
基于特征融合和粒子群优化算法的运动想象脑电信号识别方法
2021-06-19 06:46:44郜东瑞冯李逍张云霞彭茂琴张永清
电子科技大学学报 2021年3期
郜东瑞,周 晖,冯李逍,张云霞,彭茂琴,张永清,3*
(1.成都信息工程大学计算机学院 成都610025;2.电子科技大学生命科学与技术学院 成都611731;3.电子科技大学计算机科学与工程学院 成都611731)
运动想象作为脑机接口(brain computer interface,BCI)的一个热门领域已经广泛应用在医疗康复中。运动想象(motor imagery,MI)主要通过采集受试者想象肢体运动的脑电信号,并使用机器学习(machine learning, ML)的方法进行分类,最终将分类结果反馈给外界设备,辅助受试者进行肢体运动,达到帮助身体残疾的人进行日常运动的目的,因此该研究方向在医疗康复领域有重大的意义[1]。
在基于BCI-MI的研究中,特征提取方法将直接影响脑机接口分类的准确率,特征提取主要在时域、频域和空域上进行。空域上的特征提取主要是采用共空间模式(common spatial pattern,CSP)以及相关改进算法。文献[2]提出了一种特征权重CSP算法来提取空域特征。文献[3]介绍了目前常用的几种特征选择算法,包括基于信息熵、基于相关系数等。文献[4]对2007年以前的BCI分类算法做了总结,包括线性分类器以及神经网络分类器等。2017年该文献作者又总结了近十年创新的分类方法,将分类方法扩展到流形学习、迁移学习以及张量学习上面。文献[5]对集成分类器做了创新并应用在BCI中,文献[6]在黎曼几何分类器的研究上做了总结并通过协方差矩阵来提升分类器的性能,将黎曼分类器的准确率提升了1.2%~3.6%。文献[7]通过迁移学习提高MI分类性能,降低了计算复杂度并提高了2%~6%的准确率。近几年随着优化算法的普及,各类优化算法都结合着分类器或特征选择算法来处理脑电数据,文献[8]通过粒子群优化算法结合支持向量机、粗糙集以及相对约减集来进行模式分类和特征选择。但调研发现,运动想象脑电识别还存在一些问题:1)特征分类准确率低,通常只有80%左右;2)计算复杂度较高,无法从离线数据分析扩展到在线数据分析并应用在医疗设备中[1]。
为了解决特征分类准确率低的问题,该文设计了新的算法模型来处理MI数据。首先,提取了脑电信号的小波系数、得分共空间模式(score-common spacial pattern,SCSP)算法滤波后的方差和均值以及自回归模型的系数。这3种特征提取方法能够提取到信号的时频域和空间域的信息,非常适合于分析生物非平稳信号。接着对获得的3部分特征进行特征融合,克服特征单一所导致的分类准确率低的问题。针对融合特征所存在的冗余性以及高计算复杂度的问题,该文提出了一种基于粒子群优化算法(PSO)和随机森林分类器的特征筛选方法(PSORF)。该文所设计算法模型的具体过程为,首先对MI数据进行带通滤波,随后通过小波软阈值法进行去噪,使用上述3种方法提取相关脑电特征之后,采用本文设计的PSO-RF来进行特征筛选,对重要的特征进行保留,同时剔除冗余特征,最终筛选到了个位数的特征维度,既减少了计算的时间复杂度,也提高了分类精度。最后使用4种不同的分类器,包括:K近邻(K-nearest neighbors,KNN)、收缩线性判别分析(shrinkage linear discriminant analysis,sLDA)、随机梯度下降(stochastic gradient descent,SGD)以及集成分类器来验证分类的效果。
本文所作出的贡献主要有以下3点:
1)提取脑电信号的时域、频域以及空间域特征,并进行多维特征融合,提高分类准确率;
2)提出了一种PSO-RF算法进行特征筛选,解决传统方法进行特征提取后维度过大且存在冗余性、分类器准确率低和耗费运算资源的问题;
3)对分类器进行改进,通过集成分类器的方式解决单个分类器因训练样本过少而产生的分类效果差的问题。
1 相关背景技术
1.1 运动想象脑电信号识别
在众多的脑机交互控制范式中,基于运动想象技术的脑机接口是其中最普遍的一类。运动想象是在各部分肢体器官都没有发生任何真实运动的情况下,通过大脑想象运动动作即会产生相对应的脑电波。脑电处理流程分为以下几个步骤:首先使用脑电采集设备采集运动想象时的脑电信号,然后使用计算机进行分析,完成模式分类任务,最后将模式分类的结果反馈到外部设备中,从而起到辅助和康复的作用。
1.2 预处理方法
小波阈值去噪算法的主要理论依据是脑电信号经过小波分解之后,信号的小波系数幅值大于噪声,即含噪信号在各个尺度上通过正交小波基进行分解之后,将低分辨率的值全部保存下来,对于高分辨率下的分解值,通过设定一个阈值,将幅值低于该阈值的小波系数都置为零,高于该阈值的小波系数做相应的收缩或者直接保留[9]。最后将处理后所得到的小波系数利用逆小波技术进行重构,就能还原得到去噪后的脑电信号。
得分共空间模式:对于EEG信号而言,空域滤波技术很适合处理这种多维信号和数据。SCSP主要是对CSP算法进行了一定的改进,从而起到一个筛选通道的作用[10]。通过计算投影矩阵每一个通道的得分,筛选出每一类得分最高的通道,最后将这两类筛选出的通道进行合并,得到最优的筛选通道。该算法不仅将两类样本的方差差异进行最大化,而且减少了计算资源的耗费。
1.3 特征提取方法
自回归模型(auto regression, AR)是利用初期的某个特定时刻的随机变量的线性组合来描述后期某个特定时刻的随机变量,处理脑电这种时间序列的数据非常简便有效,因此该模型被广泛应用于BCI的数据处理中[11]。
AR模型特征提取的原理主要如下:首先针对该时间序列的数据,采用AR模型对其进行建模,假设有等时段n个样本点组成时间序列x(k),建立AR模型:
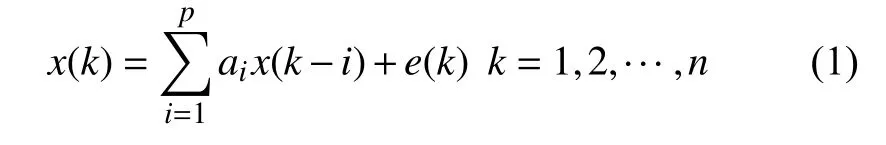
式中,p为AR模型的阶数;a为AR模型系数;e(k)表示AR模型的残差,是均值为0、方差为2的白噪声序列。由式(1)可知,AR模型系数直观地反映了信号x(k)在k时刻与k−1,k−2,···,k−p时刻值之间的依赖权重,因此对特征向量的构建具有重要意义。本文采用最小二乘法实现对AR模型参数的估计。
1.4 粒子群优化算法
粒子群优化算法(PSO)通过模拟鸟类捕食来解决连续非线性的数值问题或多模态问题。在该算法中,粒子被设置在一个多维空间中,每个粒子都会移动到搜索空间中的最佳位置,整个粒子群也会移动到全局的最优位置。在每次迭代的过程中,每个粒子的速度和位置都会根据其动量和最佳位置的影响而改变[12]。
在S维搜索空间中的每个粒子的速度被限制为最大速度Vmax。通常来说,最大速度Vmax设置为搜索空间长度的一半,它被确定为最优解:如果Vmax太高,粒子可能会越过好的解,如果Vmax太小,粒子可能不会从局部好的区域进行适当的搜索。在调整惯性权重W和最大速度Vmax的参数之后,PSO可以完成嵌套搜索能力。每个粒子的位置和速度都是随机形成的,并基于方程进行迭代。如果最终满足了迭代次数或者设置好的迭代效果之后,就会跳出迭代返回最优的结果。
PSO具体的迭代更新如下:
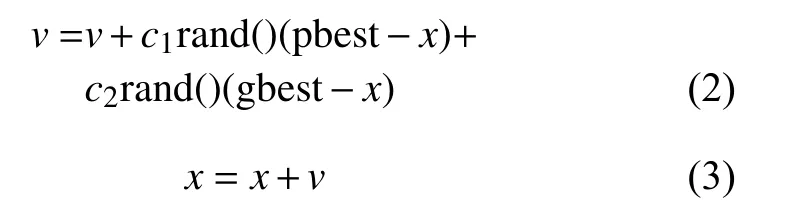
式中,v是粒子的速度;rand()>是介于(0,1)之间的随机数;x表示粒子当前的位置;c1和c2是两个学习因子,通常在PSO算法中设置为2。
PSO算法在搜索全局最优值方面也有较好的效果,它的参数更新比较少,计算复杂度也不是很高,后续比较适合处理需要实时反馈的脑电信号。
1.5 分类算法
随机森林算法(random forest,RF)是一个基于统计学习理论的组合分类器,该算法将Bootstrap重抽样方法和决策树算法结合起来,本质是构建一个树型分类器的集合,然后使用该集合,通过投票的方法进行分类和预测任务。RF中的每一棵树都是一颗决策树,决策树是通过信息增益来得到最终的分类结果[13]。
2 本文所提方法
本文首先对信号的时域、频域、空间域3个不同观察面的特征进行提取,然后进行特征融合,最后提出了一种基于粒子群优化算法和随机森林分类器的特征筛选方法。
2.1 算法模型概述
本文的算法模型如图1所示,该算法模型总共包含4个部分。

图1 算法模型流程图
第1部分是针对数据集的介绍。实验使用的数据集是BCI竞赛III中的IVa数据集[14],该数据集包含5个健康的人,详细内容在3.1小节介绍。
第2部分是数据预处理部分。由于脑电信号幅度微弱,经常淹没在噪声中,因此需要对数据进行去噪处理。本实验采用小波软阈值法进行去噪。由于该部分数据由112个通道组成,计算复杂度高。为了提高计算效率,该文采用SCSP算法进行通道筛选,将112个通道筛选为16个最优通道,简化后续计算复杂度。最后通过3种不同的方法进行特征提取,并做了特征融合,将脑电信号的时频域以及空间域特征都进行提取,防止信息遗落。
第3部分是特征筛选部分。由于特征融合之后的矩阵维数较高,会耗费大量的计算资源。因此本文采用PSO算法并结合随机森林分类器的3个评价指标来筛选特征。最终筛选出较小维度的特征矩阵,减少了计算复杂度并保证了较高的分类性能。
第4部分是分类器。实验采用4个分类器,分别是K近邻(KNN)、收缩线性判别分析(sLDA)、随机梯度下降(SGD)、以及上述3种分类器集成得到的集成分类器(Ensemble)。通过这4种分类器能够验证本文所提算法是否具备普适性。
KNN是通过将未标记的样本由距离其最近的K个邻居投票来决定。sLDA是线性判别分析的一种改进版,在训练样本数与特征数相比较少的情况下更加适用。SGD是梯度下降算法的一个扩展,将梯度设为期望,期望可以使用小规模的样本近似估计来表示。Ensemble是根据上述3个分类器最终所得到的预测标签来进行集成,采用投票法来对最终集成分类器的预测标签进行预测。
2.2 特征融合方法
由于脑电信号所包含的信息量较为复杂,单单提取一个方面的特征无法很好地表示该部分的脑电信号包含的信息。因此本文提出了一种特征融合的方式来克服上述缺点。
首先针对脑电信号的时域部分信息,通过AR模型的拟合效果,使得这部分脑电信号能够自己模拟之后的运动轨迹。通过提取该AR模型的系数来构建特征向量,能够反映出部分的时域特征。其次通过小波分解的方法提取脑电的时频域信息。小波分析技术能够很好地克服传统傅里叶变换所产生的只适用于平稳信号的缺陷,更好地处理非平稳的生理信号,因此本文通过小波分解得到的高低频系数来反应脑电信号的时频域特征[15]。最后通过SCSP的通道筛选方法,将两类样本的方差最大化,从而提取两类样本的方差作为空间域上的特征。
2.3 特征选择算法
本文所提出的特征选择方法是在基于PSO粒子群优化算法的基础上,结合随机森林分类器构建更优的适应值函数,最终筛选出最优的特征。
本实验所用到的适应度函数是由正确率、ROC面积值和F分数评价指标组成。这3个值能从不同角度反映出分类器所产生的效果是否最佳,更全面的考虑算法性能。适应度函数的计算公式如下:
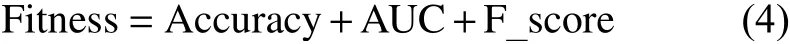
式中,Accuracy代表分类正确率;AUC代表ROC面积值;F-score代表F分数。其中分类正确率取为正确分类的样本数与样本总数之比。具体计算公式如下:
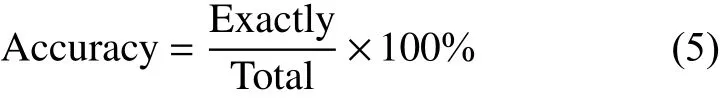
式中,Exactly值是分类正确的样本数量;Total指的是总样本数量。
F分数是衡量二分类的一种评价指标,它结合了精确率和召回率,具体公式如下所示:
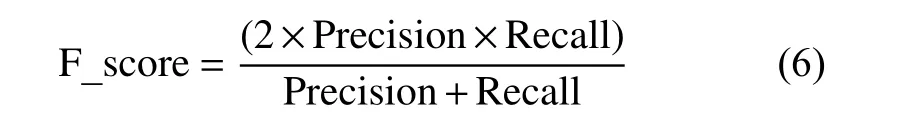
式中,Precision和Recall分别是模型的精确率和召回率。它们的计算公式如下所示:

式中,TP是真阳性样本数;FN是假阴性样本数;FP是假阳性样本数。
2.4 算法核心步骤
本实验所设计的PSO结合随机森林分类器的特征选择算法核心步骤如下。
1)对所有粒子进行随机初始化
根据表1对所有粒子进行初始化,由于特征融合之后得到的特征矩阵维度为112维,因此粒子的初始位置为[0,111]中的一个随机整数。
2)根据适应度函数评估粒子并得到全局最优值
根据式(5)所设置的适应度函数,计算种群的初始适应值,并将该初始适应值中的最优值赋给全局最优值gbest。
3)判断是否满足迭代结束条件
迭代的结束条件主要有两个:①超过了表1所设置的最大迭代次数1000;②适应度函数达到了最优值,当适应值为3时,已达到了全局最优,因此保存粒子参数后跳出循环。

表1 PSO参数设置
4)更新每个粒子当前的速度和位置
根据式(2)和式(3)来迭代更新每个粒子的速度v和位置x。
5)评估每个粒子的适应度函数值
根据当前粒子的速度和位置评估每个粒子的适应值,并进行横向(不同粒子间)和纵向(该粒子历史)的比较。
6)对每个粒子的历史最优位置进行更新
将粒子纵向比较后的最优结果作为局部最优值并赋值给pbest。
7)对群体的全局最优位置进行更新
将所有粒子的pbest进行比较,最终得到最优值替代原有的gbest。
8)如果满足上述的两个迭代结束条件则退出,否则返回并重新执行步骤4)~7)。
该算法的伪代码部分如下所示:

3 实 验
为了充分证明本文方法的有效性,在多个数据集上进行了广泛实验。主要回答了以下几个研究问题:
1)本文方法在训练样本少的情况下,能否在3个评价指标下都能表现的很好;
2)相比其他特征选择的对比算法,本实验所提的方法在相同训练集和测试集的情况下能否优于这些对比算法;
3)适应度函数定义为3个评价指标的和,是否优于任一个或任两个评价指标的和;
4)在不同的数据集下,本实验所提的方法是否具有较好的鲁棒性。
3.1 数据集
本次实验所用的数据集是BCI竞赛III中的IVa的数据集,该数据集来自5个健康受试者,包含来自4个初始会话的数据[14]。运动意识的主题应执行:(L)左手,(F)右脚。视觉刺激有两种类型:1)用固定十字后面的字母表示目标;2)随机移动的物体表示目标。从受试者a1和aw记录了两种类型的两次会话,而其他受试者记录了3种类型2)的会话和1种类型1)的会话。
该数据集采用的是BrainAmp放大器和ECI的128通道Ag/AgCl电极盖进行记录,是在扩展的国际10/20系统的位置上测量了118个EEG通道。左手和右脚的样本数都是140,该数据集在采集的时候采样率为1000,并且采集的时间也是1 s,因此采集到的样本数也为1000。
3.2 评价指标
分类正确率:就是分类器的准确率,是整个分类系统中最重要的指标。
AUC值:AUC值是ROC曲线所覆盖的面积值。它是一个概率值,即随机挑选一个正样本以及负样本时,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类[16]。
F分数:可以看作是模型精确率和召回率的一种调和平均,它的最大值是1,最小值是0。
3.3 特征选择对比算法
基于核函数的主成分分析
Kernel-PCA算法主要是针对传统的PCA算法做了一定改进,该算法加入了核函数,借此可以通过非线性映射将数据转换到一个高维空间中,在高维空间中使用PCA再将其映射到另一个低维空间中[17]。
快速盲源分离:Fast-ICA是线性盲源分离算法中较为成熟的一种,算法流程主要包括3步:首先对特征矩阵进行归一化,将所有的特征值都归一化到[0,1]的范围。接着进行白化,因为ICA模型不包含噪声项,为了使模型正确就必须使用白化。最后将白化之后的模型进行ICA分析[18]。
基于KL散度的特征筛选算法:KL散度也被称为相对熵,用于度量两个概率分布之间的差异程度,具有非负性和不对称性。计算公式如下:
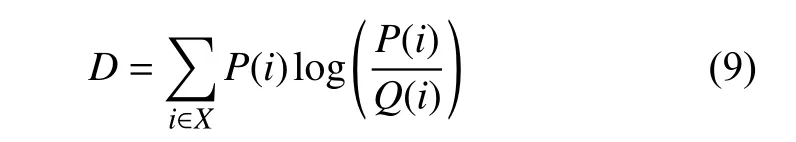
式中,P表示真实分布;Q表示P的拟合分布[19]。
基于相关系数的特征筛选算法:Corr方法是基于皮尔森相关系数,它是衡量两个随机变量之间线性相关程度的指标,描述的是一种非确定性的关系。相关系数r的取值范围是[−1,1],表示变量之间相关程度的高低,r的绝对值越大,其相关度越高。r>0表示正相关,r<0表示负相关,r=1称为完全正相关,r=−1称为完全负相关,r=0称为不相关[20]。
3.4 实验调参
随机森林分类器中决策树数量参数的确定:针对随机森林分类器中的决策树数量进行参数调整,分类器的正确率随着决策树的数量增加产生的结果如图2所示。
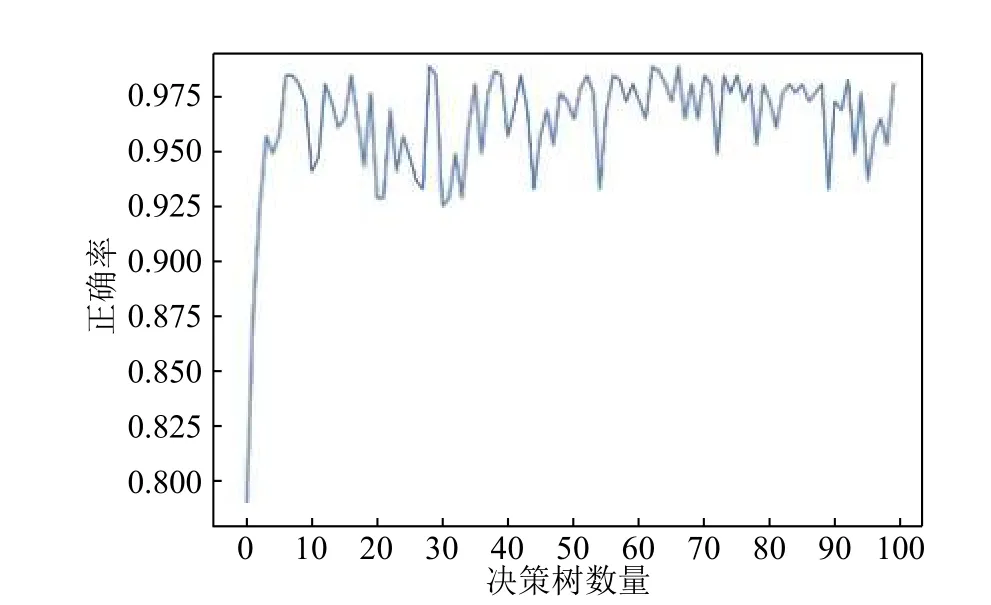
图2 随机森林参数图
在该分类器中,随着内部决策树数量的增加,正确率逐步上升。最终在5棵决策树的时候,分类正确率接近98%。为了避免资源浪费并保证正确率,后续的实验结果都采用5棵树作为随机森林分类器中的决策树参数。
带通滤波参数的确定:主要是通过计算每一类数据的功率谱密度,并根据功率谱密度绘制出能够反映不同频率段所含信息量大小的R2图,根据该图能得到信息最多的频段信息。在这些R2图中,该滤波段所蕴含的信息越多,则该频段的颜色就越鲜艳,由此确定每个数据集的带通滤波参数。绘制的R2图如图3所示。由图得知,不同的数据集对应的R2图也不同,由颜色对比来进行滤波参数选择。aa数据集的滤波频段选取为3~30 Hz;al数据集的滤波频段选取为5~40 Hz;av数据集的滤波频段选取为8~45 Hz;aw数据集的滤波频段选取为8~48 Hz;ay数据集的滤波频段选取为5~35 Hz。
PSO参数设置:本实验所设置的粒子群优化算法的各项参数以及描述如表1所示。

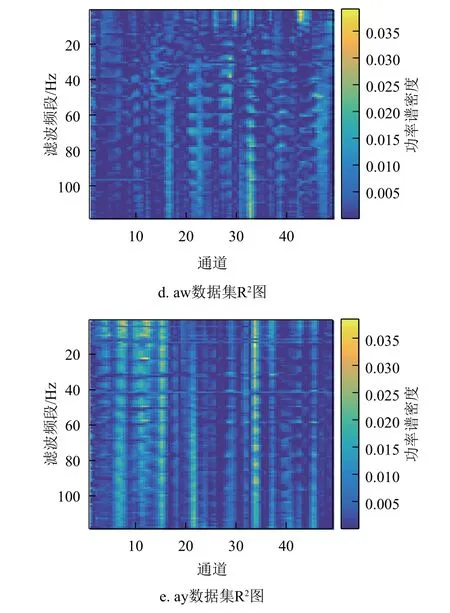
图3 带通滤波R2图
3.5 特征选择对比算法实验结果
将5个数据集的训练集和测试集按照2∶8的比例进行分割,验证不同的对比算法在训练集样本少的情况下和本实验所提方法的分类精度比较情况,并且每个算法都是经过10次实验得到的5个数据集的平均的分类正确率,具体结果如表2所示。
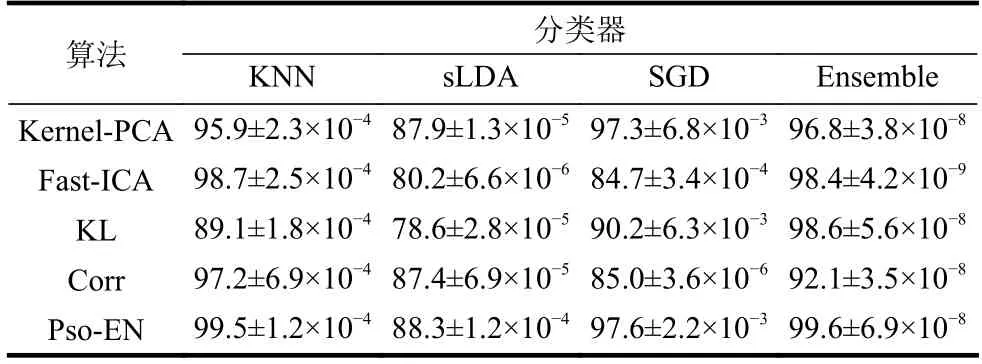
表2 各算法平均分类正确率和方差结果表%
上表展示了各个特征选择的对比算法以及本文所提方法的结果,最后一行表示本文所提出的特征选择算法。通过此表可以看出,本文所提出的特征筛选方法相比现阶段较为热门的4种算法来说,效果更优。在训练样本少的情况下,4种分类器所得到的平均分类正确率也能达到96.25%。
为了更直观地反应出这5种不同算法的区别,计算每个特征选择算法后所得到的分类器的平均F分数,并利用平均F分数值绘制图4。
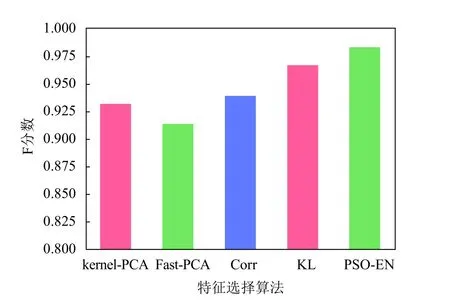
图4 特征选择算法F分数图
由上图可得,本文所提算法的F分数,在分类器平均10次后能到达0.98,超过其余4种特征选择算法,验证本文提的方法更优。
3.6 适应度函数实验结果
本实验所使用的适应度函数是3个评价指标的和,分别是Accuracy、AUC以及F_score。为了验证这3种评价指标的和是否比任意单个或两个所组成的适应度函数的效果更好,结果如表3所示。
表3展示了不同的适应度函数所得到的不同的分类效果。本实验所设计的由上述3种评价指标所构成的适应度函数在集成分类器上的平均效果能达到98.6%,因为这3种评价指标能从各个角度反映分类性能,从而互相辅助来达到更优效果。在SGD的分类效果上也分别从多到少提高了1.6%~12.3%,因此验证了本文所设计的适应度函数的效果更优。
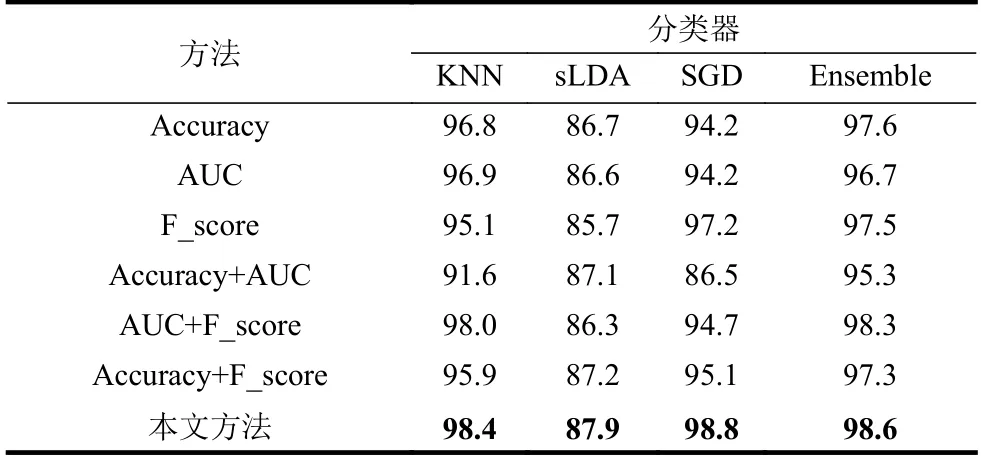
表3 不同适应度函数对应分类结果表%
3.7 不同数据的特征分类验证实验结果
为了证明本实验所提出的算法在不同数据集中都能适用,且训练集较少的情况下也表现优异,将5种数据集的训练集和测试集全部按照1∶3的比例进行分类,在4种不同分类器上得到10次结果后的平均值和方差,结果如表4所示。
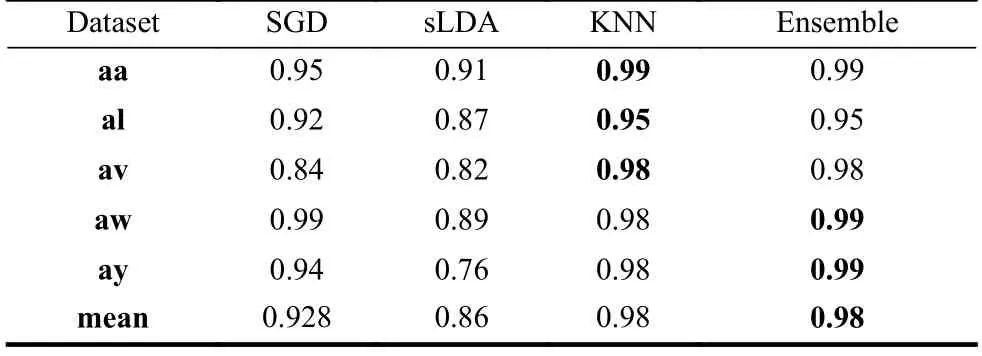
表4 不同数据分类正确率结果表
4 结束语
本文提出了一种新颖的BCI运动想象任务分类模型,该模型结合了带通滤波、小波去噪、通道筛选、特征提取、特征融合、特征选择以及模式分类。此外本文采用了PSO结合随机森林分类器的特征筛选算法,以一种新颖的方法来选择或者消除相关特征,将Accuarcy、AUC值以及F-score作为评价指标,最终得到的集成分类器98.34%的平均正确率,且AUC值和F-score也都表现优异。与其他特征选择方法来相比,表现优异,因此能够达到精确运动想象分类的目的。未来将基于现有的实验成果,继续降低该算法模型的计算复杂度,把离线分析变成在线分析,从而更好地应用在医疗康复领域中。
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
中华养生保健(2020年7期)2020-11-16 01:14:26
电子制作(2017年23期)2017-02-02 07:17:06
家教世界·创新阅读(2016年11期)2016-12-27 18:49:15
天津护理(2016年3期)2016-12-01 05:40:01
故事会(2016年15期)2016-08-23 13:48:41
中国塑料(2016年11期)2016-04-16 05:26:02
西北工业大学学报(2015年4期)2016-01-19 03:31:47
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
