
基于跨模态语义增强的图像检索方法
2021-06-03 02:12王琪,王睿,王力
南阳理工学院学报 2021年2期
王 琪,王 睿,王 力
(1.南阳理工学院信息工程学院 河南 南阳 473004; 2.乐凯华光印刷科技有限公司 河南 南阳 473004;3.南阳理工学院土木工程学院 河南 南阳 473004)
0 引言
随着网络的发展,网络信息增长迅速,且多样化发展,如图像、文本等,这类信息被称为跨模态数据。这些跨模态数据并不是各自独立存在的,他们之间存在很大的关联性,例如,在同一个网页上出现的文本和图像往往有交叉信息,也即文本包含了图像的语义解释。且文本信息往往比底层视觉信息具有更高的语义判别特性,这为图像检索问题中长期存在且并未有效解决的“语义鸿沟”问题提供了一个新的解决方向。然而,现有的检索方法中,通过文本或图像检索,往往是独立运用了单一的文本或图像信息,并没有有效利用文本和图像之间的关联性。主要原因是文本和图像表征存在于两个异构空间,不同的分布难以融合判断,为解决有效利用文本中的深层有效信息的问题,典型相关分析法(CCA)是近年中的经典算法,此算法通过最大化文本信息矩阵和图像信息矩阵两个模态之间的关联性使其映射到一个同构空间,从而计算相似度达到检索目的。围绕CCA方法提出了多种研究方法[1,2],N Rasiwasia等提出语义关联匹配(SCM)方法[3],Gong Y等人提出了三视角CCA方法[4],利用实际标签达到CCA方法的语义增强。但由于CCA的线性映射无法很好地拟合现实数据的线性问题,核典型相关分析法(KCCA)被提出用于跨模态学习,KCCA方法分别通过非线性映射到高维空间,在高维空间中进行CCA的同构训练[5,6],但由于其数据维度的增加使得计算量随数据的增加呈指数增加,因此训练速度较慢,计算代价较高。以上方法虽然能将图像和文本信息有效关联起来,但都忽略了文本信息较强的语义判别性。J Pereira等人提出潜语义加强算法,将图像语义空间信息映射到文本语义空间,使得文本和图像同分布,同时用文本特征增强图像语义[7,8],虽然考虑了文本较强的判别力,但其图像语义空间的构建过程中,数据源仅来自底层视觉信息,并未有效利用文本信息的强语义特点,同时忽略了图像底层视觉特征的语义模糊性,使得文本较强的语义判别性被弱化。基于此,本文提出了一种跨模态语义增强协同约束模型(CSR),总体框架如图1所示,主要步骤如下:
(1)获取图像和文本的底层特征向量。图像数据通过SIFT(Scale Invariant Feature Transform)算法分析特征点及特征点向量矩阵,通过词袋算法对特征矩阵进行映射得到图像的SIFT特征。文本数据采用隐含狄利克雷分布(LDA,Latent Dirichlet Allocation)分析文本信息的LDA概率分布从而抽取文本特征向量。
(2)构建语义增强协同约束空间。为了有效利用文本对语义的强判别性增强图像语义信息,同时避免在语义映射空间中底层视觉特征的弱语义削弱文本的语义判别性,本文通过线性判别分析(LDA)协同约束文本和图像CCA空间,实现CCA及线性判别LDA模型的联合优化,以此达到增强底层特征语义的目的。
(3)多分类逻辑回归语义映射空间。首先,根据步骤(2)中获得的联合优化后的视觉特征及文本特征信息建立softmax模型,计算图像或文本属于每个类别的后验概率值,作为图像和文本的高层语义描述子。由于此时的高层语义描述子基础信息源来自步骤(2)中联合优化后的特征描述子,因而相较于直接由底层特征映射的高层信息更准确。然后,用文本语义描述子正则化图像语义描述子,使得图像具有文本近似的分布。

图1 总体框架
1 底层特征描述
通过SIFT算法获得图像的底层视觉描述。SIFT算法采用金字塔模型提取图像特征点,计算特征点方向梯度信息生成特征点SIFT描述子,因而具有较强的鲁棒性和尺度不变性,因而本文采用SIFT描述子获得图像的特征点及特征点的SIFT描述子形成[1024*n]维大小的SIFT特征矩阵,n为特征点数目。为形成图像特征描述向量,采用BovW(bag of visual word)词袋模型获得1024维图像特征描述子。
图像对应的文本信息利用隐含狄利克雷分布(LDA,Latent Dirichlet Allocation)获取文本信息的100个语义中心的概率分布,从而得到100维的文本特征描述向量。
2 语义增强特征学习
文献[7,8]方法虽然将图像高层语义特征空间映射到文本特征空间,利用了文本信息的强语义判别性,但无论是图像的语义信息还是文本的语义信息,都是单独由图像和文本的底层特征分别提取,忽略了文本和图像之间的语义关联性,同时低估了图像底层特征的弱语义性,使得图像和文本语义信息表示并不准确,影响文本语义正则化图像语义的效果。因而本文设计语义增强的协同约束空间,此空间联合优化CCA模型,和文本的LDA模型(Linear Discriminant Analysis, 以下简称LDA),通过CCA模型最大化文本和图像的关联性,可充分利用两类信息的语义相关性,同时考虑到文本信息较之视觉底层信息有更强的语义内容,因而在CCA模型迭代优化的同时优化文本LDA模型,使得文本语义最大化的同时视觉和文本信息的关联性也最大。
2.1 文本语义增强表示
线性判别分析(LDA)的基本思想是通过LDA映射后的类内数据具有较大的关联性,同维的同时增强文本的语义信息。

(1)
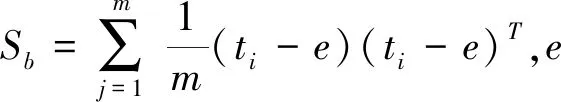
(2)
其中,即主对角线元素和。W是d2*d3维的投影矩阵。使用拉格朗日乘子法优化目标等价为
minJ(W)=tr(WTSwW)-λtr(WTSbW)
(3)
W即为上式求解的特征向量,tr函数表示矩阵的迹。
2.2 CCA模型最大化关联
通过CCA模型可使得文本信息和图像信息的关联最大化,同时将文本的强语义判别性迁移到视觉空间中增强视觉信息中语义表达的准确性。CCA模型求解获得两组不同样本的投影矩阵V、W,使样本通过矩阵投影后的数据具有高关联性,其目标函数等价为

(4)
其中V=⎣v1,v2…vd3」为图像样本的投影矩阵,大小为d1*d3;W=⎣w1,w2…wd3」表示文本投影矩阵,大小为d2*d3。其中,假设W一定,则TW一定,则上述可表示为
(5)
J(V)=tr(GV-TW)=(GV-TW)T(GV-TW)
(6)
采用最小二乘法可得投影矩阵为
V=(GTG)-1GTTW
(7)
2.3 CSR协同约束模型
本文CSR方法融合LDA模型和CCA模型两个独立的特征空间进行协同优化,寻求最优解,使得LDA文本语义增强的同时通过CCA模型使文本和图像两种不同分布结构的数据近似同分布,并且使语义信息更准确。CSR方法的约束目标函数为
(8)
(9)
代入V表达式,目标函数转化为
J(W)=tr(WTTT(G(GTG)-1GT-Id3)T(G(GTG)-1GT-Id3)TW)+tr(WTSwW-λWTSbW)
(10)
为方便求解特征值及特征向量,由式(11)和(12)得最优化目标为
maxJ(W)=maxtr(WT(λSb-Sw-TT(G(GTG)-1GT-Id3)T(G(GTG)-1GT-Id3)T))W)
(11)
X=λSb-Sw-TT(G(GTG)-1GT-Id3)T(G(GTG)-1GT-Id3)T
(12)
maxJ(W)=WTXW
(13)

3 语义正则化空间
3.1 图像和文本的语义特征描述
多分类回归Softmax模型提取图像和文本的语义特征描述。Softmax模型分别计算文本和图像每一个样本归属于各类别的后验概率,将文本和图像底层特征映射到高层语义同构空间。设图像和文本对共有k个类别,则图像和文本的语义描述向量分别为k维,向量各元素求和为1。Softmax模型损失函数
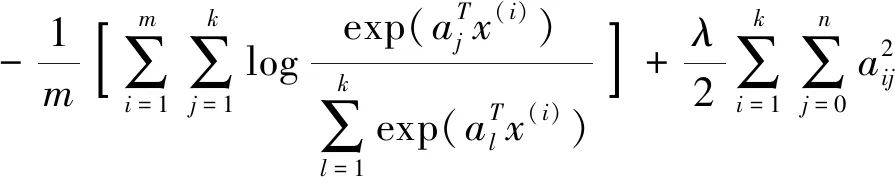
(14)
式中a为与样本对应的映射参数,x为CSR语义增强特征,第二项为衰减项可使得损失函数凸优化,求解损失函数最优时的a值即可得到CSR特征与高层语义特征之间的映射关系,从而获得样本语义特征描述。
3.2 语义正则化
由于文本语义较图像语义有较强的语义判别性,此处用文本语义表示正则化图像语义表示,可使得图像语义描述向量的语义信息更准确,从而提高图像检索的准确性。
设图像语义特征矩阵为P,文本语义特征矩阵为Q,语义正则化即求得矩阵H,使得Q=PH,即图像语义描述通过映射矩阵H获得与文本语义描述近似的分布,由最小二乘法得H=(PTP)-1PTQ,获得语义正则化后的图像特征描述P′=PH。
4 实验分析
将本文CSR算法在图像检索应用中运用,在Wikipedia和PascalSentence两个公开数据集上实验,并与CCA(典型相关分析法)、SM(语义匹配算法)、SCM(语义关联匹配算法)、RIS(语义正则化算法)4种算法进行对比分析,验证本文CSR算法的有效性。Wikipedia数据集有10个类别成对的图像和文本数据,拥有2866对数据,其中有2173对训练集和693对测试集。Pascal数据集共20个类别,1000对图像和文本样本,随机选取80%为训练样本,20%为测试样本。提取1024维BovwSIFT视觉词袋特征作为图像底层视觉特征,100维的隐含狄利克雷分布LDA特征作为文本特征向量。采用mAP作为图像检索性能指标,即计算每类图像平均查准率的平均值。表1显示了两种数据集上5中方法获得的图像检索mAP值,其中本文CSR方法相较于其他4中方法,在检索性能上有明显的提高。SM方法分别独立提取两个模态的语义特征,忽略了模态之间的关联性;CCA方法虽最大化了模态之间的关联性,但底层特征之间的关联性并不准确;SCM方法虽最大化两模态之间的语义关联性,但其语义特征仍然单独获取并未有效利用文本的强语义性;RIS方法使用文本语义特征正则化图像特征,但其特征各自独立且均由底层特征产生,因而文本特征并不准确,且不能很好地修正图像特征,且由于图像特征的弱语义关联性使得文本的强语义性被弱化;而本文CSR方法增强文本语义的同时将其迁移到两模态的公共空间,使得图像的视觉特征描述更具有语义判别性,从而提高语义正则化空间准确性,提高图像检索的平均查准率(mAP)。

表1 两种数据集上mAP值对比
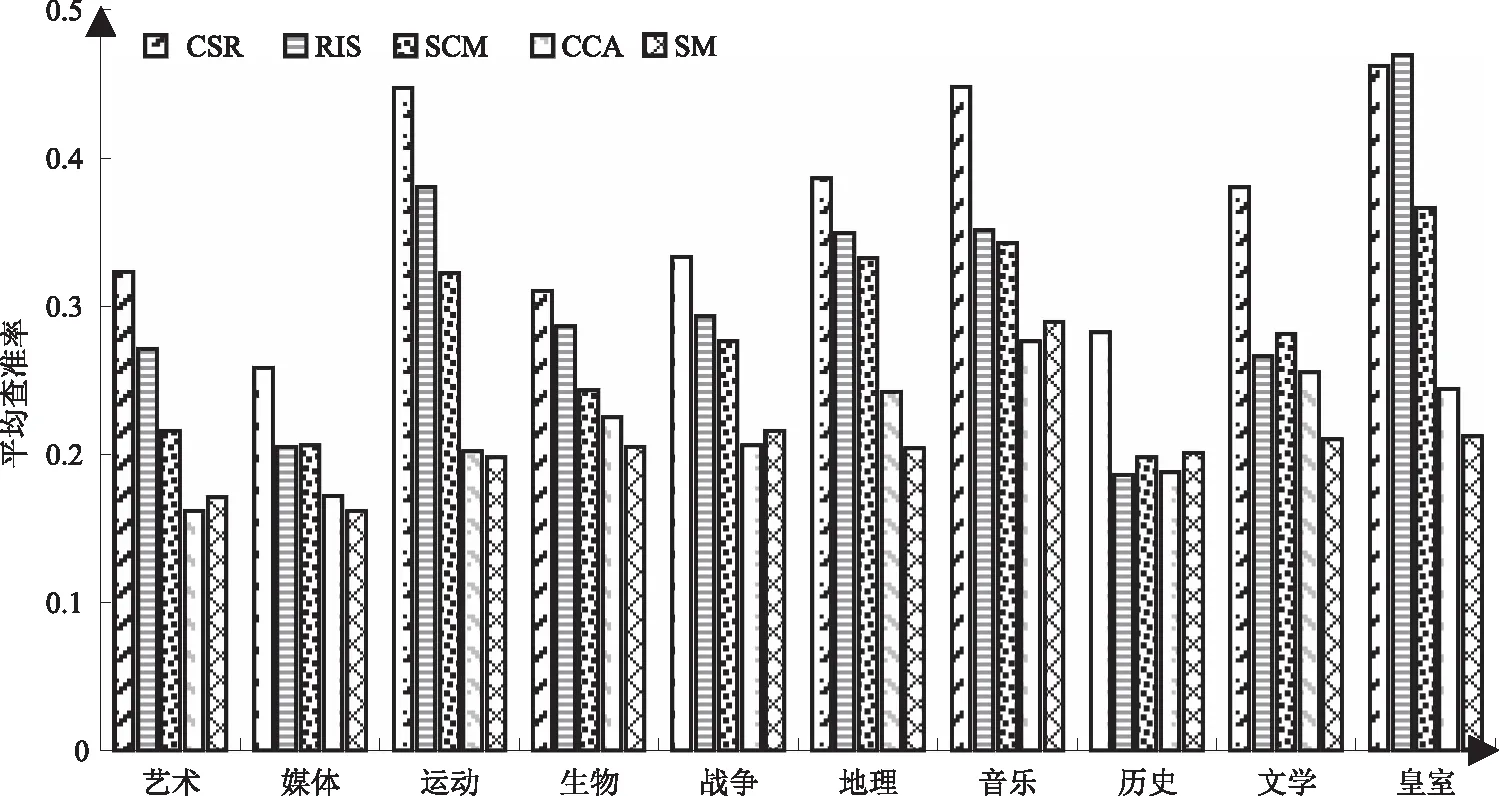
图2 Wikipedia数据集中每类数据的平均查准率
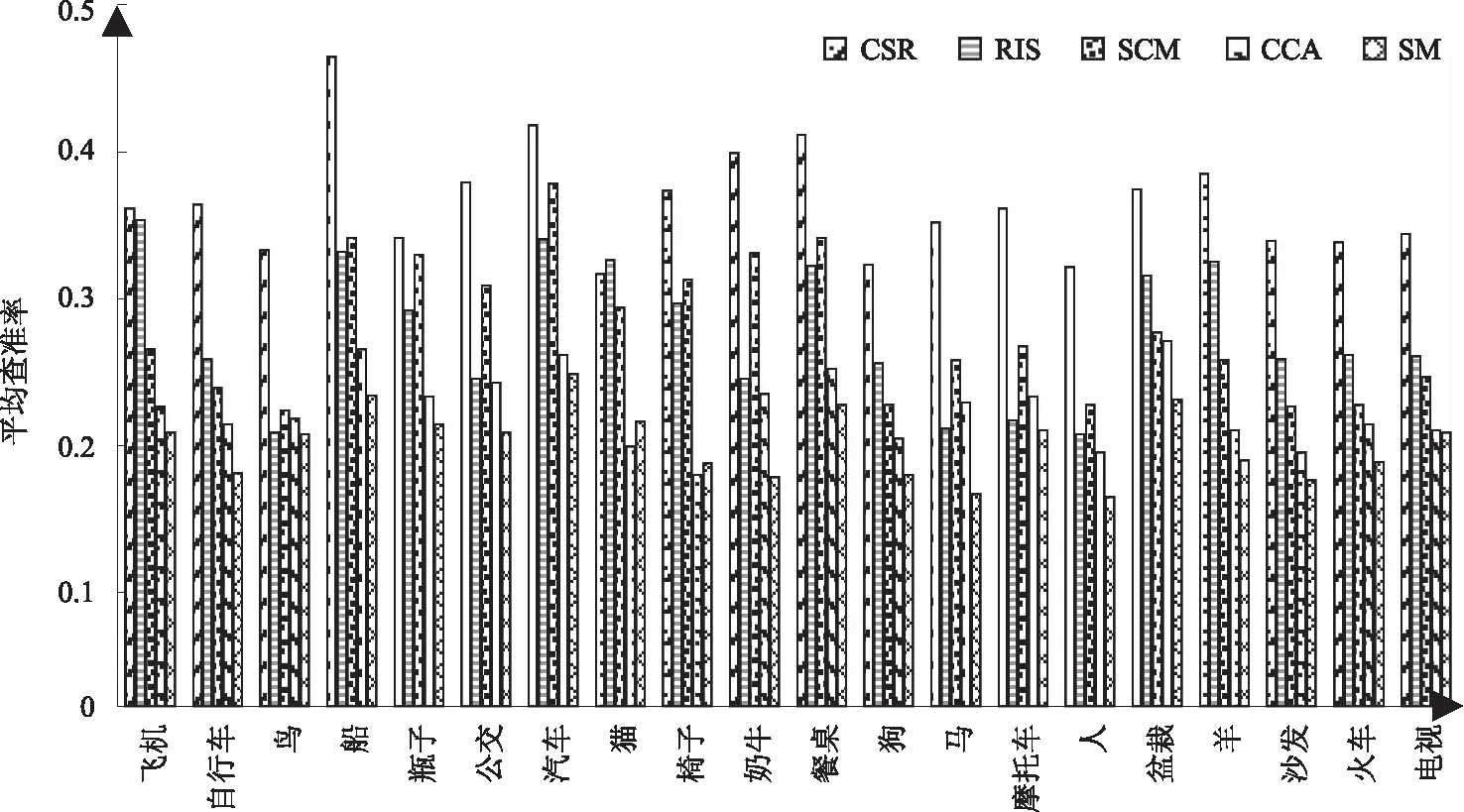
图3 Pascal Sentence数据集中每类数据的平均查准率
图2、图3分别表示CSR方法和4种方法在Wikipedia和Pascal Sentence数据集上每一类数据的mAP值,每列分类条形图中从左到右依次为本文CSR方法、RIS、SCM、CCA、SM方法。图中可见CSR方法的在绝大多数类别中的mAP值都优于其他4种方法。图4显示以Pascal数据集中cat图片为查询图片分别采用5种方法的检索结果,左侧为查询图像,右侧5行图像从上到下依次为本文CSR方法、RIS、SCM、CCA、SM方法检索结果中前4幅图像,其中检索有误的图像加黑色边框,显示本文方法的准确性高于其他4种方法。

图4 cat为查询图像的5种方法检索结果
5 结束语
本文提出的一种跨模态语义增强框架,充分利用文本信息的强语义性及文本和图像信息的关联性,提出协同约束模型提高图像和文本特征的语义判别性,使得从协同空间映射到softmax语义空间的特征描述准确,最后使用文本语义特征正则化图像特征,最大化图像信息的语义判别性,提高图像检索准确率。在Wikipedia和Pascal Sentence数据集上用5种方法对比实验,显示本文方法相较其他方法提高了图像检索的准确性。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
小学教学参考(语文)(2022年3期)2022-05-26
电子产品世界(2022年2期)2022-03-22
老年医学研究(2021年5期)2022-01-19
云南医药(2020年5期)2020-10-27
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
赢未来(2018年4期)2018-09-27
科技视界(2018年32期)2018-02-21
