
一种基于Q-Learning技术的水声网络协议*
2021-06-01 03:36赵开新刘小杰朱命冬
河南工学院学报 2021年1期
张 阳,任 刚,赵开新,刘小杰,朱命冬
(1.河南工学院 计算机科学与技术学院,河南 新乡 453003;2.河南工学院 数据挖掘与智能计算研究所,河南 新乡 453003)
0 引言
水声网络由若干分布在被监测区域的水下网络节点组成,在环境监测、资源勘探、灾难预警和潜艇探测等民用和军用领域均具有广阔的应用前景,是进行海洋开发的重要工具[1-4]。
水声网络技术的发展面临着多种挑战。首先,水声信道具有时空变化的特点,通信系统的最佳工作参数无法在部署前确定;其次,水声信道具有高延迟、低带宽和复杂多径衰落等特点,节点间实现可靠通信非常困难;最后,水声网络中能量补充困难,提高能量效率非常关键[5]。
机器学习方法,尤其是增强学习能够根据水声环境的动态变化,实时优化网络参数,实现网络的自主优化。本文提出了一种基于Q-Learning技术的水声网络协议,采用增强学习方法,使智能移动节点能够根据水声信道的时空变化情况和网络的实时特性,自适应地优化移动路径和服务时间,提高网络的能量效率,降低平均延迟。该方法为人工智能技术应用于水声网络提供了一个较好的借鉴。
1 Q-Learning算法
由于水声环境的时空变化特性,水声网络的最优工作参数无法在部署前确定。近年来水声网络中出现了应用增强学习算法来实现系统参数自适应更新的协议。Q-Learning技术是增强学习的主要算法之一,是一种无模型的学习方法。该算法将智能体与周围环境的交互视为Markov决策过程,即智能体根据当前所处的状态和所选择的动作,决定一个固定的状态转移概率分布和下一个状态,并得到一个即时回报[6-7]。
Q-Learning的目标是寻找一个策略,可以最大化未来回报Q。Q可通过以下模型计算:
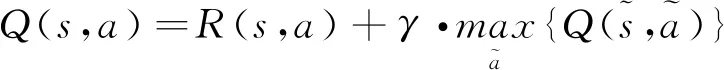
(1)
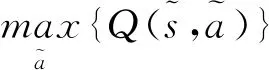
步骤1:给定折扣系数γ和奖励矩阵R。
步骤2:令Q=0。
步骤3:对每轮决策,随机选择一个初始状态s,若未达到目标状态,则执行:(1)在当前状态s的所有可能行动集合中选取一个动作a;(2)利用选定的动作a,得到下一个状态s;(3)按照公式(1)计算Q(s,a)。
2 网络模型
本节定义了一种典型的水声数据采集网络,用以验证所提出的网络协议。如图1所示,网络由n个静态锚节点和一个AUV(Autonomous Underwater Vehicle)节点组成。静态锚节点通过连接到海底的线缆保证悬浮在水中固定位置,采集海洋环境数据;AUV是具有移动能力和相对“无限”能量的水下航行器,能够在网络范围内自主移动,帮助锚节点完成数据交换。为了覆盖较大的范围和节约成本,锚节点经常稀疏布放;同时考虑到能耗,锚节点的通信能力是受限的,通常无法相互通信,需要移动AUV协助锚节点完成数据的交换。
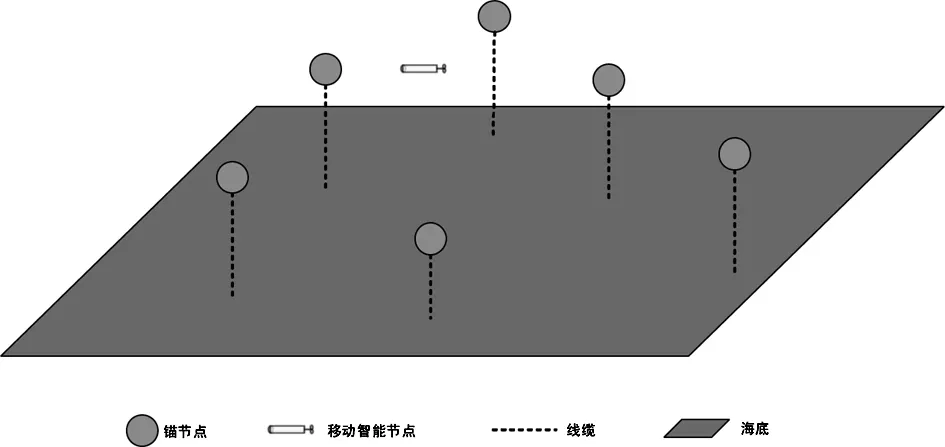
图1 一个典型的水声网络
AUV节点在网络中作为智能Agent,通过Q-Learning算法实时计算出最优移动路径。AUV节点在移动时,周期性的广播信标信号以发现处于通信范围内的锚节点。如果锚节点收到信标,则立刻向移动节点返回一个确认报文,随后AUV与锚节点之间建立通信并完成数据交换。为了简化模型,在每个锚节点附近定义一个位点,当AUV移动至该位点时,AUV和锚节点之间能够进行数据传输。假设节点i∈(1,n)对应的位点为wi,AUV的移动路径可以看做是一条折线,折点为节点的位点wi。AUV在两位点之间的运动简化为匀速直线运动,穿越一个锚节点的通信范围所消耗的时间Tv=2r/v,其中r表示锚节点的通信范围,v表示移动节点的运动速度。AUV达到一个位点后,可以自由选择下一个要访问的位点。
2.1 系统状态空间
整个网络可以看作是仅含一个Agent的Q-Learning系统,系统状态是离散的且和AUV要访问的位置相关。当AUV节点在时间t达到节点j时,系统状态可以定义为st=j,j=1,2,……n。可以得到系统的状态空间S={1,2,3…,n}。
2.2 动作集
动作集合定义为AUV节点访问某个锚节点的过程。通过在时间t执行动作at,AUV运动至节点i,同时系统状态转移到i。完成对应服务后,AUV需要决定下一个动作(即运动至哪个位点)。最优动作的选择取决于对当前状态下所有动作质量的估计。系统状态下的动作集可表示为Ai={1,…,i-1,i+1,…,n}。
2.3 回报函数
协议的目标是减少数据包传输延迟,在回报函数的设计上,主要考虑AUV的移动距离、锚节点的消息队列长度和AUV的等待时间。设当前系统的状态st=i,要执行的动作为at=j,则回报函数rij可以表示为式(2):
ri,j=dij+uij+qij
(2)
其中Dij表示距离因子,uij表示等待时间因子,qij为目标锚节点消息队列长度因子。下面对回报函数的三个组成因子分别进行分析。
(1)AUV移动距离
dij用来度量AUV移动距离对系统的回报,距离越大,消耗时间越多,锚节点数据传输延迟越大。归一化后,dij可表示为式(3),可以看出移动距离越小,系统回报奖励越大。
(3)
(2)AUV等待时间
为了节约能量,锚节点通常有两种状态:工作态和睡眠态。只有当AUV运动至对应锚节点通信范围内,且锚节点处于工作态时,AUV和锚节点间才能建立数据服务。如果AUV到达目标位点时,无法与锚节点建立联系,则进行等待。假设锚节点j由睡眠态切换到工作态的概率服从参数为λj的泊松分布,Tv和Tw分别表示移动节点的运动时间和等待时间,移动节点与锚节点建立服务的概率为:
pm(j)=1-(ps,j)Tv+Tw
(4)
在运动时间Tv内与锚节点j建立服务的概率为:
pmt(j)=1-e-Tvλj
(5)
移动节点在位点j处的等待时间可表示为:
(6)
对AUV等待时间归一化,可得等待时间因子uij。如式(7)所示,等待时间越短,对系统的回报越大。
(7)
(3)消息队列长度
锚节点内消息队列采用先进先出模型,设gj表示节点j的数据率,tnow为当前时间,trj为移动节点上次与j建立服务的时间,tij表示从位点wi运动至wj的时间,则两次服务间隔内生成数据包的数量nj可表示为:
nj=gj(tnow-trj+gjtij)
(8)
考虑到最大队列长度为qmax,则队列因子qij可用式(9)表示,可以看出消息队列越短,算法回报越低。
(9)
3 仿真验证
为了更好地验证本文提出的基于Q-Learning算法协议的性能,我们将该协议与基于随机游走模型的协议[8]和基于最短路径的协议[9]进行了对比。在的区域内均匀且稀疏地生成了20个锚节点,锚节点的最大传输距离为50m。每个锚节点按照泊松分布随机生成数据包,生成速率(包每秒)在0.01—0.05间,所有锚节点最多可缓存500包数据。AUV节点的运动速度范围为0.5—10m/s,AUV的最大等待时间为5s,AUV与目标锚节点建立服务的概率pm=0.8。锚节点工作态和睡眠态间的切换速度λ∈[0.05,0.07]。Q-Learning算法的折扣系数γ=0.5。
图2表示的是数据包端到端延迟与AUV运动速度之间的关系。可以看出三种协议的延迟均随AUV移动速度的增加而降低,这是因为AUV速度增加,消耗在路径上的时间相对减少,加快了数据包的转运。Q-Learning算法在AUV速度较低时延迟较大,随着AUV速度的增加,延迟逐渐降低,主要原因是较低的移动速度导致训练过程变长。
图3表示每传输一包数据AUV平均移动的距离。可以看出随着AUV速度的增加,三种协议下平均移动距离都变大,这是因为随着速度增加,AUV与锚节点建立服务的概率降低,转运数据包的数量下降。当AUV速度超过6.5m/s时,强化学习过程得到加速,Q-Learning协议的平均移动距离在三种协议中最小,能量效率最高。
图4对比了三种协议中移动AUV与锚节点成功建立服务的概率。随着速度增加,AUV在锚节点通信范围内的停留时间减少,降低了与锚节点建立通信过程的概率。基于Q-Learning算法的协议在三种协议中表现最好,成功建立服务的概率远超其他两种协议。图5给出了三种协议下AUV成功与锚节点建立服务的概率波动情况,可以看出基于Q-Learning算法的协议性能最稳定。
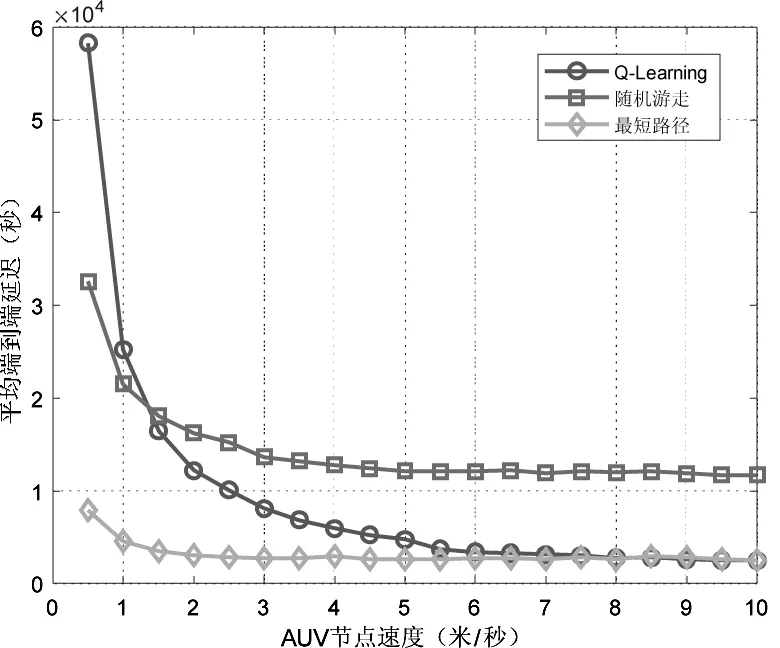
图2 平均端到端延迟
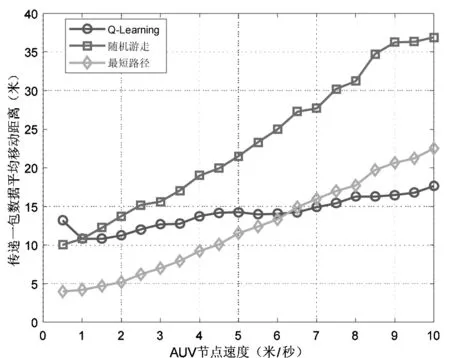
图3 AUV节点移动距离
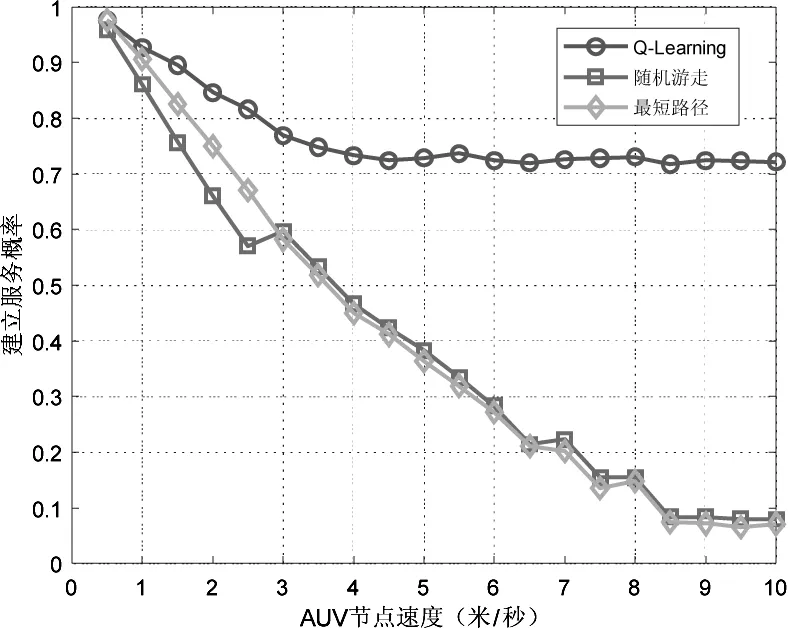
图4 AUV与锚节点建立服务的概率
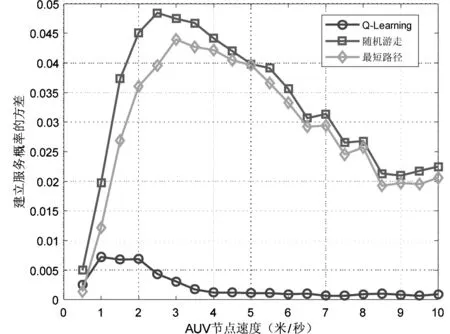
图5 建立服务概率的方差
4 结论
本文探讨了将机器学习以及深度学习技术应用于水声网络中的方法,提出了一种基于Q-Learning算法的水声网络协议,通过对比仿真验证了该算法能够有效地降低端到端延迟和平均能量消耗。
猜你喜欢
——国外课堂互动等待时间研究的现状与启示
中小学教师培训(2022年6期)2023-01-11
舰船科学技术(2022年21期)2022-12-12
舰船科学技术(2022年20期)2022-11-28
计算机与数字工程(2022年3期)2022-04-07
民用飞机设计与研究(2020年4期)2021-01-21
物联网技术(2018年8期)2018-12-06
电子制作(2017年22期)2017-02-02
电子制作(2017年19期)2017-02-02
视野(2015年14期)2015-07-28
读者(2015年12期)2015-06-19
