
基于句法的神经机器英语翻译研究
2021-06-14 13:02陈敏
电子设计工程 2021年10期
陈敏
(咸阳师范学院,陕西咸阳 712000)
机器翻译作为自然语言处理和人工智能研究领域的研究方向,主要是利用计算机来实现不同语言间的相互转化[1-3]。目前,较多互联网企业提供了多语言在线翻译服务,如谷歌翻译、微软Bing 翻译、百度翻译等,但机器翻译质量与专业译文间依然存在较大差异,尤其是在翻译一些长语句方面,对源语言和目标语言间的语序差异,难以进行准确描述[4-7]。为解决长距离调序问题,相关学者进行了多方面研究[8-10]。如基于最大熵的调序模型,通过句子中不同词汇间的相互关系完成语句的精确翻译[11];一些学者将源语言句法信息植入到翻译模型,有效提升了长距离调序的描述准确度,但容易造成翻译解码时间延长的问题[12];一些学者提出一种预调序方式,直接将源语言段转化为目标语言语序,有效解决了长语句翻译中的调序问题[13]。
在相关研究基础上,文中基于语言翻译中长距离调序问题,提出了一种基于神经网络的语言翻译预调取模型,通过建立线性排序框架来建立神经网络模型,实现在多样本语句和语义的有效信息抽取,预测语言翻译中存在的语序差异,提高翻译准确度。
1 英语语义参数处理
1.1 语义词汇的向量化表示
在传统自然语言处理系统中,通常将词汇当作高维稀疏特征。该文在相关研究基础上,为提升高维词汇推广能力,通过建立神经网络模型实现高维词汇的低维稠密转化,利用映射关系将相似词汇量转为低维相似点,建立负抽样快速学习算法,如图1所示。
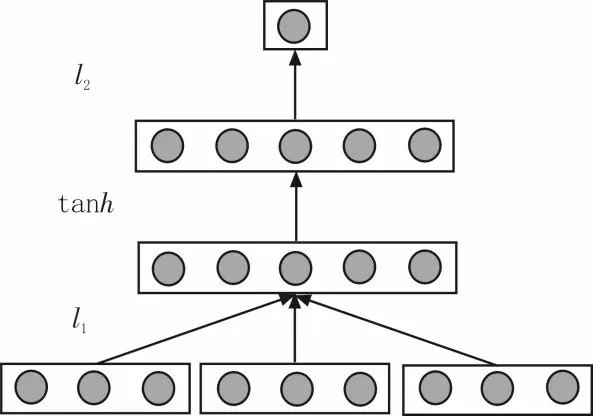
图1 神经网络学习结构图
神经网络通过查找表LOOKUP 搜索长度为2n+1的词汇{w-n,…,wo,…,wn},采用向量表示词汇量v(wi),根据一定关系进行关联,在经过线性层l1、正切双曲层tanh和线性层l2转换下输入,式(1)为系统输入文本的向量化处理:
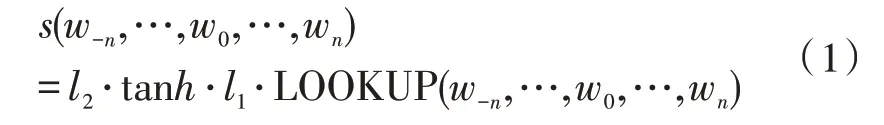
为保证神经网络能够区分真实文本片段与随机生成的错误片段,即对于真实文本片段(w-n,…,w0,…,wn),随机从词汇表选择词w′替换掉真实文本中的w0,获得新的文本片段(w-n,…,w′,…,wn)。为保证片段的真实性,要求较新的文本片段有一个高的分数,使用随机梯度下降方法对目标进行优化,如式(2)所示。
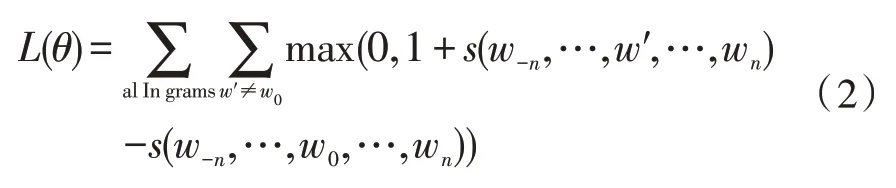
同时,Mikolov 等也提出了基于Skip-ngram 的快速学习词汇算法[14],利用前馈神经网络建立词w与上下文中词汇c(w)间的条件概率模型,基于哈夫曼树层级softmax 加速,确定上下文词汇c(w)条件概率模型为:
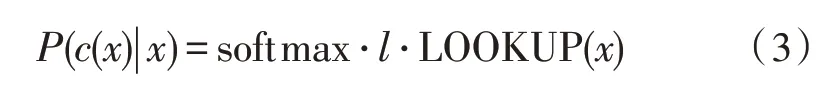
其中,l为一个线性层,以词汇长度为输入长度,词表大小作为输出长度,利用softmax 实现l的归一化处理。神经网络得到庞大的样本后,进行词汇训练,得到对应向量特征和低维度相近空间,并输入到建立的调序模型中。
1.2 线性排序模型
线性排序模型将一个序列排序分解为序列中元素两两排序的子问题的总和,即对序列{1,2,…,n}对应一个置换π,给定的分数为:
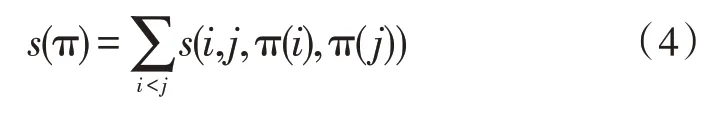
式中,s(i,j,π(i),π(j))为词对(i,j)的排序分数。当π(i)<π(j) 时,有关系s(i,j,π(i),π(j))=s(i,j,0),即当(i,j)变换位置时,词汇顺序改变不会对语义造成影响,反之,存在有s(i,j,π(i),π(j))=s(i,j,1),则(i,j)变换位置对词汇语义造成影响。对一个需要调序的源语句src={w1,…,wn},存在一个调序结果{wπ(1),…,wπ(n)},通过调序模型给出的分数为词汇调序分数和,即:
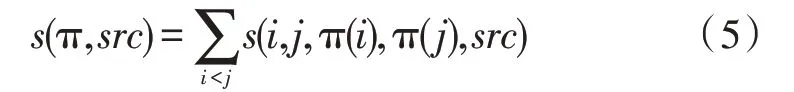
工作中的s(i,j,π(i),π(j),src)由一个线性分类器实现,即:
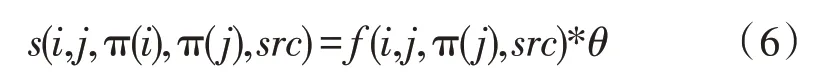
式中,θ为特征权重,f为特征向量。在调序模型框架下,机器翻译预调序转化为寻找最高分置换过程,其中,特征向量f是模型性能的关键,通常采用大量高维词汇特征表达,并引入词类、词性标准进行特征向量平滑。
2 翻译语义预调序训练
2.1 预调序模型
该文基于神经网络建立预调序模型,将词汇调序问题分解为两两排序问题,通过多层神经网络进行排序打分[15]。具体说,对于句子src={w1,w2,…,wn},给出的调序结果评分为:
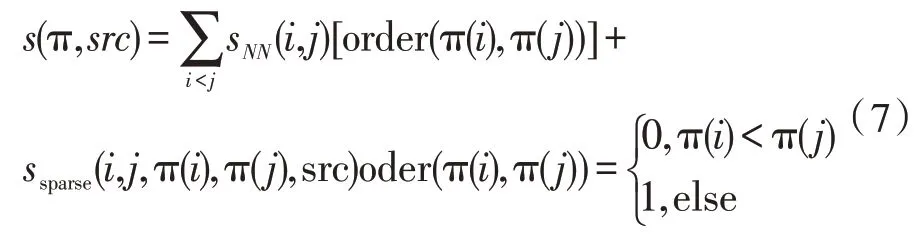
式中,sNN和ssparse分别为神经网络和稀疏特征计算评分值,输入量为第i,j上下文词汇,输出为二维向量。确定模型调序的输出最优解为:
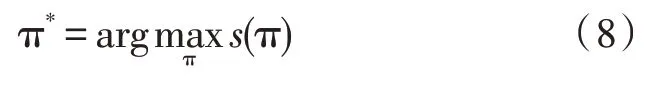
2.2 调序训练数据
调序数据训练主要从双语平行预料中获取训练数据,并根据训练数据对模型进行参数学习[16]。对于一个有词对齐信息的双语句对(e,f,α),其中e为源语言句子,f为目标句子,a为二者间词对齐关系。要获得源语言句子e重排序π*,使它和目标语言句子f语序相近,采用交叉连接数来评价调序结果,用数对(i,j)表示词对齐连接,即源语言第i个词与目标语言第j个词间建立相互连接关系,则称两个词链接(i1,j1)和(i2,j2)之间为交叉关系,若满足式(9)中的关系:
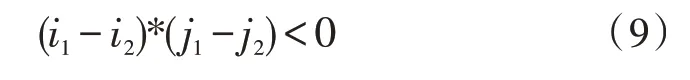
此时定义:
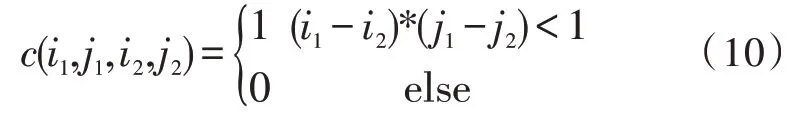
则源语言为一种重排序π 的交叉连接数相应的计算公式为:
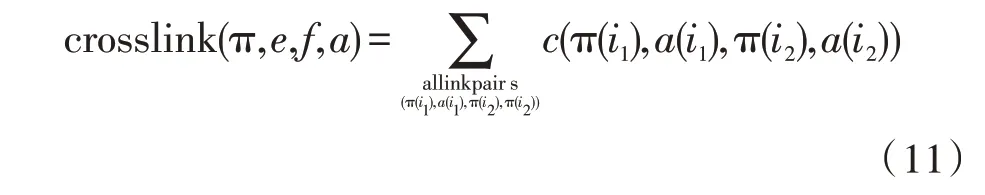
通过计算获得交叉连接数最小重排序π*,则源语言的重排序的交叉连接数为:
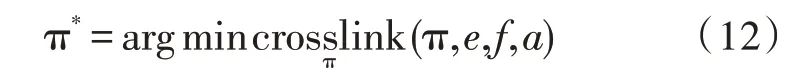
当源语言和目标语言语序完全一致时,这个交叉连接数为0。语序差异性越大,则交叉连接数也就越大。由于重排序的数量与句子长度间呈现出一种指数级关系,因而无法准确寻找到交叉数对的最小重排序。基于此,可采用CKY 动态规划在O(n3)的时间复杂度下获得最优解。同时需要注意,由于存在空对齐形式,可能存在多个交叉连接数的最小重排序,在这种情况下,随机获得的任意一个最小重排序作为目标排序。
2.3 参数学习
通过调序训练数据可以得到双语句对(e,f,α)的一个交叉连接数最小重排序π*。为确保预调序的准确度,首先需对获得的训练数据执行参数训练。假设θ为训练参数,其中包括了稀疏特征权重向量与网络参数,采用最小化损伤函数[17]对模型进行参数训练学习:
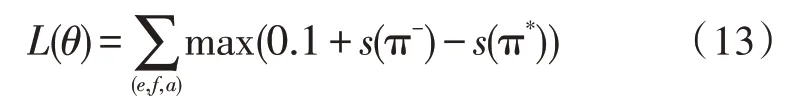
其中,π-为排序中分数最高的重排序。对于双语料中所有句对,从中随机抽取一个句对,用当前参数值进行CKY 解码[18],获得π-,并与π*进行比对,若对比损失不为0,则根据获得的最小损失梯度[14]进行参数更新:

其中,γ为学习率,∇L(θ)为稀疏特征权重参数的梯度,对应的关系式为:
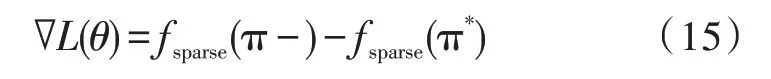
fsparse为系统特征向量,可通过反向传播算法计算获得。当模型参数初始化时,由学习的词汇向量作为查找表参数初始值,将神经网络两个线性层参数初始化到一个小区间,稀疏特征权重的初始值设为0。
3 实验分析
3.1 实验数据
为验证该文建立模型的有效性,选择中英互翻译进行实例验证。实验数据包括用于训练词汇向量的单语文本,由互联网中随机抓取,经过正规化、去重处理后获得的英文文本;用于与调序模型和翻译模型的双语数据,由互联网中抓取,包括中文到英文数据包2 600 万句;用于测试评价的测试数据,采用NIST05 作为开发集NTST06 和NTST08 为测试集,NIST 作为机器翻译评测测试集。
为验证该算法模型的翻译性能,对比实验选择未经处理的预处理翻译系统。对神经网络模型,采用的词汇向量长度为100,设置网络输入层为5 个节点数,隐含层长度为50个节点数,设置初始学习率为0.1。
3.2 结果分析
在中英文数据集上进行实验,采用BLEU-4 作为评价指标,如表1 为机器翻译实验结果。可以看出,采用神经网络的预调序模型得到的翻译效果可以显著提高,这是因为在中英文翻译中,调序更多的是以词汇化模式为介入点[19-20],而神网络模型通过对词汇进行向量化表示,寻找其中的相似性,有效提升了词汇间的关联程度,因而具备更好的翻译效果。
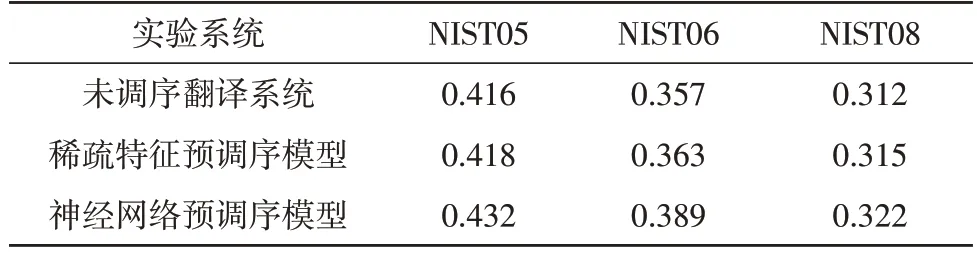
表1 中文到英文翻译结果
同时,采用源语言和目标语言间词对齐交叉连接数进行评价。源语言和目标语言语序越接近,则对齐交叉连接数越小,预调序效果越好。表2 中对随机选定的500 个中英文语言数据集进行词堆积标准测试,可以看出,神经网络的预调序模型获得的对齐交叉连接数仅有16.8,远小于稀疏特征预调序模型和未调序翻译系统,有效提升了预调序效果,获得的语句翻译质量更优。

表2 中文到英文交叉连接数均值
4 结束语
针对长距离调序中难以对翻译词汇进行有效描述的现象,提出一种利用神经语言模型实现对文本词汇的向量化表示,建立基于神经网络的翻译预调序模型。模型融合在线性排序框架,从大量样本数据获得句子词汇间的句法和语义信息,获得不同语言间潜在的语序差异。最后通过建立不同的翻译模型进行性能对比结果表明,采用提出的神经网络预调序模型有效提高了系统性能和翻译准确度。
猜你喜欢
教育教学论坛(2019年18期)2019-06-17
河南教育·高教(2019年3期)2019-04-11
北方文学(2018年18期)2018-09-14
国际汉语学报(2016年1期)2017-01-20
考试周刊(2015年36期)2015-09-10
疯狂英语·中学版(2013年7期)2013-08-01
