
基于Hadoop 的智能配用电数据存储处理的设计研究
2021-06-11 03:53曾麒杰符晓洪柳羿何宽政张升平
电子设计工程 2021年11期
曾麒杰,符晓洪,柳羿,何宽政,张升平
(深圳供电局有限公司,广东 深圳 518000)
电网公司涉及业务广泛,因此业务生成数据面和类别也比较多,包括结构化、地理信息以及海量时序测点数据等不同类型数据。基于多种类型数据共存的现象,需要构建一个可以实现数据综合分析利用的平台[1]。当前,在非结构化或半结构数据存储中,通常选用文件存储方式,没有实现关于文档、音频和视频等文件的检索功能,同时,对于不同数据的混合也无法实现深入挖掘分析。在此情况下,需要构建一个能够采集、存储、过滤大量低价值密度的数据对象,且可以针对数据实施分布式计算及各种算法,以此对其实施深入挖掘分析,从而提升数据利用价值,为公司管理决策提供支持[2-3]。Hadoop 下的数据存储处理设计可以满足以上需求,不但能够满足智能配用电数据存储需求,也能够提升数据处理效率,为数据分析应用提供便利。
1 Hadoop存储处理能力
Hadoop 技术体系包含有多种技术,例如全分布式架构、在线扩容减容等,可以实现对PB 级以上规模数据在线存储的支撑,为智能配电网不断加大的数据体量存储提供重要支撑作用。在Hadoop 技术中,一项重要任务即为数据计算,具备有Kafka+Storm 数据流计算功能。对于时间窗口中应用系统出现的流动数据,可以不实施持久化存储,在内存中直接导入且实时计算,数据处理的速度平均在10 万条/s 以上,吞吐量在100 M/s 以上。所具备的Spark 内存迭代计算,对于计算中的磁盘I/O 具有显著的降低作用,实时计算和交互式查询对于配电网海量数据中的实时/准实时处理具有显著改善作用[4]。
2 海量异构数据存储和处理
海量异构数据存储和处理如图1 所示。对于配电网业务中海量规模的非结构化以及非结构数据存储,通常采用的是集中式和阵列式存储方式,导致存在扩容性不足、可用性不佳以及可靠性偏低等问题,影响数据存储质量[5-6]。Hadoop 技术下的分布式存储技术在应用中,可以实现对海量数据存储问题的有效处理,同时也能够基于Hadoop 为数据处理提供MapReduce 统一并行计算框架,从而实现对相关数据的综合开发应用,以此实现对智能配电网业务中海量异构数据共存以及计算分析问题的有效处理。

图1 海量异构数据存储和处理
3 框架建构
3.1 总体框架
智能配电网数据存在的特点有用户种类复杂、海量、多样化、涉及面广以及发现数据价值较难等,数据本身也具有一定的内在规律,具有大数据信息特征,数据存储以及处理中存在有较大开发空间。比如,若可以在大数据分析工具的应用下实现对用户日志信息、功能以及用电特征的有效分析,从而实现区域内相应能源需求的有效预测评估,则可以为智能配电网未来营销业务拓展提供相应发展思路[7-8]。在智能配电网数据存储中,在结构化以及非结构化数据存储处理中建构3 个层级实施管理,其中分别为资源层、存储层以及查询层,如图2 所示。
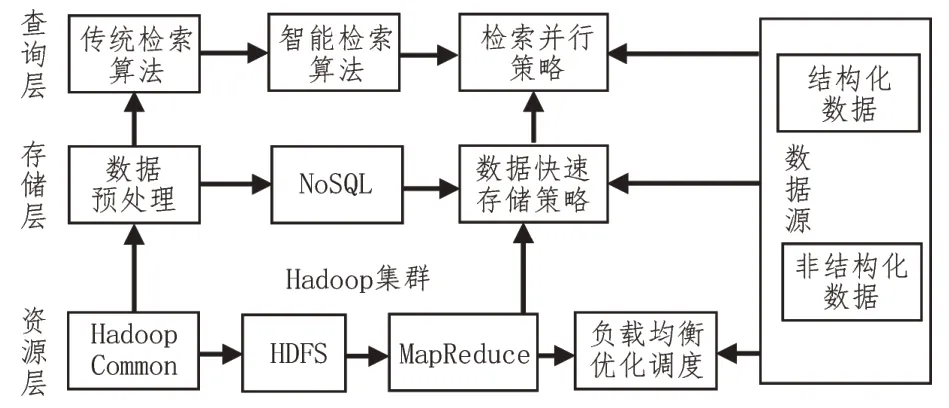
图2 智能配电网数据存储技术框架
3.2 资源层
在智能配电网的数据存储中,资源层是基础部分,是在Hadoop 技术的应用下,与配电网数据资源特性相结合,针对疏忽存储资源实施良好的管理[9]。在配电网数据管理中,资源层建立在分布式主从式技术上,可有效整理、分析配电网中的服务器、PC 移动终端等相关硬件资源,进而构建相应逻辑结构,保障Hadoop 的顺利开展。Hadoop 技术中主要包括两个技术,分别为HDFS 和MapReduce,可以为配电网数据存储调度以及管理提供有效保障。针对配电网资源在资源层的应用下实现调整以及优化,有助于显著提升配电网资源的可利用价值。
若要构建配电网数据的大数据资源,则需要实现对当前配电自动化主站、用电信息采集系统主站以及GIS 主站等数据软硬件IT 资源的应用,基于当前配电自动化主站平台,实现大数据资源层主节点的构建。电力企业中存在有内外网,针对这一需求,需要构建相应的内网Master 节点以及企业外网Master 节点,但是也需要注意防范冗余热备节点[10];其他网省公司应用平台均可以作为从节点,例如配电网相关系统、其他资源系统等,可以借助于电力系统光纤实现以太网以及无线GPRS 网络的连接,从而构建成一个网络纽带,同时在用户和第二结构联系中完成智能配电网数据中心群的构建。
3.3 存储层
存储层能够实现配电网数据存储的标准和分布,主要包括有两部分,分别为数据预处理以及NoSQL。在数据预处理中,针对获取的不同结构化数据模型格式实施统一规划,将其转变为XLM 格式,在对数据格式统一后进一步提升了数据存储以及检索的便利性;NoSQL 能够有效实现数据的分布式存储[11-12]。
针对不同结构化配电网数据预处理,所采用的方法也存在差异。结构化数据结构相对比较简单,通常在预处理中,主要为数据转换以及数据统一;在非结构化数据预处理过程中,先要对数据实施详细归属,主要为4 个步骤,分别为数据清洗、调样、转换以及统一,以此有效实现结构化和非结构化数据属性的统一,且将其在Slave 节点中存储,实现数据预处理过程的规范化。针对已经预处理后的智能配电网数据,将其统一转化为XML 格式,为数据的处理分析提供便利[13]。在NoSQL 技术的应用下,则可以实现配电网数据的分布式存储,从而有效提升配电网数据的存储标准化,也能够确保实现分布式存储。
3.4 查询层
查询层在智能配电网数据存储处理中具有重要作用,能够实现数据的快速检索[14]。该层针对配电网中的海量数据实施选择、整理以及分析,之后将其在存储载体或管理系统中进行存储。如果需要应用数据,则可以通过关键字进行提取。查询层在运行过程中,采用的是分层分区同时工作的方式,在对数据实施查询时,可以在Master 中明确数据要求,之后针对所有数据化数据实施并行检索,以此获取数据查询中的详细信息;明确存储详细信息后,基于Slave 进一步明确数据所属类型;依照区位以及数据类型,可在Top-k 技术下映射出过去数据的实际地址方位,与第一步中获取的数据分区相结合,可以实现对原始数据的快速定位[15]。在查询层分层分区并行技术的应用下,有助于显著提升数据检索效率,从而进一步实现智能配电网的数据存储。
4 安全存储设计
密码技术以及加固技术是云安全的重点,针对智能配电网中的数据完整性以及保密性,可以在密码技术的应用下实施保障。当前的数据加密算法主要分为对称解密算法以及非对称加密算法两种。其中,对称加密算法具有加密速度快的优点,但是在相同密钥实施加/解密中,无法为安全性提供保障,也无法实现对密钥的有效管理;在非对称密钥体系的应用中,虽然不需和密钥协商,但必须构建相应的公钥管理方案,同时,这一方法在应用中的加密速度偏慢,效率不高,只是单纯对于少量数据加密具有适用性。在智能配电网中,数据源较多,存在海量数据,同时对于时间效率也具有较高要求。在加密算法应用中,不但需要具备较高的加密速度,而且需要具备较高的效率[16]。所以,在配电网数据安全管理中,可以采用对称加密算法实施加密处理,非对称加密算法则可以在元数据过密钥加密中应用。文中针对系统数据安全存储构建了相应的管理方案,如图3 所示。摘要信息是在数据消息签名中所获取的数据;密文是数据加密后所获取的数据;密钥信息是在针对数据加密中采用的密钥实施信息隐藏后获取的数据。
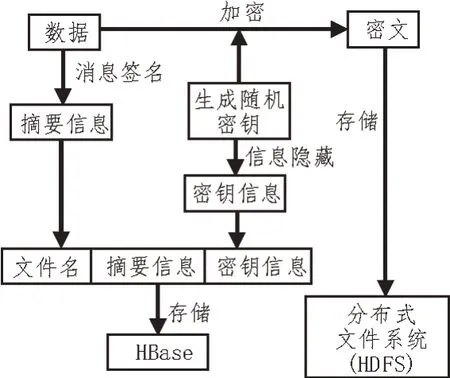
图3 数据存储方案设计
智能配电网中的存储数据为加密数据,若缺乏密钥信息,则其他人无法获取相应的信息。关于数据的完整性,可以针对所存储的数据预先生成摘要信息,基于此,在数据读取过程中,就可以实现对数据完整性的验证。另外,若要提升密钥信息操作便利性,针对密文和密钥信息存储可以实现解耦,以保障在密钥信息操作过程中,不会影响到密文。数据存储的步骤如下:第一步,生成摘要。先在摘要信息算法的应用下,针对存储数据生成数数字摘要。第二步,加密数据。在密钥的应用下建构函数生成随机密钥,在其应用下实现存储数据的加密处理,获取密文。第三步,随机密钥隐藏。针对第一步获取的随机密钥,需要信息隐藏。第四步,存储密文,在云中实现对密文的存储。第五步,保存相关信息。实现密文成功存储后,获取密钥信息和数字摘要信息,并共同存储在HBase 中。
5 实验分析
为实现对数据存储处理方案有效性的实施分析,构建了基于Hadoop 集群的原型系统。在Hadoop集群中共包括有3 台机器,节点配置也保持一致,各个机器的内存为2 GB,操作系统为Window10,硬盘空间为160 GB。在机器上安装Cygwin,以完成虚拟Linux 环境的建构。集群中的3 台机器全部完成hadoop-0.20.2、jdk-6u26-windows-i586 以及Cygwin安装。存储数据的加密算法选用的是AES(高级数据加密标准)算法,密钥长度为256 位。智能配电网海量数据存在大小差异较大以及时间要求高等特点,因此将系统衡量中的存储耗时作为一个标准,在加权平均方法的应用下对系统性能实施检测。
为实现对方案总体性能的了解,需要针对不同大小数据文件实施测试。针对智能配电网中存在数据大小差异大的问题下,此次检测选用的数据文件大小分别为1 MB、5 MB、10 MB、50 MB、200 MB、500 MB、800 MB。该次实验结果如表1 所示。

表1 不同大小数据文件的存储耗时
6 结论
文中通过研究得出了以下结论:
第一,基于Hadoop 的智能配电网数据存储处理,依照计算层、存储层以及查询层建构了三层体系结构,实现了对智能配电网信息数据存储以及管理的有效处理;
第二,针对智能配电网信息数据存储,基于Hadoop 构建原型系统,通过对其优点和性能的检测分析发现,这一方法具有有效性和可用性,可为智能配电网数据存储安全性提供有效保障。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年10期)2021-11-19
当代陕西(2019年14期)2019-08-26
信息安全与通信保密(2016年10期)2016-11-11
中学数学杂志(初中版)(2016年5期)2016-11-01
衡阳师范学院学报(2016年3期)2016-07-10
火控雷达技术(2016年1期)2016-02-06
深圳大学学报(理工版)(2015年5期)2015-02-28
应用技术学报(2014年1期)2014-02-28
