
基于LSTM神经网络的股票预测系统的研究
2021-05-30 10:35江柏霖兰胜杰
河北建筑工程学院学报 2021年4期
江柏霖 岳 杰 兰胜杰
(河北建筑工程学院,河北 张家口 075000)
0 引 言
随着国家经济的发展.人民所接触的新奇事物也开始增多,人民开始金融经济的投资,其中金融经济的入口之一便是股票.21世纪的今天,股票作为人民金融投资的普遍方式,如何在股票中赚钱成为中国大大小小股民的共同目标.如何赚钱便要掌握股票的走势,因此股票市场的预测工作引起了社会以及学术界的广泛关注.由于股票的走势随市场变动,又常常因为政策变化发生很大的变动,这也使得股民对于股市的走势越发难测,股民很难在股票中投资盈利[5].
人工智能在国内的快速发展,越来越多的专家学者开始研究深度学习领域相关技术,深度学习广泛应用于图像识别、图像分类、目标预测、自然语言处理、语音识别、文本分类等各个领域[8].其中目标预测对于股票走势方向能起到提升准确度的目的[1].最后发现循环神经网络(RNN)对于顺序序列数据学习处理中又表现出优于其他神经网络的性能.但是循环神经网络再处理大量数据时往往会出现对于过去数据信息遗忘太快的缺点[2],于是我们使用长短期记忆模型循环神经网络(LSTM),它在原有RNN的条件下加入了输入门,输出门以及遗忘门,这能处理好循环神经网络对于过去数据遗忘的问题,还能解决RNN梯度爆炸等一系列问题[6].我们将股票几年的走势引入RNN中进行训练,让计算机分析出股票近几年的走势习惯,从而预测出股票后几天的走势情况.`
1 相关工作
1.1 循环神经网络
循环神经网络[3]由一个输入层以及若干个隐藏层和一个输出层组成.它会先将即将训练的数据分成若干个大小相同且有先后顺序的数组.通过将这些数组有顺序的放入神经网络中训练来建立一个网络模型[7].训练过程如图1所示:

图1 循环神经网络的训练过程
X(t)表示若干个被分开数组的第t个数组.将其放入循环神经网络中训练,使得循环神经网络中的隐藏层构建起对t这个数组的描述S(t).然后输入第t+1个数组X(t+1)时.X(t+1)的输出Y(t+1)不仅受到隐藏层对t+1数组的描述(S(t+1))的影响,还受到隐藏层对之前数组的描述影响.同时RNN的隐藏层再对t+1数组做出输出时,也会在S(t)的前提下做出对t+1数组描述的改变.让一个数组前后输入具有联系性,从而对于连续数据具有独特的准确性.
然而循环神经网络在处理大量数据的训练的就表现的差强人意[4].对于数据它遗忘的太快,主要原因是在训练长数据时,前面数据的结果与后面结果差距太大而引起的梯度弥散或者梯度爆炸,如图2所示:

图2 循环神经网络处理长数据的问题
当训练长数据时,RNN最初给的结果是T,而最后的结果却是R.因为R与T差距过大引起误差.当误差大于0小于1时,误差在经过层层权值相乘改变后传到最初结果时误差已经接近于零而导致梯度弥散.当误差0于1时,误差在经过层层权值相乘改变后传到最初结果T时误差便接近无穷大而导致梯度爆炸.这些问题都能导致循环神经网络的判断出现错误.由于这些原因,我们使用了长短期记忆模型循环神经网络(LSTM)来避免误差.
1.2 LSTM循环神经网络
LSTM循环神经网络[10]对于长数据的处理得心应手.LSTM的核心思想是用每个神经元去维护一个细胞的存储信息,并设立三个逻辑门即输入门,输出门和遗忘门来控制一个细胞对信息的去除保存的控制能力正如图3所示:
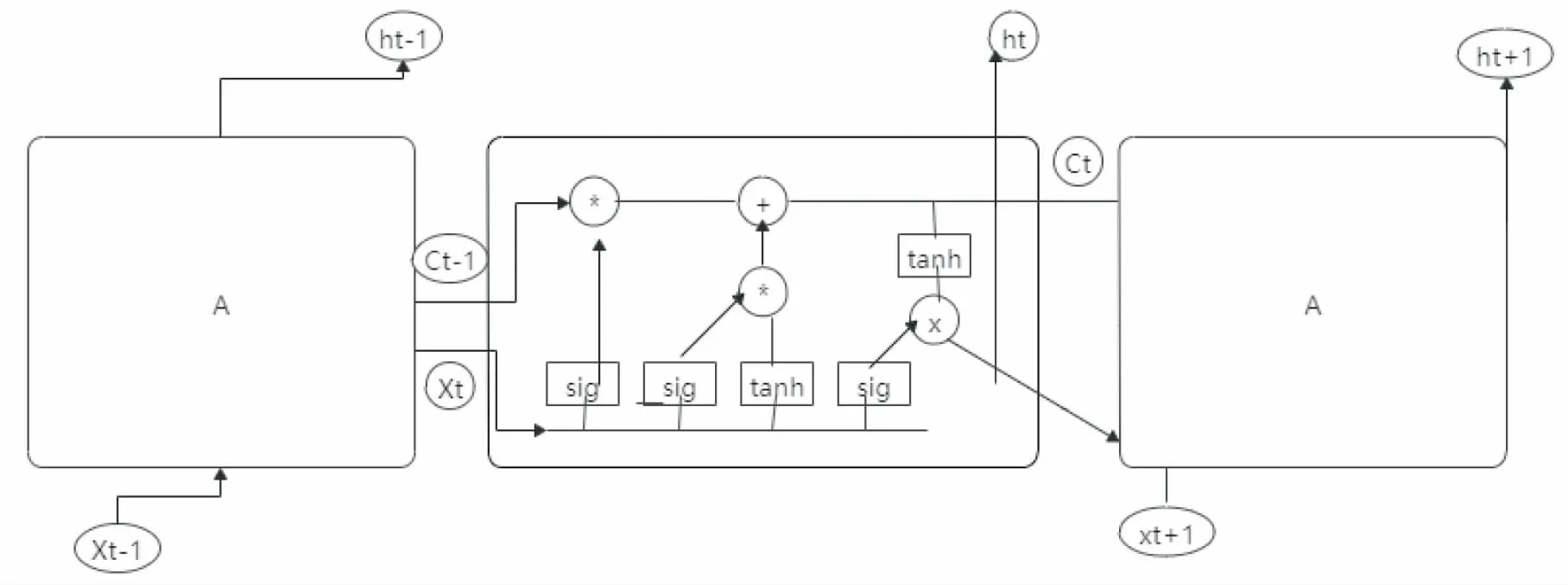
图3 LSTM循环神经网络的工作原理
其中X(t)表示t时的输入数值,h(t)表示t时的输出数值,Ct表示t时刻的它的输出状态情况.每个逻辑门按训练顺序计算过程如下:
输入门:i(t)=sigmoid(w(i)*[x(i),h(i-1)]+b(i))
(1)
C(i)=tanh(w(c)*[x(i),h(i-1)]+b(i))
(2)
式子(1)是t时的输出数值情况,式子(2)是t时输出的状态情况.i(t)决定着C(i)能否加入这个时间段的状态情况.
遗忘门:f(t)=sigmoid(w(f)*[x(t),h(t-1)]+b(f))
(3)
C(t)=i(t)*C(t)+f(t)*C(t-1)
(4)
其中式子3是遗忘门的值,对于这个状态是否保存在神经网络取决于f(t)的值.
输出门:O(t)=sigmoid(W(o)*[x(t),h(t-1)]+b(O))
(5)
h(t)=O(t)*tanh(C(t))
(6)
其中式子(5)是输出门的值,这个值决定神经网络在t时刻的输出.
当输入端口的输入对于主线状态具有重大意义时,输入门就会按照数据重要程度写入神经网络的状态中;而对于遗忘端口,当输入的数据与神经网络的状态分歧过大时,遗忘门就会将神经网络的状态做些许改变,并将输入数据按重要程度写入神经网络的状态中;输出端口的输出情况不但要受到最后一次输入网络的数据影响,神经网络的状态也对于结果又很大的影响.以此三个逻辑门控制神经网络对于数据的去除保存能力.不仅使得神经网络具有对顺序数据的记忆能力,而且还防止了因大量数据而引起的梯度弥散或梯度爆炸.对于股票数据而言,LSTM很好的解决了股票预测系统中股票数据难以预测及股票数据过长的问题.
2 我们的工作
2.1 LSTM股票预测模型的搭建
在win10系统下实验选择搭建CUDA来进行并行计算,它使得GPU做出内部并行运算,从而能完成很多复杂的计算问题.GPU的特点是集成大流量处理器和计算单位,用于处理并行运算的过程中具有很大优势,很适合用来处理神经网络中的大规模计算.模型方面我们采用Sequential模型.因为Sequential模型构成栈的方式是用网络层依次按顺序进行,它能使得输入和输出之间具有一定的联系,每层之间也具有相邻关的系.应用与顺序数据较为合适.
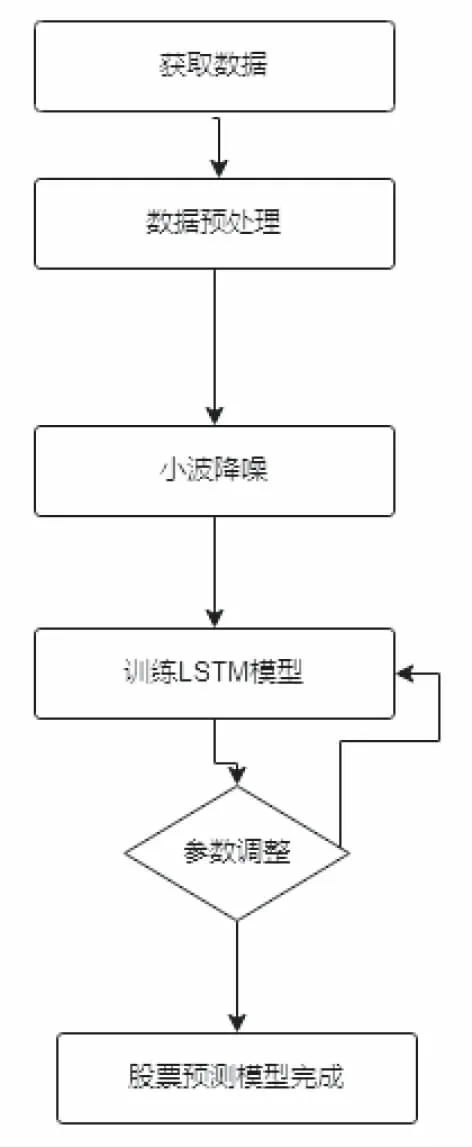
图4 实验流程图
使用Sequential模型进行实验,分别搭建一层两层三层隐藏层来对同一支股票进行训练,由于股票跳动不是特别剧烈,本次实验采用LSTM与全连接的连接方式.将股票接近两年的数据情况引入神经网络.数据包括股票的开盘、收盘、最高点、最低点、成交量、成交额、换手率这8个数据为输入端口,其中实验以28天为一次训练,以第二天的开盘、收盘、最高点、最低点、成交量、成交额作为标签.用这些标签来对神经网络的输出作出损失的调整.使用Adam优化器进行优化,来防止数据走向过拟合,使用L2正则化项和dropout机制来提高模型的泛化能力.
2.2 实验及其分析
本次实验过程按照获取数据、对数据进行预处理、对数据进行降噪、神经网络模型的训练、调整相应的超参以及股票预测这几步来完成.
数据获取方面,我们使用python在网站上爬取GQY视讯2018年到2020年关于开盘、收盘、最高点、最低点、成交量、成交额、换手率等顺序数据.
数据预处理方面,因为获取的原始数据存在乱序或缺值我情况,实验使用插值、排序等操作得到GQY视讯股票十年的顺序数据.一共600多条包含开盘、收盘、最高点、最低点、成交量、成交额、换手率的数据.
对于数据降噪,实验使用小波降噪来去降低数据的噪声.
微调参数方面,实验通过不断的训练,在训练中进行参数的调整,每次调整与前几次最高性能的参数做对比,选出最好的实验参数.流程如图4所示.
(1)第一次实验使用一层隐藏层的LSTM神经网络模型来对股票做出预测.将GQY视讯2018年到2020年的数据放入神经网络中进行训练.其中设置输入层八个神经元,隐藏层设置64个神经元、输出层设置8个神经元.将股票以28天为一次训练,以股票的开盘、收盘、最高点、最低点、成交量、成交额、换手率作为输入.实验每过四天抽取一次损失值,其损失函数的走向如图5所示:
在以真实值的收盘与测试值的收盘做对比,其走向如图6所示:

图5 损失函数走向

图6 真实值的最高与测试值的最高走向
可以得出随着训练次数的推移,LSTM神经网络的它的损失值在不断变小,真实值与测试值的走向在步步逼近.
其次我们设立两层LSTM神经网络的隐藏层和一个全连接层模型,其中两层隐藏层的它的神经元个数都设置为64,并采用和第一次实验相同的输入值和测试值得出的实验结果如图7所示:
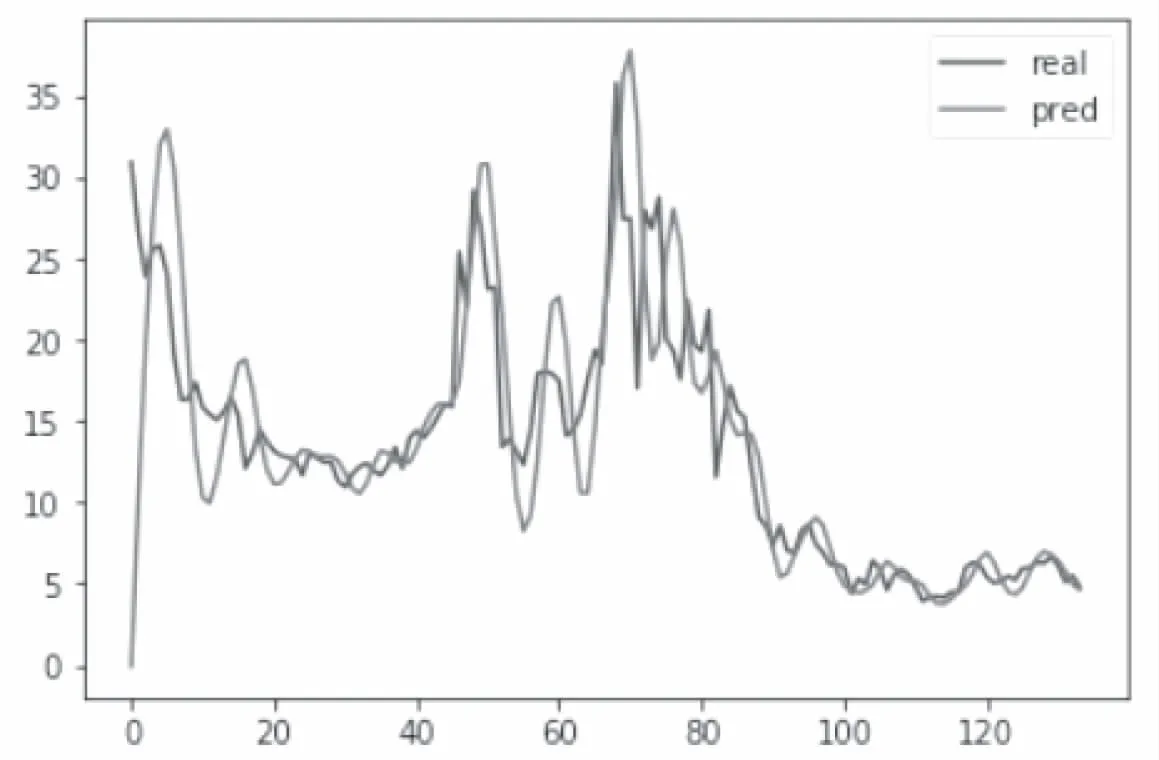
图7 真实值最高与测试值最高的走向
从第二次实验结果可以看出,两层的LSTM神经网络隐藏层模型的预测性能得到了很大的提升,图7展示的数值拟合度速度要高于图6展示的数值拟合度速度,并且在图7真实值和测试值的走向更加的逼近.证明了LSTM神经网络用于处理股票这类顺序数据的优越性.
实验可以通过增加隐藏层来增加模型的准确率来把握数据走势,但是当隐藏层增加到四层时,预测准确率却只提升了0.02%.还增加了很多计算的冗余.再增加多层对于预测的准确率提升也微乎其微.所以实验建议使用三层隐藏层的LSTM网络模型来进行股票预测,它对于股票预测的准确度上表现良好,对于计算产生的参数消耗上也有不错的表现.
3 结束语
本次实验通过对股票的数据使用小波降噪、应用L2正则化项和dropout来提高LSTM神经网络针对于股票预测它的适应性,通过实验调整微参和隐藏层神经元个数,来对GQY视讯股票进行预测.最终使得真实值与测试者的走向步步逼近,使得股票预测更加娴熟.之后会找寻更好的预测模型,希望能再次提高股票预测的准确度.从而让股民在选择股票投资方面有更多更好的参考.
猜你喜欢
现代电力(2022年2期)2022-05-23
电脑报(2022年13期)2022-04-12
电脑报(2020年24期)2020-07-15
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
电脑爱好者(2017年22期)2017-12-04
北京航空航天大学学报(2017年12期)2017-04-23
股市动态分析(2016年23期)2016-12-27
股市动态分析(2016年22期)2016-12-27
股市动态分析(2016年7期)2016-09-29
