
基于不同内容层面的特定领域研究主题差异分析研究
2021-06-10 03:32:38章成志
农业图书情报学刊 2021年5期
赵 磊,章成志
(南京理工大学经济管理学院信息管理系,南京 210094)
1 引言
随着信息技术的进步和开放获取运动的日益蓬勃发展,以期刊、报告、会议为代表的全文本数据获取更加容易,数据量呈爆发式增长。与此同时,自然语言处理、机器学习等计算机技术不断发展,使得对学术论文的挖掘分析深入到全文之中。与基于机器可读目录等元数据进行的传统文献计量研究相比,基于全文本文献的计量研究在引用行为、实体抽取、关键词自动抽取、新兴研究话题和新兴技术预测等方面为文献计量学的研究提供了更加广阔的空间[1]。
尽管全文本文献的获取更加容易,但是与标题和摘要相比,文献的全文内容仍然较难获取,例如在Web of Science(简称WOS)数据库中,只提供了文献的标题和摘要内容,没有提供全文内容,这给基于全文本文献的主题分析带来了困难。因此,分析标题和摘要、全文内容中的主题差异,对使用标题和摘要中的主题内容来揭示全文的研究内容具有重要意义。此外,引文内容是作者对他人研究成果的总结和概括,分析引文内容与施引文献内容的主题差异,可以发现引文内容对其施引文献内容的作用,进而分析作者的引用动机[2]。然而,目前鲜有研究从不同内容层面:标题和摘要、引文内容、全文内容,对其主题差异进行分析,因此该研究是有必要的。
随着新冠肺炎(简称COVID-19)疫情的爆发并在全球范围内蔓延,众多领域的科研人员积极投入到了新冠病毒的研究中,发表了大量的学术成果,为病毒结构分析、病例诊断、疫苗研发、公共卫生管理等工作做出极大贡献。目前,已有一些研究人员从大量文献中挖掘信息,为新冠研究提供参考,例如为分析当前科学研究的转变和在全球流行病预防和控制中的应用,YANG 等使用文献计量聚类算法从国际合作、跨学科合作和研究热点的角度描述和分析当前的COVID-19 研究态势[3]。
为了探究在文献的标题和摘要、引文内容、全文内容中的研究主题是否存在差异,并分析国内学者在应对新冠肺炎疫情的过程中所关注的主要研究内容。本研究将基于新冠领域的中文期刊论文,从文献的标题和摘要、引文内容、全文内容中识别研究主题,并进行对比研究,分析三者之间的主题差异,总结新冠研究的主要内容,为后续的新冠防治和研究提供参考。
2 相关工作概述
本研究主要使用主题识别方法来提取新冠论文中的研究主题,并对文献的标题和摘要、引文内容、全文内容中的主题差异进行分析。因此,首先介绍了情报分析和数据挖掘领域中主题识别的相关方法,并提出了本文所采用的主题识别方法;然后列举了基于不同内容层面的主题分析研究,提出了本文研究的不同之处。
2.1 主题识别研究概述
目前,主题识别方法主要包括两类,一类是基于特征词的主题识别方法,另一类是基于概率模型的主题识别方法[4]。基于特征词的主题识别方法,主要包括词频分析法、共词分析法等。其中,词频分析方法主要对文本中的特征词进行分析,能够较为直接地反映文本的主要内容,例如储节旺等[5]运用词频分析法,对文献关键词进行词频统计,分析了2002—2011 年10年来知识管理领域的研究热点、应用领域和研究方法。共词分析法是在词频统计的基础上,更加关注特征词的共现关系,例如陈红琳等[6]以国内文本情感分析的学术论文为对象,利用共词分析法,研究关键词之间的联系,探讨了近10 年来在文本情感分析的研究热点及现状。此外,这两种方法还可以进行融合,共同用于主题识别研究,如高劲松等[7]构建了一个词频分析和共词分析融合的关键词频度演化模型,以揭示学科热点及其类团结构的变化情况。
在基于概率模型的主题识别方法中,具有代表性的模型方法是LDA 模型[8]。该模型用一个服从Dirichlet 分布的K 维隐含随机变量表示文档的主题概率分布,模拟文档的生成过程,可用于从大规模文档数据中抽取潜在主题,已经被广泛应用于各类文本的主题识别任务中,例如BOON-ITT[9]为了分析Twitter 用户在新冠疫情期间关注的话题,使用LDA 主题模型和自然语言处理方法分析了107 990 条与新冠相关的Twitter 推文。
虽然LDA 模型逐渐成为主题识别领域的主要方法之一,但由于LDA 采用词袋模型,仅考虑一个词汇是否在一篇文档中出现,而不考虑其出现的顺序[10],使得不同语义的词汇可能会出现在同一个主题下,再加上缺乏研究领域的相关知识,很难对每一个主题进行总结。因此,本文在进行主题识别时,采用基于特征词的主题识别方法,即首先从文档内容中抽取特征词,并使用Word2Vec 模型来训练词向量,在相邻词之间建立语义联系;然后使用AP 聚类算法对特征词进行聚类,以避免相同词反复出现在同一簇中,同时降低不同语义的特征词出现在同一簇中的可能性;最后采用人工判读的方式,识别文档内容中的主题。
2.2 基于不同内容层面的主题分析研究
主题分析能够反映某领域的研究水平和总体状况,揭示该领域的研究现状、热点及发展趋势[11]。目前,可用于文献主题分析的数据源有文献标题、摘要、作者给出的关键词、全文,例如刘志辉[12]为了分析国外信息历史的研究现状,从文献的标题中抽取关键词,然后对高频关键词进行分析,得到图书馆史、信息学史、信息科学、信息社会是信息历史关注的重要领域。李万辉等[13]从文献的摘要中抽取高频关键词,得到1990—2009 年20 年内城市信息化持续研究的热点词有:数字城市、信息产业、电子政务、信息技术、无线城市、信息资源建设、电子商务、企业信息化、社会信息化、信息共享、信息服务等词。张涛等[14]以CSSCI 数据库中1998—2019 年1 361 篇舆情文献为数据集,使用作者给出的关键词,分析了中国舆情文献研究的主题及演化趋势。TATSAWAN 等[15]为了细粒度地掌握图书馆学的知识趋势,运用了共词分析、文本摘要、主题建模等文本挖掘技术,对6 种图书馆学的全文期刊文章进行了细致的分析。
在所使用的数据源中,文献的标题、摘要、全文需要使用自然语言处理等技术,从文本中抽取出特征词或者关键词,然后在特征词或者关键词的基础上进行主题识别研究,比基于作者给出的关键词的主题分析复杂,因而使用这些数据源进行主题分析的研究相对较少。此外,从全文内容中抽取的引文内容也是研究被引文献主题内容的重要数据源。
目前,大多数研究均使用单一数据源对文献的研究主题进行分析,鲜有学者关注到文献的标题和摘要、引文内容、全文内容中的研究主题是否存在差异。因此,本文以新冠领域的中文期刊文献为数据集,探究在文献的标题和摘要、引文内容、全文内容中的研究主题是否存在差异,分析标题和摘要中的主题内容是否可以揭示全文的研究内容,以及引文内容对其施引文献内容的作用,并总结国内学者在新冠流行期间所做的主要研究工作,为后续的新冠防治和研究提供参考。
3 研究思路与关键技术描述
3.1 研究思路
本研究以CNKI 数据库(https://www.cnki.net)中的新冠论文为研究对象,分析标题和摘要、引文内容、全文内容中的主题差异,其研究过程主要分为3 部分:第一部分是新冠数据的采集;第二部分是数据的预处理;第三部分是数据分析和主题对比研究,如图1 所示。
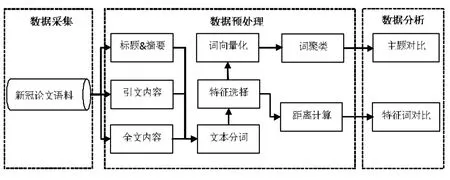
图1 研究框架图Fig.1 Research framework
在数据采集的过程中,为方便文献内容的解析,本文采集了HTML 文档等内容,并同时采集了论文中作者标注的关键词以及新冠病毒疫情防控相关词汇(https://cidian.cnki.net/cidian/XG_Link),以用于扩展分词器的词典,让分词器具有识别新冠术语的能力。在预处理阶段,需要解析HTML 文档,即从文档内容中抽取出论文摘要、全文以及参考文献内容,并根据参考文献在全文中的引用标志找到对应的引文内容句。在数据分析和主题对比研究中,分别从标题和摘要、引文内容、全文内容中抽取特征词,根据词频度量特征词的分布差异,并使用聚类算法进行特征词聚类,分析研究主题并进行对比研究。
为了分析在文献的标题和摘要、引文内容、全文内容中的研究主题差异,需要确保研究的数据集之间彼此互不相交。因此,在全文内容中,需要去掉标题、摘要和引文内容,而对剩余的部分进行分析。在本文中,将去掉标题、摘要和引文内容的全文依然称为全文,但实际上这部分内容已不再包含标题、摘要和引文内容,需要引起读者注意。
3.2 关键技术描述
3.2.1 数据采集及预处理
(1)数据来源。COVID-19 是一场全人类正在遭受的重大突发公共卫生事件,为了能够寻找到合适的应对办法,国内学者积极开展新冠研究,发表了大量的学术论文。CNKI 为其开辟了一个出版专栏(https://cajn.cnki.net/xgbt),以方便研究者分享和交流最新的研究成果。本文从该专栏中采集了2020 年1 月份至6 月份的新冠文献,去除重复、信息不全以及全文内容是英文的文献,共获得HTML 全文数据2 510 条,采集的字段内容如表1 所示。

表1 采集的论文字段Table 1 The fields of collected papers
图2 是论文发文量随OA 首发时间变化的分布图,该时间字段在OA 专栏中可以获取,时间范围为2020年1 月29 日至2020 年6 月30 日。由图2 可知,自COVID-19 爆发以来,有关此项研究的学术论文产出不断增加,尤其是前3 个月,发文总数急剧增加。这表明COVID-19 从爆发之初就得到了国内学者的普遍关注。随着研究力度不断加大,有关COVID-19 的认识进一步深化,对战胜病毒、控制疫情起着重要作用。
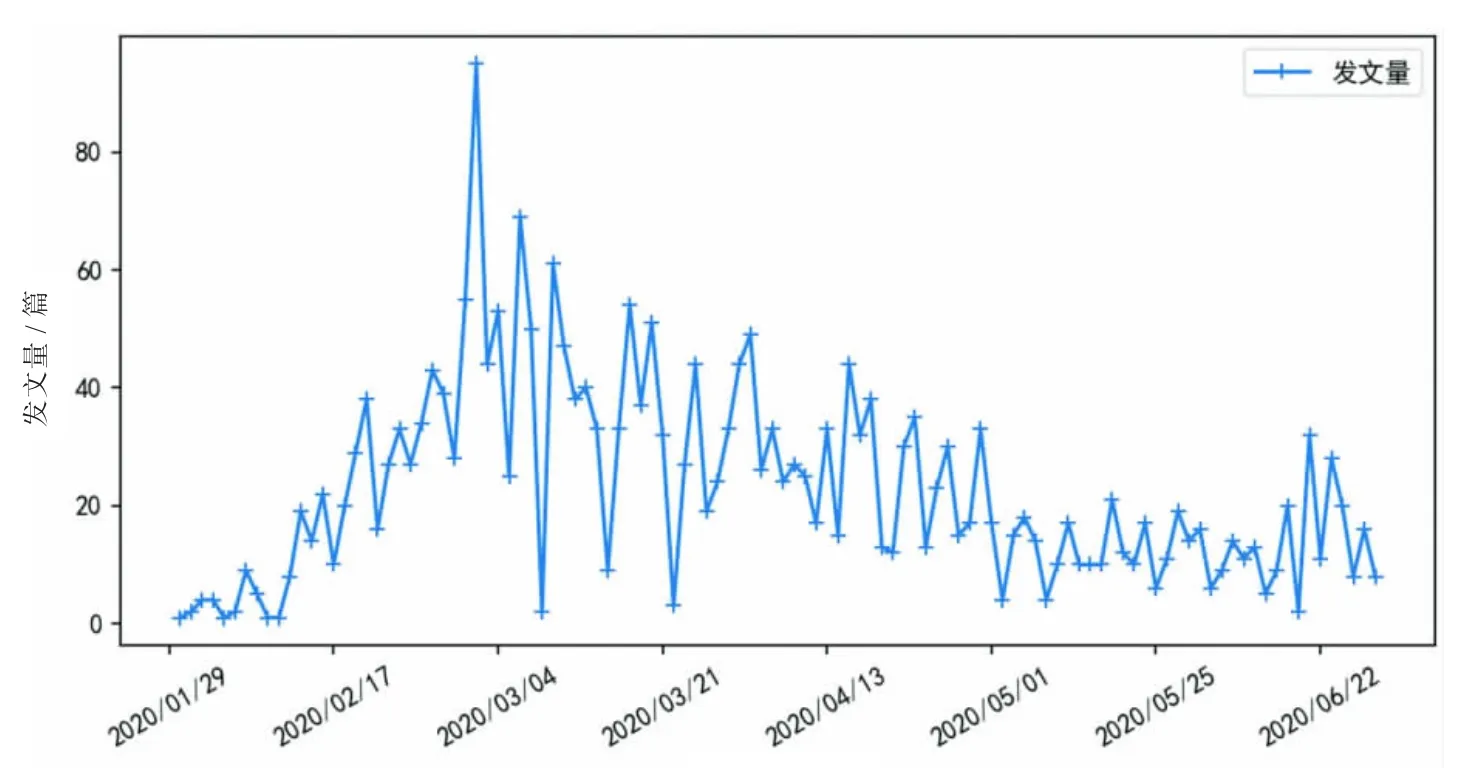
图2 新冠论文时间分布曲线Fig.2 Time distribution curve of COVID-19 papers
(2)数据预处理。由于采集到的全文数据是HTML格式,不能直接用于数据分析,需要从HTML 文档中抽取出文献摘要、全文和参考文献内容,然后在全文内容的基础上,抽取出引文内容句,完成文本分词等工作。①引文内容句抽取。引文内容是作者引用他人研究成果的文字表述,是对他人研究成果的吸收和借鉴,在一定程度上能够反映他人成果的主要内容,需要使用引用标记进行标注。本文根据参考文献对应的引用标记从全文内容中抽取引文内容句,即通过引用标记的位置向前和向后寻找句子的结束标志,通常为句号,将引文内容句从全文中抽取出来。通常,一篇文献会引用多篇文献,也就会抽取出多个引文内容句,将这些引文内容句组合在一起,就构成了该篇文献对应的引文内容数据。②基于规则的参考文献解析。每条参考文献的内容都按照一定的格式规范进行组织和书写,可以使用基于规则的方式进行解析。在本文采集的学术论文集合中,参考文献的引用格式主要采用的是“GB/T 7714-2015”,但也有少数参考文献存在格式错误。因此,本文在进行解析之前,剔除了格式错误的参考文献,并使用正则表达式进行各字段内容的提取,如引用文献的标题、作者、来源、年份。通过解析,共获得了35 773 条引用文献信息,文献的类型主要是期刊、专著和会议文献。③文本分词。文本分词是进行文本分析的基础,其效果的好坏会直接影响到分析结果。本文使用的分词工具是Jieba 分词器(https://pypi.org/project/jieba/),由于该分词器中的词典不包含新冠研究领域的专业术语,在进行本文分词时,会造成专业术语无法切分准确。因此,需要扩展Jieba的分词词典。
通常,学术论文中作者标注的关键词是由相关术语组成。为了提升分词效果,采集了新冠论文中的13 865个关键词作为Jieba 分词器的拓展词典,使分词器可以识别新冠研究领域中的术语。对分词后的文本去停用词,其中停用词主要包括数字、数学符号和无意义的虚词等。
3.2.2 文档特征词抽取
TF-IDF 算法可以计算一个词对于一篇文档或者一篇文档对于一个文档集合的重要性。其基本原理是:词项的重要性与其在文档中出现的频次正相关,与其在文档集中出现的频次负相关,其中TF 代表词项频率,IDF 代表逆文档频率指数,通过公式(1)得到词项Wi在单篇文档中的重要程度[16]。
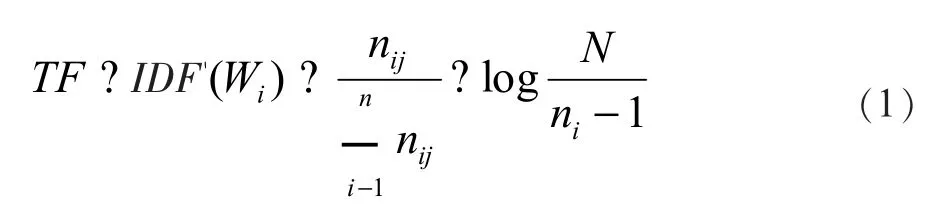
其中,nij表示词Wi在文档j 中出现的次数,N 为文档集中总的文档数,ni表示包含词Wi的文档数总和。一般来说,单字词和双字词包含的语义过于广泛,例如“治疗”“疫情”等,而由3 个及以上的字符构成的词所包含的语义更具体,如“核酸检测”“中医药”等。因此,本文在对一篇文档中的词计算TF-IDF权重后,将字符长度低于3 的词过滤,以确保抽取到的特征词语义清晰。
此外,一篇文档中包含大量特征词,但绝大多数是一些高频低权词,对于文档的表征意义不大。因此,本文根据实验的需求,选取了TF-IDF 权重排名前50的词作为文档的特征词。
3.2.3 特征词分布差异度量与聚类
(1)基于JS 散度的特征词分布差异度量。Kullback-Leibler散度(简称KL散度)于1951年由KU1LBACK 等提出,主要用于统计变量间的独立性,即从概率分布的角度去衡量两个变量间的距离[17],计算公式如公式(2)所示。由于该方法在度量两个变量的分布时不具有对称性,LIN 在此基础上提出了一种变体——JS 散度,解决了KL 散度非对称的问题[18],计算公式如公式(3)所示。
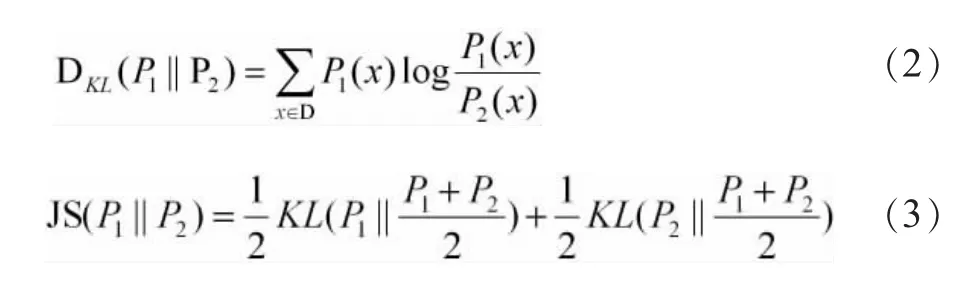
本文将使用JS 散度来度量在文献的标题和摘要、引文内容、全文内容中抽取的特征词的分布差异,即根据标题和摘要、引文内容、全文内容,对抽取的特征词进行分组,然后从每部分中选取相同数量的高频特征词,使用词频进行归一化,计算JS 距离值。JS 值取值范围为[0,1],若值趋近于1,则两个变量独立性更强,即两者之间的差异更大,反之,差异更小。
(2)构造词向量。文本数据是一种符号集合,无法直接通过计算机进行处理。词嵌入可以将文本数据中的词映射为一个向量,即将词语表示为一个浓密的、低维度的实值向量,向量中的每一个维度可视为对应特定的语义[19],从而使得计算机可以对文本数据进行计算和分析。
Word2Vec 是谷歌开发的一款词嵌入开源工具,其基础是神经语言模型[20]。Word2Vec 可以将词从一个非常稀疏的向量空间映射到一个低维的空间,并保留词向量之间的位置关系。Word2Vec 中有两种模型,分别是CBOW 和Skip-gram。其中,CBOW 模型训练时需要输入的是上下文中词t 相关词的词向量,对这些输入词向量进行累加处理后输出词t 的词向量。Skip-gram与CBOW 的输入与输出相反,输入词t 的词向量,通过恒等投影输出词t 上下文对应词的词向量。本文借助Gensim 库,使用论文全文数据对Word2Vec 的CBOW模型进行训练,从而获得相应词的词向量。
(3)基于AP 的特征词聚类。近邻传播算法(英文名为Affinity Propagation,简称AP算法)是最早由FREY 等在2007 年提出,该聚类算法的主要特点是无需事先指定聚类数目并且聚类结果稳定[21]。近邻传播算法的基本原理是通过吸引度和归属度矩阵的更新来调整聚类中心的数量和位置,直到聚类中心不再变动或者迭代次数超过预先设定的最大迭代次数,其中两个矩阵的更新是近邻传播算法的关键步骤。对于具有n个点的数据集,其吸引度和归属度可以表示为n×n 矩阵。本文借助Sklearn 库(https://scikit-learn.org/stable),使用余弦相似度[22]计算n 个节点的相似度矩阵,以初始化AP 聚类模型,从而获得相应的聚类结果。
为了量化聚类结果的性能,本文使用了轮廓系数[23]作为评估指标。该系数取值范围为[-1,1],取值越接近1 则说明聚类性能越好,相反,取值越接近-1 则说明聚类性能越差。
4 结果分析
首先,对参考文献的解析结果进行分析,介绍了高被引文献主要的研究内容。其次,使用JS 散度度量了文献的标题和摘要、引文内容、全文内容中的特征词分布差异。最后,对标题和摘要、引文内容、全文内容中抽取的特征词进行聚类,识别新冠的研究主题,并从主题内容上对比分析具体的差异。
4.1 高被引文献内容分析
按照作者和文献标题,对期刊、专著和会议类型的35 773 条引用文献信息进行统计,得到19 912 篇引用文献在数据集中的引用次数列表。表2 列举了引用次数排名前10 的文献,这些文献的引用次数占总文献引用次数的6.78%,且文献的发表时间较早。其中,排名第一的文献报告了41 名新冠感染患者的症状、体征、实验室检查结果、影像学检查结果、潜在疾病和并发症,并得出结论,COVID-19 会引起严重急性呼吸窘迫综合征,导致ICU 病例和死亡率的增加[24];排名第二的文献同样介绍了99 例新冠感染患者的流行病学和临床特征[25];排名第三的文献报告了一种新的CoV(2019-nCoV),并实现了对该病毒的分离以及初步描述了其特定细胞病变效应和形态[26]。从这些文献的研究内容上看,早期的新冠研究集中于新冠患者的临床症状和治疗研究,以及对新冠病毒的认识和溯源研究上,这些研究对后期新冠的诊断、治疗和防治起着重要作用。
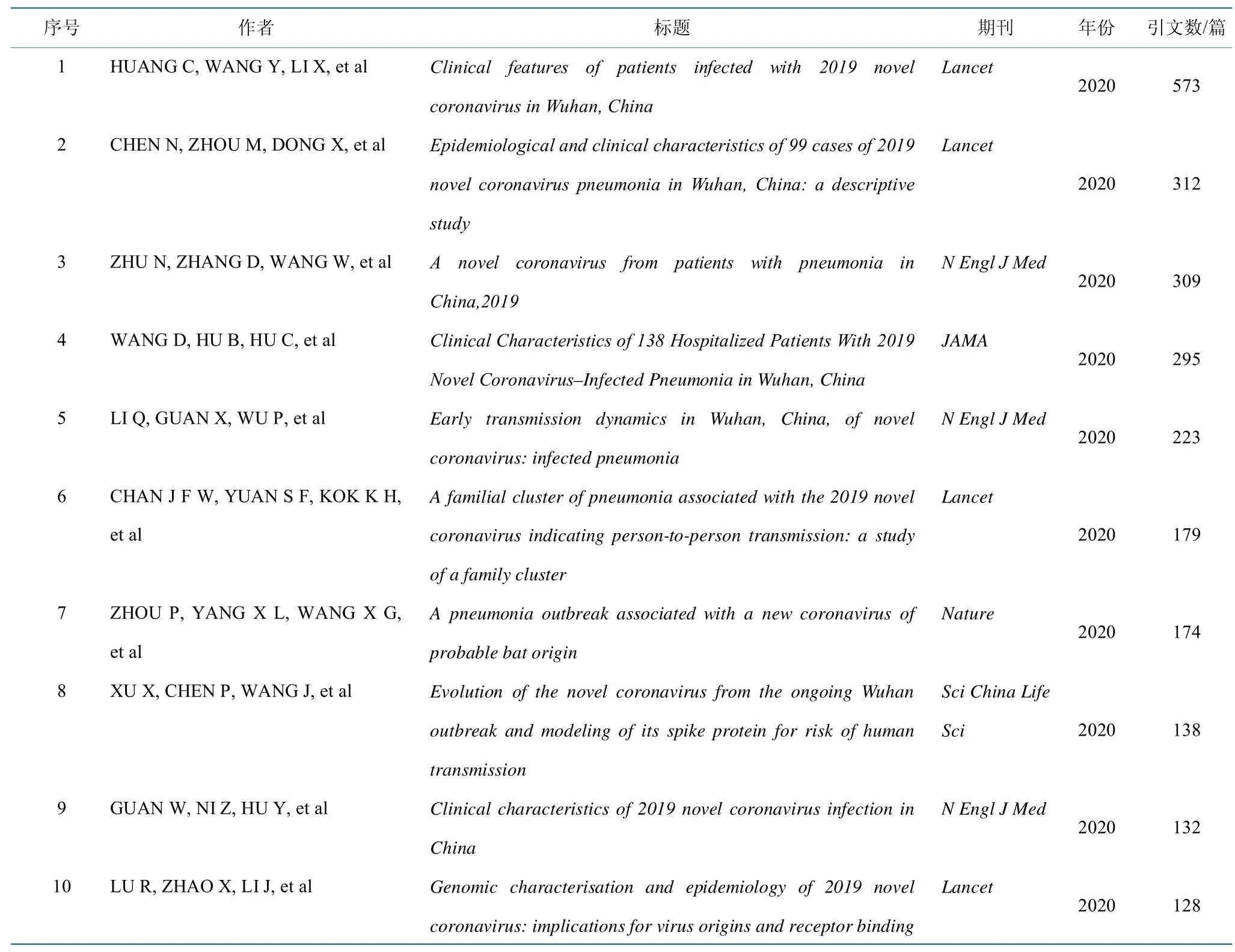
表2 高被引文献Top10Table 2 Top 10 of highly cited works
4.2 文献不同内容层面的特征词分布差异分析
为了考察从标题和摘要、引文内容、全文内容中抽取的特征词分布是否存在差异,本文分别从这3 个部分中抽取高频特征词,使用JS 散度计算三者之间的相关性,结果如图3 所示。从图中可以看到,随着提取的高频特征词增多,三者之间的JS 距离值越小,意味着三者之间的内容相似性越强。但是,三者之间还是存在一定差异,即标题和摘要与引文内容的相似性要比标题和摘要与全文内容、全文内容与引文内容的相似性低,而标题和摘要与全文内容的相似性最高,这也反映出标题和摘要是对全文内容的总结和提炼,具有较高的内容相关性。引文内容是作者引用他人成果的总结和概括,与其施引文献全文内容相关,同时也要高于引文内容与施引文献标题和摘要的相关性。
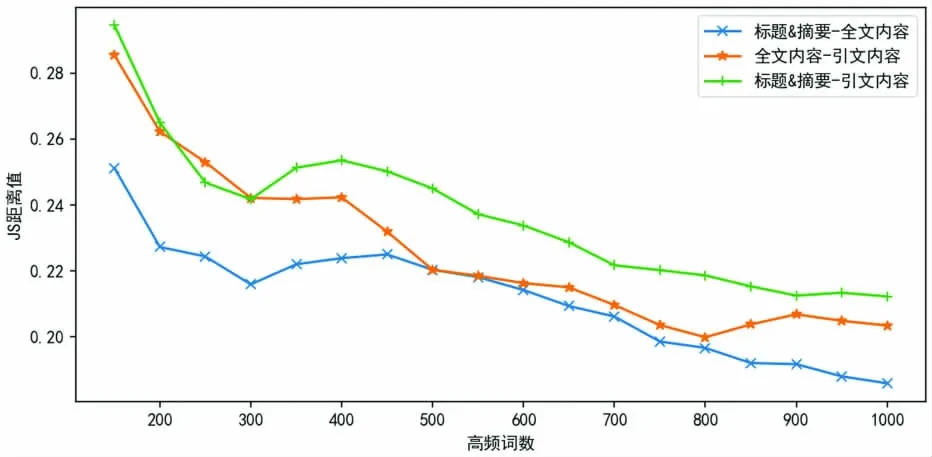
图3 不同文献部分中的高频特征词分布差异Fig.3 Distribution differences of high frequency feature words in different parts of a research paper
在此分析基础上,本文扩展了研究实验,分析了不同引用频次的引用文献在引用内容的相似性上是否存在差异,即根据引用文献被引用的次数划分不同层次,使用JS 散度计算文献不同层次之间的内容相似度。本文将引用次数达到10 次及以上的文献归类为高频引用文献,该类文献占总引用文献的1.66%,引用次数介于1~10 之间的文献归类为中频引用文献,占总引用文献的17.53%,而引用次数为1 的文献归类为低频引用文献,占总引用文献80.81%,分别计算高频、中频和低频引用文献之间的JS 值,如图4 所示。由图4 可知,不同引用频次的引用文献在引文内容的相似性上存在差异,即中频和低频引用文献在引文内容的相似程度上较高,而高频和低频引用文献在引文内容的相似程度上较低。
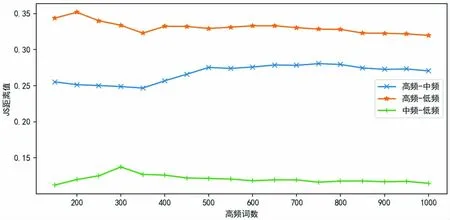
图4 不同引用频次文献的高频特征词分布差异Fig.4 Distribution differences of high frequency feature words in works with different citation frequencies
4.3 特征词聚类结果分析
从标题和摘要、引文内容、全文内容中抽取特征词直接进行聚类分析,会造成聚类数过多,如图5 所示。因此,本文分别从这3 部分内容中,将抽取的特征词进行汇总,并按照词频大小,选取高频特征词进行聚类分析。为了尽可能涵盖较多主题内容,并确保聚类数在合适范围内,本文经过多次实验,选取前100个高频词进行聚类分析最为合适。
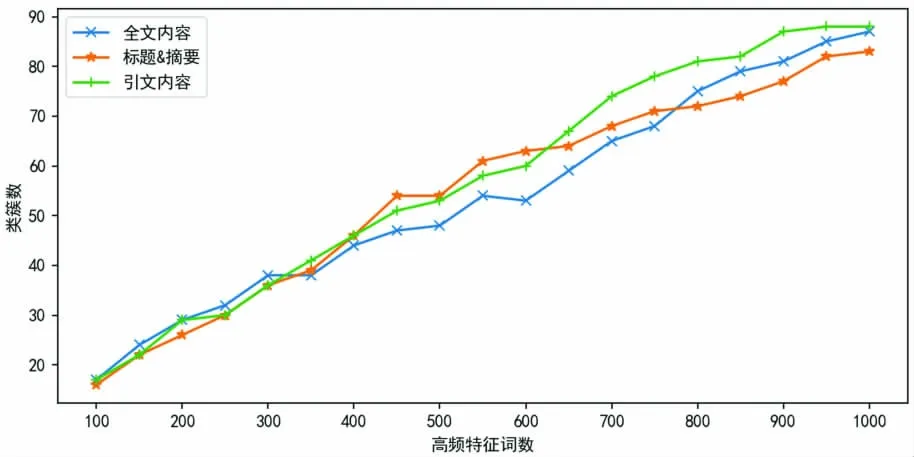
图5 聚类数与特征词数的分布变化趋势图Fig.5 The distribution trend of the number of clusters and the number of feature words
在完成聚类分析后,根据特征词的语义,采用人工判读的方式,对每一个聚类簇进行主题总结,并使用轮廓系数来量化聚类效果,以分析在标题和摘要、引文内容、全文内容中的主题差异。
4.3.1 标题和摘要中主题识别结果
从2 510 篇文献的标题和摘要中,使用TF-IDF 算法抽取50 个特征词,共获得特征词8 224 个。然后根据词频选取前100 个高频特征词进行AP 聚类,聚类结果的轮廓系数为0.278,聚类效果较好,主题结果如图6 所示。
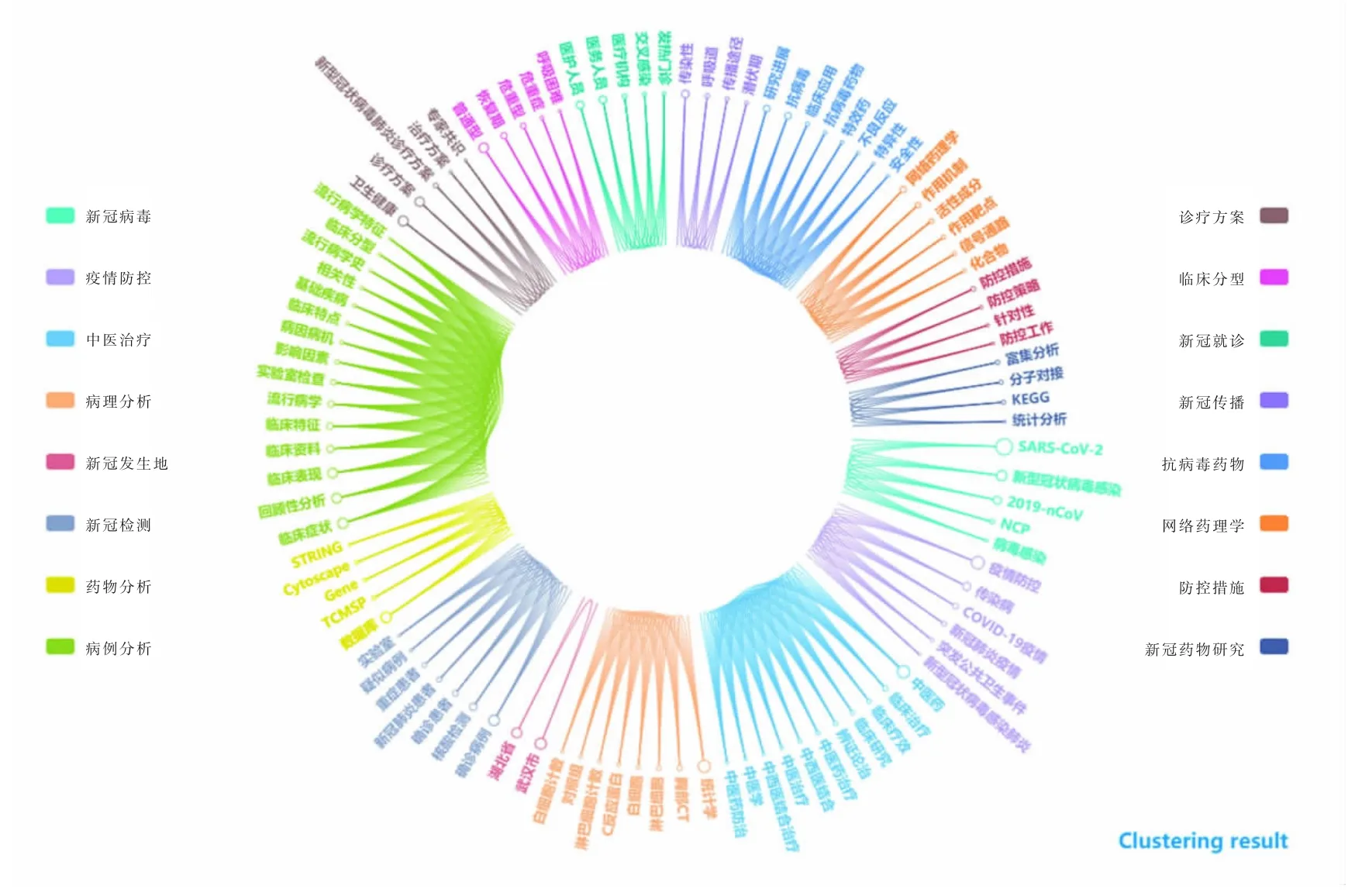
图6 标题&摘要中主题聚类结果Fig.6 The results of topic clustering in the title&abstract
从特征词聚类结果可以看出,标题和摘要中的研究主题主要涉及新冠病毒、疫情防控、中医治疗、病理分析、新冠发生地、新冠检测、药物分析、病例分析、诊疗方案、临床分型、新冠就诊、新冠传播、抗病毒药物、网络药理学、防控措施、新冠药物研究16个研究主题。
4.3.2 引文内容中主题识别结果
本文从2 510 篇文献的全文内容中,根据引用标记抽取引文内容句,并去除重复内容,共抽取出引文内容句39 287 句。然后使用TF-IDF 算法从每篇文献对应的引文内容中抽取50 个特征词,共获得特征词19 733 个。最后根据词频选取前100 个高频特征词进行AP 聚类,聚类结果的轮廓系数为0.321,聚类效果较好,主题结果如图7 所示。
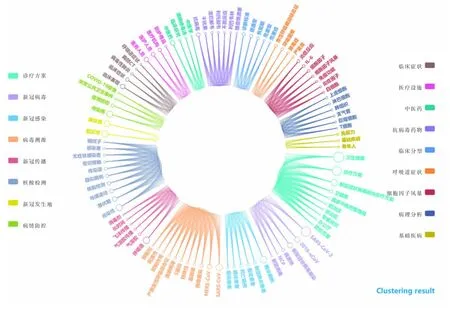
图7 引文内容中主题聚类结果Fig.7 The results of topic clustering in citation content
从特征词聚类结果可以看出,引文内容中的研究主题主要涉及诊疗方案、新冠病毒、新冠感染、病毒溯源、新冠传播、核酸检测、新冠发生地、疫情防控、临床症状、医疗设施、中医药、抗病毒药物、临床分型、呼吸道症状、细胞因子风暴、病理分析、基础疾病17 个研究主题。
4.3.3 全文内容中主题识别结果
从2 510 篇文献的全文内容中,使用TF-IDF 算法抽取50 个特征词,共获得特征词34 624 个。然后根据词频选取前100 个高频特征词进行AP 聚类,聚类结果的轮廓系数为0.33,聚类效果较好,主题结果如图8所示。
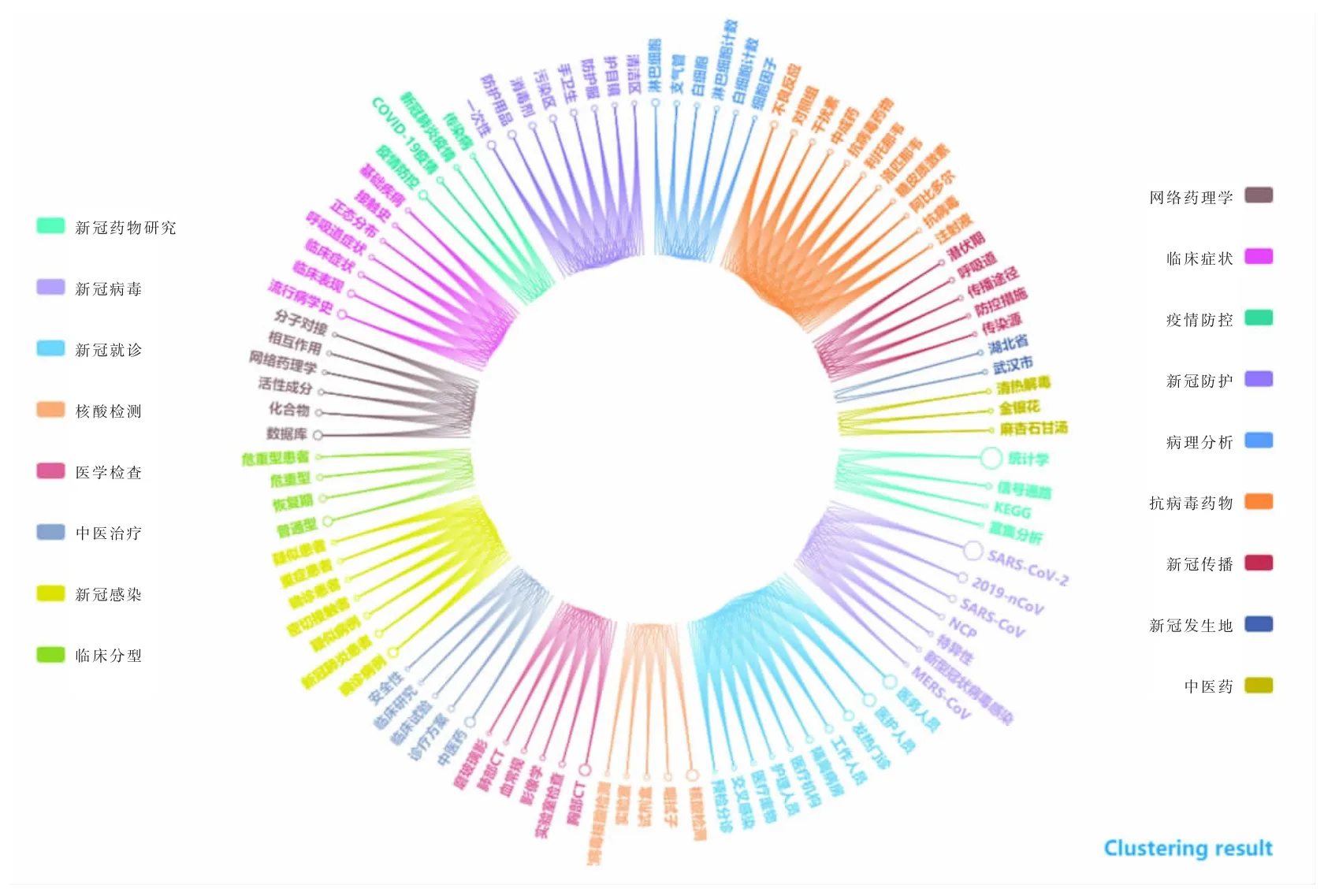
图8 全文内容中主题聚类结果Fig.8 The results of topic clustering in the full text content
从特征词聚类结果可以看出,全文内容中的研究主题主要涉及新冠药物研究、新冠病毒、新冠就诊、核酸检测、医学检查、中医治疗、新冠感染、临床分型、网络药理学、临床症状、疫情防控、新冠防护、病理分析、抗病毒药物、新冠传播、新冠发生地、中医药17 个研究主题。
4.4 研究主题对比分析
将从标题和摘要、引文内容、全文内容中识别出的研究主题进行汇总,共得到27 个主题,如表3 所示。从主题内容上看,这些主题涉及新冠的诊疗方案、病理分析、病毒溯源、传播与防护、检测与治疗、抗病毒药物研究、基础疾病各方面,并且重视中医药和中医治疗方法在新冠防治中的运用。此外,基于网络药理学、分子对接、富集分析、数据挖掘等方法进行新冠治疗药物的研究与开发,在新冠的研究中也占有重要地位。
4.4.1 标题和摘要与全文的主题对比分析
将标题和摘要中的研究主题与全文中的研究主题进行对比,发现有11 个主题相同,即新冠病毒、新冠传播、新冠发生地、疫情防控、抗病毒药物、临床分型、病理分析、新冠药物研究、新冠就诊、中医治疗、网络药理学。从主体内容上看,这11 个主题与新冠的防治联系紧密,在一定程度上能够揭示当前新冠研究的主要内容。从主题的数量上看,全文中富含较多的主题信息,与标题和摘要中的主题信息相比,研究者关注的内容较多。
4.4.2 标题和摘要与引文内容的主题对比分析
标题和摘要是作者对文献全文内容的总结和概括,引文内容是作者对他人研究成果的总结和概括。换言之,标题和摘要、引文内容分别是对施引文献集和被引文献集的总结和概括,将二者进行对比,可以分析引文内容对施引文献内容的作用。
由表3 可知,标题和摘要、引文内容之间有8 个相同主题,比标题和摘要与全文的相同主题少3 个,其中新冠药物研究、新冠就诊、中医治疗、网络药理学、新冠检测、药物分析、病例分析、防控措施8 个主题是引文内容中没有的,而病毒溯源、医疗设施、呼吸道症状、细胞因子风暴、基础疾病5 个主题是引文内容独有的,在标题和摘要、全文内容中都未出现。因此,引文内容与其施引文献内容的主题相关,二者可以进行互补。

表3 新冠研究主题Table 3 The research topics of COVID-19
5 讨论
本文使用有关新冠的中文期刊文献数据,从不同内容层面:标题和摘要、引文内容、全文内容,探究三者之间的主题差异,得到研究主题在文献的标题和摘要、引文内容、全文内容中存在差异的结论,现对该结论进行讨论并分析其产生的原因。
首先,从主题的相似性上看,标题和摘要与引文内容的主题相似性低于全文内容与引文内容的主题相似性,而全文内容与引文内容的主题相似性又低于标题和摘要与全文内容的主题相似性。究其原因,文献的标题和摘要是对全文内容的总结和提炼,具有高度的内容相关性,引文内容是作者引用他人成果的总结和概括,与其施引的文献内容相关。其次,从主题数量上看,全文内容中富含较多的主题信息,与标题和摘要相比,新冠感染、核酸检测、临床症状、中医药、医学检查、新冠防护六个主题受到研究者的关注。最后,从引用和被引用内容上看,引文内容中涵盖的主题信息较广,与标题和摘要相比,新冠病毒的溯源、医疗设施以及基础疾病等内容受到研究者的关注。
综上所述,标题和摘要中的研究主题与全文内容中的研究主题更相似,在对文献进行主题分析时,可以使用标题和摘要中的研究主题来概括全文内容的研究主题;引文内容与其施引文献内容的主题相关,二者可以进行互补,能够凸显出新冠研究的主要内容。
此外,本文还发现不同引用频次的文献,在引文内容中揭示的研究主题也不同,即中频和低频引用文献在主题的相似程度上更高,而高频和低频引用文献在主题的相似程度上更低。经过分析,被高频引用的文献侧重新冠的流行病学和临床特征研究,这些文献发表时间较早,对新冠病毒的诊断和治疗具有重要的指导作用。然而,被中频和低频引用的文献发布时间较晚,研究的内容涵盖新冠的各个方面,主题内容宽而广,没有高频引用文献中的主题集中,故而两者之间的主题相似性较低。
6 结语
自从COVID-19 在全球爆发以来,许多国家、机构和科研人员都把研究重点放在该主题上,这导致了新冠领域的学术论文迅速增长。使用文献计量方法来分析新冠的研究现状,可以了解新冠研究的最新动态,给相关研究者提供参考。本文的研究建立在中文期刊文献资料的分析基础上,分析了国内学者在新冠研究中的主要内容,得出了研究主题在文献的标题和摘要、引文内容、全文内容中存在差异,即与标题和摘要相比,全文中富含更多的主题内容,但二者的主题内容差异较小,可以使用标题和摘要中的主题内容来表征全文的研究内容;引文内容与其施引文献内容的主题相关,二者可以进行内容互补。
中国在疫情的防治工作中,采取了一系列有效措施,使得疫情得到稳步控制。此外,国内学者在新冠研究中也做了大量工作,研究的内容涉及新冠的发病机理、病毒溯源、传播与防护、检测与治疗、抗病毒药物研究、基础疾病等各方面,并且重视中医药和中医治疗方法在新冠治疗中的运用,为新冠疫情的防治提供了理论和实践保障。
本文使用特征词聚类来识别研究主题,也存在一些不足之处。一方面,由于缺乏医学领域的专业知识,对主题的总结欠妥,不能很好地确定每一聚类簇的主题。另一方面,特征词抽取的准确率需要进一步提高,未来可以考虑使用机器学习的方法来抽取论文中的关键词,对关键词进行分析。
猜你喜欢
风机技术(2021年3期)2021-08-05 07:41:38
风机技术(2019年4期)2019-06-24 05:42:14
计算机技术与发展(2018年8期)2018-08-21 02:08:14
电子测试(2017年15期)2017-12-18 07:19:27
中国机械工程(2017年22期)2017-12-02 01:52:34
南风窗(2017年9期)2017-05-04 21:04:27
智能系统学报(2015年4期)2015-12-27 09:38:39
中文信息学报(2015年4期)2015-04-21 08:29:12
电子设计工程(2015年6期)2015-02-27 12:04:53
语文知识(2014年5期)2014-02-28 21:59:59
