
密集异构蜂窝网络中基于深度强化学习的下行链路功率分配算法
2021-05-28 09:15:50宋荣方
南京邮电大学学报(自然科学版) 2021年2期
周 凡,王 鸿,宋荣方,2
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003 2.南京邮电大学 江苏省通信与网络技术工程研究中心,江苏 南京 210003)
在过去的几年中,随着无线通信技术的飞速发展,移动设备得到迅速普及,各类新兴互联网业务百花齐放,移动数据流量呈现爆发式增长态势,无线通信网络的规模也越来越大。当前移动用户日渐增加的无线频谱需求同有限的频谱资源之间的不平衡问题正日益突显和加剧,无线通信和网络架构正朝着智能一体、绿色节能、高宽带低时延等多元化方向发展。在当前技术环境下,由于传统的蜂窝网络系统无法解决频谱资源紧缺、通信质量下降、用户体验不佳等问题,密集部署的异构无线网络将成为未来移动通信的主要存在形式,为此小区内的基站数与核心网的功率消耗会大规模地增加。网络容量的提高以及过度追求考虑频谱效率往往需要以巨大的能耗为代价,因此,产生了一个新的概念——绿色通信[1]。绿色通信以节能减排为主要目标,旨在保证用户传输速率和网络服务质量(Quality of Service,QoS)的同时,尽可能地减少传统能耗对环境造成的污染,保护生态环境,使通信网络能够绿色可持续发展。
在绿色通信系统中,能量效率(Energy Efficiency,EE)是网络节能效率的主要标准之一。当前能量效率的优化主要通过功率控制来实现。由于功率控制的优化问题是一个非凸优化问题,使用传统的启发式方法进行静态优化来完成资源分配,并不适用于动态变化的网络系统,且复杂度高,求解困难。最近,机器学习(Machine Learning,ML)已经成为解决非凸优化问题的热门技术[2]。一些工作者提出了基于监督的深度学习(Deep Learning,DL)资源分配方案[3-5],通过一些启发式算法(例如遗传算法GA、蚁群算法ACA,模拟退火算法SA等)来生成训练数据,但从计算角度来说,训练数据的生成往往是昂贵且费时的,因此,有监督的DL方法并不适用于大型网络系统。也有工作者利用非监督的强化学习(RL)方法[6],通过与环境交互来获得功率控制问题的最佳解决方案[7-8],但在传统的 RL中,策略是以表格形式进行存储的,其缺乏通用性,对较大的动作和状态空间来说并不可行。
因此,近年来深度强化学习(Deep Reinforcement Learning,DRL)成为一种解决复杂控制问题的热门技术。深度强化学习将深度学习的感知能力和强化学习的决策能力相结合,不断以试错的方式与环境进行持续交互,通过最大化累积奖赏的方式来获得最佳策略。文献[9]提出了一种用于多小区功率分配的深度神经网络,称为深度Q全连接网络(DQFCNet),与注水法和Q学习方法相比,DQFCNet可以提高系统的整体容量,且在收敛速度和稳定性方面有显著提升。文献[10]中,作者提出了一种新型的基于深度强化学习的在线计算卸载方法,用于解决基于区块链的移动边缘计算问题。文献[11]中,作者提出了一种基于深度强化学习的新型非合作实时方法,在满足D2D通信服务质量约束的同时,解决节能型功率分配问题。
受深度强化学习的启发,针对多小区密集异构蜂窝网络,本文基于深度Q学习提出了一种全新的集中式下行链路功率分配方案,使其能够自适应环境变化,以提高通信系统的能量效率。考虑到无线网络的巨大状态空间,本文将深度学习与Q学习相结合,为强化学习agent定义了状态空间、操作空间和奖励等要素,同时将能量效率设为奖惩值,构建损失函数来训练神经网络的权值。仿真结果表明,与传统的贪婪算法和Q学习方法相比,本文提出的DQN方案得到的系统能量效率更高,收敛速度更快且更加稳定。
1 系统模型和问题陈述
1.1 系统模型
考虑密集异构蜂窝网络的下行链路,该网络系统由多个OFDM小区构成,每个小区中心部署一个带有发射机的基站。假设密集异构蜂窝通信系统中有M个小区基站和N个授权移动用户,所有的基站和移动用户都采用单天线系统,基站的地理分布遵循泊松点过程模型,用户随机分布在小区覆盖范围内。系统所使用的路径损耗模型借用文献[12]的路径损耗模型。从实际出发,考虑多个基站密集分布部署,小区之间共享所有可用的频带,每个用户在同一时刻只能连接到一个基站。
网络系统模型如图1所示[13]。

图1 系统模型
图1系统采用集中式控制,一个中央控制器可以对整个网络的信息进行收集,包括信噪比和传输功率,中央控制器在收到用户传输的位置、速率及干扰信息后,制定出最终的资源分配方案。该系统模型使用六径瑞利衰落模型进行评估,系统中用户主要受到相邻基站的干扰,用户之间不存在干扰。
1.2 问题陈述
在该异构蜂窝通信系统模型中,假设小区基站用 m = {1,2,…,M} 来表示,移动用户用 n = {1,2,…,N}来表示。某一时刻,当基站m与其覆盖范围内的移动用户n进行通信时,受到的干扰信号为
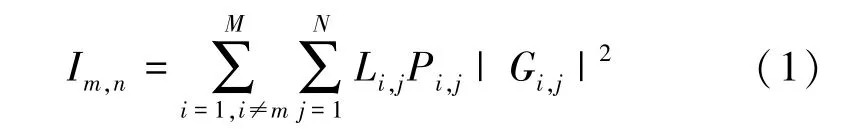
其中,Li,j表示基站i与用户j的连接状态,如果用户j成功接入基站 i,则 Li,j= 1, 反之则 Li,j= 0;Pi,j表示基站i与移动用户j进行通信时的发射功率;Gi,j表示基站i与移动用户j进行通信时的链路增益,其表达式为
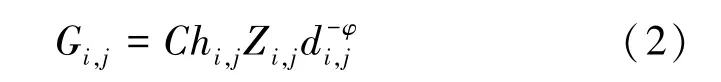
其中, C 表示系统影响的常数, hi,j,Zi,j,φ 分别为基站i与移动用户j进行通信时的多径衰落、阴影衰落及路径损耗因子,di,j表示基站i与移动用户j两者之间的距离。
当信道状态信息已知,基站m与移动用户n进行通信时,系统的接收信噪比(SINR)可表示为
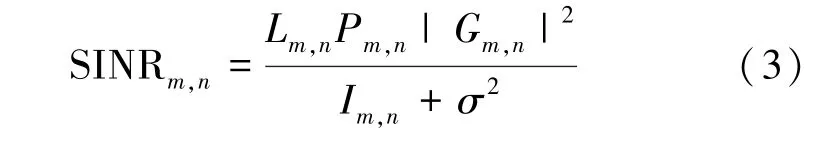
其中,σ2表示基站m与移动用户n通信时噪声的方差。
由香农定理可得系统的总吞吐量为
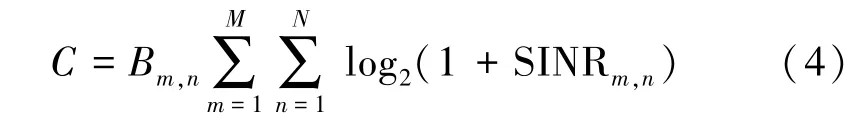
其中,Bm,n表示基站m与用户n通信时的带宽。
采用文献[14]提出的系统能效模型,将系统的能量效率η(单位为bps/Hz/W)用系统发送功率的产出与投入的比值来表示,有

其中,分子项是所有可用子载波的传输速率,为系统的功率产出,分母项是所有基站的发送功率,为系统的功率投入。
在基站发射功率满足最大发射功率限制的约束条件下,最大化系统能量效率这一目标优化问题可简述为

其中,Pmax为基站最大发射功率。
传统的求解方法是利用拉格朗日乘子法获取最优解。将系统能量效率最优化问题转化为

约束条件为

采用拉格朗日乘子法将约束优化问题转化为下列无约束优化问题

其中,λm为拉格朗日乘子。
将式(9)分别对 Pm,n、λm求偏导,得

解得最优功率分配方案为

其中,[·]+表示取值非负。
上述问题是一个NP⁃hard问题,对于基于模型的传统方法而言,通常难以量化与最优方案之间的性能差距,且计算量大,复杂性高,实际实现也受到限制。此外,这种面向模型的方法无法适应未来的异构服务需求和随机变化的环境,因此在下一节中,将讨论和研究数据驱动型的深度强化学习算法来解决此优化问题。
2 基于深度强化学习的资源分配算法
深度学习的感知能力很强,但决策能力一般;而强化学习与之相反,具有较强的决策能力,但不擅于解决感知问题。深度强化学习则集二者所长,将深度学习的感知能力与强化学习的决策能力相结合,以试错的方式与控制环境进行持续交互,旨在找到一种最佳策略,以在连续交互中最大化累积奖励[13]。因此,本文使用同时具有感知和决策能力的深度 Q 网络(Deep Q⁃Network,DQN)来求解异构蜂窝网络系统下行链路的资源分配问题。
2.1 强化学习之Q学习
对于持续变化的密集异构无线网络而言,收集环境信息的最简单直接的方法就是与环境进行持续交互。强化学习通过连续迭代的方法来进行学习,其核心目标是在每个学习状态通过最大化一个特定指标来找到最优动作。学习者与环境进行连续交互,通过从环境中获取的强化信号来评估系统性能,从而获得优化后的控制策略。
强化学习的基本模型由以下要素组成:学习者的动作集合A={a1,a2,…,an}、环境状态集合S={s1,s2,…,sm}、强化信号R及学习者的策略π:s→a。 这些要素组成的基本模型如图2所示[15]。

图2 强化学习基本模型
在t时刻,学习者获得当前的环境状态st∈S,并依据此时的策略π执行动作a∈A,当前环境受到动作a的影响后,转变为新的环境状态s′∈S,同时产生强化信号R并将其反馈给学习者。学习者再根据新的环境状态s′及强化信号R来更新策略π,并进入到下一次迭代过程中。
学习者的最终目标是找到所有环境状态s对应的最优策略π∗(s)∈A,从而最大化长期累积奖励的期望值Vπ(s), 表示为

其中,γ∈[0,1)为折扣因子。
根据贝尔曼最优准则,式(12)最大值为
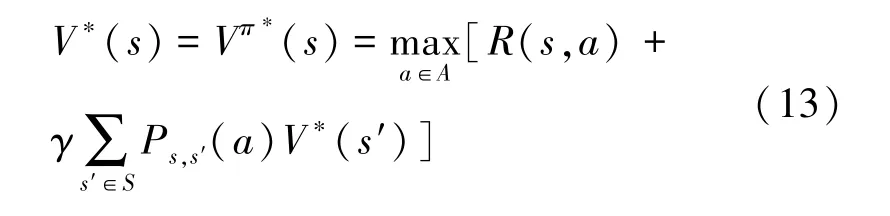
其中,Ps,s′(a) 为状态s在动作a的作用下变为新状态s′的转移概率,R(s,a) 为r(st,at) 的数学期望。
Q学习作为一种基于价值函数的无模型强化学习算法,在解决动态无线网络环境问题上具有天然的优势,它能够在R(s,a) 和Ps,s′(a) 未知的情况下找出最佳策略π∗。 将当前策略π下的状态与动作(s,a) 映射为一个 Q 值,用Qπ(s,a) 表示为
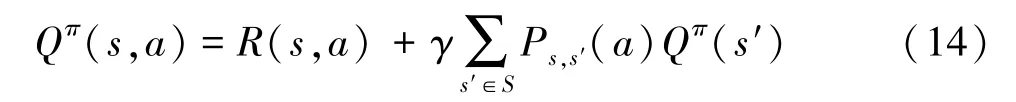
由式(12)和式(13)可以得到

在Q学习算法中,学习者通过连续的迭代学习来逼近自己的行为价值函数,具体过程表示为

其中,α∈[0,1)为学习率。随着时间t→∞,若Qt(s,a)能够经历无穷多次更新,同时学习率α能以特定方式逐渐降低为0,则Qt(s,a)能够收敛于最优值(s,a), 通过式(7)便可获取到最佳策略π∗。
2.2 算法框架
深度Q学习(DQL)是Q学习算法的一种优化体,它与深度学习相结合,使用卷积神经网络(CNN)来估计值函数,同时利用经验回放技术进行学习,并通过设立第二个值网络——目标值网络来解决时间差分算法中的时间偏差问题。
基于深度Q学习的算法框架如图3所示,该算法框架包含DQL误差函数、环境、当前值网络、目标值网络及回放记忆单元5大模块[16]。深度Q网络中包含两个不同的值网络,一个是与网络环境进行持续交互并随时更新的当前值网络,另一个是不与环境进行交互,每隔一段时间才进行赋值更新的目标值网络。DQL利用经验回放技术,在每个时间步将学习者与环境交互的经验 (s,a,r,s′) 存储在回放记忆单元中,训练数据时会从存储样本池中随机抽样出训练样本并采用Q学习更新,可以有效降低样本之间的关联性。其中,s为当前状态的观测值,a是在观测值s下采取的动作,r表示采取动作a后得到的奖罚值,s′为采取动作a后新的环境状态的观测值,a′表示在新观测值s′下所采取的下一步动作,θ表示DQN网络的权重和偏置。

图3 基于深度Q学习的算法框架
2.3 问题映射
本文将深度Q学习的思想引入异构无线网络的资源分配算法中,需要将学习者、状态、动作和强化信号等因素映射到实际的接入模型中,具体的映射过程如下所述。
(1)学习者:基站m,1≤m≤M。
(2) 状态集合S:sm={Nm,Pm},Nm代表与基站m相连的用户数,Pm代表基站m的发送功率。
(3) 动作集合 A:am={m,ΔPm},m代表小区基站,ΔPm代表基站m的发送功率适配值,表示进入下一状态时基站发射功率的调整量。
(4)强化信号R

当基站m与移动用户n进行通信时,基站m的奖励值为rm,n。 学习者通过连续的迭代学习来对行为状态值函数进行更新,具体更新流程为

其中,α∈[0,1]为学习率,γ∈ (0,1)为折扣因子,∇Q(s,a;θ) 表示误差函数梯度。
在传统的Q学习中,策略以表格形式进行存储,且由于缺乏通用性,对于较大的动作和状态空间不可行。因此,使用深度神经网络(Deep Neural Network,DNN)这一函数近似方法来代替传统表格方法,拥有更高的准确性。图4所示是本文用到的DNN模型,含有输入层、隐藏层及输出层等结构,并将深度Q网络作为行为状态值函数Q(s,a;q)。

图4 DNN模型架构
在上述DNN模型中,输入层的数据为连接到基站的移动用户数量及基站发射功率的集合[N1,…,Ni,…,Nm,P1,1,…,Pi,j,…,Pm,n], 隐藏层能够提高网络的拟合能力,同时优化网络的非线性,采取随机丢弃节点是为了防止出现过度拟合;输出层的数据为基站发射功率的调整值。深度神经网络的损失函数为

2.4 算法实现
首先,将Q值表中的Q值都初始化为0,随机设置神经网络的初始参数为θ,初始化折扣因子γ及学习率α。接着,获取起始状态的观测值得到初始化状态集合序列s1,并通过函数φ转化为神经网络的输入。DQL利用经验回放技术,在每个时隙将学习者与环境交互的经验et=(st,at,rt,st+1) 存储在回放记忆单元数据集D=(e1,…,eN)中。在算法的内部循环中,从存储样本池中随机抽样出训练样本并采用Q学习更新或小批量更新。在执行经验回放之后,学习者根据ε⁃greedy策略选择并执行下一步动作。由于神经网络的输入无法为任意长度,因此利用函数φ产生固定长度的输入。完整的DQL算法如下。
算法 1 Deep Q⁃learning算法

每一个时间步的经验都可用于权重的更新,从而能够提高数据的更新效率。由于训练样本之间的相关性较强,从连续样本中进行学习效果很差,而随机抽样能够破坏样本之间的相关性,使学习更加高效。利用经验回放技术,能够使行为分布通过其之前的状态被均匀化,进而能够平滑地进行学习并避免产生参数的振荡或发散现象。
3 仿真与分析
本节通过计算机仿真的方法来评价提出的基于深度Q学习的功率控制方案,并与基于Q学习的功率控制方案及传统的贪婪算法进行对比分析。其中,本文中的高斯白噪声参数采用文献[9]所用的噪声方差;多径衰落和阴影衰落采用文献[12]所用的参数,分别服从指数分布和对数正态分布。具体仿真参数如表1所示。
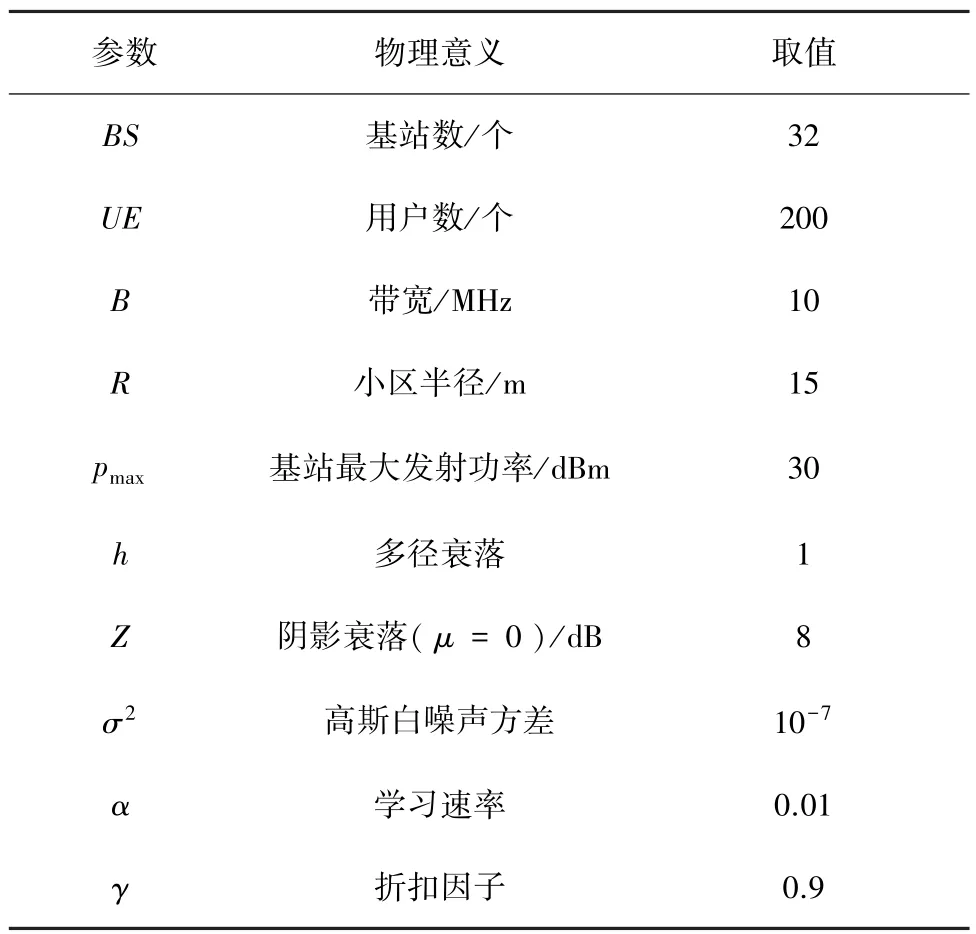
表1 仿真参数
本文通过Tensorflow来实现提出的算法,使用2个隐藏层的深度神经网络作为DQN,将ReLU函数作为隐藏层的激活函数。图5所示为系统的能量效率与更新迭代次数之间的关系,将本文提出的DQL算法与Q学习算法以及传统的贪婪算法进行对比可以看出,采用深度Q网络(DQN)和Q学习算法获取到的系统能量效率要比采用贪婪算法获取到的系统能效高得多,并且使用DQN获取到的系统能效要高于使用Q学习算法获取到的系统能效1 bps/Hz/W左右。

图5 系统能量效率比较
图6所示为DQN和Q学习的收敛速度对比图。从图6中可以看出,DQN的收敛速度随着迭代次数的增加慢慢加快,且逐渐优于Q学习算法。其主要原因:随着用户的每次移动以及网络进行更新迭代后,Q学习算法需要对Q值表格进行更新并需要再次达到收敛,产生的波动较大。而DQN与Q学习算法相比更加稳定,产生的波动较小。除此之外,DQN策略的持续优化能够大幅提高系统的能量效率。
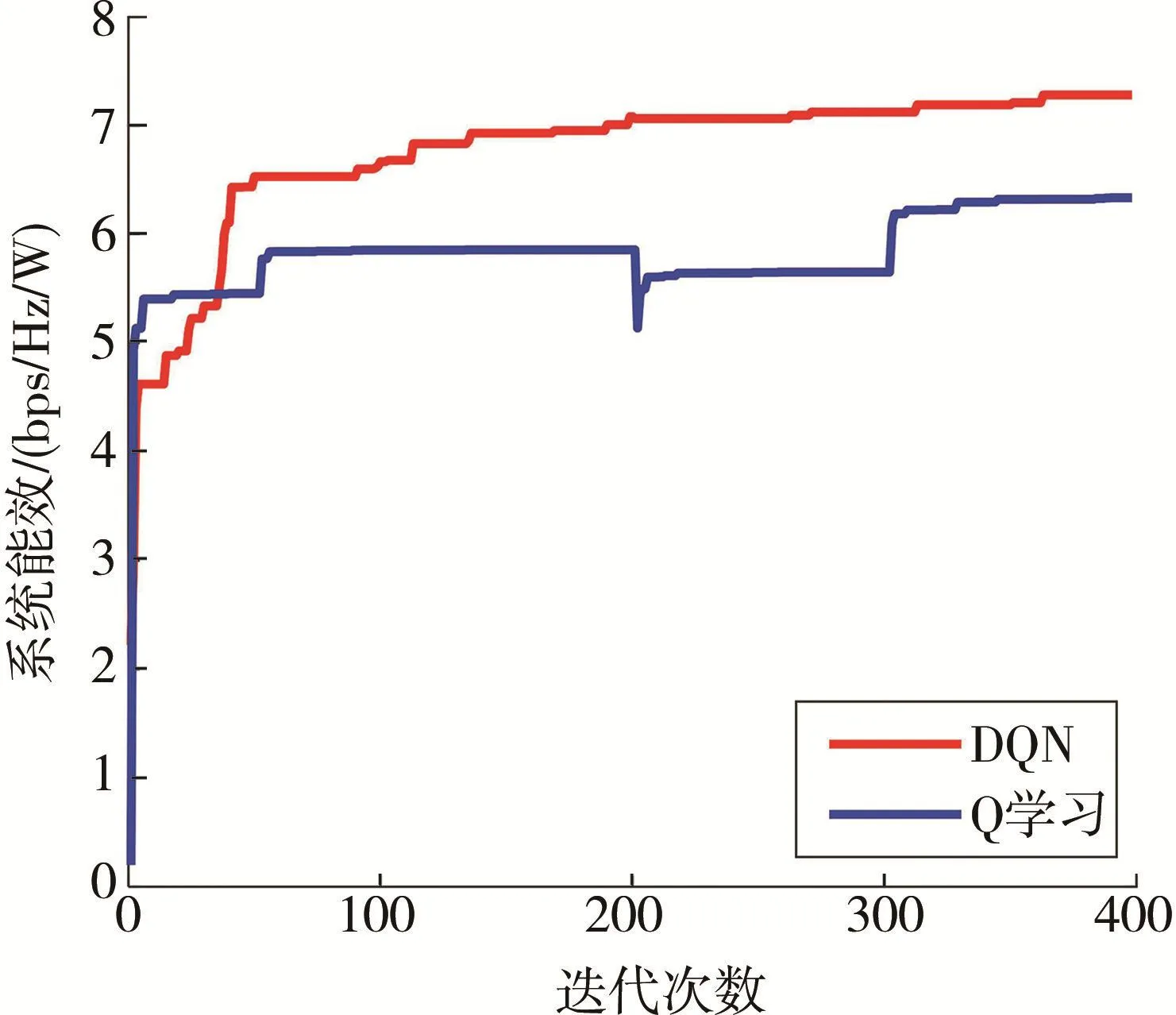
图6 收敛速度比较
学习速率是控制训练过程中DQN权重变化量的重要超参数,它控制DQN从数据中学习的速度。我们将学习率分为 0.001,0.005,0.01,0.02,0.03,0.05,0.1等7个跨度来考察算法性能。当最终算法得到的平均能量效率趋于相对平稳时(经过120次迭代),将最大值和最小值的差值与均值的比值定义为平均能效的浮动比例。
如图7所示,算法在学习率为0.01及以下时的平均能效浮动比例较小,在0.06左右;而当学习率增大以后,平均能效的浮动陡增。这是由于较大的学习率使得神经网络在每次更新时更加偏向学习当前这批记忆样本的特性,但是在强化学习的过程中,学习的样本是在不断增加的,样本的多样性会慢慢提高。因此较大的学习率会使得每次执行动作后的反馈奖励无法进行稳定的提高,导致平均能效无法稳定提高。
如何找到最佳学习率成为了一项挑战,因为较低的学习率可能会导致训练时间增加,而较大的学习率则可能会导致训练过程不稳定。
如图8所示,可以看出较低的学习速率实际上需要更多的训练迭代次数来达到平稳,而较高的学习率(例如0.02)得到的最终平均能效的浮动又过大(如图7所示)。所以选择0.01的学习率,在本文的数据网络环境下是最佳的。

图7 平均能效浮动比例
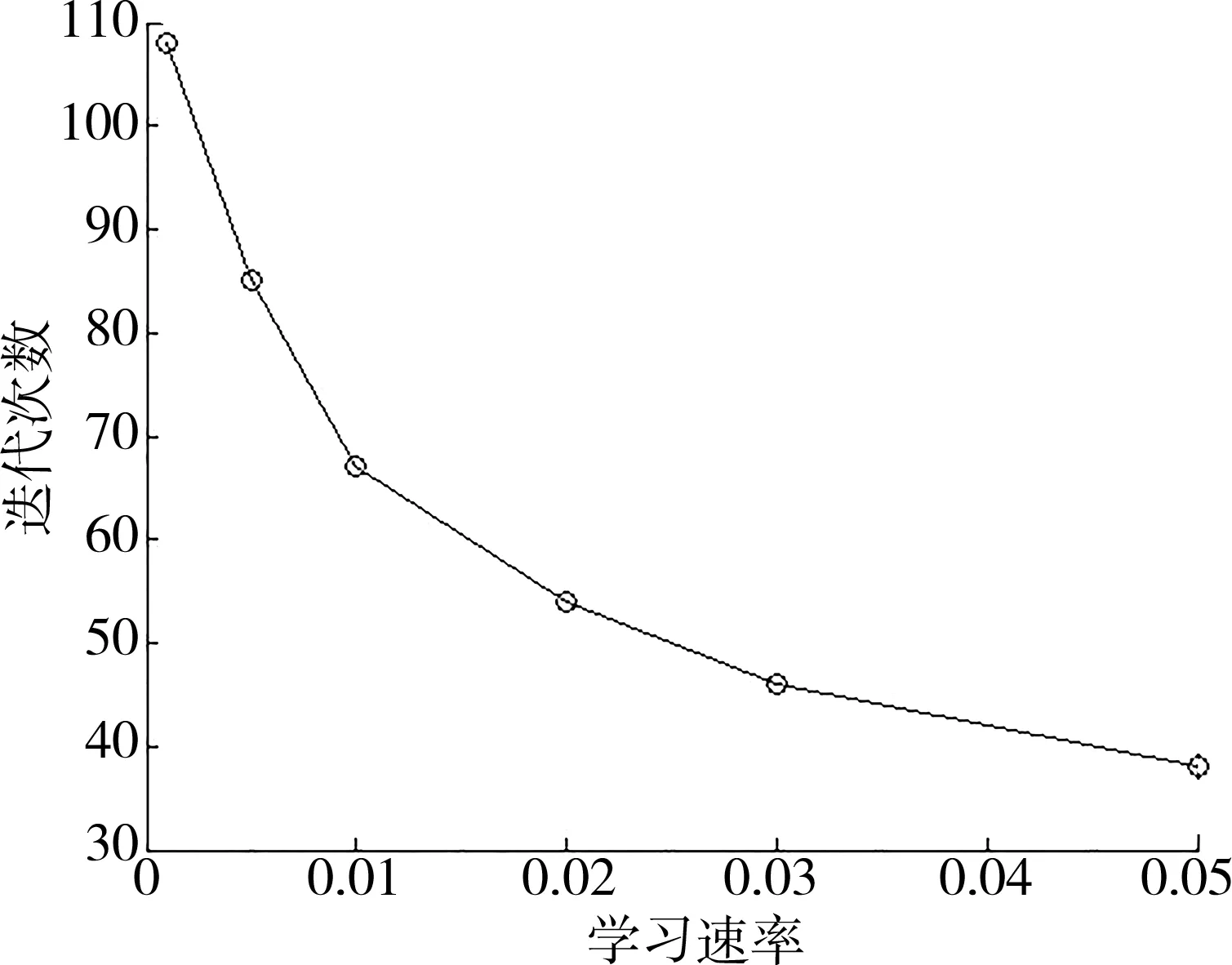
图8 迭代次数
4 结束语
为了提高密集异构蜂窝通信系统中的能量效率,本文讨论了多小区蜂窝网络的资源分配问题,提出了一种基于深度强化学习的下行链路功率分配算法。仿真结果显示,与Q学习和传统的贪婪算法相比,本文提出的深度Q学习算法能够获得更高的能量效率。同时,由于使用了深度神经网络,DQN的收敛速度和稳定性也得到了提高。此外,通过仿真结果分析了学习速率对DQN网络模型的影响,找到了最佳学习速率。
猜你喜欢
中学生数理化·八年级物理人教版(2022年6期)2022-06-05 06:55:38
中学生数理化·八年级物理人教版(2022年6期)2022-06-05 06:55:32
中学生数理化·八年级物理人教版(2022年6期)2022-06-05 06:55:30
学生天地(2020年15期)2020-08-25 09:22:02
意林·少年版(2020年2期)2020-02-18 11:14:52
中学生数理化·八年级物理人教版(2019年6期)2019-06-25 01:00:18
探索科学(2017年4期)2017-05-04 04:09:47
海外华文教育(2016年4期)2017-01-20 08:22:24
中国交通信息化(2016年8期)2016-06-06 03:56:25
移动通信(2015年17期)2015-08-24 08:13:10
