
食品安全舆情事件抽取模型研究
2021-06-06 00:33孙劭
中国质量万里行 2021年5期
食品安全领域的舆情事件抽取是当前信息抽取领域的重要研究课题,也是食品安全舆情监管和预测的重点技术之一。
如今,科研人员在研究事件抽取时,一般使用两种方法。一是基于规则的方法,一般来说,这种方法更适用于英文报道,普适性较差,并不适用于中文舆情的事件抽取。第二种是基于神经网络模型的深度学习方法,近年来已成功地应用于各领域的中文事件抽取任务中,并表现出了更好的性能。本文的模型是基于深度学习的研究方法。
事件抽取相关工作的有关研究
事件抽取作为信息抽取的子任务,在知识挖掘领域起着非常重要的作用,也一直是经典而又富有挑战性的任务,在过去十几年的研究发展中也取得了很多阶段性的突破。
事件抽取研究中,首先被提出的就是研究者们通过文本分析和自身的语言知识,把语料中每一个句子用一系列特征和规则进行处理,我们称之为基于规则的方法。2008年,Ji等人在不标记数据的前提下,采用基于规则的方法在句子和文档之间传播一致的触发词分类和事件元素,提高了性能。
2009年,郑家恒和毋菲等人 针对中文事件的特点,提出了一种更适用于提取中文事件论元值的方法,他们的研究以决策树为依托,对语料事件的触发词以及其上下文进行分析并将语料分类,最后利用规则匹配抽取语料中的目标词。
后来,孟雷、丁效等人在依存句法的基础上,提出了一种对事件元素抽取的方法,并根据短语结构句法分析,进一步确定事件元素的边界情况。
研究发现,通过句法关系结合抽取规则,能够很好地抽取事件的元素核心词,然后再利用短语结构句法,就能够很好地确定完整的事件元素。
区别于基于规则的方法,基于神经网络模型的深度学习的方法近年来受到越来越多的研究者的重视,已经成为了最主流的事件抽取方法。Ahn明确指出对于事件元素识别分类问题,可以将其转变为多变量分类问题,并通过分类学习的方法,在ACE语料库中,有效地识别事件触发词、事件元素。Xia等人于2015年提出一种融合文本、图像和地点等信息的一种联合架构模型,并用该模型抽取事件的空间和时间信息,然后在这一基础上,将特定的事件信息抽取出来。Chen等人构建出了动态多池化卷积神经网络(DMCNN),利用简单的NLP工具,能够自动提取出词汇及句子级别的特征提取出来。他们采用卷积神经网络(CNN)的框架来捕获句子级线索,同时还提出了动态多池化卷积神经网络(DMCNN)来保留关键信息。实验结果表明该方法优于其他最新方法,是深度学习在事件抽取任务上应用的有效尝试。
另一项里程碑的工作是Nguyen 等人提出在具有双向递归神经网络的联合框架中进行事件抽取,它在考虑事件触发词的基础上,还兼顾事件元素,并且对联合模型的记忆特征进行了深入地分析,并通过实验证明了所提出的模型在ACE2005数据集上达到了最好的性能。随着深度学习研究的不断深入,图卷积网络也被应用于多事件抽取任务,并且成效显著。
BiLSTM神经网络近年来也有了长足的发展,何等人利用BiLSTM,在抽取生物事件通用语料MLEE 时,表现出了非常好的抽取性能。
食品安全舆情事件抽取模型
本文所提出的食品安全舆情事件抽取模型,主要用于实现食品安全舆情事件触发词的识别及分类和食品安全舆情事件的论元识别及抽取。在本章节中,我们将详细介绍食品安全舆情事件抽取模型的网络结构和内部的处理过程模型前期准备工作。
1. 食品安全舆情事件模型
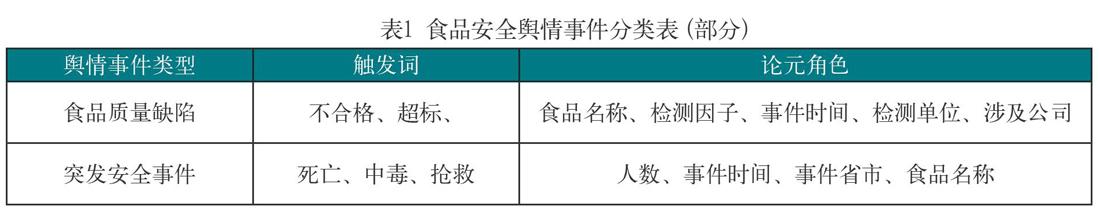
我们参照ACE2005 对事件定义的8种事件类型和33种子类型,构建了实验所需的食品安全舆情事件模型。该模型可通过舆情事件类型、触发词、必要论元角色(唯一)和可出现论元角色四部分,为食品安全舆情事件进行分类。具体分类如表1所示:
2.数据预处理
在神经网络中,数据输入的质量是至关重要的,因此我们需要对食品安全领域舆情语料库中的语料进行预处理,提高其数据质量,保证模型不会受到噪声干扰,发挥最佳的性能。
第一步,数据清洗,由于网络中的舆情文本中经常存在一些特殊字符,例如:表情符号,乱码,中文文本中不会出现的【@#¥&~^*/】等与舆情本身无关且干扰模型训练效果的字符,所以我们首先要对其进行处理,将文本中的无用符号去除。
第二步,通过构建触发词词典,将事件抽取视为分类工作。按照一定的知识逻辑和事件规律,按类别总结候选触发词,并在预料中验证候选触发词,最终构建触发词词典,并在后期实验中不断更新补充。
第三步:由于食品安全舆情报道往往是长文本,无法全部输入到神经网络中,因此我们读取语料库中经第一步中处理过后的舆情语料,以‘。为分隔符,加入标记符号“[SEP]”,最大长度为300字,对于长度大于300字的句子,选择距离结尾最近逗号加入标记符号,将处理好的句子存储到数据库新的字段中。
同时,我们根据食品安全舆情事件模型对舆情语料进行人工标注,将舆情事件中的舆情事件类型,触发词,论元,论元角色等四部分内容做标记,其中空值记为NULL。
3. 词向量训练
词向量训练是将字转换为向量坐标表示的方法,通过语言模型的训练,将模型词典中的词以向量形式表示,其中具有相似语义关系词之间的坐标距离会更接近,在训练时能够更好的理解词语的语义信息,是处理同义词,相近词等问题的有效手段。
本文通过Word2Vec,针对食品安全舆情预料,展开了一系列词向量训练。Word2Vec可以有效实现词语的向量编码,保留文本上下文特征和位置特征等,具有较好的语义表达准确性。
本研究完成的主要工作是基于BiLSTM-CRF构建了一个事件抽取模型,应用到食品安全领域舆情的事件抽取中。通过BiLSTM模型对语料進行特征提取,并通过CRF模型对事件类别和元素种类进行判别,这两个模型共同组合成食品安全舆情事件抽取模型,其在测试集上取得了较好的效果。
本文的研究为食品安全舆情领域的事件抽取提供了新的方法及思路,为实现相关食品安全舆情监管可视化平台、食品安全舆情预测等应用奠定了基础。
此外如何对抽取后出现的噪音数据进行识别、校正以及对食品领域词、知识的补全将会是下一步工作的重点。未来可通过人工智能技术进一步打造食品安全舆情监管智能化系统,实现资源共享,为大众和监管部门可以快速准确的把握食品安全舆情提供便利。
作者:孙劭 北京工商大学电商与物流学院研究生
猜你喜欢
韶关学院学报(2017年4期)2017-04-13
海外华文教育(2016年3期)2017-01-20
海外华文教育(2016年1期)2017-01-20
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
江西师范大学学报(哲学社会科学版)(2014年1期)2014-09-05
外语教学理论与实践(2014年2期)2014-06-21
