
一种基于深度学习的Docker风险预测方法研究
2021-05-28 09:16邵思思尧海昌杨卫东刘尚东季一木
南京邮电大学学报(自然科学版) 2021年2期
邵思思,李 奎,尧海昌,杨卫东,尤 帅,刘 强,2,3,4,刘尚东,2,3,4,季一木,2,3,4
(1.南京邮电大学计算机学院,江苏 南京 210023 2.南京邮电大学江苏省无线传感网高技术研究重点实验室,江苏 南京 210023 3.南京邮电大学高性能计算与大数据处理研究所,江苏 南京 210023 4.南京邮电大学高性能计算与智能处理工程研究中心,江苏 南京 210023)
近几年,云计算作为一种新型的计算形式快速地发展起来,它是以虚拟化机制为核心,以Internet为载体,以规模的计算、存储和数据资源组成的信息资源池为支撑,按照用户需求动态地提供虚拟化、可伸缩的信息服务[1]。 在早期计算领域中[2],虚拟机(VM)是云计算环境中的常用资源。对于云服务提供商,虚拟机有助于提高硬件资源的利用率。对于云客户,它支持提供弹性资源并提供一系列服务集合。 但随着Docker技术[3-4]的发展,传统部署带来的问题越来越严重,因为多个应用对运行环境的要求不同,导致应用部署产生了很多麻烦[5-7]。 由传统虚拟机集群为基础的云计算集群逐渐转变为以Docker物理节点为集群的方式。Docker是一种轻量级、可移植、自包含的软件打包技术,使应用程序可以几乎在任何地方以相同的方式运行[8]。Docker采用客户端/服务器(C/S)的架构模式,客户端向服务器发送请求,服务器负责构建、运行和分发容器。
随着Docker应用的规模越来越大,领域越来越广泛,人们越来越关注容器安全方面的问题[9-12]。这不仅仅是一个技术性问题,更是一种意识性问题。Docker目前已经在安全方面做了一定的工作,包括Docker daemon在以TCP形式提供服务的同时使用传输层安全协议;在构建和使用镜像时验证镜像的签名证书;通过cgroups及namespaces对容器进行资源限制隔离;提供自定义容器能力(capability)的接口等。如果合理地应用上述方法,可以有效提高Docker容器的安全性。国内已经有很多关于容器安全方面的工作,但主要还是分布在如何从底层提升Docker安全性而忽略了 Docker镜像这一环节[13]。恶意用户可以尝试在Dockerfile文件中添加恶意命令,如反弹shell或引入存在漏洞的应用等造成Dockerfile攻击。文献[14]系统分析了 Docker Hub上的30万个镜像,发现平均每个镜像有180个漏洞,大多数镜像不会修复这些漏洞并且父镜像会向子镜像传播这些漏洞。文献[15]分析了全球133个公开Docker仓库中最大的91个仓库,用Clair扫描仓库中的镜像,其中存在明显漏洞的占24%,高风险等级的漏洞占11%。Clair是目前最流行的镜像扫描工具,主要模块分为Detector、Fetcher、Notifier和Webhook,Clair首先对镜像进行扫描,然后再将这些特征匹配CVE漏洞库,若发现漏洞则进行提示及修补。但是Clair只能对Docker镜像进行检测,无法检测Dockerfile文件,从源头控制风险也无法提前检测可能存在的安全风险。
因此,针对如何有效提高Docker镜像的安全,从源头控制风险,提前检测Docker镜像可能存在的漏洞,从而进一步提高Docker容器的安全问题,本文提出了一种基于深度学习的Docker风险预测框架和算法,本文主要有以下两方面贡献:
(1)提出了一种基于深度学习的Docker特征提取风险预测框架。该框架从镜像的源头对Docker进行风险控制。可以准确预测Dockerfile的风险性,减少Docker镜像的漏洞。
(2)提出了一种基于深度学习的Docker风险预测(DRPA)算法,该算法利用深度学习神经网络对训练数据集中的Dockerfile文件进行语义和结构特征的提取以及概率预测,将待检测的Dockerfile文件输入到训练好的网络模型中进行预测,判断其是否具备风险,并返回其风险概率。结合容器集群放置方法,从而进一步保证了容器的安全。
1 相关工作
目前Docker安全的保证主要依赖于3种Linux内核安全机制:namespace负责构建资源隔离环境,确保Docker容器有更严格的安全性机制;cgroups主要确保每个容器可以获得公平的系统资源;capability用于增强容器控件内的权限,从而隔离容器内外之间的根权限。加强Linux容器安全性的最有效方法是在内核级强制执行强制访问控制(MAC),以防止在主机和容器端进行不必要的操作,使用的工具包括 AppArmor[16]或 SELinux[17]。文献[18]针对Docker平台上的Dos攻击,提出了一种安全策略和实验方法,加强访问控制、身份验证和授权解决以应对Dos攻击。文献[19]提出了一种为不同的容器化进程引入特定SELinux类型且对用户透明的方式,在主机中安装DockerPolicyModules(DPM)模块,避免Docker镜像在主机系统中安装SELinux模块时出现威胁,从而提高Docker的安全性。文献[20]提出了一种通过执行访问策略来保护Docker容器的整个生命周期的用户友好机制,该机制为每个容器自动创建AppArmor配置文件,在Docker的安全默认值之上增加了一个额外的安全层;此外,给定应用程序工作负载,通过生成动态安全配置文件来增强Docker容器安全性。文献[21]认为内核漏洞是操作系统安全面临的最大威胁之一,因此提出了一种基于名称空间状态检测的防御方法,该方法能够检测异常过程并防止逃逸行为,确保容器在运行期间受到保护和监视。以上研究工作都是集中于如何从底层提升Docker安全性,在一定方面有效地提高了Docker容器的安全性,但这些研究工作都忽略了Docker镜像在Docker安全中的重要性。为了保证镜像安全,Docker Hub在最近发布的Docker数据中心中提出了一个签名机制,他们构建了一个基于更新框架(TUF)和Docker内容信任(DCT)的签名基础结构,允许管理员设置签名策略,防止使用不受信任的内容。文献[13]针对Docker存在的容器及镜像被篡改问题,构造了一条利用可信计算相关技术的信任链,设计了一种分层式数据安全防护系统,以提高对Docker镜像的全方面安全防护。虽然这些方法在一定程度上有效地提高了Docker镜像运行的安全性,但却没有对Docker镜像本身进行安全加固,也无法提前检测Docker镜像可能存在的安全风险。
目前已经有很多机器学习算法被用于文本特征提取,利用深度学习对文本进行特征提取也得到越来越多的应用,常用于自然语言处理的问题。文献[22-23]分别提出了一种基于深度信任网络(DBN)进行软件缺陷预测的方法和一种通过卷积神经网络(CNN)进行软件缺陷预测的框架,通过对程序源码提取特征与传统方式相结合的方式来预测程序是否存在错误,大大降低了软件缺陷中的错误率。因而利用深度学习算法从Dockerfile文件中提取特征并预测概率成为可能。
综上所述,已有的Docker安全加固方法虽然在一定程度上保证了Docker容器的安全可靠运行,但却无法从源头控制风险,降低Docker镜像的漏洞,从而进一步确保Docker容器的安全。
2 DRPA框架设计
基于深度学习的Docker风险预测框架如图1所示。

图1 基于深度学习的Docker风险预测框架
该框架主要包括4个模块:数据预处理模块、文件检测模块、镜像放置模块和容器集群模块。数据预处理模块根据训练集对Dockerfile文件进行语义和结构的特征提取并预测其风险概率;文件检测模块利用训练好的网络模型对待检测的Dockerfile文件进行预测是否具有风险并评估风险等级,然后由用户决定是否放置到容器集群中;容器集群模块根据文件检测模块的结果决定放置方式,对Docker镜像进行放置。
基于深度学习的Docker风险预测框架各模块的具体步骤如下:(1)数据预处理模块。首先对Dockerfile文件进行解析,生成抽象语义树,并从中生成Token向量,进一步对向量标准化,将结果输入深度学习网络中,从而得到Dockerfile文件的语义特征和结构特征,并得到Dockerfile文件风险特征概率。(2)文件检测模块。当待检测的Dockerfile文件进入后,首先通过步骤(1)训练好的网络模型,提取到Dockerfile文件语义和结构特征,然后通过模型进行预测其是否具备风险,并返回其风险概率。(3)如果该Dockerfile文件被标记为具有风险,则进行提示并决定是否放置,如果不放置则进行风险处理,否则使用风险控制放置算法将由Dockerfile文件生成的镜像放置到集群中,如果Dockerfile文件被标记为无风险,则通过容器集群进行负载均衡放置。(4)容器集群。容器集群负责镜像的接收和处理,决定使用基于风险控制的放置算法或者负载均衡对镜像进行放置,容器集群为容器安全检测的处理对象。
3 基于深度学习的Docker风险预测(DRPA)算法
本节主要分为风险预测算法的模型构建和Dockerfile文件的风险预测两个部分,其中风险预测的模型训练是利用CNN⁃FPN深度学习模型提取Dockerfile文件的语义和结构特征并进行风险概率预测;Dockerfile文件的风险预测是利用训练好的神经网络模型对Dockerfile文件进行分类预测,然后结合容器集群放置方法将Docker镜像放置到集群中。
3.1 基于CNN⁃FPN网络的Dockerfile风险预测算法模型构建
抽象语法树(AST)是一种以树的形式充分体现代码语法和语义结构的抽象表示[22]。树上的每个节点都是代码中的一种结构。在Dockerfile文件中,局部的微小差别就可能导致巨大差异,甚至存在巨大漏洞。深度学习架构可以有效地捕获复杂性高的非线性特征。利用深度神经网络可以从Dockerfile文件的AST中提取Token向量并从中学习语义和结构特征。卷积神经网络(CNN)可以更好地捕获局部的差异,因此 CNN能够更好地检测局部模式[23]。CNN已经被充分地证明适应于图像分类、自然语言处理等领域,近些年常被用于文本的分类,对于英语文本数据的分类有很好的效果,在大部分的数据集上的分类准确性都超过了传统的SVM等模型。CNN的稀疏连通性和共享权重两个关键特征可以帮助更好地从Dockerfile文件中获取到其语义和结构特征。但通常情况下CNN网络结构中对应的stride一般比较大,会忽略待检测文件中小物体的检测,导致小物体检测性能急剧下降。因此引入特征金字塔网络(FPN),解决检测中的多尺度问题,通过对CNN网络进行简单的网络连接改变,在不增加原有模型计算量的情况下,通过对高层网络特征进行上采样和低层网络特征进行自顶向下的连接及每一层都进行预测的方法,提升小物体的检测性能。由此可见,FPN可以在CNN网络结构的基础上进一步获取更加准确的Dockerfile文件语义和结构特征,从而提升检测的准确率。
基于CNN⁃FPN网络的Dockerfile文件风险预测算法首先需要将Dockerfile文件解析为AST,然后选择AST上关键节点形成Token向量,由于CNN⁃FPN的输入形式是整数向量,进一步对Token向量进行统一标准化,将其转化为整数向量,最后将整数向量输入到CNN⁃FPN中。CNN⁃FPN会根据输入的向量自动生成Dockerfile文件的语义和结构特征。基于CNN⁃FPN网络的Dockerfile文件风险预测工作流程如图2所示。
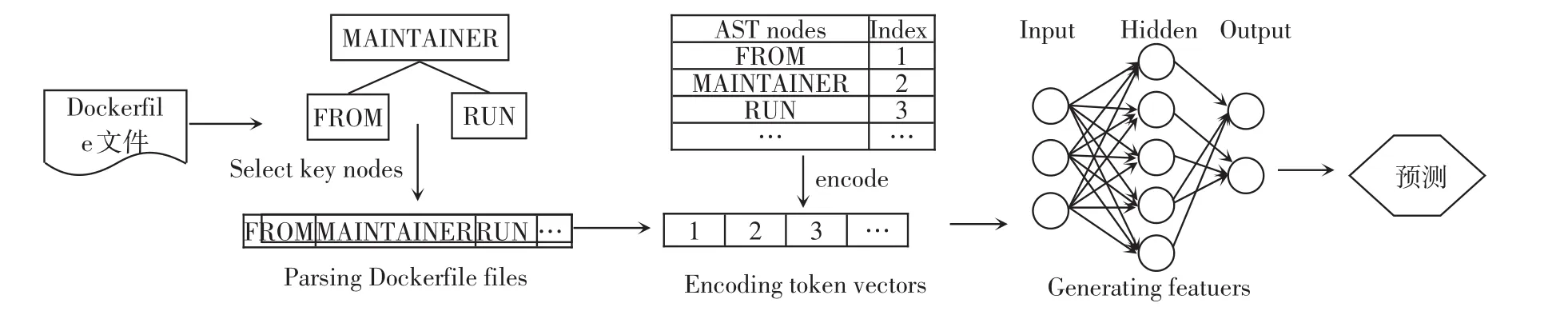
图2 基于CNN⁃FPN网络的Dockerfile文件风险预测工作流程
解析Dockerfile文件:为了CNN⁃FPN网络结构能够有效地捕获复杂性高的非线性特征,首先对Dockerfile文件中的信息进行筛选,以区别重要的语义和结构信息。为了将每个Dockerfile文件表示为向量,只有AST上的节点才是构建Dockerfile文件表示的合适粒度,既保留了语法信息又保留了结构信息。选择 Dockerfile文件中重要指令集包括FROM、RUN、CMD、apt⁃get等和控制流节点如 if、for等作为Token向量。排除不属于以上类别的AST节点,因为添加它们可能会减弱其他节点的重要性。通过上述操作,将每个Dockerfile文件转换为Token向量。如图3所示,是一个简单的Dockerfile文件。其 Token向量为{[FROM][MAINTAINER][RUN][echo][RUN][apt⁃get][RUN][echo][CMD]}。

图3 Dockerfile文件
Token向量标准化:由于CNN需要数值向量形式作为输入,并且输入向量长度必须相同。所以提取的Token向量无法直接作为CNN的输入。为了解决此问题,首先在Token向量和整数之间进行映射,对Token向量进行标准化,将Token向量编码为整数向量。每个Token向量对应唯一的整数标识符,即不同的指令或控制流节点对应不同的整数标识符,整数标识符从1开始至Token向量类型的总数结束。由于不同的Dockerfile文件内容不同,所以提取到的Token向量长度不同,向量进一步标准化后得到的整数向量长度不同,因此在每个整数向量后添加0作为补充,使它们的长度与最长向量一致。图3的Dockerfile文件对应的整数向量为{[1][2][3][4][3][5][3][4][6]}。 通过此方法得到的整数向量可以输入CNN模型并且保持了原有Token向量顺序不变,保留了原本的结构信息。
建立 CNN⁃FPN网络模型:要区分安全的Dockerfile文件和存在安全漏洞的Dockerfile文件的语义和结构特征,首先需要训练数据来构建CNN⁃FPN模型输出其特征,即训练CNN⁃FPN中的权重和偏差。CNN⁃FPN训练分为“自底向上”过程和“自上而下”过程,其中“自底向上”过程是指神经网络普通的正向传播,特征图经过卷积核和最大池化操作不断缩小;“自上而下”过程是对高层网络的特征图进行上采样操作,然后将上采样得到的特征横向连接上一层空间大小相同的特征图并进行预测,这样一方面加强了高层特征,另一方面每一层的预测都融合了不同分辨率,可以完成不同大小分辨率的检测,保证每一层都有合适的强语义和结构特征。
网络模型使用Inception Net网络结构,一层可能会有多个尺寸的卷积核,在同一个位置但在不同通道的卷积核输出结果相关性极高。在同一个空间位置,不同通道的特征结合起来。而不同尺寸的卷积核可以保证特征的多样性。使用Word2vec词嵌入作为第一层,它将整数转换为固定大小的实值向量。简单索引不会携带太多有关从AST中提取的Token向量的上下文信息。词嵌入根据每个Token向量的上下文进行训练,每个Token都要学习一个特征向量,并且出现在相似上下文中的令牌往往由相似的向量表示,这些向量表示在特征空间中的距离很近。CNN⁃FPN特征提取过程如图4所示。

图4 CNN⁃FPN网络风险预测过程
假设CNN⁃FPN网络输入的是矩阵A,经过F1个卷积核(i=1,2,…,F1)的卷积生成F1个特征图,其中 conv2(A,B′,valid′)被称作窄卷积,为该层的激活函数。

接着,进入最大池层进行池化操作,由于池化又称下采样,所以用S=βdown(C)+b表示。
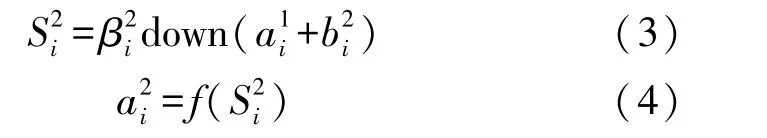
然后,对特征图进行上采样操作,此处使用最邻近元法,将距离待求点最近的临像素灰度赋予待求点。将上采样得到的特征图与上一层空间大小相同的特征图进行横向连接。
重复上述操作,直到进入全连接层,将最后得到的顺序展开成向量,有序连接成一个长向量,作为全连接层的输入。
为了让神经网络具有非线性的拟合能力,在每一层的输出后面都添加一个激活函数,其中输出层使用Sigmoid激活函数,见式(5),其余层使用ReLU激活函数,见式(6)。使用反向传播与梯度下降优化调整CNN⁃FPN网络中的参数。通过Keras快速地构建神经网络。得到CNN⁃FPN网络后,将测试数据向量化后的整数向量输入到CNN⁃FPN网络中,然后CNN⁃FPN的输出层获得测试文件的存在安全风险概率。

3.2 基于Dockerfile文件的风险预测
预测主要分为两部分:待检测Dockerfile文件输入到训练好的网络模型中预测的风险概率;根据风险概率将Dockerfile文件通过不同的方式放置到集群中。具体来说,首先将测试数据集中的Dockerfile文件输入到训练好的CNN⁃FPN网络模型中进行风险预测并返回风险概率,如果该Dockerfile文件不存在风险或风险概率极低,生成Docker镜像后可以通过负载均衡放置到集群中,如果该Dockerfile文件风险概率较高,会进行风险提示。如果用户决定不放置,则进行风险处理,否则通过一定的风险控制放置算法改进Docker集群分配策略,从而使具有风险的容器难以与安全容器共同定位,提高容器集群整体的安全性。
Dockerfile文件风险预测:首先通过上述的特征提取方法对待检测的Dockerfile文件进行处理,将其解析为AST树,提取其Token向量并进行向量标准化;然后将处理后的向量输入到构建好的CNN⁃FPN网络,CNN⁃FPN网络经过内部计算会返回用户该Dockerfile文件是否存在风险及其概率,并提示用户进行风险处理。
风险控制放置:当待检测的Dockerfile文件通过CNN⁃FPN网络,判断其是否具备风险并输出其风险概率后,如果Dockertfile文件不存在风险或风险较小,集群会通过负载均衡将容器放入。如果Dockerfile文件风险较大,会进行风险提示,并且如果决定对镜像进行放置,则会通过一定风险控制放置(PSSF)算法放入到集群中,该风险控制放置算法[24-25]定量描述了集群安全性、工作负载、能耗之间的关系,如式(7)所示,不仅大大降低了存在风险的容器与其他安全容器共存的可能性,而且可以满足工作负载平衡和能耗方面的限制。
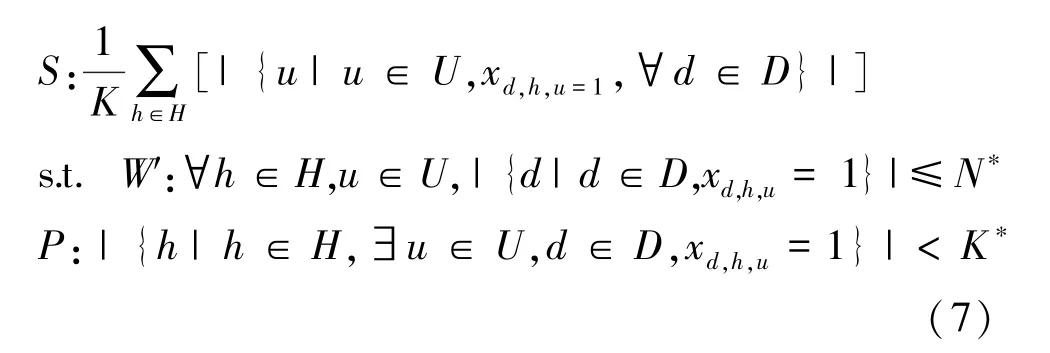
其中,S表示安全性,W′表示工作负载,P表示能耗。在K个主机H={h1,h2,…,hK}的云计算系统中,M个用户U={u1,u2,…,uM},启动N个容器D={d1,d2,…,dN}。如果将每个用户的容器分配到特定的主机上,XD×H×U-{xd,h,u|xd,h,u-1,if Dockerdof useruis allocated to hosth}。N∗和K∗为预先确定的阈值。
4 实验
4.1 实验环境
1台基于x86平台的物理服务器,配置参数为Intel Core i7 CPU 3.7 GHz、32 GB内存以及千兆网卡;在该物理服务器上采用VMware Workstation Pro进行虚拟化,共虚拟出3台主机,具体配置和功能如表1所示。
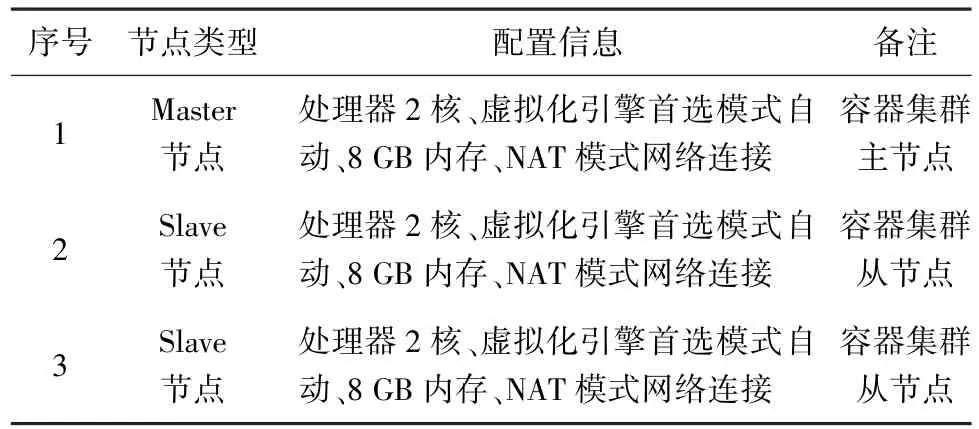
表1 虚拟机配置和功能
为了保证数据的客观性,本实验用爬虫从GitHub上采集了3 183个Dockerfile文件,经过初步排重,共计有效Dockerfile文件2 706个,包含不同类型和版本的Dockerfile文件。本实验采用手动标注数据的方式,将数据集分为存在风险和不存在风险两类,其中存在风险的Dockerfile文件有902个,不存在风险的Dockerfile文件有1 804个。在此基础上,随机抽取80%的数据作为训练集,剩余的20%作为测试集。
4.2 评估指标
为了评价预测的准确率,使用了在分类问题中采用的重要评价指标:精准率(Precision,P)、召回率(Recall,R)、F 值(F⁃measure,F)。 首先定义有关精准率、召回率和F值的相关参数。Nr→r代表将存在风险的Dockerfile文件正确预测为存在风险的数量;Nr→s代表将存在风险的Dockerfile文件错误预测为安全的数量;Ns→r代表将安全的Dockerfile文件错误预测为存在风险的数量。
精准率:正确分类为存在风险的Dockerfile文件数量与分类为存在风险的Dockerfile文件数量的比。
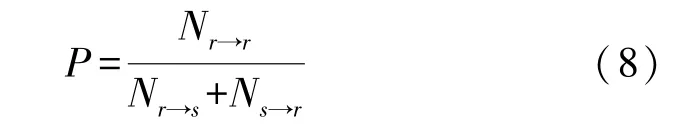
召回率:正确分类为存在风险的Dockerfile文件数量与真正存在风险的Dockerfile文件数量的比。

F值:F值是精确率和召回率的调和平均值。

4.3 实验分析
主要从两个方面来验证实验,一方面验证本文中所使用算法的可行性和有效性。另一方面通过在不同的特征提取方法下比较本文所使用的算法与传统机器学习算法的优劣情况,通过精确率、召回率和F值的变化来验证本文使用算法的优越性。
4.3.1 DRPA算法可行性和有效性实验
本实验的目的是验证DRPA算法中对Dockerfile文件风险预测的可行性和有效性。实验结果分别如图5、图6所示。通过计算量FLOPs和参数量params来衡量本文给出方法的时间效率和空间复杂度。一般情况下,更深的网络有更大的计算量,并且数据越多,计算时间越长。Inception Net相比于其他的一些网络结构来说,在同样参数量的情况下更有效率。不同组之间的特征不进行交叉计算,减少了计算量。通常卷积层的参数数目为:KW∗Kh∗Ci∗CO,其中,KW和Kh分别为卷积核的长宽,Ci和CO分别为输入和输出通道数;全连接层的参数数目为Ci∗CO。根据本文中使用的CNN⁃FPN网络结构,对参数量进行计算结果为:1 653.7×103。对比相同深度的普通结构的参数量减少30%左右。在Inception Net网络中卷积层的计算量为((KW∗Kh)∗Ci)∗((Ow∗Oh)∗CO),其中Ow和Oh分别为输出的长和宽。根据对本文中使用的CNN⁃FPN网络结构,对计算量进行计算结果为:827×106。最后,针对本文所提出的DRPA算法进行多次测量并取平均,预测时间为0.174 s。
根据Dockerfile文件的大小,本算法中使用L2损失函数,其对较大误差的惩罚力度更大,对较小误差更为容忍。图5描述了随着DRPA算法迭代次数的增加,损失函数呈下降趋势,最后降至0.8左右;从图6中可以看出,随着迭代次数的不断增加,DRPA算法的准确度呈上升趋势,达到0.82左右。可以看出,随着DRPA算法不断地训练,模型在不断地优化,输出结果与真实结果之间的差异越小,预测准确率也越高。

图5 DRPA算法的损失函数图
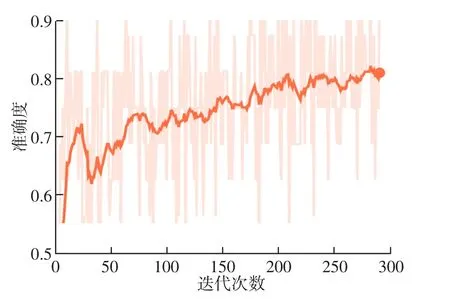
图6 DRPA算法的预测准确度图
4.3.2 不同特征提取方法下不同算法的对比实验
将本文所使用的算法与传统机器学习算法支持向量机(SVM)和传统CNN网络进行比较。并在不同的特征提取方法下对比精准率、召回率和F值的变化,其中本文所使用算法的特征提取工具为Word2vec,即方案 A为对比的基准算法,如表 2所示。
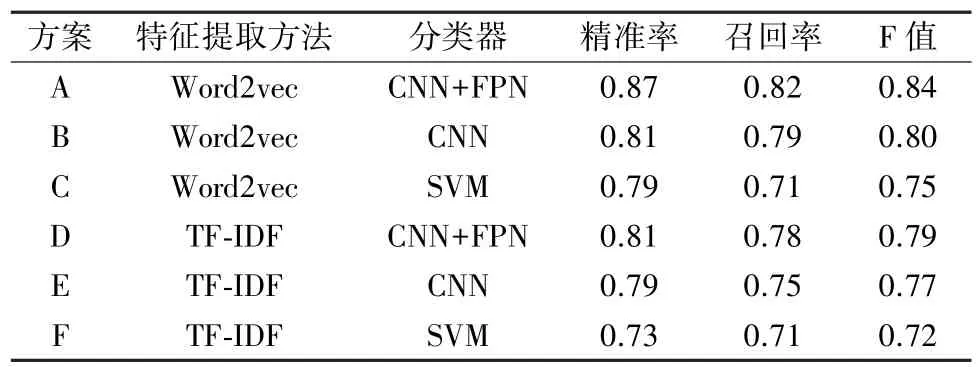
表2 不同特征提取方法下不同算法的对比
在特征提取方法方面,通过比较方案A、方案D或方案B、方案E或方案C、方案F可以看出,无论使用何种分类器,Word2vec方法都要优于TF⁃IDF方法。在分类器方面,通过前3组的数据或后3组的数据可知在特征提取方法相同的情况下,本文所使用的 CNN+FPN算法要优于传统的CNN算法和SVM算法。
5 结束语
文中提供了提高Dokcer安全性的新视角。提出了一种基于深度学习的Docker特征提取风险预测框架,针对Dockerfile文件的安全性这一问题,从源头进一步控制风险,减少了Docker镜像的漏洞,保证了容器和容器集群的安全。同时,本文提出一种基于深度学习的Docker风险特征提取(DRPA)算法,该算法利用CNN⁃FPN网络提取Dockerfile文件的语义和结构特征,并判断其是否存在风险及风险概率,得到风险概率后根据用户需求进行下一步工作。通过实验可以看出,该算法针对Dockerfile文件是否存在风险的预测正确率达82%。但是还有一些工作可以在后续继续展开,具体如下:
(1)本文使用的数据集将Dockerfile文件分为存在风险和不存在风险两种标记,在后续工作中,可以继续细分存在风险的Dockerfile文件的类型,标记为多分类。
(2)目前使用的数据集为手工标记,还存在杂乱等问题,在后续工作中,对数据集进行进一步地清洗。
(3)在本文提出的框架上进一步完善,将预测式和响应式相结合。
猜你喜欢
当代党员(2020年20期)2020-11-06
读者·校园版(2019年24期)2019-12-10
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
雷达学报(2018年5期)2018-12-05
小康(2018年23期)2018-08-23
考试周刊(2016年82期)2016-11-01
小朋友·聪明学堂(2015年8期)2015-11-30
小康(2015年4期)2015-03-31
