
基于多智能体强化学习的物流配送路径调度策略
2021-05-29 02:01:12齐晗
萍乡学院学报 2021年6期
齐 晗
基于多智能体强化学习的物流配送路径调度策略
齐 晗
(安徽电子信息职业技术学院 经济管理学院,安徽 蚌埠 233030)
为优化物流系统的配送路径,课题组提出了基于多智能体强化学习的配送路径调度(Multi-agent Reinforcement Learning based Routing Scheduling,MRLRS)策略。MRLRS策略将配送路径调度视为路径生成过程,采用了具有注意层的编码器-解码器框架来迭代生成物流的配送路径,并为模型训练设计了一种具有无监督辅助网络的多智能体强化学习方法。使用模拟实验对MRLRS策略进行评估,实验结果表明,提出的MRLRS策略的性能要优于现有的方法。
物流配送;强化学习;路径调度优化
经济技术的发展和国际经济贸易往来的日益扩大,促使全球物流需求快速增长,我国快递市场在2021年获得多达1083亿份订单。物流业的快速发展给物流管理和调度系统的实时运行带来了前所未来的挑战。因此,研究物流系统配送路径调度问题就成为一个重要课题。在物流配送中,多个客户将由容量有限的车队服务,车队管理者的目标是在特定服务约束下最小化服务成本。从仓库出发的车队需要在特定的时间窗口限制内服务拥有不同需求的客户。当违反给定的时间窗口时,车队管理者会受到相应的处罚,所以配送路径调度是一个复杂的问题,针对此类问题设计一种快速、可靠的解决方案是极具挑战性的。当前主流的启发式算法难以在短时间内解决需求激增的问题,导致这类算法无法支持大规模应用。基于机器学习的方法由于其出色的学习能力在众多研究领域中受到越来越多的关注[1–2]。其中,由于深度强化学习算法能学习解空间特征并建立参数化计算图来模拟原始问题的约束,因此其在解决复杂的时间相关问题方面表现出强大的能力[3]。深度强化学习为动态环境中的优化决策提供了一个通用框架,有助于解决组合优化问题[4]。
本文提出了基于多智能体强化学习的路径调度(Multi-agent Reinforcement Learning based Routing Scheduling,MRLRS)策略,构建了一个具有多头注意力层的编码器-解码器框架,利用深度强化学习策略来确定模型参数。
1 多智能体模型
1.1 路径调度优化建模

1.2 MRLRS框架设计
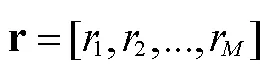

其中,是表示时间步t除以车辆编号的余数,表示在时间步t为车辆选择客户的概率,是指已在时间步得到服务的客户。
2 编码器-解码器框架设计
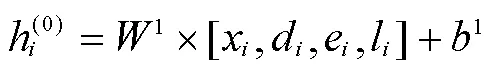
使用多个注意力层更新嵌入,每个注意力层执行多头注意力和前向操作。注意力机制可以解释为图中客户之间的加权消息传递算法。客户从其他客户那里收到消息的权重取决于其查询与其他客户的密钥的兼容性。单个注意函数由下式给出:
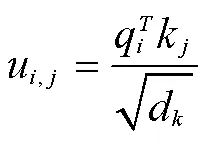

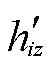

注意力层的其余部分是带有跳跃连接的前馈操作:




在解码器部分,需要定义状态、动作空间和奖励,并通过深度神经网络对每个代理进行建模。将车辆视为从环境和彼此感知状态的代理,车辆根据通过感知获得的知识来决定一个动作序列。采取的行动会影响环境,因此会改变代理所处的状态。DRL系统中的每个代理都有一个必须达到的目标状态,代理的目标是通过学习一个好的策略来最大化长期奖励。
2.1 状态
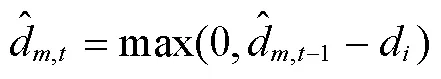
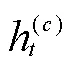

2.2 动作


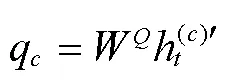
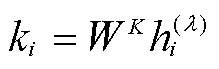

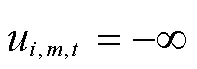
通过softmax函数计算在时间步为车辆选择客户的概率,即:
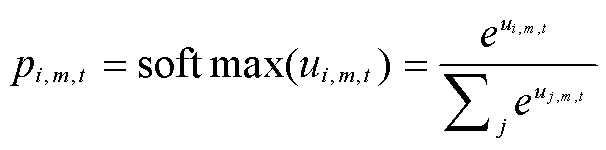
2.3 奖励
奖励函数是强化学习问题的目标,其奖励函数如下式所示:
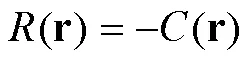


3 实验评估
在10×10的范围内随机生成了仓库的位置,客户的数量分别为[20,50,100],车辆的容量分别设置为[60,150,300],时间窗口分别服从[0,10]、[0,20]和[0,40]的均匀分布。早到和迟到的惩罚系数分别服从[0,0.2]和[0,1]的均匀分布。每个客户对两辆车的需求服从[0,10]的均匀分布,对三辆车的需求服从[0,15]的均匀分布,四辆车的需求服从[0,25]的均匀分布,五辆车的需求服从[0,25]的均匀分布。实例的数量为1000。
实验部分将MRLRS与两种经典的启发式方法(即遗传算法和局部搜索算法)[5]和主流的ortools优化工具[6]进行比较。遗传算法(GA)是一种基于类似于生物进化的自然选择过程来解决有约束和无约束优化问题的方法。遗传算法从当前人口中随机选择个体作为父代,并使用父代产生下一代。采用两组参数:GA-100的种群大小为100,最大迭代次数为300;GA-300的种群大小为300,最大迭代次数为1000。交叉率设置为0.80,突变率设置为0.05。局部搜索算法(LS)从一个可能的解决方案迭代地移动到相邻的解决方案,直到获得可能的最佳结果集。局部搜索算法可以避免陷入局部最优。采用两组参数:LS-100的最大迭代次数为100,LS-500的最大迭代次数为500。ortools是一个用于优化的开源软件套件,是一种广泛使用的车辆路径问题和约束优化求解器。
在训练MRLRS的过程中,将学习率设置为0.0001,使用随机生成的数据对模型进行了 100个epoch的训练。每个epoch处理了64000个实例,批处理大小设置为 512。实验环境的配置为:具有11GB内存的NVIDIA GeForce RTX 2080Ti Founders Edition,具有96GB内存,处理器为英特尔志强E5-2673。MRLRS模型是使用Pytorch实现。编码器中初始客户嵌入层的维度设置为128,层数为3,注意头数为8。
图2展示了不同规模下每种方法的总成本和时间。由结果可知,在小规模场景中(客户数量为20),所有方法的成本相差不大。但是,当问题规模增大(客户数量增加)时,与其他算法相比,GA的性能越来越差,ortools的性能仅次于MRLRS,LS的整体性能均优于GA。在大多数情况下,提出的MRLRS在降低总成本和提高计算效率方面都要优于其他方法。
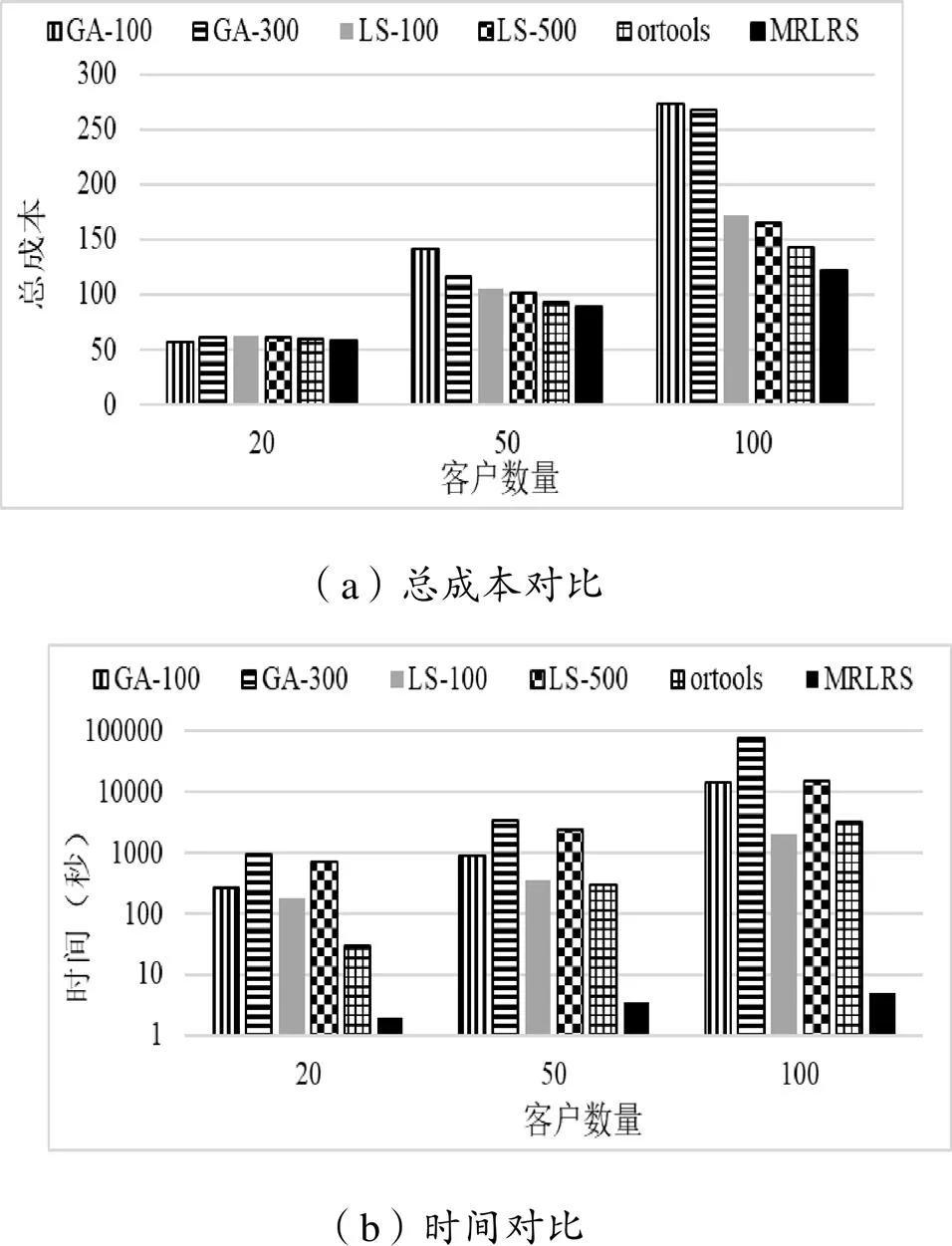
图2 不同规模下每种方法的总成本和时间
接下来分析了编码器中初始客户嵌入的维度和编码器层数对MRLRS的影响。通过将客户嵌入的维度分别设置为64和256来重新训练网络,并评估相应的性能,结果如图3所示。由于低维空间可能会忽略有用信息,因此随着嵌入维度的增加,模型能更快地收敛。
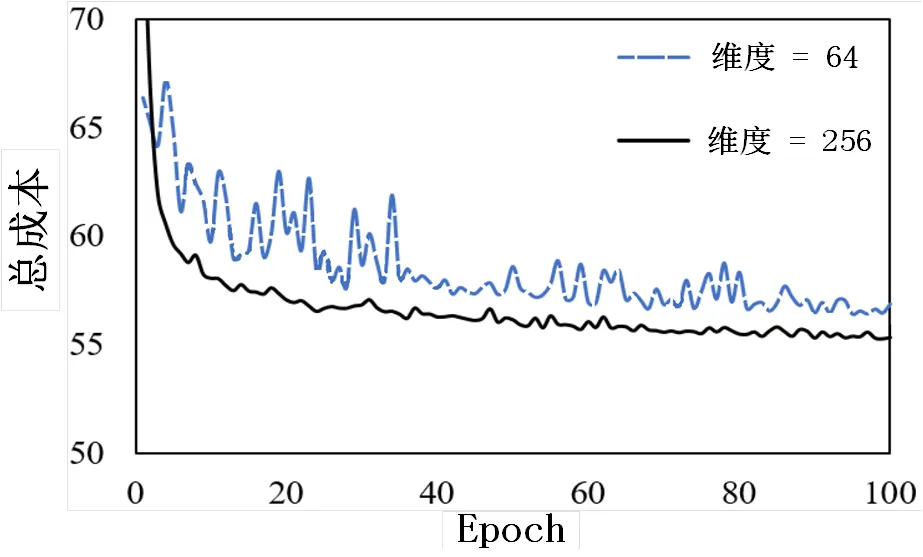
图3 客户嵌入维度对训练的影响
本文分别将编码器层数设置为2、3、4进行重新训练,奖励曲线如图4所示。由结果可知,层数较少的编码器难以捕捉客户之间的信息,而层数较多的编码器并不一定可以获得较好的结果。

图4 编码器层数对训练的影响
4 结论
本研究提出了MRLRS,一种用于配送路径调度的强化学习算法。由模拟实验结果可知,与现有方法相比,提出的MRLRS能获得最好的性能,同时具有最低的开销,这表明提出的MRLRS在解决方案的质量和效率方面都具有优越的性能。在未来的研究工作中,将扩展MRLRS,使其适应具有多个站点、多个周期和异构车队等的应用场景,并优化MRLRS以提高解决大规模路径调度问题的效率。
[1]Shinde P P, Shah S. A review of machine learning and deep learning applications[C]//2018 Fourth international conference on computing communication control and automation (ICCUBEA). IEEE, 2018: 1–6.
[2] Avola D, Cinque L, Foresti G L, et al. VRheab: a fully immersive motor rehabilitation system based on recurrent neural network[J]. Multimedia Tools and Applications, 2018, 77(19): 24955–24982.
[3] Zhang C, Patras P, Haddadi H. Deep learning in mobile and wireless networking: A survey[J]. IEEE Communications surveys & tutorials, 2019, 21(3): 2224–2287.
[4] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题[J]. 自动化学报, 2020, 46(7): 1301–1312.
[5] Katoch S, Chauhan S S, Kumar V. A review on genetic algorithm: past, present, and future[J]. Multimedia Tools and Applications, 2021, 80(5): 8091–8126.
[6]Sarkar C, Paul H S, Pal A. A scalable multi-robot task allocation algorithm[C]// 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018: 5022–5027.
Logistics Distribution Route Scheduling Strategy Based on Multi-Agent Reinforcement Learning
QI Han
(School of Economics and Management, Anhui Vocational College of Electronics & Information Technology, Bengbu, Anhui 233030, China)
Aiming at the distribution route optimization problem in the logistics system, the paper proposes a Multi-agent Reinforcement Learning based Routing Scheduling (MRLRS) strategy. The MRLRS strategy regards delivery route scheduling as a route generation process, proposes an encoder-decoder framework with attention layers to iteratively generate logistics delivery routes, and designs a multi-agent reinforcement with unsupervised auxiliary network for model training study method. The MRLRS strategy is evaluated using simulation experiments, and the experimental results show that the proposed MRLRS strategy outperforms the existing methods.
logistics distribution; reinforcement learning; route scheduling optimization
TP391 文献志识码:A
2095-9249(2021)06-0077-04
2021-12-10
安徽省人文社科重点项目(SK2021A1062);安徽省质量工程项目(2020SJJXSFK0238)
齐晗(1984—),男,安徽枞阳人,讲师,硕士,研究方向:现代物流管理。
〔责任编校:吴侃民〕
猜你喜欢
东北水利水电(2022年6期)2022-06-28 06:04:36
康复(2022年31期)2022-03-23 20:39:56
工程与建设(2019年5期)2020-01-19 06:22:26
电子制作(2019年11期)2019-07-04 00:34:50
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
中学生数理化·高二版(2017年3期)2017-07-07 08:47:25
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
小天使·五年级语数英综合(2015年4期)2015-04-20 06:03:23
电测与仪表(2014年13期)2014-04-04 12:04:18
