
基于多尺度自注意力增强的多方对话角色识别方法
2021-06-10 07:18:44张禹尧蒋玉茹张仰森
中文信息学报 2021年5期
张禹尧,蒋玉茹,张仰森
(北京信息科技大学 智能信息处理研究所,北京 100101)
0 引言
角色识别(character identification)任务的目标是在多人参与的对话中,将每个人物提及(mention)映射到具体的人物实体,这里的人物提及可以是任何表示人物的名词,如“他”“阿姨”等。由于多方对话数据中的上下文往往由多个角色轮流交替发言组成,其中包含着大量的对话场景内以及对话场景外的人物提及,因此想要正确理解上下文的内容,必须明确这些人物提及的具体指代。换言之,角色识别任务是多方对话理解中关键性的步骤,也是后续高级自然语言处理任务(机器问答、文本摘要、信息抽取等)能应用在多方对话数据上的基础[1]。
Chen等[2]对美剧《老友记》(Friends)的剧本进行了收集、整理、标注,构建了第一个关于多方对话理解的数据集,并将其以任务的形式发布在了SemEval2018 Task4[3]。在该评测任务中,来自庞培法布拉大学的Aina等[4]为了提升非高频角色的识别效果,构建了基于角色实体库的角色识别模型(AMORE-UPF),取得了评测的冠军。然而,就最终的评测指标来看,该模型取得的效果似乎仍不尽如人意。原因一定程度上来自于模型的编码器部分,该部分仅由单层的BiLSTM构成。一方面,数据中存在着大量的长对话,尽管LSTM相较于基础的RNN结构能保留更长的记忆信息,但是对于过长的文本,同样会有信息的丢失;另一方面,对话之间是存在着信息关联的,只使用BiLSTM无法捕获这种信息之间的关联。本文针对这两方面的问题,提出了一种基于多尺度自注意力增强的多方对话角色识别方法(multi-scale self-attention character identification,MSA-CI)。首先,通过尺度较大的全局注意力,对场景内的全部对话信息进行处理,保留全局的对话信息;其次,通过尺度较小的局部注意力,对局部范围内的对话进行计算,捕获近距离信息之间的关联关系,这也符合人类对话交流的特点;最后,将不同尺度得到的信息进行融合,达到对原始编码结果增强的效果。实验结果证明了本文所提出的方法的有效性。在主要角色的识别效果上,F1值达到了89.03%,相较于Aina等人的AMORE-UPF模型提升了9.67%;在全部角色的识别效果上,F1值提升了18.94%,达到59.99%。
1 相关工作
1.1 角色识别
角色识别任务最早在文献[2]中进行了明确定义,标注整理了数据集,并给出了基于共指消解和簇映射策略的解决方法。文献[1]对语料库中《老友记》部分的若干注释错误进行了扩充和修正,并提出了一种新的方法用于解决该问题。首先,采用聚合卷积神经网络学习提及和提及对(mention-pair)的嵌入,然后将学到的嵌入信息应用在实体链接模型中,实现最终的角色识别。文献[3]对数据《老友记》部分按照CoNLL2012共享任务格式进行了格式化,将其作为SemEval2018 Task4发布。在该评测中,文献[4]提出的基于角色实体库的角色识别模型将该任务视为一项多分类任务,整体思路是通过BiLSTM编码获得提及在对话中的表示,并与角色实体库中的实体表示计算相似度,完成角色识别,角色实体库中的表示同样通过学习得到;文献[5]则将该任务视为一项序列标注任务,使用的结构为编码器解码器结构,编码器的输入为对话文本,解码器则按照提及出现的顺序对提及进行角色分类。上述方法均建立在纯文本的数据之上,文献[6]则认为在某些情况下人类也很难通过单纯的文本信息识别出提及具体指代的角色,因此在模型中引入了视频场景信息来进一步提高角色识别的性能。
1.2 注意力机制
近年来,随着深度学习的研究深入,基于注意力机制的神经网络成为神经网络研究中的重点。注意力机制最早由Bahdanau等人[7]提出并将其应用在神经机器翻译中;随后,Luong等人[8]对注意力机制在循环神经网络中的应用方式进行了扩展,提出了全局注意力(global attention)和局部注意力(local attention)两种不同形式的注意力机制;Google团队将注意力机制进一步进行了抽象描述[9],提出了缩放点积注意力(scaled dot-product attention),通过将缩放点积注意力重复多次得到多头注意力机制(multi-head attention),并在完全基于注意力机制的基础上提出了Transformer模型。除机器翻译任务外,注意力机制在其他自然语言处理任务中同样有广泛的应用,如共指消解[10-11]、文本分类[12]、情感分析[13]、关系抽取[14]、机器阅读理解[15-17]等。
2 模型结构
2.1 基线模型
基线模型为SemEval2018 Task4的最佳系统。模型整体架构如图1所示,底部为模型的输入部分,最上方为模型的输出部分。简单来说,模型通过BiLSTM对对话中的信息进行编码,并对提及进行解析,最后通过与角色实体库中的角色实体表示进行相似度计算,得到最终的预测结果,角色实体库中的向量表示会随模型训练逐渐进行更新。

图1 AMORE-UPF模型结构
模型的输入为一个场景中全部对话信息,包括说话者以及说话的内容。首先,将输入中的第i个词ti和所对应的发言者集合Si进行one-hot表示,然后通过角色实体嵌入矩阵Ws和词嵌入矩阵Wt分别进行嵌入编码,并将二者编码后的结果进行拼接,得到最终的向量xi。如果发言者集合Si包含多个发言者,则将多个发言者编码后的结果进行求和。如式(1)所示,其中Ws和Wt为可学习的参数。
(1)
得到输入向量xi后,将其通过一个激活函数f(=tanh),并对输出的结果使用BiLSTM进行编码,得到包含上下文信息的编码结果hi,如式(2)~式(4)所示。
接下来,对被标记为提及的词ti的BiLSTM编码结果hi进行映射,将其映射到一个向量ei∈R1×k,如式(5)所示,其中Wo和b为可学习的参数。
ei=Wohi+b
(5)
在基线模型中,学习到的每个实体表示都被存储在角色实体库E∈RN×k中,角色实体库中共包含N个角色实体,每个角色实体通过一个k维向量表示。需要注意的是,这里的角色实体库与角色实体嵌入矩阵二者并不等价,权重参数相互独立,但是二者包含的角色实体的个数是一致的,并且均随着训练进行更新。利用上一步得到的向量ei,对角色实体库中角色实体进行余弦相似度计算,并对输出的结果使用softmax函数进行概率化,得到最终的输出oi=[0,1]1×N,如式(6)所示。
oi=softmax(cosine(E,ei))
(6)

2.2 MSA-CI
本文所提出的基于多尺度自注意力增强的方法主要是对基线模型中的编码部分进行扩展,完整模型结构如图2所示。

图2 MSA-CI模型结构
模型输入及基本的BiLSTM编码器这两部分与基线模型中一致,设此处输入xi经过BiLSTM编码后,得到包含着上下文信息的编码结果hi,整个场景的全部对话信息编码结果为H。
接下来,引入大尺度的全局自注意力机制,这里的注意力机制采用点积注意力,是Transformer模型中缩放点积注意力的简化版本,如式(7)、式(8)所示。将式中的Q,K,V均替换为H,即可得到全局自注意力的计算结果HGA。
将BiLSTM的编码结果H与全局自注意力计算的结果HGA相加,相加后的结果经过激活函数f(=relu)后再次使用BiLSTM进行编码,如式(9)所示,此时整个场景的全部对话信息编码结果为H′。
H′=BiLSTM(f(H+HGA))
(9)
下面,引入小尺度的局部自注意力机制,与全局自注意力机制相同,这里同样采用点乘注意力,但是需要通过一个mask矩阵Mwin来限制注意力的范围,这个限制的范围可以简称为注意力的窗口大小w,为一项可以调整的超参数。这里需要定义一项操作mask_fill(x,mask,ε),其作用是根据mask的值对x进行填充,填充值为ε。首先将点乘后的结果根据mask矩阵Mwin进行mask_fill,而后再进行后续操作,即可实现局部自注意力的计算,如式(10)、式(11)所示。同样的,只需要将式中的Q,K,V替换为H′,便可以得到局部自注意力的计算结果HLA。
此时,已经得到了四部分的编码计算结果,分别是最初BiLSTM的编码结果H,全局自注意力的计算结果HGA,再次BiLSTM编码的结果H′和局部自注意力的计算结果HLA。这里,选择使用H,H′和HLA三部分进行加权求和,其权重值分别为α、β、γ,将加权求和后结果经过层归一化,得到最终的编码结果HMSA,如式(12)所示。其中,α、β、γ三个值为可调节的超参数。
(12)
模型中映射的部分,直接对HMSA中的编码结果进行映射即可。后续部分,按照基线模型中的方式进行处理。此外,在MSA-CI中角色实体库与角色实体嵌入矩阵共享参数。
3 实验设置
3.1 数据集
本文所使用的数据集来自SemEval2018 Task4,该评测任务提供了基于《老友记》剧本标注的多方对话角色识别数据。数据集中的数据按照类似CONLL2012评测任务进行了格式化,如图3所示。可以看到,在样例数据中,包含着三个提及,分别是“He”“guy”和“I”,对应的角色实体分别是284和248,其中提及“He”和“guy”指代的是同一角色实体。

图3 SemEval2018 Task4样例数据
数据中共包含448个场景的对话,不同的场景中参与对话的人可以是不同的。此外,对话中共包含401个角色实体,15 709个提及。训练集和测试集的数据分布如表1所示。这里需要注意的是,在训练集和测试集中包含的角色实体是有差异的,测试集中存在训练集中未出现的角色实体29个。
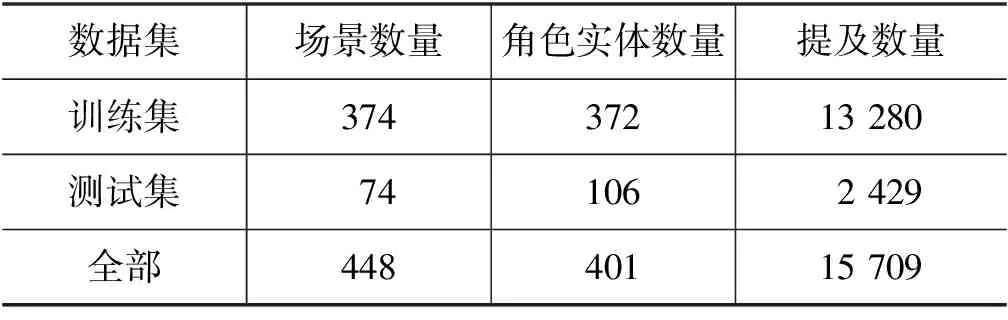
表1 训练集和测试集数据分布
根据词性标注的结果,所有的提及可以大致被划分为五类,第一人称代词、第二人称代词、第三人称代词、专有名词和一般名词,其中第一、二、三人称代词可以统称为代词,测试中各种类型的提及的分布如表2所示。其中代词所占的比例最大,高达82.99%,而其中又以第一人称为主,占比达到44.38%。
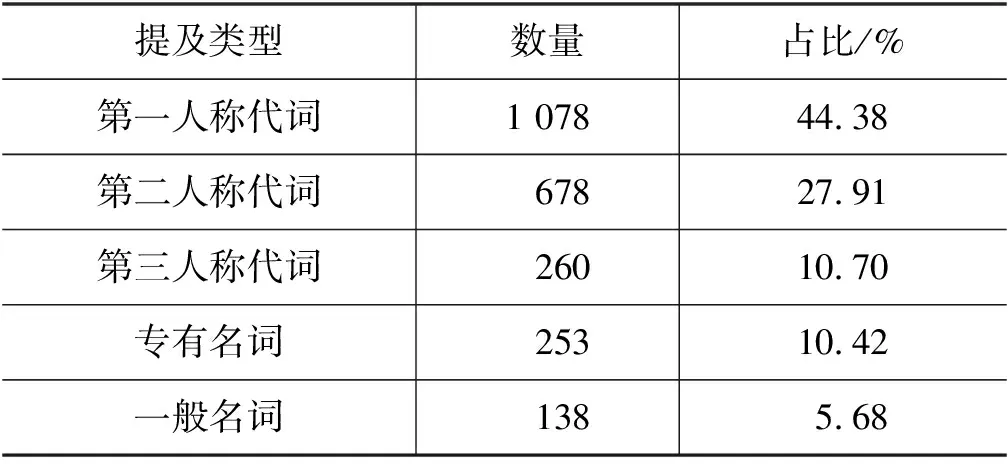
表2 测试集中不同类型提及分布
此外,为了更好地对系统的性能进行评估,SemEval2018 Task4中按照角色不同对数据进行了进一步划分,分为“主要角色+其他”和“全部角色”。其中,“主要角色+其他”将全部角色划分为两大类7小类,分别为“Chandler Bing”“Joey Tribbiani”“Monica Geller”“Phoebe Buffay”“Rachel Green”“Ross Geller”和“Others”;而“全部角色”中同样包含着“其他”类,这里的“其他”类指的是在测试集中出现,但并未出现在训练集中的角色,因此,在“全部角色”这种划分中,共包含78类。由于对数据进行了“主要角色+其他”和“全部角色”的划分,后文实验结果中将包含这两部分各自的实验结果。
3.2 评价指标
SemEval2018 Task4评价指标主要包含准确率(accuracy,Acc)和宏平均F1值(Macro-averageF1)。Acc指标计算的是整体的准确率,计算如式(13)所示。
(13)
Macro-averageF1为每个角色实体的F1值的平均值,其中C为总的角色数,F1i表示第i个角色的F1分数,计算如式(14)~式(17)所示。
3.3 参数设置
本文按照文献[4]的设置,对训练集进行五折交叉验证,并使用五个模型的融合模型对测试集进行预测。使用的深度学习框架为Pytorch[18],词嵌入层初始化选择使用GloVe[19]官方提供的预训练好的词向量(1)nlp.stanford.edu/data/glove.840B.zip。训练过程中,批量大小为32,场景内对话最大长度为757,学习率0.001,优化器为Adam[20],总轮数设置为50,如果损失超过5轮没有下降则训练停止。此外,由于文本长度较长,为了防止训练时出现梯度爆炸的问题,这里加入了梯度裁剪策略,最大梯度范数设置为5.0。在模型部分,角色实体嵌入的维度为134,BiLSTM的隐藏层维度为400,局部注意力机制的窗口大小w设置为50,填充值ε的值为1e-9,α、β、γ的数值分别为0.6,0.25和0.15。在嵌入编码层与归一化后的Dropout层丢弃率大小统一设置为0.05。此外,BiLSTM网络中的参数进行正交初始化。
3.4 实验结果
3.4.1 基于角色类别的实验结果
表3中给出了本文所提出的模型在测试集上的评测结果。可以看到,本文所提出的MSA-CI模型在测试集上的表现明显优于其他模型。在“主要角色+其他”的识别效果中,Acc值达到了87.98%,宏平均F1达到89.03%,相较于之前最好的结果,分别提升了2.88%和3.03%,而相较于本文使用的基线,则分别提升了10.75%和9.67%。此外,本文所提出的模型并未随着主要角色的识别效果提升而降低对非主要角色的识别性能。在“全部角色”的识别中,与基线模型相比,本文所提出的模型同样展示出了巨大的性能提升,Acc值从基线模型的74.72%提升至83.29%,提升了8.57%;宏平均F1值从41.05%提升至59.99%,提升了18.94%。

表3 SemEval2018 Task4 评测结果 (单位: %)
表4中给出了“主要角色+其他”部分更为详尽的评测结果。相较于基线模型,性能提升最低的角色“Phoebe”提升了6.51%,性能提升最高的“Others”甚至提升了21.97%。主要角色部分的性能提升,表明本文所提出的MSA-CI模型可以较为准确地学习到高频角色实体的表示。

表4 “主要角色+其他”测试集F1值细节 (单位: %)
3.4.2 基于提及类型的实验结果
除了SemEval2018 Task4的官方基于角色类别的实验结果外,本文还按照文献[4]中的设置,给出了测试集中不同类型提及的评测结果。
图4和图5中对比了本文所提出模型与文献[4]的基线模型在全部角色实体上的Acc值和宏平均F1值。可以看到,本文所提出的模型在不同类型的提及上性能均有不同程度的提升。其中,代词方面的Acc和宏平均F1相较于基线模型有较大的提升,Acc提升了9.38%,F1值提升了17.43%。代词提及中,以第二人称代词和第三人称代词提升较为突出,Acc分别提升了17.4%和24.23%,宏平均F1值的提升比Acc的提升更为明显,第二人称代词从22.83%提升至58.29%,第三人称代词从12.09%提升至了32.48%;而第一人称代词在Acc上提升较小,但是在宏平均F1值上提升了7.13%。除代词外,其余类型提及也都有不同程度的提升,且F1值的提升均略高于Acc的提升。以上结果一方面证明了本文方法的有效性,另一方面说明本文方法在出现次数较低的非主要角色上有比基线模型更好的识别效果。
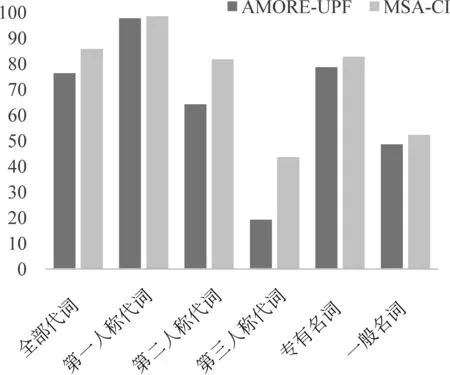
图4 测试集中不同类型提及Acc值对比
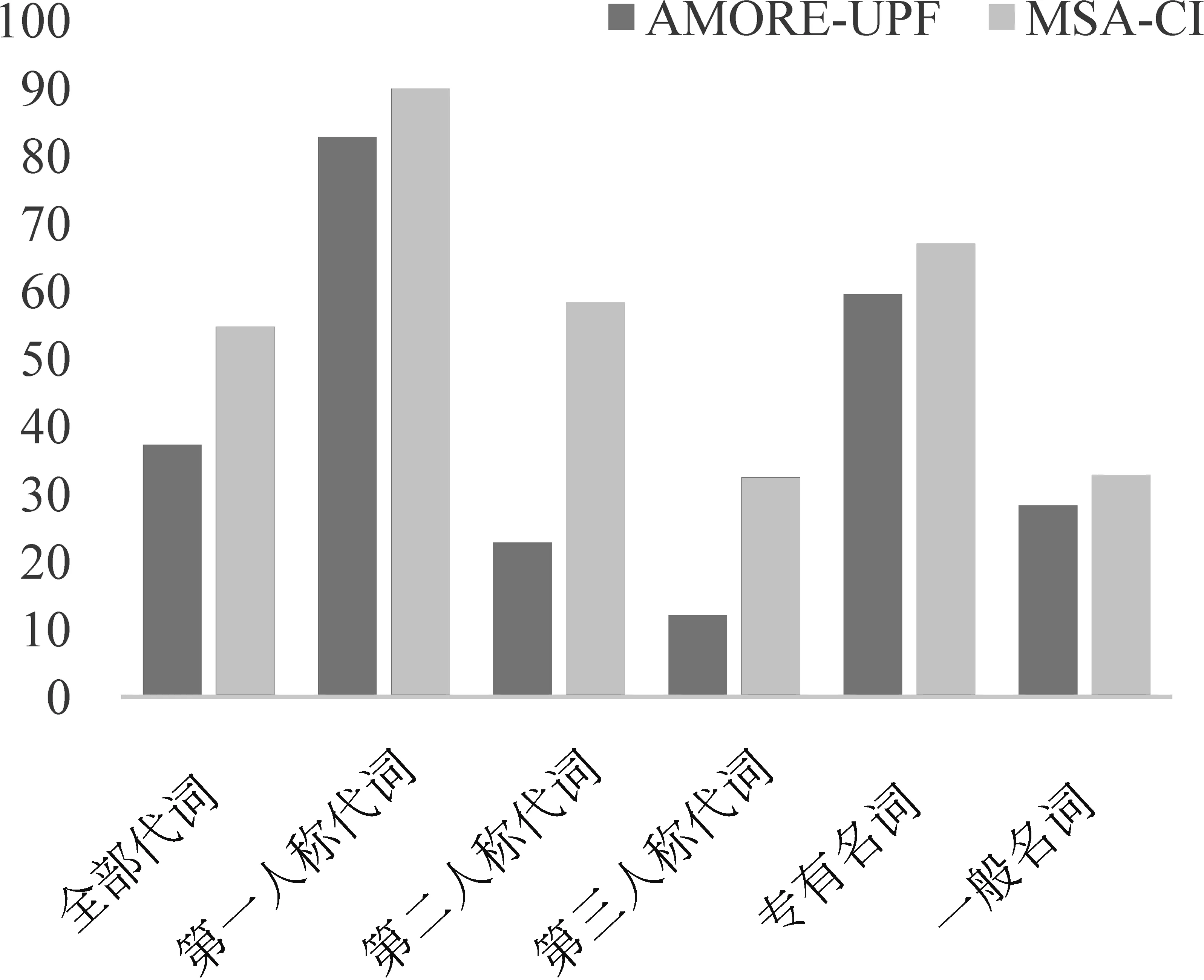
图5 测试集中不同类型提及F1值对比
4 模型分析
4.1 消融研究
表5中给出了MSA-CI模型完整的消融实验的结果,这里需要注意的是,表5中最后的结果与文献[4]中的结果并不一致,本文复现的基线模型计算结果略高于原始模型,其原因可能源于深度学习版本的更迭以及软硬件环境。
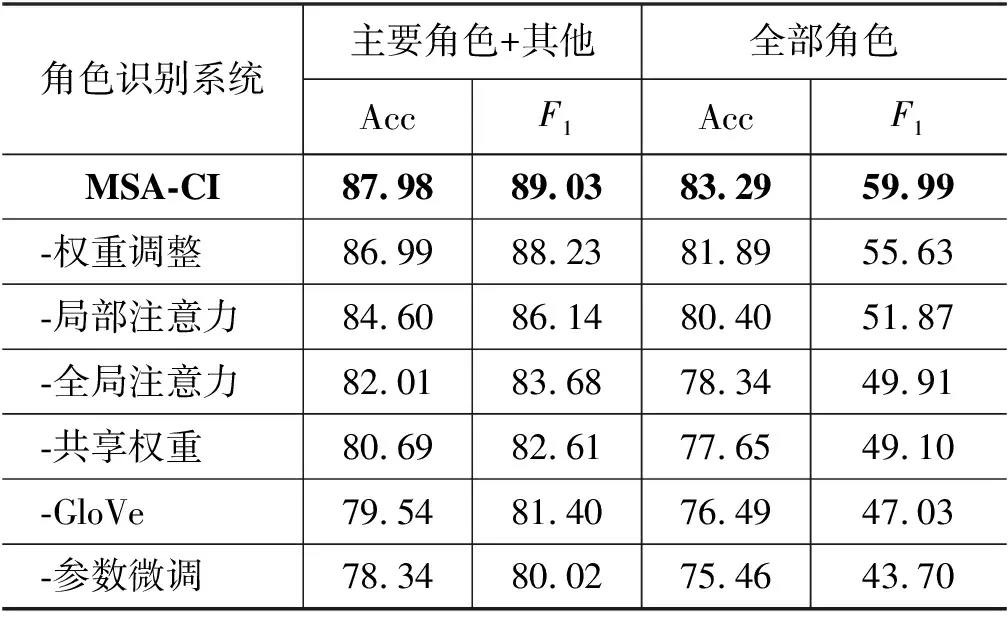
表5 MSA-CI模型消融实验结果 (单位: %)
以全部角色的宏平均F1值为标准,可以看到对参数的微调可以使基线模型的性能从43.70%提升至47.03%,GloVe预训练词向量和共享角色实体权重分别又带来了2.07%和0.81%的性能提升,多尺度自注意力中的全局注意力机制使模型性能突破了50%,达到了51.87%,随后的局部注意力将其提升至55.63%,通过赋予不同注意力不同的权重,模型的性能达到59.99%。总的来说,多尺度自注意力机制对模型的性能提升达到了10.08%。
4.2 显著性检验
为保证结果的有效性,本文采用近似随机测试(approximate randomization test)[21]检验对全部角色上的性能(Acc、F1)进行显著性检验,迭代次数为10 000,检验结果如表6所示。
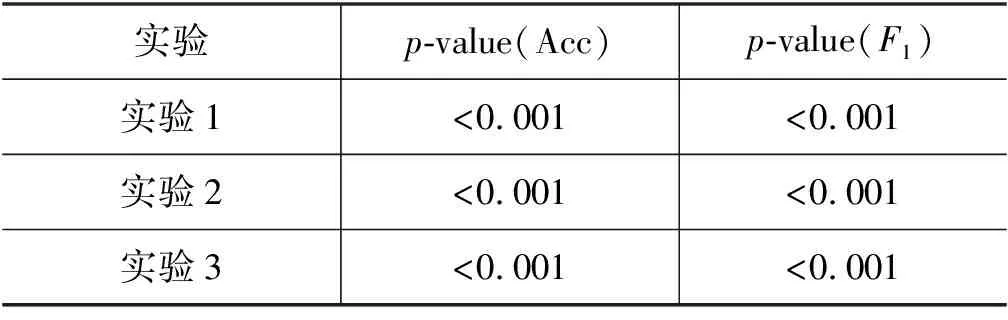
表6 全部角色近似随机检验结果
表6中,实验1为MSA-CI对比基线模型,实验2为未使用多尺度自注意力机制的模型对比基线模型,实验3为MSA-CI对比未使用多尺度自注意力机制的模型。首先,通过实验1的对比可以看到完整模型相较于基线模型在测试数据上的表现有极其显著的统计学差异,这表明本文所提出的完整模型相较基线模型有更好的性能不是出于偶然。接下来,通过实验2,可以看到未使用多尺度自注意力的模型相较于基线模型在测试数据上同样有极其显著的统计学差异。进一步地,实验3则表明使用和未使用多尺度自注意力模型的系统,在测试数据上同样表现出极其显著的统计学差异,说明了本文提出的多尺度自注意力机制模型的有效性。
4.3 多尺度自注意力
进一步对多尺度自注意力进行研究,可以看到单纯的全局注意力对模型的提升似乎并不明显,反而是加入了局部注意力后模型的性能有了较大提升,那么这种较大提升是单纯来自于局部注意力本身还是这种整体的设计便无法确定。为了验证是否为本文所提出的模型的整体结构带来的提升,这里增加了一组对比实验,对比实验包含两部分,一部分用于探究仅使用单尺度注意力的模型的性能,另一部分对多尺度自注意力中两种注意力的计算顺序进行了探究,实验结果如表7所示。其中,L为局部注意力,G为全局注意力,L+G表示先进行局部注意力再进行全局注意力,G+L则是先进行全局注意力再进行局部注意力。
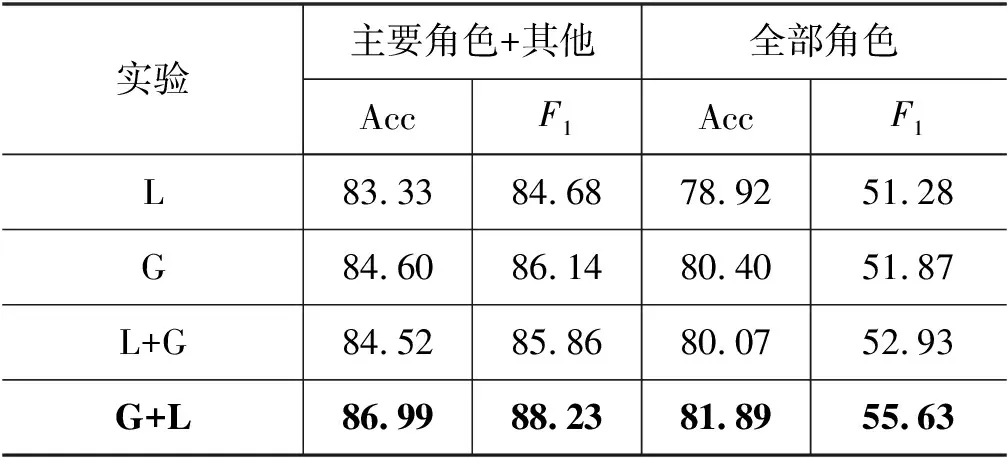
表7 不同注意力机制实验结果对比 (单位: %)
从前两个实验的结果中可以看到,在只使用一种注意力机制的情况下,全局注意力与局部注意力之间并无明显差异;通过后两个实验结果可以看到,不同注意力之间的计算顺序,对实验结果有巨大影响,以全部角色为例,顺序(L+G)相较于顺序(G+L)的宏平均F1相差2.7%。
为了更细致地分析全局注意力和局部注意力在模型中的作用,本文统计了各种模型对不同类型提及的性能表现,结果如表8所示。其中,L、G与表7表示内容一致,△表示G+L的效果相对于L与G中值的变化,“-”代表低于L和G中最低值,“*”代表在L与G的值中间,“+”代表大于L和G中的最高值。

表8 不同类型注意力机制测试集全部角色F1值 (单位: %)
可以看到,在仅使用一种尺度注意力的模型中,局部注意力在第二人称代词上的表现更佳,在一般名词上的表现虽有优势但不明显,其余项则均不如全局注意力的结果。当使用多尺度的注意力机制时,可以看到在第三人称代词、专有名词和一般名词上性能有显著的提升,超过了单独使用时的最优值,说明两种尺度的注意力机制在这三种提及类型中有一定的互补的效果;在第二人称代词上的性能则没有提升,但比全局注意力要高,略低于局部注意力,说明局部注意力在这里发挥了更多的作用;而第一人称代词的性能不仅没有提高,反而些许下降,出现这种情况的原因,本文分析是由于注意力机制的多次使用,使得模型更多关注了范围更大的上下文,减少了对临近上下文信息的关注。
最后,本文对局部注意力机制中的窗口大小进行了不同的尝试,以10为差值对窗口分别进行缩小和放大,实验结果如表9所示。可以看到,当取窗口大小为50的时候,可以达到最优效果,当窗口被放大或缩小的时候,都会有不同程度的性能下降。

表9 不同窗口大小实验结果对比 (单位: %)

续表
5 结论
面向多方对话中的角色识别任务,本文在现有模型的基础上进行了改进,提出了一种基于多尺度自注意力增强的方法,该方法能够利用不同尺度的自注意力机制,获得不同方面的信息,从而达到对最终的编码信息增强的效果。在SemEval2018 Task4数据集上的实验结果证明本文提出方法的有效性。
尽管本文提出的方法已经取得了一定的效果,但是还有提升空间。首先,本文并未加入语言模型,借助语言模型,模型的性能大概率还能进行提升;其次,在局部注意力的使用上,生硬地划定窗口大小这个方法还不够完美,可以细化改进;最后,由于数据集来自剧本,与真实场景下的多方对话可能还存在着一些差异。因此,构建整理真实场景下的多方对话数据集,也将是我们下一步工作的重点。
猜你喜欢
初中生学习指导·提升版(2023年9期)2023-10-08 13:24:35
高技术通讯(2021年3期)2021-06-09 06:57:46
疯狂英语·初中天地(2021年11期)2021-02-16 00:39:14
疯狂英语·初中天地(2021年12期)2021-02-12 01:13:38
科学(2020年5期)2020-11-26 08:19:14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
高中生·天天向上(2018年1期)2018-04-14 09:24:38
舰船电子对抗(2016年5期)2016-12-13 08:41:14
太空探索(2016年5期)2016-07-12 15:17:55
时代英语·高三(2014年5期)2014-08-26 17:01:17
