验来证明本文模型增强源端表征的能力,另做了一组实验来考察本文提出的带门控机制的残差网络对模型性能的影响.
第一组实验,通过对本文提出的分类器性能进行对比实验,来证明本文模型的编码器可以学习到更加有效的篇章信息.先利用句子级基准模型的编码器,分别对源端句和上下文句进行编码,将两个源端表征输入至分类器模块,测试分类器的性能.相同地,接着利用本文提出的篇章翻译模型的编码器进行编码,得到的两个源端表征来测试分类器性能.对比实验在中英任务上进行,上下文的选取方式采用TF-IDF策略,正负例比为1∶3.结果显示,使用基准模型的编码器测出分类器的准确度为73.0%,使用本文建议的模型编码器测出的分类器准确度为76.7%,与基准模型相比提高了3.7个百分点.可以看出,使用本文模型的编码器能够明显提升分类器性能,能够识别出更多有效的篇章上下文信息.
第二组实验,对比不同的上下文选取方式在篇章翻译任务上的性能,采用的比照对象为从篇章中随机挑选句子作为上下文来生成负例.对比实验是在中英翻译任务上进行的,生成数据的正负例比为1∶3.表4为3种数据生成方式下模型在测试集上的性能.可以看出,本文提出的选取方式较盲目随机的选取上下文方式具有明显的优势,尤其TF-IDF的选取方式较随机选取的平均BLEU值提高了0.32个百分点.可见,本文提出的数据生成方式具有优越性,更利于分类器识别出有效与无效上下文.

表4 生成数据方式的BLEU值对比Tab.4 BLEU value comparison of data generation methods %
第三组实验中,本文将带门控的残差网络换成普通的残差网络(w/o context gating),保留分类器模块.在中英翻译任务上进行验证实验,其他的实验设置同3.1节的中英实验设置,采用上下文长度为一句,TF-IDF策略的正负例比为1∶3,KL_div策略的正负例比为1∶1,结果如表5所示,可以看出,移除带门控的残差网络后,在TF-IDF策略的上下文选择方式下模型的平均BLEU值下降了0.32个百分点,在KL_div策略的上下文选择方式中模型的平均BLEU值下降了0.31个百分点.可见,本文提出的带门控的残差网络能够在解码端对上下文信息进行更加有效的利用,能够使得模型的性能得到进一步提升.

表5 不同残差网络的BLEU值比较Tab.5 BLEU value comparison of different residual networks %
4 结 论
针对篇章机器翻译如何更高效利用上下文信息的问题,本文提出了一种新的模型结构.首先在现有NMT模型基础上融入了篇章信息,其次对篇章信息进一步识别处理,最终通过解码端的改进使得识别出的有效篇章信息得到充分利用.在中英和英德翻译任务中表明,本文提出的模型和方法可以有效地提高机器翻译的质量.
然而,本文模型在处理过多、过复杂的篇章上下文信息时,存在着处理能力不足、识别能力下降、无法让模型利用更有效的上下文信息的问题.在未来的研究中,会针对模型的识别部分进行进一步改进和研究,努力完善模型,争取达到更好的效果.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子测试(2018年1期)2018-04-18 11:52:35
电子设计工程(2017年20期)2017-02-10 03:39:29
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
电子器件(2015年5期)2015-12-29 08:42:24
河南科技(2015年8期)2015-03-11 16:23:52
