
满足差分隐私保护的矩阵分解推荐算法
2021-06-19 06:46尹恩民
电子科技大学学报 2021年3期
王 永,冉 珣,尹恩民,王 利
(1.重庆邮电大学电子商务与现代物流重点实验室 重庆南岸区400065;2.桂林电子科技大学广西密码学与信息安全重点实验室 桂林 541004)
推荐系统是当前互联网商家为用户提供个性化信息服务的主要技术手段之一。协同过滤作为一类主流的推荐算法,它利用用户对项目的历史评价信息来预测用户对未知项目的好恶并据此进行推荐。协同过滤技术需要使用大量用户数据,存在用户个人隐私泄漏的风险[1]。在基于邻居的协同过滤技术中,攻击者可以通过追踪邻居用户的推荐列表变化,推测目标用户对项目的评分[2];在基于矩阵分解的协同过滤技术中,由于分解所得的隐因子矩阵携带数据信息,可能被攻击者利用,通过重构攻击等方式推断出用户的评分数据[3-4]。遭泄露的评分可能被进一步用于推测出用户的性别、年龄等信息,侵犯用户隐私[5]。如果用户出于安全考虑拒绝提供部分信息,则可能会导致推荐系统性能下降,甚至无法提供个性化服务。因此,非常有必要在推荐系统中考虑对用户信息进行隐私保护。
文献[6]提出了差分隐私的定义,为在推荐系统中实施有效隐私保护提供了良好的理论基础。文献[7]将差分隐私保护引入协同过滤技术中,通过扰动项目协方差矩阵实现差分隐私保护。文献[8]将差分隐私应用到基于邻居的协同过滤推荐算法中,通过在邻居选择和相似性度量过程中加入噪音,实现隐私保护。文献[9]提出了两种分别对原始评分和用户相似性度量过程添加Laplace噪音的隐私保护方案。
针对基于矩阵分解的推荐算法,文献[10]在考虑推荐系统不可信的情况下,扰动矩阵分解算法的目标函数,将实施了隐私保护的项目隐因子矩阵用于推荐任务。文献[11]假设用户有不同程度的隐私保护需求,基于概率矩阵分解提出一种个性化的差分隐私推荐算法。文献[12]通过对目标函数进行扰动,提出了基于联合优化的隐私矩阵分解方案。文献[13-14]将差分隐私保护应用到矩阵分解推荐算法中,设计了3种添加噪音的方式,即分别在输入信息中、训练过程中和输出信息中添加噪音。依据这种思想,文献[15]在SVD++模型上设计了3种差分隐私保护模型。目前的工作大多通过对矩阵分解过程的各种结果(如梯度、隐因子矩阵、目标函数)加入噪声项以实现差分隐私保护,这类方案存在如下问题:1)噪声较大。较高的隐私保护需求或敏感度会使噪声分布的方差增大,导致加入过大的噪声;2)不具通用性。加噪方法可能导致最终解在有约束问题上不可行;3)没有考虑隐因子的重要程度,影响了算法求解效率。
针对上述问题,本文将遗传算法引入矩阵分解任务,使得差分隐私保护可以通过扰动候选解的选择过程实现,而不依赖于上述加入噪声的方法[16]。此外,遗传算法中解的搜索将在可行域内进行,易于延伸到带约束的矩阵分解问题。然而,直接应用遗传算法存在如下困难:首先,矩阵分解属非凸问题且参数量大,求解难度高;其次,如何减小隐私保护机制引入的扰动也是重要挑战。为解决上述问题,本文改进了遗传算法的关键步骤,提出一种满足差分隐私保护的矩阵分解方案。本文的主要贡献为:1)将矩阵分解转化为两个交替进行的用户隐因子和项目隐因子优化问题,有效克服了求解过程中存在的解空间高维性和优化中的非凸性问题。2)考虑用户或项目对隐因子的不同偏重,重新设计了遗传算法的变异过程,提升解的搜索效率;在此基础上利用增强指数机制减轻了算法受扰动程度,更好地实现了隐私保护水平和算法效用之间的平衡。
1 理论知识
1.1 矩阵分解算法
矩阵分解是隐语义推荐模型的典型算法,它将用户和项目均映射到相同的d维隐因子空间中[17]。将用户u对应的隐因子向量表示为P u∈Rd,将由所有用户的隐因子向量构成的矩阵表示为P;将项目i的隐因子向量表示为Q i∈Rd,将所有项目的隐因子向量构成的矩阵表示为Q;则矩阵分解算法就是求解满足式(1)的最佳P和Q:
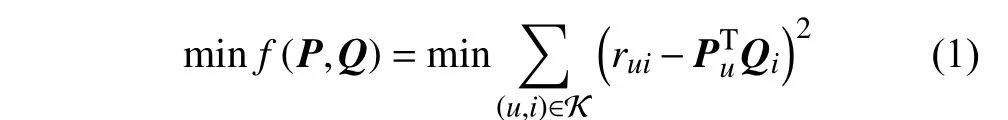
式中,rui为用户评分矩阵r中用户u对项目i的评分;K为观测到的评分数据对应的用户−项目对(u,i)集 合。假设r中包含的用户数为m,项目数为n,则有r∈Rm×n,Q∈Rn×d,P∈Rm×d,其中d≪m,n。
1.2 差分隐私
差分隐私(differential privacy,DP)是一种新型隐私保护框架,通过添加可控的噪声到数据的统计结果中,保证隐私不被泄露且数据具有可用性。
定义1差分隐私(DP)[6]:对于任意的邻近数据集D和D′至多相差一条数据,且随机算法A所有可能的输出O⊆Range(A),当且仅当满足不等式(2)时,A满足ε-差分隐私:
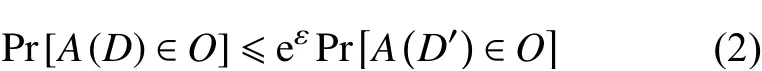
式中,ε为隐私预算,当ε值越小时,隐私保护的需求水平越高。
1.3 指数机制
指数机制[18]是一种实现差分隐私保护的技术手段,其定义如下。
定义2指数机制:设随机算法M的输入为数据集D,输出为ω ∈Ω。 函数Q(D,ω)→R为 ω的可用性函数。若算法M以正比于e xp(εQ(D,ω)/Δ)的概率从Ω 中选择并输出ω,则算法M提供ε-差分隐私保护,称算法M为指数机制。其中,Δ为可用性函数Q(D,ω)的阻尼因子,也称Q(D,ω)的敏感度,表示单个数据的差异对Q(D,ω)造成的最大影响。假设D′与D为邻近数据集,Δ满足不等式:
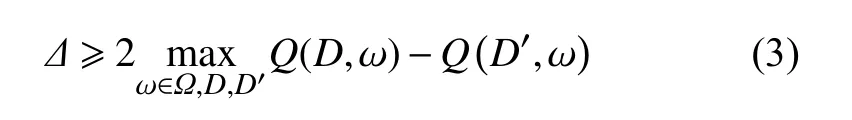
1.4 增强指数机制
文献[16]针对模型拟合问题设计了增强指数机制,与指数机制相比,增强指数机制的应用限于可用性函数,具有特定形式:
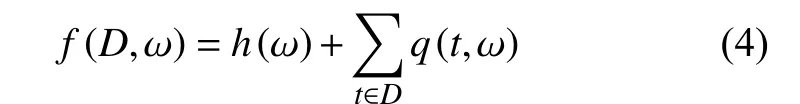
式中,D是包含了n个元组的数据集;T 是任意元组t的取值范围;q(t,ω)为元组拟合函数,表示模型对D中单个元组t的拟合程度;h(ω)是独立于数据集D的函数。基于此可用性函数,增强指数机制的定义如下。
定义3增强指数机制(enhanced exponential mechanism,EEM):设随机算法M的输入为数据集D,输出为 ω∈Ω。 算法M以正比于exp(εf(D,ω)/Δ)的概率从 Ω中选择并输出ω,其中f(D,ω)满足式(4)且Δ 满足不等式:
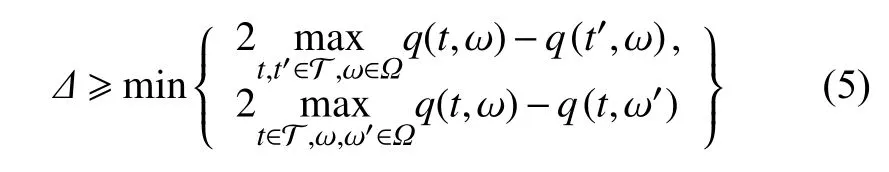
那么算法M提供ε-差分隐私保护,称算法M为增强指数机制。
2 隐私遗传矩阵分解算法
2.1 算法总体流程
本文算法围绕推荐系统的评分矩阵分解展开,将隐因子矩阵P和Q的求解过程转化为两个交替进行的优化过程。在优化过程中使用遗传算法求解,并在求解过程中引入增强指数机制,进而使矩阵分解过程满足差分隐私保护。本文算法的总体流程如下:
1)为提高评分预测准确性,对用户评分矩阵r进行预处理,即设边界参数为B,将评分转化到[−B,B]的范围,得到新的用户评分矩阵R。然后,对矩阵R进行隐因子分解,即:
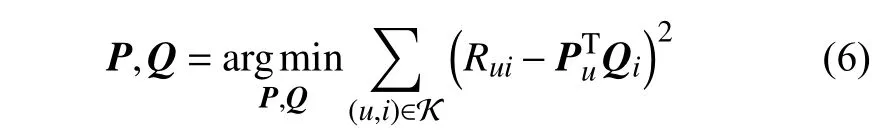
式中,Rui为R中用户u对项目i的真实评分。隐因子分解的目标是找到使预测评分与真实评分误差平方和最小的P和Q矩阵。
2)将式(6)的目标问题转换成两类特征求解任务:1)求解用户的隐因子向量;2)求解项目的隐因子向量。即在求解P u时,将矩阵Q看作常数,构建目标函数:
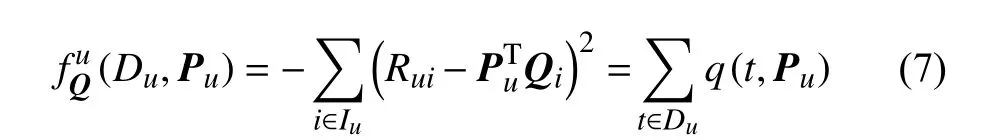
同理,在求解Q i时,保持P矩阵不变,构建目标函数:3)首先保持矩阵Q不变,使用2.2节设计的隐私遗传算法(APrivGene)为每个用户求解式(7)所示的优化问题,得到对应的用户隐因子,更新矩阵P。然后,保持矩阵P不变,同样使用2.2节设计的隐私遗传算法为每个项目求解式(8)所示的优化问题,得到对应的项目隐因子,更新矩阵Q。交替重复上述过程,持续优化P和Q矩阵,直至达到最大迭代次数T。
上述隐私遗传矩阵分解算法的伪代码如算法1所示,其中改进的隐私遗传算法APriveGene将在2.2节中进行详细说明。


2.2 改进的隐私遗传算法
本算法对文献[16]中的隐私遗传算法进行了改良,提出调整的隐私遗传算法(adjusted private genetic algorithm, APrivGene)。使用APrivGene算法对式(7)和式(8)所示的优化问题进行求解,在选择阶段引入增强指数机制,实施对矩阵分解过程的隐私保护。按照执行顺序、从初始化、选择和变异3个方面介绍APrivGene算法。
初始化阶段:设置包括ε在内的各个控制参数。然后,随机生成l个d维的向量作为初始候选解集 Ω ,计算 Ω 中每个解的目标函数值f(D,ω)作为遗传算法的适应度值。
选择阶段:以f(D,ω)为可用性函数,使用ε/2TG作为选择操作的隐私预算,应用增强指数机制EEM以正比于 exp(εf(D,ω)/2TGΔ)的概率从 Ω中挑选出 ω。为了有效减轻选择阶段引入的扰动,只选出单个个体进行后续操作,之后将 Ω置空,准备接纳新解。
变异阶段:为避免交叉操作造成敏感度过大,只使用了变异操作。为了改善寻优效率,采用全局搜索效率较高的柯西变异算子生成变异扰动,即从标准柯西分布C(0,1)中生成随机扰动。然后,以寻找重要程度最高的隐因子为目的,让变异操作对各个隐因子进行变化,且每次只在一个维度k上搜索。由于用户或项目对某隐因子的偏好可分为正负两类,对单个隐因子的扰动对应地被设计为正负两个方向。对每个维度进行上述变异,每次变异生成两个新解,加入Ω ,最后形成新的候选解集。
生成新集合之后,为逐步减小搜索范围提高寻优效率,使用衰减因子β 缩减变异步长η。然后,返回选择环节,进入下一轮循环。当达到最大迭代次数G时,使用EEM方式选出最终解ω∗。
上述改进的隐私遗传算法的伪代码如算法2所示。

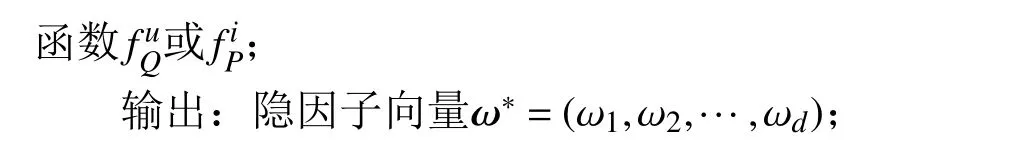
初始化算法中的控制参数:设置隐因子个数d,隐私预算ε,变异步长η,衰减因子 β<1,最大迭代次数G,候选解集Ω 的大小l;

在算法2中,为了发挥增强指数机制的作用,在每次迭代中需要根据当前候选解,求解增强指数机制中的阻尼因子。求解过程如2.3节所示。
2.3 阻尼因子求解
在求解隐因子向量时,根据候选集合中个体的适应值f(D,ω)和隐私预算ε,EEM将按照如下的概率输出用户隐因子向量和项目隐因子向量:
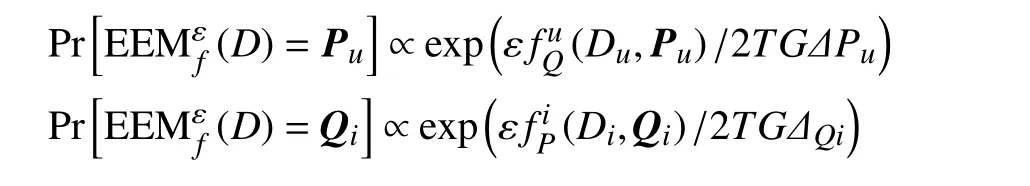
数据集Du或Di中的元组t有d+1个属性,其中预处理后的评分数据Rui在 [−B,B]之 间,|Puk|≤1和|Qik|≤1,k∈{1,2,···,d},所以元组t的取值范围T=[−B,B]×[−1,1]d。设 ΔPu为求解用户隐因子向量时的阻尼因子, ΔQi为求解项目隐因子向量时的阻尼因子,则根据增强指数机制的定义可得:
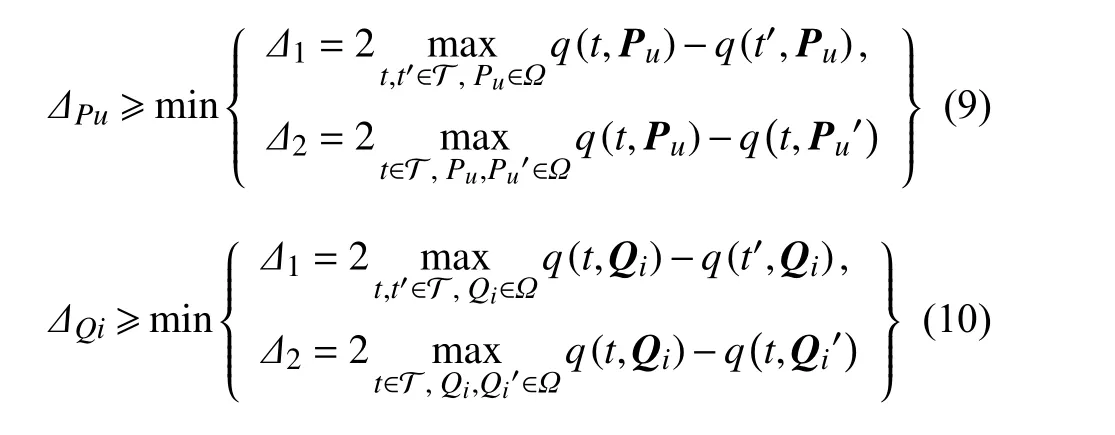

同理可得求解项目隐因子向量时阻尼因子ΔQi应满足的条件为:
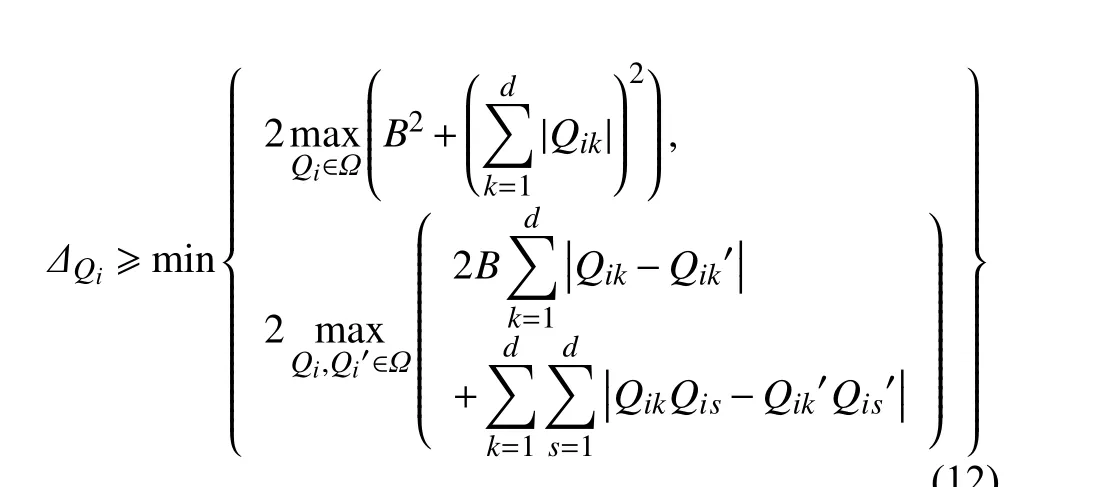
观察 ΔPu和 ΔQi应 满足的条件,可以发现 Δ2衡量的是候选解集中各隐因子向量之间的差异。在多数情况下 Δ1>Δ2,这是因为随着APrivGene的迭代,q(t,P u)−q(t,Pu′)或q(t,Q i)−q(t,Qi′)的 值 会 逐 渐 减小,但 Δ1的值并不会受到APrivGene迭代的影响。所以,随着APrivGene迭代次数增加,阻尼因子会减小,增强指数机制可以选择出更精确的解,从而有效保证算法的效用。
3 算法的分析
3.1 安全性分析
定理1算法1满足ε-差分隐私。
证明:令D为数据集Du或Di,D′与D为其邻近数据集,t和t′分别表示D与D′中相异的元组;令ω为隐因子向量P u或Q i,在应用APrivGene求解ω时,设EEM的隐私预算 ε′=ε/2TG,T表示算法1(PGMF)中外循环的次数,G表示算法2(APrivGene)中的最大迭代次数。令Δ 为EEM的阻尼因子ΔPu或ΔQi,根据2.3节中式(9)和式(10),考虑以下两种情况:


故应用APrivGene算法求解隐因子向量时,其每一轮迭代均满足ε /2TG-差分隐私。由差分隐私保护的序列组合性质可得,更新每个用户或项目的隐因子向量时算法满足 ε/2T-差分隐私,算法1满足ε-差分隐私。
3.2 效用分析
3.2.1对问题转化的分析
本文算法将矩阵分解的求解转换为对两个优化问题的求解,这样处理有两点优势:
1)更好地体现个性化的思想。因为直接求解式(6)可能忽视单个个体的推荐质量。转化为式(7)和式(8)所示的问题后,可以为每个用户或每个项目分别设计其专属的考虑隐私保护的隐因子值,更好地体现个性化的推荐思想,利于提升推荐精度。
2)提升算法效率和效用。直接对原问题应用遗传算法求解,解的维度将是d×(m+n),而推荐系统中的用户数m和项目数n通常都很庞大。采用遗传算法在高维空间中寻优,将会导致效率非常低。同时,原问题关于P,Q是非凸的,也会导致算法收敛速度慢。过慢的收敛速度,会导致迭代轮次增加。由于需要在每轮迭代中添加隐私保护的噪音,会导致噪声增大,从而使解的质量下降甚至不可用。本算法将原问题分解为两个优化问题,使得各个子问题都是凸问题,且解的维度是隐因子个数d,它远小于m和n,极大地提高了求解的效率,也利于提高解的效用。
3.2.2改进隐私遗传算法的分析
APrivGene算法是PrivGene算法的改进算法。PrivGene算法并没有对变异操作进行专门的设计,它所采用的随机变异方式,将导致解的搜索效率不高,影响最终解的质量。APrivGene算法在变异操作中,对选择的个体沿着解的各个维度,从正反两个方向使用标准柯西分布生成随机扰动进行变异,具有如下优势:
1)有助于EEM选出更好的解。EEM的特点是,当候选解之间的变动程度不大时,其敏感度将取得较小值从而减轻选择过程的扰动。单维度变异所生成的新解之间只存在一个隐因子上的差异,此时式(9)和式(10)中对于ΔPu和ΔQi通常有Δ1>Δ2。随着算法逐渐收敛, Δ2的取值将更小,增强指数机制的阻尼因子减小,使得选中优质解的概率提高。
2)有助于提高解的搜素效率并减少扰动。矩阵分解中用户和项目共享相同的隐因子,但不同的用户或项目对不同的隐因子会有不同程度的关注,单维度变异将有利于快速找到相对重要的隐因子。用户或项目对隐因子只有正向或负向两类偏好,变异算子在隐因子的正负方向上同时进行搜索,而非随机搜索,符合实际情况。该做法有效提升了解的搜索效率,同时控制了候选解之间的变动程度,减轻选择过程受到的扰动。
3)标准柯西分布 C(0,1)由于有较高的两翼概率特性,具有较好的全局搜索能力,能帮助算法在迭代的初期保持一定程度的多样性。设置了衰减因子β在每次迭代时对步长η 进行缩减,利于在迭代后期增强指数机制实现更优的选择。因为随着迭代进行,式(9)和式(10)中ΔPu和ΔQi的值Δ2会逐渐减小,但 Δ1的值并不会受到影响,这样增强指数机制的阻尼因子会减小,使选择过程受到更少的扰动,做出更优的选择。
4 实验结果与分析
4.1 实验数据
采用两个常用数据集Movielens100K和YahooMusic进行实验,按8∶2的比例随机划分为训练集和测试集。两个数据集的统计属性如表1所示。
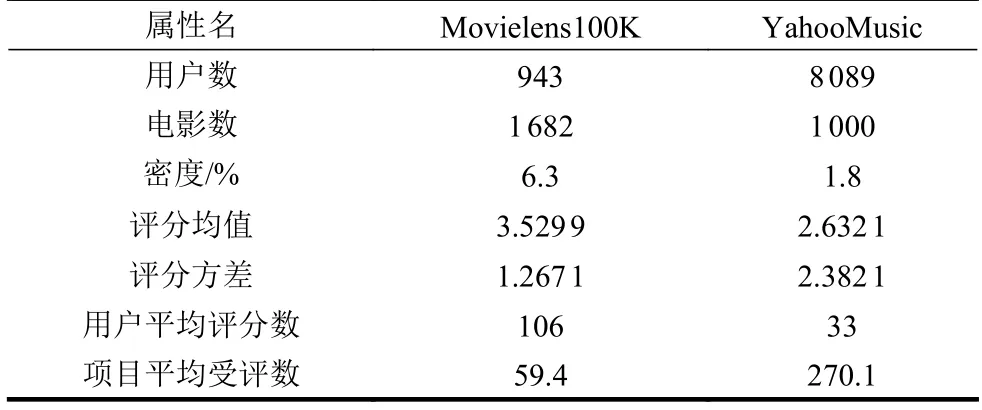
表1 实验数据集统计属性
4.2 实验算法与评估指标
除本文算法外,还对其他一些类似算法进行了对比实验。实验中涉及到的算法及其描述如表2所示。
本文取10次实验的平均值作为最终结果。采用均方根误差(RMSE)度量算法的性能:
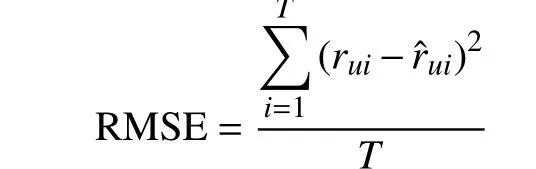
式中,T为有效预测项目的个数;rui为用户u对项目i的真实评分;rˆui为用户u对项目i的预测评分。RMSE越小则推荐精度越高。
4.3 实验结果
采用文献[14]中的预处理方式,将评分区间转换为[−1,1],设置隐因子变量域为[−1,1]。在APrivGene中,最大迭代轮次为23,候选集大小为85,柯西变异算子的步长为0.2,步长的衰减率为0.95。对比算法的参数设置均遵循相应文献中的最优参数设置。
为了保证有效的隐私保护,实验中将隐私预算ε设置为较小范围,即 ε∈[0.1,1]。图1和图2分别给出了本算法与其他对比算法在Movielens100K和YahooMusic两个数据集上的RMSE测试结果。其中,将不考虑隐私保护的ALSBase算法的实验结果作为对比基线。从整体上看,随着ε的增大,各个算法的RMSE均逐渐减小,表明随着隐私保护水平的下降,推荐准确性增加。各算法在Movielens 100K数据集上的推荐准确性均高于YahooMusic数据集,主要原因是YahooMusic数据集具有更高的稀疏性。
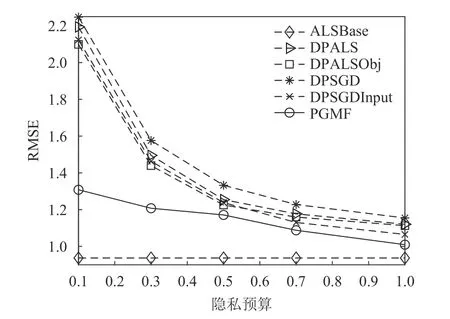
图1 Movielens100K数据集上的RMSE测试结果
在图1中,随着ε的变化,PGMF在Movielens 100K数据集上的RMSE为: 0.995≤RMSE≤1.308,低于其他的隐私保护算法。同样的趋势也存在于YahooMusic数据集的测试中。在图2中,PGMF的RMSE总是低于其他对比算法,其RMSE值的范围为1 .290≤RMSE≤1.670,比其他隐私保护算法平均低0.2左右,显示出了更好的准确性。在两个数据集上,PGMF与不考虑任何隐私保护的ALSBase算法的RMSE差距是最小的,同样证明了PGMF具有更好的推荐准确性。
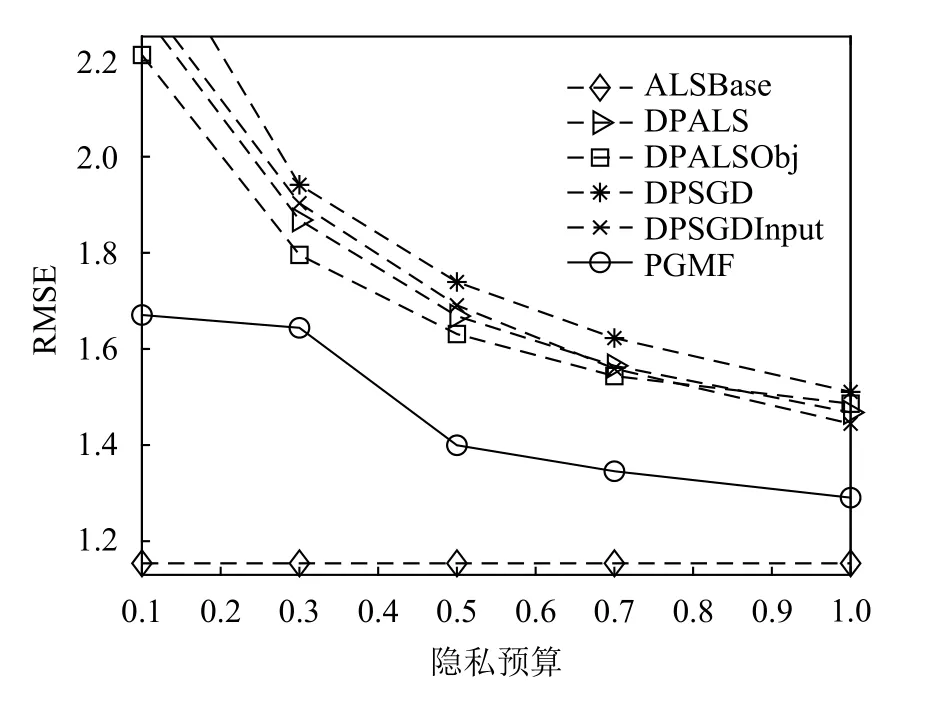
图2 YahooMusic数据集上的RMSE测试结果
在本实验中,DPALS算法的推荐准确性比DPSGD算法要高。因为在不考虑隐私保护的情况下,ALS的性能比SGD要好,这种优越性在考虑差分隐私的情形下同样存在。但是,这两种方法都是基于传统优化方式的算法,当隐私预算ε越小,DPSGD和DPALS所引入的噪声就越大,导致求解出的隐因子向量与最优解之间差距过大,推荐准确度降低。在图1中,ε =0.1时,DPALS与DPSGD的RMSE都超过了2.1,而PGMF的RMSE只有1.3;在图2中,ε=0.1时,DPALS与DPSGD的RMSE都超过了2.3,而PGMF的RMSE只有1.67。比较结果说明在隐私保护要求较高时,PGMF的优势更为明显。
DPSGDInput算法是文献[13]中表现最优的算法,直接对评分数据添加噪音。它不需要在矩阵分解过程中分配隐私预算,在较低隐私保护需求下具有良好的推荐准确性。当ε=1时,其RMSE值在Movielens100K与YahooMusic数据集上分别为1.06和1.44,是除PGMF算法以外最低的。但是,这种直接对数据集加噪音的方式在高隐私保护需求下会引入过大的噪声。从图1和图2中可以看出,在ε<0.5时,该算法的推荐RMSE值显著增加,其推荐准确性比DPALSObj算法和PGMF更差。
DPALSObj算法通过对目标函数进行扰动而实现隐私保护。它的推荐精度在高隐私保护条件下,即ε∈[0.1,0.5]时,优于除PGMF之外的其他隐私保护算法。这种方法对隐私预算的大小比较敏感,在高隐私保护需求下相对于PGMF仍然引入了过大的噪声,即便在其表现更为突出的YahooMusic数据集上,其RMSE仍然明显比PGMF高。
PGMF的性能优于其他算法的主要原因是采用了独特的进化方式限制了候选解集的方差,又借助增强指数机制改善了解的选择过程。所以,即使在很小的隐私预算条件下,求解出的隐因子向量都不会偏离最优解太远,实现了更高的推荐准确度。
5 结束语
本文针对推荐系统中的隐私问题提出了一种满足差分隐私保护的矩阵分解算法。该算法将矩阵分解问题转化为两个交替进行的优化问题。在遗传算法的选择操作中采用了增强指数机制使得整个矩阵因子分解的过程满足差分隐私保护。基于搜索重要隐因子的思想,设计了遗传算法的变异操作,从正反两个方向变异隐因子,不仅提高了算法的效率而且有效增强了解的性能。在两个标准数据集上的实验结果表明本文算法能更好地平衡隐私性和推荐的准确性,尤其在隐私保护需求较高的条件下,仍然可以取得良好的推荐效果,具有很好的应用潜力。
猜你喜欢
数学杂志(2022年5期)2022-12-02
新世纪智能(数学备考)(2021年5期)2021-07-28
趣味(数学)(2020年4期)2020-07-27
支部建设(2020年15期)2020-07-08
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
现代计算机(2016年34期)2016-02-28
智能系统学报(2015年4期)2015-12-27
百科知识(2015年18期)2015-09-10
信息安全研究(2015年3期)2015-02-28
