
基于改进随机森林的驾驶员视线估计的方法*
2021-06-07 05:28单兴华王增才范柏旺
传感器与微系统 2021年5期
单兴华, 王增才, 范柏旺
(1.山东大学 机械工程学院,山东 济南 250061;2.山东大学 高效洁净机械制造实验室 教育部重点实验室,山东 济南 250061;3.山东大学 机械基础实验教学中心 国家级实验教学示范中心,山东 济南 250061)
0 引 言
分心驾驶是驾驶员造成交通事故的主要原因之一,由于驾驶员的视线方向与其注意力点关系密切[1],因此,研究驾驶员的视线方向对于安全驾驶具有重要意义。
对于驾驶员的驾驶行为的研究主要有穿戴式[2]和非穿戴式两种方法。由于前者会对驾驶员的驾驶行为造成一定的影响,不适宜在日常的驾驶过程中使用;后者随着近年来机器学习和图像处理技术的发展受到了越来越多的关注[3,4]。驾驶员的视线方向与驾驶员的头部姿态之间存在明显的映射关系,关于头部姿态[5,6]的研究也相对较多,因此,早年的驾驶员视线检测任务直接使用头部姿态来估计驾驶员的视线方向[7,8]。但仅靠头部姿态来估计驾驶员的视线区域的方法在处理车内空间划分较多的复杂情况时效果较差[9],因此,在近年来的视线检测任务中又加上了眼睛特征[10~12]。眼睛特征的主要信息是寻找瞳孔的位置信息,弗里德曼等人[13]将眼部最大圆形斑点的圆心近似认是驾驶员的瞳孔,但这种眼睛特征提取的方法在图像质量较低时效果表现较差。
本文首先建立驾驶员的实车视线检测的数据集并提取相应的面部特征点,然后通过基于表现的方法提取驾驶员的头部姿态特征;并通过眼睛区域图像的灰度分布获得驾驶员的瞳孔位置,提高该方法在低图像质量时的可靠性。针对以前视线检测方法[11~13]都使用随机森林算法对驾驶员特征向量进行分类的问题,本文设计了一种通过高斯混合模型和加权思想改进的随机森林算法,并最终通过对比实验证明了改进算法的优越性。
1 实验预处理
1.1 实验框架
为了直观展示实验的系统流程,本文提出实验的具体系统流程图如图1所示。
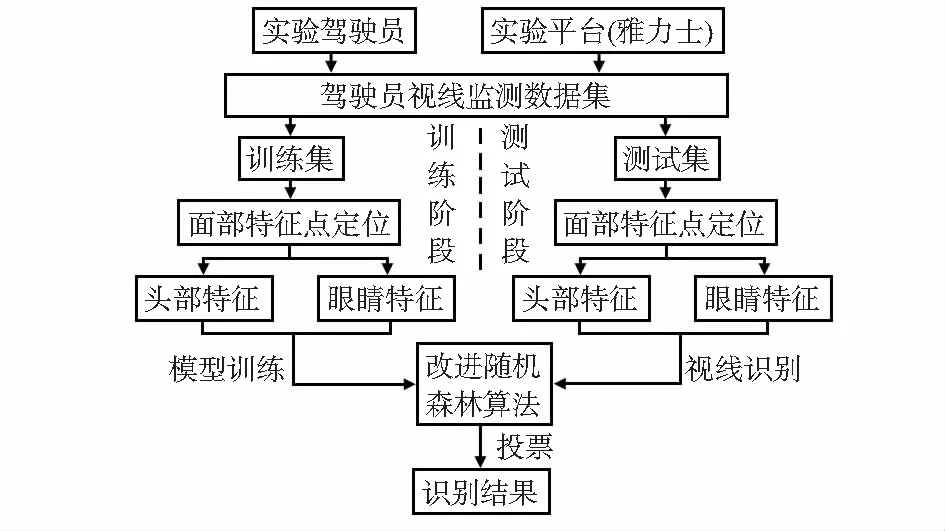
图1 本文系统流程框图
1.2 视线检测驾驶员数据集建立
由于驾驶员视线检测并没有可用的公共数据集,实验的第一步就是进行实车实验来建立所需的实车驾驶员视线检测的数据集。实验所需的数据集都是通过前挡风玻璃上的罗技C310网络摄像头拍摄的(见图2),摄影头粘贴在前挡风玻璃上,原因主要有两个:1)这个位置可以稳定地获取驾驶员正面的人脸图像,不会在驾驶过程中产生被车内的方向盘等装置遮挡的情况。2)该位置可以获得车内的广角照片,在驾驶员有大幅度身体动作时仍可以有效记录驾驶员的驾驶活动。

图2 视线检测罗技摄像头
驾驶员的视线方向划分为车内常用的13区域(见图3),根据这些区域可以估计驾驶员包括超车、转弯在内的驾驶意图。同时,当驾驶员的视线区域长时间或者频频的离开正常的驾驶区域时,就能认为驾驶员处于分心驾驶的状态,从而可以给予驾驶员一定的提示或者预警。

图3 驾驶员车内视线区域划分
为了获得足量且有效的驾驶员图像来建立视线检测所需的数据集,实验中,请了20位驾驶员进行试验并采集相应的图像数据集。为了保证数据的平衡性及严谨性,该数据集中包含4位女性驾驶员,9位戴眼镜的驾驶员,且驾驶员本身也存在一定的身高体重的差异。为了保证实验的安全性,实验过程选择在校内行人较少的道路上进行实验,因为驾驶员在驾驶过程中要进行各个角度的观察张望,因此实验时车辆进行怠速行驶,每个编号区域驾驶员的注视时间为15 s,这样以保证每个区域都有足量效果较好的图片。
1.3 驾驶员面部特征点获取
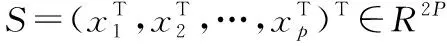
(t+1)=(t)+rt(I,(t))
(1)
式中rt为基于特征的预测,(t)为上一次迭代所预测的特征点形状或坐标。ERT可以检测到包含眼角点在内的大多数人脸特征点,检测速度快,且即使在大头部转动或复杂的面部表情的情况下也可以检测到相应的面部特征点。
1.4 驾驶员头部姿态特征提取
鉴于有些头部姿态计算方法复杂,难以作为机器学习的特征选择,本文选择基于外观的驾驶员头部姿态特征提取方法(如图4所示),该方法通过面部特征点的相对位置关系作为头部姿态估计的具体特征,简单实用,可以有效减小系统的计算量,从而减小实验的硬件要求。

图4 驾驶员的头部姿态特征提取
驾驶员头部姿态的特征具体提取方法如下所述:首先确定所有选定的面部特征点的坐标值X=[(x1,y1),(x2,y2),…,(xn,yn)]∈Rm×n,其中,(xi,yi)代表第i个特征点坐标值,特征点之间的角度特征的获取如式(2)所示,对于特征点之间距离特征获取如式(3)所示
(2)
(3)
1.5 驾驶员眼睛特征提取
眼睛状态是驾驶员视线检测工作中重要组成部分,但由于获得的眼部区域照片像素总数较少,且图片像素较低,导致驾驶员的瞳孔信息隐藏在了角膜之中,因此获得瞳孔位置的工作相对较为困难。由于角膜的像素太少,直接采用Hough变换求取瞳孔信息的方法可靠性较差;且因为受光照条件及眼镜反光等情况的影响,整个眼部照片的最小像素不一定出现在真实的瞳孔处,所以,也不能简单直接使用像素最小值的位置信息。在实验中,提出一种基于统计有效灰度的方法来获得驾驶员的眼睛特征。
提取的眼睛图片及二值化处理之后的结果如图5所示,由图5可知:处理之后的照片基本保留了驾驶员角膜所在的位置信息,可以通过统计二值化之后的图片灰度分布得到灰度中心,进而把二值化图片的灰度中心认为成驾驶员的瞳孔中心。

图5 驾驶员眼睛的灰度图像及二值化后的图像
具体的眼睛特征处理如下:假设得到驾驶员的眼睛图像大小为Rm×n,其中每个像素点的像素信息为X=[x00,x01,…,x0n;…;xm0,xm1,…,xmn],最后通过式(4)的方法提取驾驶员的眼睛特征
(4)
2 实验理论
2.1 随机森林模型
随机森林算法是由大量分类回归树组成的集成算法,其中每颗单独的树都有一定的分类效果,但通过投票使用众多的分类树能有效提高算法整体的分类效果。假设样本S有N个观测特征,则k棵树的随机森林生成算法流程如下所述:
1)在样本S中通过Bootstrap技术重复有放回的随机选取k个样本子集(S1,S2,…,Sk),每次未被抽取的袋外数据(OOB)备选作为测试集。
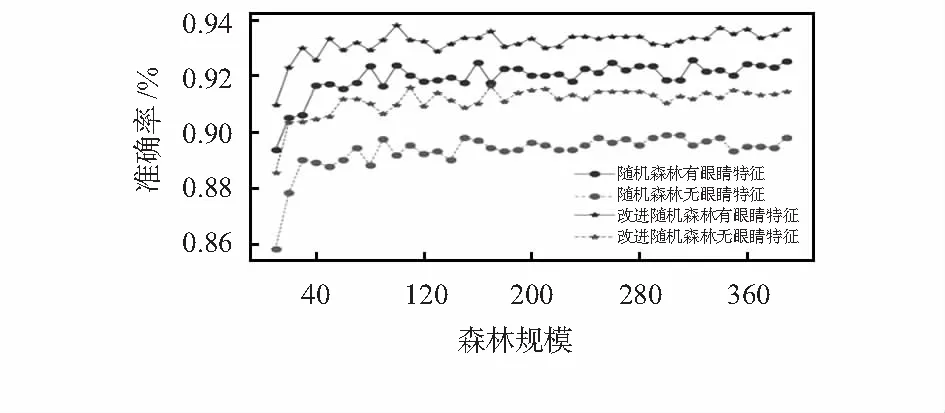
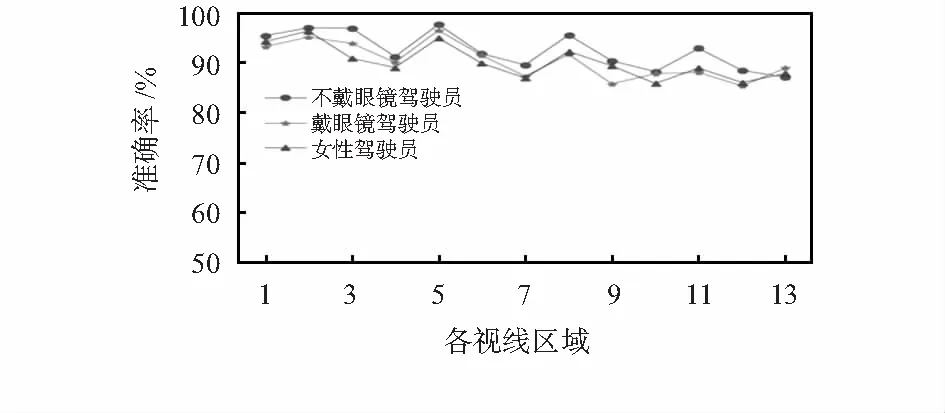
2)构建决策树时随机地选取n(n 3)重复上面两个步骤k次建立k棵决策树,每棵独立的决策树都可能因为各自选择的样本子集和所选特征不同而生长为不同的决策树。 4)最后生成所有的决策树整体一起构成随机森林模型,并最终根据式(5)确定决策树的最终分类 (5) 式中H为最终的随机森林模型,Y为各数据的分类标签,I为指示性函数,h为单棵决策树。 如前文2.1节所述,传统的随机森林算法通过采用Bootstrap重采样的方法随机选取训练子集,这样选取的各训练样本之间的独立性不能得到有效保证,这样就导致各个决策树之间的相关性有进一步降低的可能。因此本文通过高斯混合聚类分簇来选取训练子集以求减小各子集的相关性,从而提高各决策树之间的独立性。 高斯混合聚类模型是一种常见有效的概率模型,模型的数学公式表达如式(6)所示 (6) 该分布共有k个高斯分布混合组成,其中,μi,σi为第i个高斯混合成分的均值与标准差参数,前面的αi为第i个高斯分布所对应的混合系数。 具体的算法流程如下所述: 1)初始化模型参数{(μi,σi,αi)|1≤i≤k}。 2)根据贝叶斯定理计算各混合成分生成的后验概率 (7) 3)通过采用极大似然函数式(8)计算高斯混合模型的参数(μi,σi,αi),对各参数求偏导并令其为0计算参数值 (8) 4)重复进行步骤(2)和步骤(3)直到满足条件,求得各参数后根据式(9)计算得出样本所属的簇标 (9) 传统随机森林算法的结果是通过所有决策树输出结果的简单平均投票得出的,这样不能保证发挥出分类效果好的决策树的分类效果,因此,在本文中使用了一种结合分类效果的随机森林加权投票输出方法。 对于每一棵随机森林中的决策树,根据每个训练子集中的袋外数据对其分类效果进行评估,并以此做为参考给予其相应的分类权重 (10) 式中OOBcorrect(i)为第i棵决策树在袋外数据OOB中预测正确的样本数量,OOB为袋外数据的总体样本数量。给定权重后,随机森林最终的输出结果如式(11)所示 (11) 模型的有效性结果是通过整体测试集数据评价的,实验准确度的计算如式(12)所示 (12) 综上所述,本文提出的改进随机森林算法步骤主要如下文所述: 1)首先设定高斯混合聚类的聚类簇数k和最大迭代次数(实验中分别取值4和100)。 2)对驾驶员训练集特征向量进行高斯混合聚类处理得到不同的簇[c1,c2,c3,c4,c5,c6,c7,c8]。 3)给定随机森林的森林规模参数k并根据步骤(2)中的不同簇的数目大小决定各簇决策树的数量,在各簇中训练生长决策树,并在决策树生长完成后按前文2.3节所述方法给予各决策树相应的投票权值。 4)所有的决策树在一起构成改进的随机森林,按前文2.4节所述的算法评价指标得出最终的算法分类准确率。 为了检验改进随机森林算法在驾驶员视线检测任务中的有效性,将前文所得驾驶员头部特征和眼睛特征同时导入改进随机森林和随机森林模型中进行分类。以森林规模为自变量,同时通过十折交叉验证的方法得出两种模型在相同条件下的分类准确率。实验结果如图6所示,可以得出两个比较明显的结论:1)通过增加驾驶员的眼睛特征可以明显增加驾驶员视线分类的准确率,证明了眼睛特征提取的有效性;2)实验提出的改进随机森林算法可以有效提高驾驶员视线分类的准确率。 图6 不同模型的驾驶员视线分类结果 确定了改进随机森林算法相较于传统随机森林的优势后,接下来将所提理论与现有常用的其他机器学习模型的识别效果对比,对比结果如图7所示。由图7可知:实验所提出的改进随机森林算法与其他机器学习算法相比也取得了更高的准确率。 图7 各种经典机器学习模型的分类效果对比图 因为驾驶员的性别以及是否佩戴眼镜都会对最终的视线检测结果造成一定的影响,因此需要验证系统所提算法针对不同情况驾驶员人群的有效性,具体识别结果如图8所示。由图可知,眼镜的佩戴与否确实会对视线分类造成一定的影响;由于实验样本女性驾驶员数据较少也会使准确率有一定降低;个体的体型差异也会对识别结果有一定的影响。不过最终各区域的实验准确率都在可接受的范围内,基本满足日常驾驶活动对驾驶员视线识别的要求。 图8 不同实验人群识别效果对比 随着近年来深度学习的发展,深度学习也作为分类的常用手段之一。将改进随机森林算法与深度学习经典网络Alexnet和VGG16在测试集中进行分类效果对比。最终识别结果如表1所示,由表可知,改进随机森林算法相比于Alexnet和VGG16网络在本实验能取得更佳的分类效果;且改进随机森林算法对大部分区域的识别准确率在90 %以上,其中最小的准确率也达到了87.85 %,对驾驶过程中常用的区域识别准确率更是达到95 %以上,基本满足驾驶员正常驾驶活动的视线检测的要求。 表1 视线区域识别结果对比 实验结果表明:相较于包括传统随机森林在内的其他机器学习算法,改进随机森林算法在驾驶员视线检测任务中可以取得更高的准确率,且在不同类型的实验人群中均能取得良好的效果,对于未来的安全驾驶行为具有广泛的应用前景。2.2 高斯混合聚类选取训练子集
2.3 加权投票算法
2.4 算法的评价指标

2.5 改进随机森林算法步骤
3 实验结果
3.1 算法验证与实验结果对比

3.2 与深度学习模型分类结果对比

4 结束语
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
汽车实用技术(2022年4期)2022-03-07
特区文学·诗(2021年6期)2021-12-22
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
金色少年(奇趣科普)(2017年11期)2017-11-28
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
公民与法治(2016年4期)2016-05-17
当代贵州(2015年19期)2015-06-13
郑州大学学报(医学版)(2015年1期)2015-02-27
