
GM(1, 1)模型对不同范围血糖的预测性能分析
2021-06-11 04:09:14卢相月王延年李全忠
实用临床医药杂志 2021年9期
卢相月, 王延年, 李全忠
(1. 郑州大学人民医院/河南省人民医院 内分泌科, 河南 郑州, 450003;2. 郑州大学 信息工程学院, 河南 郑州, 450001)
2型糖尿病(T2DM)是糖尿病的主要类型,临床发病率较高[1-2]。T2DM引起的慢性并发症不仅会对患者的预后及生活质量造成严重影响,而且会给社会带来巨大的经济负担[3]。为了更好地控制T2DM病情,众多学者[4-7]提出预测血糖。邓聚龙教授[8]提出了GM(1, 1)模型,该模型通过对处于白色信息(完全已知)和黑色信息(完全未知)之间的灰色信息(部分已知、部分未知)建立灰色微分方程来揭示其变化规律和未来趋势,在小样本、信息获取量少的数据分析中具有优势。本研究评价了GM(1, 1)模型在血糖预测中的性能,分析该模型对不同范围血糖数据的预测能力,现报告如下。
1 资料与方法
1.1 研究资料
收集2018年1—2月在河南省人民医院内分泌科住院的50例T2DM患者作为研究对象,其中男28例,女22例。纳入标准: 符合1999年世界卫生组织T2DM诊断标准者; 佩戴美国美敦力公司(Medtronic, Inc)生产的动态血糖监测系统(CGMS)者。排除标准: 佩戴CGMS未满72 h者或实测血糖序列有断点者; 过敏体质或有胶带过敏史者; 妊娠期糖尿病患者; 传染性疾病患者; 有严重糖尿病急慢性并发症者或病情危重者。
1.2 方法
1.2.1 数据采集: 所有受试者均佩戴美国美敦力公司(Medtronic, Inc)生产的CGMS, 该血糖仪每10 s接收1次信号,储存每5 min的血糖平均值,连续监测72 h, 可得到864个血糖值。
1.2.2 建立GM(1, 1)模型: GM(1, 1)模型是灰色预测模型的基本模型之一,表达式为一阶方程、单变量。该模型在Matlab 2018软件环境下编码和运行,得到未来5、15、30 min的血糖值。具体建模步骤[9]为:
实测血糖序列记为X(0), 对其先进行对数变换得到Y(0), 后一阶累加生成得到序列Y(1), 则

得到相应的白化微分方程,其中a为发展系数,b为灰色作用量,表示为

应用最小二乘法求出发展系数a, 灰色作用量b, 则

逆对数变换获得原始血糖数据的预测序列,则

采用新陈代谢算法得到血糖预测值,其原理是预测x(0)(20)时,剔除离x(0)(20)最远的数据x(0)(1), 添加离x(0)(20)最近的血糖数据x(0)(19), 即以x(0)(20)~x(0)(19)为训练集。预测x(0)(21)时,剔除离x(0)(21)最远的数据x(0)(2), 添加离x(0)(21)最近的血糖数据x(0)(20), 即以x(0)(3)~x(0)(20)为训练集。简而言之,始终保持18个血糖数据的训练集,不断更新操作。


1.2.4 划分不同血糖范围: 划分血糖的不同范围时,从模型的角度出发,将预测效率较高时的血糖范围(目标血糖范围)作为分组标准。应用随机数字表法抽取20例患者纳入对照组,其余30例患者纳入实验组。对照组患者的数据用于推导分组标准,实验组患者的数据用于统计验证。应用Excel 2016计算对照组所有患者预测时长为5、15、30 min时的MAE。筛选血糖范围时要求连续性,不能定义为单个或少量数据。考虑到GM(1, 1)模型是以18个连续原始血糖作为训练集进行预测,因此要求处于目标血糖范围内的血糖数据至少连续18个且绝对误差均小于该预测时长的MAE。记录符合要求的血糖范围,求合集得到最终的目标血糖范围(记为a~b)。
1.2.5 分析GM(1, 1)模型对不同范围血糖的预测能力: 因1例患者连续72 h的血糖往往波动比较大,很难确保均属于某一血糖范围,故将实验组30例患者的血糖视为1个实验单元。以对照组筛选得到的目标血糖范围将实测血糖数据分为A组(
1.3 统计学处理
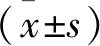
2 结 果
2.1 一般资料
本研究共纳入T2DM患者50例,患者佩戴CGMS的时间至少为72 h, 且血糖序列均完整连续。2组年龄、病程、性别构成、体质量指数(BMI)、糖化血红蛋白(HbA1c)比较,差异均无统计学意义(P>0.05)。见表1。

表1 2组T2DM患者一般资料比较
2.2 评估模型预测性能
以患者甲为例,不同预测时长的血糖预测结果见图1。所有患者实测值与预测值的误差分析见表2,预测误差随着预测时间的延长不断增大。

表2 不同预测时长实测值与预测值的误差分析

图1 患者甲不同预测时长的血糖预测结果
2.3 划分不同血糖范围
对照组预测时长为5、15、30min时的MAE分别为0.46、0.67、0.98。为明确绝对误差与实测血糖的变化趋势,以患者乙为例,绘制预测时长为5 min时的趋势图(见图2), 然后按照绝对误差降序排列绘图(见图3)。二者对比后发现绝对误差与实测血糖变化趋势基本一致,血糖较低且平稳时预测误差小,但在打乱血糖序列的时间变化后,发现规律消失。预测时长为15、30 min时仍有相同情况,进一步证实在筛选血糖范围时要求连续性。通过筛选得到患者乙预测时长为5 min时符合要求的血糖范围有6段,求合集得到3.4~7.0、7.8~8.8、9.3~10.4 mmol/L, 应用同样的方法得到预测时长为15、30 min时的目标血糖范围,见表3。对照组20例患者的结果表明,预测时长为5、15、30 min时,目标血糖范围分别为3.4~11.5、3.3~11.4、3.2~11.4 mmol/L, 见表4。

图2 患者乙预测时长为5 min时实测血糖与预测误差趋势图

图3 患者乙预测时长为5 min时降序排列后实测血糖与预测误差趋势图

表3 患者乙不同预测时长的目标血糖范围与最大绝对误差

表4 对照组患者不同预测时长的目标血糖范围与最大绝对误差
2.4 分析GM(1, 1)模型在不同血糖范围的预测能力
预测时长为5、15、30 min时分别得到25 380、25 320及25 230对实测血糖值与预测血糖值。不同预测时长的绝对误差近似正态分布(P>0.05), 相关性分析表明,不同预测时长时, B组的r值均最大(P<0.01), C组r值次之, A组r值最小,见表5。为进一步明确各组间MAE的差异,进行单因素方差分析,发现方差不齐(P<0.05), 故采用非参数检验进行分析。结果表明,每2组之间的绝对误差中位数比较,差异有统计学意义(P<0.01), 其中A组的预测误差最小, B组次之, C组最大,见表6。因此,预测时长为5、15、30 min时, GM(1, 1)模型分别对处于3.4~11.5、3.3~11.4、3.2~11.4 mmol/L血糖的预测拟合度最好且预测误差较小。

表5 不同预测时长、不同血糖范围的相关性分析及MAE结果

表6 不同预测时长、不同血糖范围的非参数检验
3 讨 论
为实现糖尿病患者智能化控制血糖以及更好地改善预后,人工胰腺(AP)概念被提出,现AP已被允许使用于临床[10-12]。多项研究表明AP或闭环胰岛素泵应用于不同类型糖尿病中均相对安全,其中一项研究[13]证实了AP治疗1型糖尿病(T1DM)患者的有效性和安全性。1例首次怀孕时使用胰岛素皮下治疗而第2次怀孕时使用AP治疗的糖尿病患者案例[14]发现, AP可使血糖管理更容易。另一项针对住院T2DM患者的研究[15]发现,闭环胰岛素泵输注组的目标范围血糖比例明显高于常规胰岛素皮下输注组。虽然AP目前仍存在伦理[16]、传感器性能[17]等方面问题,但其对糖尿病患者的益处可能更多。在构建闭环装置时,血糖的控制算法是不可缺少的一环[18],但也带来了重大挑战,尤其是在不规律的食物摄入、运动和各种自发活动下使用机器学习算法实现血糖预测。
在CGMS越来越成熟的基础上,学者们致力于探索不同模型在血糖预测中的应用效果。一种是基于生理学的模型[19](葡萄糖-胰岛素代谢模型和葡萄糖吸收模型),由于需要考虑详细的生理过程,建模复杂耗时,存在操作困难的问题。另一种是数据驱动模型[20],其基于血糖数据的数学定律建立模型,操作更容易,且预测精度良好。灰色预测模型通过模糊数学处理灰色信息逐渐发现系统中的未知信息,具有较少的训练集即可实现高精度的优势[8],且建模步骤简单易操作,这也是本研究选择该模型的原因。灰色预测模型应用于血糖预测中对糖尿病患者具有重要价值,当预测得知患者即将发生低血糖时,可提示患者补充糖分; 当预测得到的血糖值偏高时,可指导临床医生调整胰岛素用量以维持患者血糖稳定。
GM(1, 1)模型是灰色预测理论中应用最广泛的动态预测模型之一,其本质属于指数预测模型,因此其预测精度与数据序列的平滑程度以及被预测对象的跃迁变化规律密切相关。GM(1, 1)模型的核心是通过灰色微分拟合方法建立离散拟合方程,但该方程是近似微分方程,因此很难保证模型的固有误差必然是无穷小的。为了减少由建模方法缺陷而导致的固有误差,本研究对传统的GM(1, 1)模型进行了改进。首先是数据的预处理,即对实测血糖序列取对数,这样可以提高数据的平滑度。其次,利用最小二乘法求解GM(1, 1)模型的参数,从而提高拟合方程与待拟合方程之间的近似性。再者,为了延长预测时间,预测的序列被横向延长1步、3步和6步获得不同的预测时间。最终, GM(1, 1)模型通过揭示血糖中蕴含的数学规律,拟合下一时刻的血糖值。根据实验结果, GM(1, 1)模型应用于血糖预测时,预测时间越短,预测性能越好,预测时间延至30 min时,平均绝对误差达到1.01,仍可接受,这也证实了GM(1, 1)模型对血糖的短期预测是有效且准确的。
既往血糖预测模型的应用研究多局限于比较不同模型的精确度[6-9]、某一模型的性能评估[4-5, 10],并未对某一确定模型对不同范围血糖的预测能力行进一步讨论。另外团队前期工作发现, GM(1, 1)模型对处于3.9~10.0 mmol/L的血糖预测拟合度较好(r=0.85,P<0.01),但其是根据动态血糖监测仪设定的血糖水平直接进行分组分析,并未从模型角度去细化评价GM(1, 1)模型对哪一范围血糖具有最佳的预测效果。因此,本研究根据筛选得到的血糖范围进行分组,增强了血糖范围与模型的适配度,旨在为将模型更精确地应用于临床提供一定参考。
Pearson相关性分析及非参数检验结果表明, GM(1, 1)模型对不同范围血糖的预测能力是有差异的。以预测时长5 min的结果为例,从预测拟合度来看, GM(1, 1)模型对处于3.4~11.5 mmol/L范围血糖的预测效果最好,其次是>11.5 mmol/L的血糖,对<3.4 mmol/L的血糖预测效果最差。灰色预测模型对时间序列(如血糖序列)进行预测时,抛去模型的固有误差,数据的随机波动是影响预测的主要因素[11],即当被预测对象越平滑、随机性越弱,其预测效果越好。临床患者真实发生的低血糖事件较少,且低血糖持续时间短,同样高血糖的发生常伴随着机体自身调节或临床治疗措施所致的短期内血糖下降,这也造成高血糖的时间比例相对较少,而在高血糖与低血糖发生前后的数据均被纳入目标血糖组。因此,从数据的连续性、平滑度来说,处于目标血糖范围的数据的连续性最好且随机变化的值较少,高血糖组次之,低血糖组最差,这就合理解释了GM(1, 1)模型在目标血糖范围表现出的最佳预测拟合性。从预测误差来看,预测时长为5 min时, GM(1, 1)模型对<3.4 mmol/L的血糖预测误差最小,处于3.4~11.5 mmol/L范围的血糖次之, >11.5 mmol/L的血糖误差最大。MAE主要反映预测值与实际值之间的差距,取决于二者差值的绝对值大小。高血糖发生后往往有血糖的下降,由于GM(1, 1)模型是基于前18个训练集的数据进行预测的,包含高血糖极值的训练集得到的预测值往往会偏高,而所对应的真实值已存在一定程度下降,二者之间的绝对误差较大,这可能是高血糖组预测误差最大的主要原因。而低血糖组由于可变化范围窄、波动幅度小,预测值与实测值之间的差值最小。总之,本研究通过对不同预测时长的血糖范围求合集,得出GM(1, 1)模型对处于3.4~11.4 mmol/L的血糖数据预测更有效。
如果某预测模型对不同范围的血糖都表现出良好的预测性能,则其更具有临床适用性。在众多血糖预测模型中合理选择模型以实现精准预测血糖,对于延缓糖尿病并发症的发生与发展有着重要意义。GM(1, 1)模型可通过对少量、杂乱、不确定信息的数据建立灰色微分方程,描述事物进一步的发展规律。本研究结果显示, GM(1, 1)模型能有效预测血糖,其预测特点是对3.4~11.4 mmol/L范围的血糖数据预测效果最好,这不仅提示了该模型进行血糖预测时的建议适用范围,也提示在对发生高血糖较多的波动性血糖序列进行预测时,将该模型与其他模型组合预测可能会使预测值更准确。然而,GM(1, 1)模型仍然存在对偏高血糖、极低血糖预测效果不佳的局限,这也是临床研究人员未来面临的新挑战。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
保健医苑(2022年6期)2022-07-08 01:26:34
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
家庭科学·新健康(2022年3期)2022-05-10 00:32:13
哈尔滨轴承(2020年2期)2020-11-06 09:22:26
今日中国·法文版(2020年7期)2020-07-04 02:53:48
中国特种设备安全(2019年1期)2019-03-13 01:06:26
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
妈妈宝宝(2017年3期)2017-02-21 01:22:30
