
基于BERT的多源知识库索引对齐算法
2021-05-28 09:16:16季一木刘艳兰刘尚东许正阳刘凯航汤淑宁
南京邮电大学学报(自然科学版) 2021年2期
季一木,刘艳兰,刘尚东,许正阳,胡 林,刘凯航,汤淑宁,刘 强,肖 婉
(1.南京邮电大学 计算机学院,江苏 南京 210023 2.南京邮电大学 高性能计算与大数据处理研究所,江苏 南京 210023 3.国家高性能计算中心南京分中心,江苏 南京 210023 4.江苏省高性能计算与智能处理工程研究中心,江苏 南京 210023 5.南京邮电大学 教育科学与技术学院,江苏 南京 210023)
近年来,随着互联网技术的迅速发展,涌现出了维基百科、头条百科、百度百科等大量优秀的知识资源与知识社区。与此同时,互联网正面临从文档连接的万维网向数据连接的语义网演变的技术变革时期。为了实现这一技术变革,需要利用网络数字化信息资源构建高品质、大规模的知识库。目前,工业界与学业界的已有研究,已经创建了 Yago[1]、Freebase[2]、DBpedia[3]、百度知心、搜狗知立方等以实体和实体关系为主导的大规模知识库。知识库在知识图谱、智能语义问答和知识融合等自然语言处理领域有着重要意义[4]。但是,仅仅使用单个知识资源或者知识社区,存在实体覆盖面低、实体信息缺失等问题;而不同知识资源和知识社区之间资源描述结构存在较大差异,阻碍了数据的共享、集成与复用。因此,对现有的多源异构知识库进行融合能够推动语义网技术的发展。作为融合后知识一致性保障的关键,有效的实体对齐技术值得深入研究。
实体[5](Entity)是指客观存在并且可以进行区别的事物,包括具体的人、事、物、抽象的概念或关系等。实体对齐[6](Entity Alignment) 也称为实体匹配(Entity Matching)或实体解析(Entity Resolution),是判断相同或不同数据集中的两个实体是否指向真实世界同一对象的过程。百科知识库对齐研究存在的难点在于:首先是计算复杂度过高,百科知识库拥有大量的实体,例如百度百科拥有1 600万个实体,头条百科拥有1 800万个实体,如果采用普通遍历的方法,需要对1 600万∗1 800万个实体进行匹配,从中筛选出对齐实体对,计算复杂度过高。其次是不同的百科知识库之间存在异构性,既存在内容上的异构也存在描述体系上的异构。在描述体系上,不同知识库的描述体系差异较大。在内容上,存在两种不同的异构现象,(1)同名不同义,对于同一个实体指称在不同的知识库中拥有的实体是不同的。例如,在百度百科知识库中拥有28个实体指称为“王菲”的词条,在头条百科中拥有26个实体指称为“王菲”的词条,但是两个百科知识库中实体指称相同的这些词条,只有部分是存在对齐关系的。(2)同义不同名,对于指向真实世界的同一个实体,在不同的知识库中有着不同的实体指称。例如,对于泛指属于“蜚蠊目”的昆虫这个实体,在百度百科中拥有的实体指称为“蟑螂”,在头条百科中拥有的实体指称为“蜚蠊”,这两个实体指称完全不同的词条却指向同一个实体。针对描述体系异构性已有大量的研究工作[1,7-9],因此,本文的研究重点在于内容上的异构,即如何寻找多源异构知识库中实体指称的对齐映射关系。实体对齐常用的方法是利用相似性函数对实体的属性信息进行计算,进而判定两个不同数据源的实体是否对齐,对于体系结构较为完整、类和实体信息丰富的知识库有着较好的效果。但是,百科知识库是由网络大众共同编辑,存在质量参差不齐、部分实体属性匮乏、不同百科库相同属性不一致等问题,有研究表明,百科数据属性标签的覆盖率较低[5],在这种情况下,想要直接利用属性信息对实体指称进行对齐有一定难度。因此,本文提出一种基于BERT的多源知识库索引算法,有效利用百科知识库中实体半结构化信息和非结构化的上下文,利用编辑距离和BERT预训练语言模型[10]实现不同知识库间属性名的映射,利用BERT预训练语言模型获取实体非结构化文本的特征向量,进行知识库实体对齐工作,对具有半结构化信息和非结构化描述信息的实体具有良好的准确度和通用性。在此基础上,针对实体指称与实体上下文的关键词提出两种索引构建方式,通过这些索引,有效提高了实体对齐的效率和召回率。经过实验表明,本文所提方法能够有效提高多源异构知识库间实体对齐的性能。
综上所述,本文的主要贡献如下:
(1)本文利用百科实体半结构化信息和非结构化文本信息,提出一种基于BERT的实体对齐方法,能够有效解决多源异构百科知识库的实体对齐问题。
(2)本文提出了基于实体指称和实体文本关键词的两种索引结构,在提高实体对齐效率的同时,不仅提升了实体的准确率还保证了实体的召回率。
(3)本文构造了中文百科知识库实体对齐标准测试集,对测试集中可以对齐的实体进行了人工校验与标注,针对本文算法以及同类实体对齐算法进行了大量实验,结果表明,本文方法能够有效完成实体对齐工作。
1 相关工作
当前,知识库实体对齐工作的技术研究主要从实体对齐算法、特征匹配计算、分区索引构建3个方面进行[6]。三者的关系主要是根据不同知识库的特点在实体对齐算法中融入分区索引技术降低计算复杂度、使用合适的文本相似性函数或者结构相似性函数对候选匹配对进行匹配计算。
实体对齐算法主要分为成对实体对齐算法和集体实体对齐算法,成对实体对齐算法根据实体对特征的相似度获取评分来判断是否匹配,其最早出现在 Newcombe 等[11]和 Felleigi等[12]提出的实体对齐分类方法的传统概率模型中,通过统计属性的概率分布给属性赋予权重,然后根据相似性函数计算不同属性的相似度,获取加权后的总相似度来判定实体是否对齐。而后出现的各种基于机器学习的实体对齐算法也属于成对实体对齐。根据数据集是否包含标注数据,基于机器学习的实体对齐方法分为有监督学习和无监督学习。基于监督学习的实体对齐方法一般使用决策树、支持向量机和集成学习等技术,通过比较属性向量来完成实体对齐任务[13-16]。万静等[17]在对关联数据中实体的属性提取语义特征与统计特征并进行建模后,使用基于VS⁃Adaboost的有监督分类器优化算法实现实体对齐工作,可以发现隐含信息,提高对齐准确率,并降低对齐工作的复杂度。无监督学习一般在缺乏训练数据的情况下使用,主要是利用实体的相似向量将实体进行聚类,张伟莉等[18]就是利用实体的名称、属性、文本、时间、数值等信息提取多维特征,通过两个独立视图对多位特征进行协同训练,从未标注数据中获取准确的决策标准。
集体实体对齐中有部分工作是通过将实体间的关系看作是属性的一种,从而进行实体匹配计算[19],被称作局部集体实体对齐。 沈秉文等[20]则是将实体关系与实体属性统一看作一类信息,在进行手动对齐后根据关系或属性进行聚类,在同一聚类中构建索引结构,最后进行索引过滤获取对齐实体。该算法在极大提升实体对齐速度和效率的基础上还保留了较高准确性,但是需要人工干预,缺乏一定扩展性。
全局集体实体对齐方法,Bhattacharya等[21]提出的层次聚类算法能够迭代地获取匹配实体,是一种典型基于相似性传播的集体对齐算法。Lacoste等[22]对其进行改进,通过实体对属性和关联实体信息构造全局函数,对其进行最优化求解,从而得到了可用于大规模知识库实体对齐算法SiGMa。该算法具有良好的准确性和扩展性,但需要少量人工参与。近年来,大量研究[23-25]不断尝试利用基于知识表示的图嵌入模型来完成实体对齐工作,该类方法主要是利用不同的知识表示模型对数据集进行训练来获取实体和关系在图模型中的向量表示,从而实现实体间的语义相似度计算来进行实体对齐。
特征匹配技术分为基于文本相似性和基于结构相似性两大类。前者通常使用Jaccard相似性函数[26]、余弦相似性函数[27]、基于 q⁃gram 的相似性函数[27]和基于编辑距离的相似性函数[28],这些函数通常适用于短语或句子的计算且难以表示文字的深层语义信息,目前更加流行的是基于TF/IDF的文本相似度计算[5]、基于LDA主题模型的相似度计算[29]和基于 Bert模型的语义相似度计算[10]。
许多数据库的分区技术[30]可以用于知识库的对齐过程,主要的分区技术:(1)基本分区索引,根据定义选取实体属性作为键值构建索引,使得实体相似度计算只在具有相同索引键值的实体中进行;(2) Hash 索引[31],通过定义一个关于实体一项或者多项属性的Hash函数[12],关于实体对齐的算法只在具有相同Hash的实体中进行;(3)Canopy聚类索引[32],首先根据实体属性词的集合构造键来创建倒排表,然后根据算法迭代地产生互相重叠的聚类,使得实体对齐算法在聚类中进行。以上分区索引技术都需要依赖实体的属性信息。
2 基于BERT的多源知识库索引对齐算法
2.1 实体对齐框架
本文的主要工作是对百度百科和头条百科两个异构百科知识库中的实体进行对齐。本文的实体对齐框架主要分为4个部分,数据的获取与预处理、构建索引、获取候选集和筛选对齐实体。主要流程如图1所示。
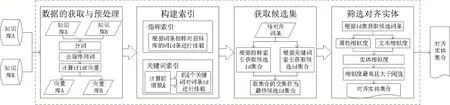
图1 实体对齐框架
(1)数据的获取与预处理。在进行实体对齐前,需要对获取的百科词条进行预处理。首先,对词条的描述性文本进行分词与去除停用词,得到每个词条对应的词向量。
(2)构建索引。将头条百科知识库作为已知知识库,先利用已知知识库实体的实体指称以及实体属性信息中别名、中文名、昵称等属性信息构建指称索引;然后利用预处理获取的词向量,建立关键词索引。详细描述见2.2节。
(3)获取候选集。将百度百科知识库作为待融合知识库,遍历百度百科的知识库,对每个实体进行对齐并挂载到已有知识库。对待对齐的实体,根据实体的指称和别名等属性信息,在指称索引中进行搜索,得到一个候选id集合;然后根据实体关键词在关键词索引中进行搜索,得到另一个候选id集合;最后获取两个集合的交集作为最终候选集。详细描述见2.3节。
(4)筛选对齐实体。根据步骤(3)获取的id集合,需要从知识库中获取所有候选实体。先使用编辑距离与BERT模型计算实体间属性相似度,然后借助BERT预训练语言模型提取实体文本的向量表示,并使用余弦聚类计算实体的相似度,最后加上各自的权重得到实体相似度。筛选出相似度最高的作为可对齐实体,并设置一个相似度最低值,当可对齐实体的相似度低于该值,认为在知识库中没有可对齐实体。详细描述见2.5节。
2.2 构建知识库索引
鉴于需匹配的两个知识库规模大,实体数量多,如何有效解决匹配效率问题是一大挑战。分区索引技术被广泛地应用于实体对齐过程中,可以说分区索引技术是当今大规模知识库匹配的关键技术[6]。通常,分区索引技术的关注点在知识库中实体的属性上,通过构建关于实体的一个或者几个属性的函数,根据函数值对知识库的实体进行区块划分。这样的分区索引技术往往对属性以及属性值有着较高的要求。首先,需要两个不同知识库的属性名具有良好的映射关系;其次,作为索引构建的属性的值如果缺失或者错误会导致实体的错误分类;最后,还需要属性值的均匀分布。然而,两大网络百科知识库中的属性体系具有较大的异构性并且存在属性值缺失的问题。例如,对于同一实体,在百度百科中属性名为“中文名”的属性在头条百科中属性名为“名称”或者“中文名”,在百度百科中属性名为“色彩”的属性在头条百科中属性名为“画面颜色”。针对属性体系异构的问题,在目前的研究中[5,19-20],基本都是通过人工比对校验编辑属性映射规则,需要大量的人工干预。综上可知,基于属性值的分区索引技术并不能良好地适用于大规模中文网络百科知识库的实体对齐工作。本文针对实体的指称项和非结构化文本信息提出了两种索引构建方式。
2.2.1 基于实体指称的索引构建
通过对知识库数据的简单分析,可以发现所有可匹配的实体集合要么与待对齐实体的实体指称在字面上应该相似,即同名实体;要么实体指称不相似但是指向同一实体,即同义实体。王雪鹏等[5]在利用网络语义标签对中文百科知识库进行实体对齐时,以实体名相同作为依据选择可匹配实体集合时,忽略了同义不同名的实体对,导致召回率不高。
在网络百科知识库的属性体系中,存在大量属性的属性值可以作为实体的指称项,例如,中文名、外文名、简称、别称、别名、软件名称等,这些属性的特点是以“名”或者“称”结尾或一个属性的属性值中可以包含多个指称项,例如,实体“蟑螂”的属性“别名”的值为“小强,黄婆娘,偷油婆”,包含有3个指称项。大多数实体都有一到多个该类属性。因此,本文在直接按名查找的基础上合理利用属性信息隐含的实体指称项,构建实体指称索引,扩展可匹配实体集合。首先,对中文网络百科知识库中的实体进行形式化描述
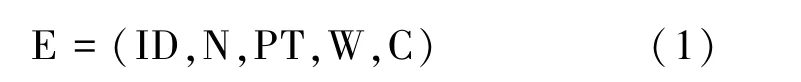

式中,E(Entry)代表实体,N(Name)代表实体的词条名称,ID代表知识库中实体的id,W(Words)代表实体的非结构化文本信息,C(Category)代表实体的类别信息,一个实体可以拥有多个类别,PT(Property Tuple)代表实体的属性三元组,一个实体可以拥有多个属性三元组。式(4)表示属性三元组由实体词条名称(s)、属性名(p)和属性值(o)构成。
然后对实体指称索引构建的流程进行描述,如图2所示,遍历知识库中的所有实体,针对每一个实体,首先获取实体的词条名称(N);然后遍历实体的属性三元组,当属性名符合前文描述的特征时,获取属性值中的一到多个实体指称(O);最后,以获取到的词条名称和实体指称作为 key、实体 ID作为value,挂载到索引库中。

图2 实体指称索引构建过程
2.2.2 基于关键词的索引构建
本节利用实体文本信息构建倒排索引,并进行前缀过滤,筛选出候选实体,加快知识库实体对齐速度。
本文实体文本匹配形式化定义:经过前期预处理,每个实体的文本信息用一个词向量来表示。假如有两个实体的文本词向量r与s,则通过余弦值来计算文本的相似度

对于一个阈值threshold,认为当

两个实体的文本是相似的,两个实体对齐的概率较大。
描述利用文本信息构建索引的主要思路:将词向量按照TF⁃IDF(w)权重值进行递减顺序排序,然后根据词向量前缀长度(k)取词向量前k个词对实体进行索引挂载,首先需要获取词向量的前缀长度,计算公式的推导如下。
假设实体文本信息可以用矩阵Ar与Aq分别表示

式中,wri代表第i个关键词,xri代表词对应的TF⁃IDF值。
设两个实体所有关键词的集合为wu,则
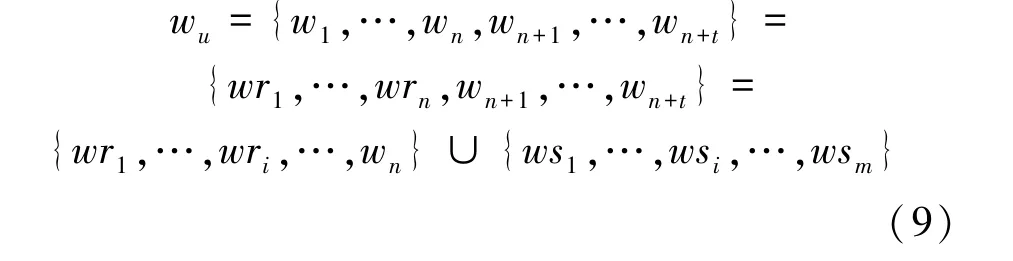
实体r与q可以用n+t维的向量表示为

根据向量余弦值的空间含义易知,两个向量同维度的值越接近,向量间的相似度越高。因此,当r与q中k+1至n维的值较为接近时,使得两个实体向量的相似度刚好达到threshold,即

若r的向量已知,当yn=xrn,…,yk+1=xrk+1, 式(12)中k可以取最大值,即前缀长度最大为k。在前k个关键词中,s至少要有一个关键词对应的向量值不为0,两个实体的文本相似度才可能达到阈值threshold。 即
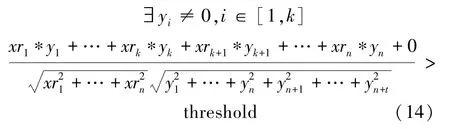
接下来对k的求解进行推导。
令: yn= xrn,yn-1= xrn-1,…,yk+1= xrk+1
代入式(14)可以得到

由式(12)和(13)可以得到式(16)和(17)

此时,任意 yi≠0,i∈ [1,k], 都可以使得两个词向量满足条件(14)。
若已知 threshold,由式(16)和式(17),可以求得k的值,进而获取r的前缀长度为k。
算法流程描述如图3所示。
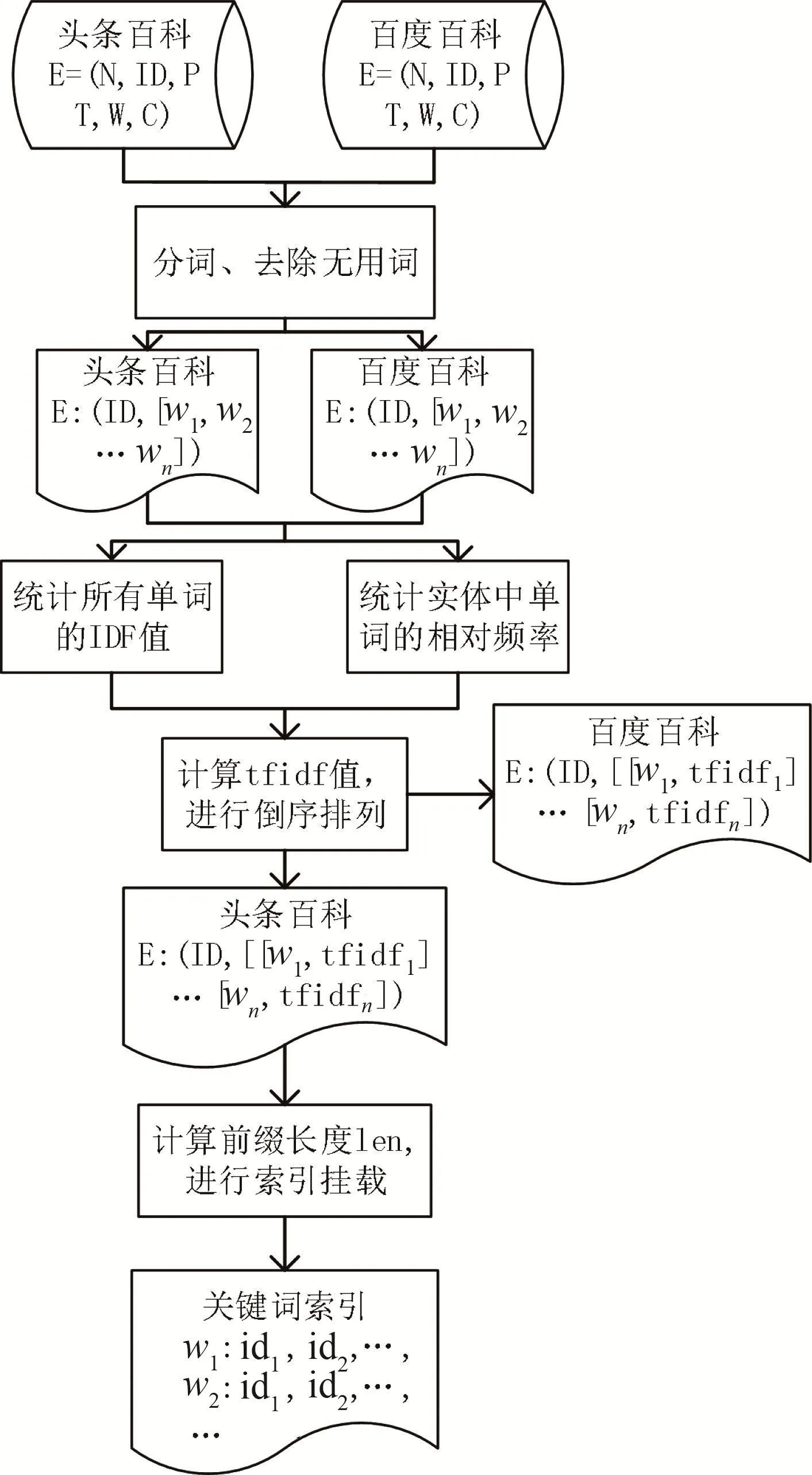
图3 关键词索引构建算法流程图
首先,针对两个百科知识库中的实体,将除了ID以外的所有文本信息作为语料,对其进行分词和去除无用词的处理,获取每一个实体的词向量表示:[w1,w2,…,wn]。
然后,计算统计两个百科库中所有单词的逆文本频率指数和词向量中每个单词的相对词频,由此获取词向量中每个单词的权重值,并将词向量按照权重值递减的顺序排列。
最后,遍历头条百科中的所有实体,根据式(16)和式(17)计算得到对应词向量的前缀长度k,以词向量的前k个词分别为索引键,对实体的id进行挂载。
2.3 候选集的获取
在2.2节中,通过构建索引对头条百科的所有实体的ID进行了挂载。对于来自百度百科的待对齐实体 E=(ID,N,PT,W,C),先根据实体的词条名称N,以及实体属性PT中可以获取到的一个或多个指称项,分别在实体指称索引库中进行搜索得到ID集合,获取这些ID集合的非重复并集,记作set1。然后,根据ID在百度百科词向量库中获取该实体的词向量,根据式(16)与式(17)计算词向量前缀长度k,在实体关键词索引库中对词向量的前k个单词分别进行搜索得到ID集合,对这些ID集合取并集,记作set2。最后,获取 set1与 set2的交集 set,set内的所有ID对应的实体就是待对齐实体E的最终匹配候选集。
2.4 BERT语义相似度计算
2.4.1 BERT预训练语言模型
BERT是由Devlin等人于2018年提出的一种预训练语言模型。该模型在OpenAI GPT和ELMo两种预训练语言模型的基础上进行了吸收与改进,BERT在沿用OpenAI GPT以Transformer为编码器的模型结构基础上,借鉴了ELMo的双向LSRTM编码单元,将GPT的单向语言模型改造为双向语言模型,由此可以在每一层中联合前后两个方向的上下文信息进行训练,以获取更强的信息捕捉能力。作为预训练语言模型,BERT需要预先通过使用海量的文本语料数据(例如百科数据库)来进行自监督学习,用来为单词获取一个优秀的特征表示。在此基础上,只需要在为BERT添加一个合适的输出层,对模型进行微调就可以完成问答、命名实体识别、预测句子相似性等下游的 NLP(Natural Language Processing)任务。
如图4所示,BERT是一个多层双向Transformer结构的训练模型。在模型中,Ei为输入句子中单词的编码表示,是3个词嵌入特征的和,3个词嵌入特征是:单词嵌入(Token Embedding)、位置嵌入(Position Embedding) 和段嵌入 (Segment Embedding)。Trm为 Transformer结构,由于 BERT是以获取更好的单词特征表示为目标,内部只是采用Transformer作为编码结构。Ti是已经训练好的单词Ei对应的词向量。
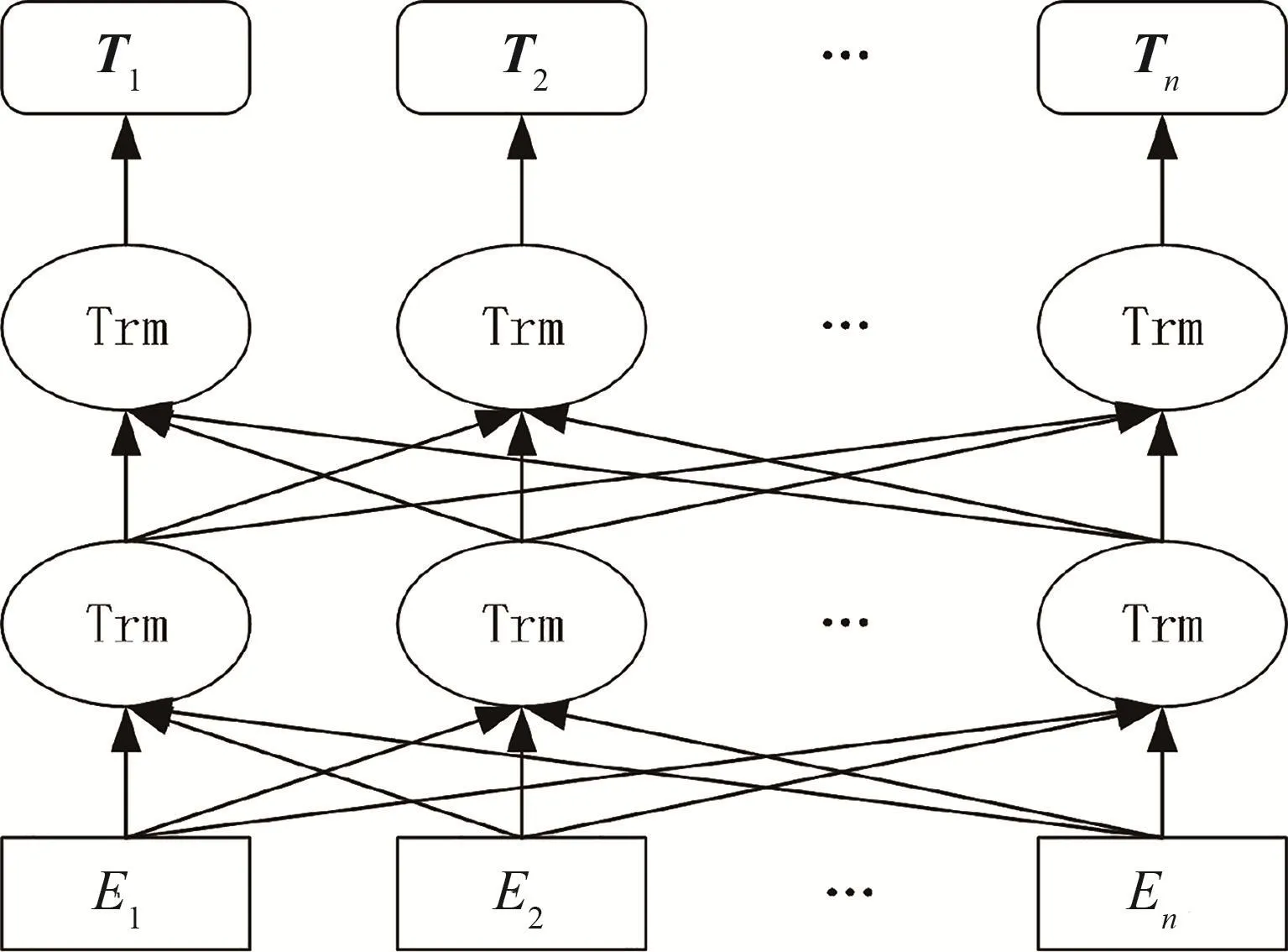
图4 BERT网络结构图
在BERT中,原始输入是两个句子,两个句子间使用[SEP]符号进行分隔。在两个句子的开头还有一个[CLS]符号,表示该特征的数据用于分类任务。输入表示部分由单词嵌入、位置嵌入和段嵌入3个特征之和表示。单词嵌入是由句子经过Word Piece处理后得到的词表示;位置嵌入是学习得到的单词位置信息的向量表示,将单词位置关系引入模型,可以解决BERT中注意力机制带来的顺序信息丢失问题;段嵌入是用于表明单词属于哪个句子。
2.4.2 基于BERT的语义相似度计算
目前,可以考虑两种方式利用BERT模型计算两个句子间的语义相似度。一种方式是将句子间语义相似度的计算看作是二分类问题,通过训练好的优化模型来获取句子对相似度为0或者为1的概率。该方法存在两个问题,首先,通过微调训练优化模型需要有标记好的样本数据,但是“不相似句子”的样本难以学习,并且需要较多样本数据。其次,使用二分类获取特征,输出主要集中在两个向量附近,容易导致相似句子对间的区分度不高。因此本文将采用第二方式,利用BERT模型来获取句子的向量表示,然后通过计算两个句子向量表示的余弦值来获取句子间的相似度。目前,谷歌已经为多种语言提供了BERT预训练语言模型,本文将采用的是哈尔滨工业大学讯飞联合实验室发布的针对汉语的BERT预训练语言模型,该模型使用中文维基百科数据进行训练,并在谷歌发布的BERT模型上有所升级,在中文NLP任务中效果更佳。
对于句子L与S,通过BERT分别获取其向量表示AS=[S1,S2,…,Sn],AL=[L1,L2,…,Ln],句子L与S间的相似度计算公式为

2.5 实体相似度计算
在前面已经将百科知识库A和百科知识库B中的实体进行了索引挂载,当需要将知识库B与知识库A进行融合时,遍历知识库B中所有实体,依次找到知识库A中可对齐的实体。例如,对于知识库B中的实体Eb,首先根据2.3节的方法获得知识库A中可能与之对齐的候选实体集合EA={Ea1,Ea2,…,Ean}
然后一次计算Eb与EA中所有实体的相似度。实体相似度的计算主要包括属性相似度计算和非结构化文本相似度计算。在计算过程中将共同使用基于编辑距离相似度计算和基于BERT的语义相似度计算。
2.5.1 属性相似度计算
属性信息是百科知识库中的半结构化文本信息,展示了百科实体重要的个性化特征。例如对于同名的人物实体,不同的出生地或者职业都可以很大程度地区分两个实体。由于不同知识库之间的数据异构性,对于相同属性的表述不同,使得如何对两个实体之间的属性进行对齐并计算属性值的相似度并不容易。本文将通过编辑距离和BERT预训练语言模型找到可以匹配的属性名,然后通过BERT预训练语言模型计算属性值的相似度,最后加上属性的权重得到两个实体间的属性相似度,主要流程如图5所示。

图5 实体属性相似度计算流程图
关于属性名的匹配,由于不同知识库之间的描述体系存在差异,属性间存在异构性,难以完全通过属性名是否相同来判断两个实体的属性值描述的是同一属性。目前研究中都是通过预先对两个不同知识库的实体数据进行属性统计,经过人工比对编订属性映射规则。该方法有一定的作用,但是对于信息不断扩充、属性个数不断增长的知识库来说,或者对于知识融合过程中出现新增数据源需求的任务来说,该方法需要不断地进行人工干预,具有一定的局限性。
如图5所示,对于实体E1的属性attr1,首先在E2的属性集合 attrs查询同名属性 attr2;未找到则使用编辑距离计算属性名相似度,找到attrs中与attr1的相似度最高且大于 edit⁃threshold的属性attr2;否则,使用 BERT模型计算属性相似度,找到相似度最高且大于bert⁃threshold的属性attr2;未找到则说明E2中没有与 attr1匹配的属性。使用BERT模型计算两个属性值的语义相似度,记为Sim1。同理,对于E1中的属性attr2,…,attrn,找到与之匹配的属性并计算相似度 Sim2,…,Simn,加上属性对应权重并归一化得到实体属性相似度SimAttr。

同一个知识库中不同属性对于实体具有不同的区分度,例如,若实体E的属性“中文名”为“蚩尤”,而在知识库中只有一个实体的属性“中文名”为“蚩尤”,该属性就具有很好的区分度。但是如果在知识库中有很多实体的属性“出生地”是“江苏”,该属性就具有较弱的区分度。由此,可以获取该属性的局部权重为

三元组的含义见式(4),如果有10个人的出生地是江苏,那么W(出生地,江苏)=0.1。每个属性与其任意一个属性值都有一个局部权重,则该属性的总权重为局部权重的调和平均数:

2.5.2 非结构化文本相似度计算
在百科知识库中每个实体都有一段简短的非结构化文本信息来对实体进行简要的总结和描述,通过BERT特征提取的方法来获取短文本的向量表示,Des=[w1,w2,…,wn],然后计算文本向量的夹角余弦值作为相似度。

其中,Des1为实体E1的文本向量表示,Des2为实体E2的文本向量表示,SimDes(Des1,Des2)为两个实体间文本相似度。
2.5.3 实体相似度计算
综合实体的半结构化属性信息、非结构化文本信息,可以通过式(23)计算两个实体间的相似度。式中,w1表示实体属性相似度的权重,w2表示实体文本相似度的权重,权重的最佳值将通过多组实验获取。

在知识库A中实体E1与知识库B中对应的候选实体集合EB中所有实体计算完实体对相似度后,得到相似度最大且大于指定阈值的实体对(E1,E2),将作为E1的对齐结果输出。
3 实验
3.1 数据集
为了验证算法的有效性,本文选择使用百度百科和头条百科两个质量较高的百科知识库作为数据来源。根据项目需求(面向教育领域资源的融合),本文设定了化学、计算机、生物、文学4个学科以及人物一共5个类别,并通过网络爬虫技术从头条百科中分别获取了与5个分类相关的200个词条作为待对齐实体,然后根据每个词条的词条名以及从词条属性中捕获的别称、别名等同义词获取一个触发词集合,从百度百科中爬取所有与触发词集合中同名的实体,并且通过人工筛查,标注了百度百科数据集中能够与头条百科数据集对齐的实体,统计了可对齐实体对数量。实验所用数据统计见表1。

表1 实体对齐数量统计
3.2 评价标准
传统的评价标准主要从精度(Precision,P),召回率(Recall,R)和总和指标F 值(F⁃measure,F)3 项来进行评价。由于本算法还设计了索引算法来提高实体对齐效率,因此,将在评价标准中加入缩减率(Reduction Ration,RR),用来评价候选匹配对的筛选能力。借鉴二分类中正类(Positive)和负类(Negative)的概念,以 TP(True Positive)表示能够被算法正确匹配的实体对个数,FP(False Positive)表示被算法错误匹配的实体对个数,TP(True Negative)表示未被算法匹配的不存在可对齐实体对的个数,FN(False Negative)表示未被算法匹配的存在可对齐实体对的个数。
(1) 精度
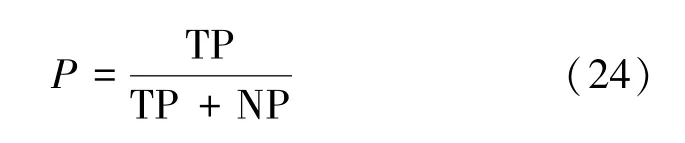
也称为查准率,表示算法获取到的准确对齐的数量和算法获取的所有对齐实体数量的比值,可以衡量对齐算法正确匹配实体对的能力。
(2) 召回率

也称为查全率,表示算法获取到的准确对齐的数量和可对齐实体对数量的比值,可以衡量对齐算法发现正确对齐实体对的能力。
(3)综合指标F值
F⁃measure,也称为 f⁃score,是查准率与查全率的调和均值,用来综合考虑两者的一个评价指标。
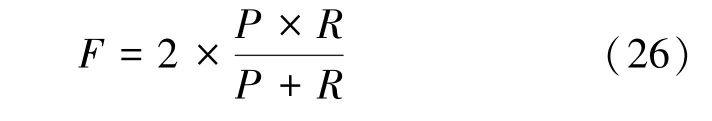
(4) 缩减率

式中,Ncandicates表示算法筛选出来的候选对的数量,Nall表示全部待匹配实体对的数量。缩减率可以用来衡量算法减少实体对匹配计算量的能力。
(5)候选对完整性

式中,Nright表示算法筛选出来的候选对中可匹配实体对的数量,Nall_right表示数据集合中所有可匹配实体对的数量。候选对完整性可以用来衡量算法产生的候选对的质量,该指标值过低会导致正确的匹配对被筛除,从而影响算法整体的召回率。
3.3 参数设置
本文算法需要设置的参数总共有5个,第一个参数是 entity_threshold,是在最后用于判定两个实体对是否对齐的实体相似度阈值,当本文算法获取的匹配实体对的相似度低于该值时,会被排除在结果集外;第二个参数是index_threshold,是在构建关键词索引时需要设置的阈值,本文算法需要根据该值确定关键词挂载数量,具体原理见2.2.2节;第三个参数是Wattr,是计算实体相似度时用到的属性相似度的权重,与之相伴的是实体描述性文本相似度的权重Wdesc,两者之和为1;第四个参数是edit_threshold,在利用编辑距离进行属性名匹配时设置的最小阈值;第五个参数是bert_threshold,是使用编辑距离获取匹配属性名失效后,利用BERT语义相似度进行补救时设置的最小相似度的阈值。
由于实验一共有5组不同学科领域的数据集合,在以化学学科数据集合为例,展示参数筛选过程,其他学科数据集合的最终参数将以表格的形式给出。在选取参数之前将给每个参数赋予一个初始值,参数entity_threshold的初始值设为0.9,参数 index_threshold的初始值设为0.6,参数Wattr的初始值设为0.4,参数edit_threshold的初始值设为 0.96,参数 bert_threshold的初始值设为0.96,后面参数值的选取将在改组初始值的基础上进行调整。
3.3.1 参数 entity_threshold 选取
为了获取entity_threshold的最佳取值,首先在[0,1]区间内以0.1为步长对参数进行取值实验,初步获取最佳值0.8及其变化范围[0.7,0.9],然后在该范围内进行参数调整实验。实验结果如表2所示。

表2 参数entity_threshold选取实验结果 %
分析表2中的数据,参数值在[0,0.7]区间范围内时,P、R、F维持不变,从 0.7开始,随着 entity_threshold值的不断增加,准确率P不断上升,召回率不断下降,综合指标则是先上升后下降的趋势。在参数取值为最大值1时,准确率达到最高100%,而召回率降至1.05%。在 entity_threshold的取值为0.85时,P为96.17%,R为91.19%,F得到最高值93.62%。由数据变化趋势不难发现,实体对相似度阈值越大,对匹配实体对的筛选越严格,只有实体间的相似度达到指定阈值才能被认定为可匹配,因此造成准确率的上升和召回率的下降。
3.3.2 参数 index_threshold 选取
参数index_threshold是在构建关键词索引时需要设置的阈值,本文算法需要根据该值确定关键词挂载数量。若该值过低,会导致关键词挂载数量较多,难以有效剔除无用的获选实体对,因此对该参数的取值将从0.51开始。先以0.1为步长初步确定取值范围,然后进行微调确定最佳值。在3.3.1节实验的基础上将entity_threshold从初始值0.9改为0.85,实验结果见表3。

表3 参数index_threshold选取实验结果 %
分析表3中的数据,参数值在[0.51,0.9]区间范围内时,P、R的值在0.52~0.59之间以及0.65处有局部的反复,由于随着参数值的增加,实体关键词挂载数量减少,候选实体对的筛选力度加大,实体对齐的精度P在上升,而召回率R在下降。综合指标F则是先增后减,在参数值为0.55~0.58时取最大值94.18%,对应的P为96.22%,R为92.23%。
3.3.3 参数Wattr选取
参数Wattr是计算实体相似度时用到的属性相似度的权重,与之相伴的是实体描述性文本相似度的权重Wdesc,两者之和为1。在3.3.2节实验的基础上将index_threshold从初始值0.6改为0.56,实验结果见表4。
分析表4中的数据,当参数值为0时,表示实体相似度完全依赖于实体文本相似度,而当参数值为1.0时,表示实体相似度由实体属性决定,在这两种情况下,算法依然有较好表现,前者的效果更佳。当参数取值为0.5时,P、R、F同时达到最佳值,分别为96.22%、92.23%和94.18%。
3.3.4 edit_threshold 与 bert_threshold 选取
参数 edit_threshold与 bert_threshold主要是在计算属性名相似度时设置的阈值,用于筛除错误的匹配属性名。选取参数的方法与3.3.1节类似,在3.3.3节实验的基础上将Wattr从初始值0.4改为0.5。
这两个参数确定得到的实验结果变化较为简单,edit_threshold 的取值以 0.8 为界限,[0,0.79]区间内R、P、F的值分别为 96.09%、89.12%和92.47%;[0.80,1.00]区间范围内R、P、F的值分别为96.22%、92.23%和 94.18%,因此可给 edit_threshold取值0.92。在此基础上选取Bert_threshold值,bert_threshold 的取值以 0.90 为界限,[0,0.89]内R、P、F的值分别为97.17%、89.12%和92.97%;[0.90,1.00]区间范围内R、P、F的值分别为96.22%、92.23%和94.18%,因此可给 edit_threshold取值0.95。
3.3.5 参数设置小结
在3.3.1至3.3.4节中以化学学科领域数据集展示了参数选取的过程,其他4类学科数据集实验参数的选取过程相同,获得的最佳参数与实验结果见表5。

表5 5组数据集参数选取结果
3.4 实验结果
为验证算法有效性,本文还采用了基于LDA主题模型的实体对齐算法针对5组数据进行对比实验。除此之外,还将5组数据作为一个大的数据集合与王雪鹏等[5]的工作进行性能对比。
(1)如表6所示,本算法在5组数据的各项性能表现都明显优于基于LDA的实体对齐算法。基于主题模型的百科知识库实体对齐算法主要是利用LDA主题模型对百科实体的非结构化文本数据进行建模,进而获取实体的特征向量表示,最后通过使用余弦计算实体相似度来完成实体对齐任务。在该算法中存在两个问题,其一,只使用了百科实体的非结构化文本信息,而没有利用百科实体的属性信息;其二,单纯使用LDA,未能较好地达到相似度计算效果。因此,其算法准确率、召回率及综合评价指标F的值相对于本文算法较低。

表6 本算法与LDA算法比较 %
(2)在第二组对比实验中,根据之前的大量实验结果数据,综合考虑选择一组参数值,entity_threshold取值为0.85,index_threshold取值为 0.53,edit_threshold 取值为 0.90,bert_threshold 取值为0.87,Wattr取值为0.5。并将5组数据集合为一组进行综合测试后与王雪鹏等人的算法进行比较。如表7所示,相对于王雪鹏等人的算法,本文算法的准确率略低,但召回率上有极大的提高,综合指标F的值也高出不少。但是,本文算法的准确率未能胜出,主要原因在于王雪鹏等人使用人工构建的方式设计不同知识库之间属性的映射规则,不会出现属性映射错误的问题。本文算法为了避免人工介入,提高算法的扩展性与适配性,采用基于语义相似度计算的方式自动获取不同知识库之间的属性映射,无法做到人工构建的无差错,因此可能出现少数错误的属性映射。

表7 算法比较 %
在王雪鹏等人的算法中,相对于本文算法有两点优势:其一,充分利用百科实体的网络语义标签,不仅用到了百科实体的属性信息、非结构化文本信息,还有效利用了类别标签来完成实体对齐任务;其二,使用人工对比校验,对两个不同百科知识库的属性名进行了映射规则的编辑,可信度极高。因此,其算法的准确率要高于本文算法。但是其算法也存在三点劣势:其一,简单地利用实体的词条名来获取获选实体集合,容易丢失同义不同名的实体对,是导致其召回率过低的重要原因之一;其二,对非结构化文本信息简单采用TF⁃IDF提取关键词构建词向量方式,语义相似度计算的精度不足,因此该算法在已有优势的基础上未能与本文算法在准确度上拉开太大差距;其三,使用人工进行属性名映射,面对百科知识库实体信息的不断扩充,缺乏自主扩展性。
(3) 本文使用缩减率(Reduction Radio,RR)评价索引减少计算实体对匹配数量的性能,使用候选对完整性(Paris Completeness,PC)评价索引得到的候选集的质量,具体定义与作用见3.2节。通过表8可以看出,候选集的完整性高达98.52%,可以有效保证质量。缩减率也达到99.94%,可以帮助筛除大量无效实体对计算,提高计算效率。

表8 算法的缩减率与完整性 %
4 结束语
近年来,随着互联网技术的迅速发展,涌现出了维基百科、头条百科、百度百科等大量优秀的知识资源与知识社区。这些数字教育资源为人们的学习和生活提供了极大的便利,但是单一的知识来源覆盖率低,无法充分满足用户的需求,不同知识库之间存在较强的异构型,难以快速有效地集成与共享。因此,多源知识库的实体对齐作为知识库融合的关键技术,具有重要意义。
本文提出的基于BERT的多源知识库索引对齐算法,经过验证能够较好地解决多源知识库实体对齐问题。本算法在缩减率达到99.71%~99.81%的情况下,针对5组不同学科领域的百科实体均能达到较好效果,在准确率能够达到91%~96.22%的同时能够达到92.23%~97.33%的召回率,可以实际应用于多源知识库的实体对齐工作。同时,本文算法的索引结构在缩减率高达99.94%的同时保证了98.52%的完整性,能够有效提高实体对齐效率。在以后的工作中,可以考虑将实体的分类标签作为新的实体特征来进行对齐工作,并在算法中加入实体间的结构相似度来提高实体对齐准确率,并通过实体关系的挖掘更多匹配实体,从而提高算法召回率。
猜你喜欢
中国外汇(2019年18期)2019-11-25 01:41:54
创新作文(5-6年级)(2019年3期)2019-09-03 05:14:59
制造技术与机床(2019年6期)2019-06-25 10:17:46
作文评点报·低幼版(2018年31期)2018-09-27 12:21:52
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
中国交通信息化(2016年9期)2016-06-06 07:42:23
图书馆研究(2015年5期)2015-12-07 04:05:48
小溪流(故事作文)(2014年6期)2014-07-31 14:21:14
