
在救灾智联网中推测信息孤岛救助需求强度的空间信息扩散模型
2021-05-27 01:43黄崇福王润东
自然灾害学报 2021年2期
黄崇福,田 雯,,王润东
(1.北京师范大学,环境演变与自然灾害教育部重点实验室,北京 100875; 2.应急管理部/教育部减灾与应急管理研究院,北京 100875)
《国家综合防灾减灾规划(2016—2020年)》明确提出,确保自然灾害发生12 小时之内受灾人员基本生活得到有效救助。在研的国家重点研发计划项目“重大自然灾害评估、救助与恢复重建技术研究与示范”(2018-2021年)考核要求,重大自然灾害启动应急响应起算的3小时内,所制定的救助方案中,救助资源须精准配置灾区的救助需求,最大限度地发挥救助资源的效用。由于重大自然灾害发生后的几个小时内,人们全力搜救受灾人员,救助需求并不明了,因此,急需关键技术,快速而较准确地评估救助需求,较大程度提高精准救助决策能力,确保受灾人员在灾后12小时内得到有效救助。
救助需求与灾情有必然的联系,但救助需求复杂而多变。国内外对灾情的快速评估,已有大量的研究和实践[1-3]。广泛使用的HAZUS、PAGER等系统,虽已有了互联网的元素,但主要功能,还是用经验、半经验和分析模型:根据记录或推测到的自然事件量级,用统计回归历史灾害数据得出的经验公式,根据灾区的自然和社会经济情况,推测出人员伤亡等灾情。例如,一旦发生破坏性地震,可根据震级对灾情进行粗估[4]。这类远隔千山万水的快速评估,我们称之为“隔空判灾”[5],缺点是精度较低,大多只能保证不出数量级错误(相差在10倍之内),而且只能在县或县以上地理单元进行[6],无法细化到乡镇,评估结果支撑不了精准救助。
互联网的普及,为较高精度地快速评估灾情和救助需求,提供了一条路径,文中称之为“采点外推”:由已观测地理单元得到的数据,推测空白地理单元中的情况。已观测单元是采点,空白单元是信息孤岛。外推的依据,是从已观测地理单元得到的数据中总结的因果关系。推测,是一种判断各种各样情况的行为,甚至于有纯主观性的层次分析法[7],半主观的模糊综合评价[8],常见的则是统计回归[9]。
当我们将灾情或救助需求以地理单元为数据采集点时,灾后第一时间能获得的数据量并不多,样本较小,加之非线性问题,传统的统计回归,精度难以保证。信息扩散模型对样本容量的要求不高,能构造出可用的因果型模糊关系[10],而且,信息扩散原理不仅在概率空间有效,Mako用解析几何学的方式证明了在几何空间中也有效[11],从而产生了地理空间上的信息扩散技术,我们能够借助自然属性和社会经济属性的背景数据推测空白单元的灾情数据[5],自然也可以实现灾害救助需求推测。虽然人们也可以利用传染病模型近似模拟灾害扩散过程,预测救助需求[12],但没有采点信息的支持,只能是空谈。应用可变集理论建立灾害应急物资分配模型[13],需用人的经验知识对各种目标相对重要度进行量化,更不具有客观性。
“采点外推”的基础是及时获得灾区现场的部分信息。这一工作,只能在互联网平台上才能实现。我们在智联网[14]中加上救助需求模块,使之能在线推测信息孤岛中灾情和救助需求。这类的智联网,称为救灾智联网[15]。本文以采点外推重大自然灾害中信息孤岛应急救助需求为目的,研究有针对性的空间信息扩散模型,并以2019年长宁6.0级地震为例,演示了推测过程。
为便于读者较系统地了解本文的工作,我们先界定一些与救助需求相关的概念,然后介绍智联网中的救助需求模块。以此为基础,才展开空间信息扩散模型和案例的研究。
1 大灾中救助需求的界定、评估及推测
2007年11月1日起施行的《中华人民共和国突发事件应对法》,自然灾害事件发生后,人民政府采取应急处置措施,保障食品、饮用水、燃料等基本生活必需品的供应。根据中华人民共和国国务院于2010年7月8日发布,自2010年9月1日起施行《自然灾害救助条例》,人民政府须紧急转移安置受灾人员;紧急调拨、运输自然灾害救助应急资金和物资,及时向受灾人员提供食品、饮用水、衣被、取暖、临时住所、医疗防疫等应急救助,保障受灾人员基本生活。
重大自然灾害救助属于社会救助的子系统[16],指某地发生自然灾害且对当地及相关地区造成重大破坏后,政府组织社会各界力量对受灾地区灾民进行紧急抢救和援助,使灾区尽快恢复灾前状态。而随着研究的深入,灾害救助需求的范围逐步丰富,不仅包括物质需求,还包括精神需求、心理需求,即灾后情感的沟通、心理的恢复。具有代表性的研究,如孙燕娜等[17]认为救助需求是指当某种自然灾害突然发生,灾害发生地区的居民身体和房屋受到损害,日常生活受到破坏,灾民为维持身心健康和基本生活,对外界提出生命生活心理救助的需要。王玉海等[18]认为灾害救助需求不仅仅是物资需求,还有更为特别的心理需求,不只立足于灾民的个体需求,还有更为重要的安全秩序整体需求,即基于灾民整体的治安保障需求和生命线需求,以及基于灾民个体的生命健康需求、生活保障需求和心理抚慰需求。综上,灾害救助的各种需求可归结为恢复灾前状态的需要。
广义而言,灾后的人员搜救活动和对灾区的物资援助等许多工作,甚至于宣传鼓动,都属于自然灾害应急救助的任务。显然,罗列万象的应急救助任务涉及的救助需求,并不必都要及时满足。但文中所指大灾中的救助需求,仅指灾民对食品、饮用水、衣被、取暖、临时住所、医疗防疫等应急物资的需求。
早在1972年,联合国经济委员会为拉丁美洲和加勒比地区提出的损害和损失评估(Damage and Loss Assessment, DaLA)方法中,就已经考虑了灾害对个人生计和收入的影响。目前,联合国相机构对救助需求评估主要涵盖4 个方面的内容:①评估灾害对社会产生的影响;②灾害应急抢险需求与方案优化;③救助资源可获得性;④促进和加速灾后恢复与区域发展的可行性。2012年8月28日,我国民政部印发《关于加强自然灾害救助评估工作的指导意见》包括倒损农房重建救助需求评估、过渡期救助需求评估、冬春救助需求评估以及相应的倒损农房恢复重建救助、过渡期救助和冬春救助工作的灾后救助绩效评估。
通常,人们将救助需求评估,作为灾害救助评估一部分,被认为是一种用于决策、控制与规划自然灾害应急救助活动管理的重要手段[19-21]。陈鹏等[22]将自然灾害救助评估按照应急救助过程分为为灾害应急救助活动提供决策支持的自然灾害应急快速评估、为灾害恢复重建提供决策支持的灾后详细评估,其中,应急快速评估以灾情评估和应急救助需求评估为主要内容。胡俊锋等[23]认为救援救助反映区域综合减灾能力。廖永丰等[19]认为救助需求与救助资源可获得性是灾害救助评估的核心。因此,灾害救助评估重点在于灾害救助需求的评估。如今,灾害救助需求评估对象逐渐由传统的受灾个体外延到社会影响、经济以及生态环境等。
从灾害应急决策的理想化角度讲,救助需求评估,应该细化到各受灾点对各种应急物资的需求量。根据大量的历史救灾实践和数据,很容易用回归方法隔空对各种应急物资的需求量进行评估,但对乡镇而言,精度太低,支撑不了精准救助。
本文根据“采点外推”的原理,由已观测地理单元得到的(并非隔空评估所得),能表征应急救助需求的数据,推测空白地理单元中的救助需求。在已观测地理单元数量远大于空白地理单元数量时,空白地理单元称为信息孤岛。由于大灾后第一时间,须全力组织搜救,尽最大努力减少人员伤亡,防范次生灾害发生,短时间内,无法统计并核实各种应急物资的具体需求量,“采点外推”只能推测出与应急救助需求相关的某种表征量。具体应急物资的需求量,则是根据表征量与需求量的关系,建立回归关系,进行评估。本文所指大灾中救助需求的评估,是指对信息孤岛中救助需求强度的评估,而非应急物资需求量的具体评估。
由于“采点外推”须依据已观测地理单元得到数据,推测空白地理单元中的救助需求,所以本文所指大灾中救助需求的推测,是指用周边已知事实对信息孤岛内情况的推测。这种推测,是以各地理单元的自然属性和社会经济属性等背景数据为桥梁而实现的。
2 救灾智联网中的救助需求模块
应急响应精准救助的要点是“快”。“采点外推”必须依托互联网,只有能及时采集和处理数据,在规定的时间之内,推测信息孤岛中救助需求。任何离线系统,都承担不了这项工作。我们将本文建议的空间信息扩散模型,嵌入智联网,形成救灾智联网中的救助需求模块。
由互联网联结多个智能体,并通过嵌入的模型集个体小智慧为群体大智慧的网络平台,称为智联网,用于风险分析可缓解假设规律、数据不足、风险变化、难保可靠等4个问题[24]。目前,在自然灾害研究领域,人们已经研制出6个智联网平台。台风灾害风险分析智联网[25]中以柔性知识捕获器作为处理模型,应用于温州地区的台风灾害水产养殖保险的可行性需求调查,对智联网平台的理念和模型进行了成功的验证。内涝风险分析智联网服务平台[26]使用属性拼图技术对原始的经验信息进行优化整合,通过“雨强-水深”模糊关系模型,在线实现了基于降雨强度的积水风险估计。海洋环境风险管理智联网平台[27]智联网平台信息来源和预处理方面提出优化方案,即中心化信息收集技术,并在围填海造地项目对天津自然灾害抵御能力的影响评价实例研究中取得良好效果。地震宏观异常的智联网服务平台[28]基于模糊数学方法,将一线地震工作者对地震宏观异常群强度的经验判断值作为输入,建立了以模糊关系矩阵表达的共识性宏观异常群测度空间,为通过观测震前宏观异常来预报地震提供了一种可能的辅助手段。风险时效性评价的智联网服务平台[29]借助因素藤理论构建了风险时效性评价模型,并用于北京延庆区果树冰雹灾害概率风险评价。风险沟通智联网服务平台[30]搭建了针对洪水灾害的风险沟通平台,并将其尝试用于宁波市洪水灾害风险管理实践。上述智联网,是为风险分析和管理而研制,对反应时间并无要求。推测信息孤岛中救助需求的救灾智联网,则要求在很短时间内完成工作。因此,除了嵌入推测需要的数学模型,还需要有灾前的背景数据库,更需要采集灾后信息的工具。
在救灾智联网中,我们使用MySQL作为数据库管理系统,使用服务器端网络编程语言PHP来进行数据库操作和数学计算,并使用HTML等前端语言将数据库中的信息按照用户要求的方式,通过终端界面来呈现给用户,而采集灾后信息的工具是网络爬虫。
救灾智联网数据库包括背景数据、灾情数据、用户信息3个主体,对应设计3张数据表[15],如图1所示。救灾智联网的用户为灾害管理人员,用户信息表包括编号、姓名、学历、工作单位等字段,用于记录其基本身份信息,同时据此划分用户等级,对应享有不同的数据管理权限。背景数据表和灾情数据表均以研究区行政单元为单位进行记录,前者用于记录各行政单元的自然地理属性和政治经济属性,后者用于记录灾害发生后各行政单元的灾情信息。背景数据表的完善需要在实际应用前完成,属于数据库中的基础数据,可依据统计年鉴等进行日常维护。灾情数据表中的各字段是随着灾害发展而动态变化的,在救灾期间由灾害管理人员进行实时更新,同时也作为快速评估的输出值以弥补统计途径所得数据的不完备。
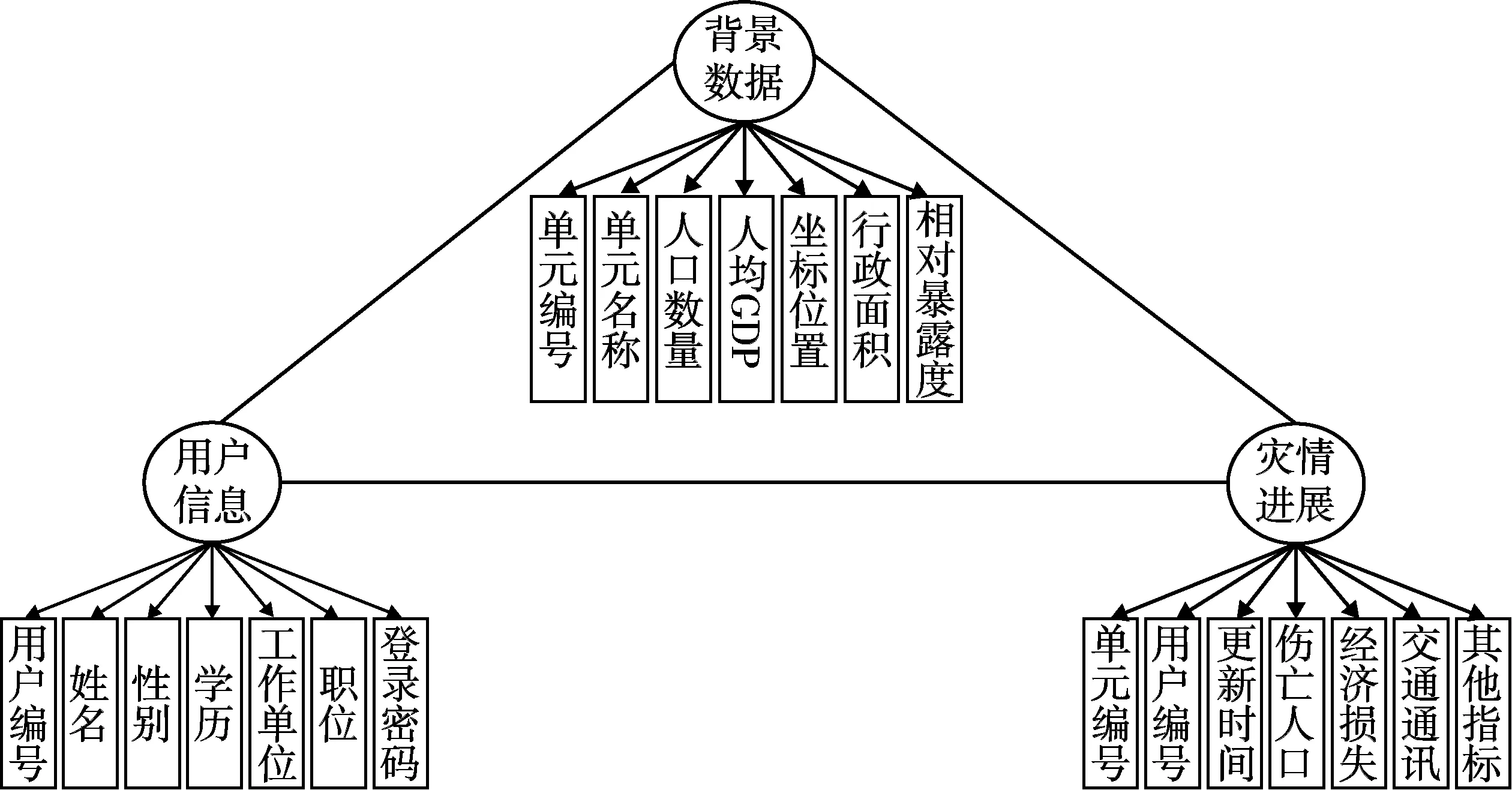
图1 救灾智联网数据库结构Fig.1 Database structure of Internet of Intelligences
模型计算代码单独编写进PHP文件并归于控制器模块,实现与数据库的交互,即数据读取和更新。开发工作用Yii框架,采用模块-视图-控制器(Model-View-Controller,MVC)的基本模式,其中模型代表数据、业务逻辑和规则,视图展示模型的输出,控制器接受出入并将其转换为模型和视图命令。采用Yii框架来搭建救灾智联网时,借助了其gii模块快速生成模型、视图和控制器模板,不需要重新编写业务逻辑,从而可以极大地压缩开发周期。在救灾智联网平台中嵌入灾情快速评估模块,充分发挥MVC模式逻辑清晰的特点,将任务合理分配至3个模块中配合实现。
灾情快速评估模块需及时采集和处理数据,互联网时代的到来使得灾情数据的实时获取成为可能。据《中国互联网发展报告2019》显示,我国网民规模已达8.54亿人,互联网普及率达61.2%,网站数量518万个[32],因此,网络数据是灾情背景数据的重要数据源。目前,数据采集方法主要有4大类,即数据库采集,采集对象需为开放性数据库;系统日志采集,主要用于收集业务平台日常产生的大量日志数据;基于智能终端的感知设备数据采集,对智能终端的数量和质量要求较高;基于网络爬虫和API的网络数据采集,其中,网络爬虫又称为Web信息采集器,是一种按照一定的规则从网站上自动下载网络资源的计算机技术[33],它能够高效率的批量下载网络数据,且能够获取位置信息[34],更为符合救灾智联网的背景数据采集需求和数据源特点,因此,救灾智联网使用Python编程语言编写网络爬虫程序,收集与灾情和紧急救援有关的互联网上的信息,包括指定关键字用从微博和微信收集信息。此外,我们提供了一种改进的基于属性向量的TextRank算法[31],用于数据挖掘和处理,该算法可以获取灾难说明,以帮助决策者了解灾难情况。其技术路径如图2所示。
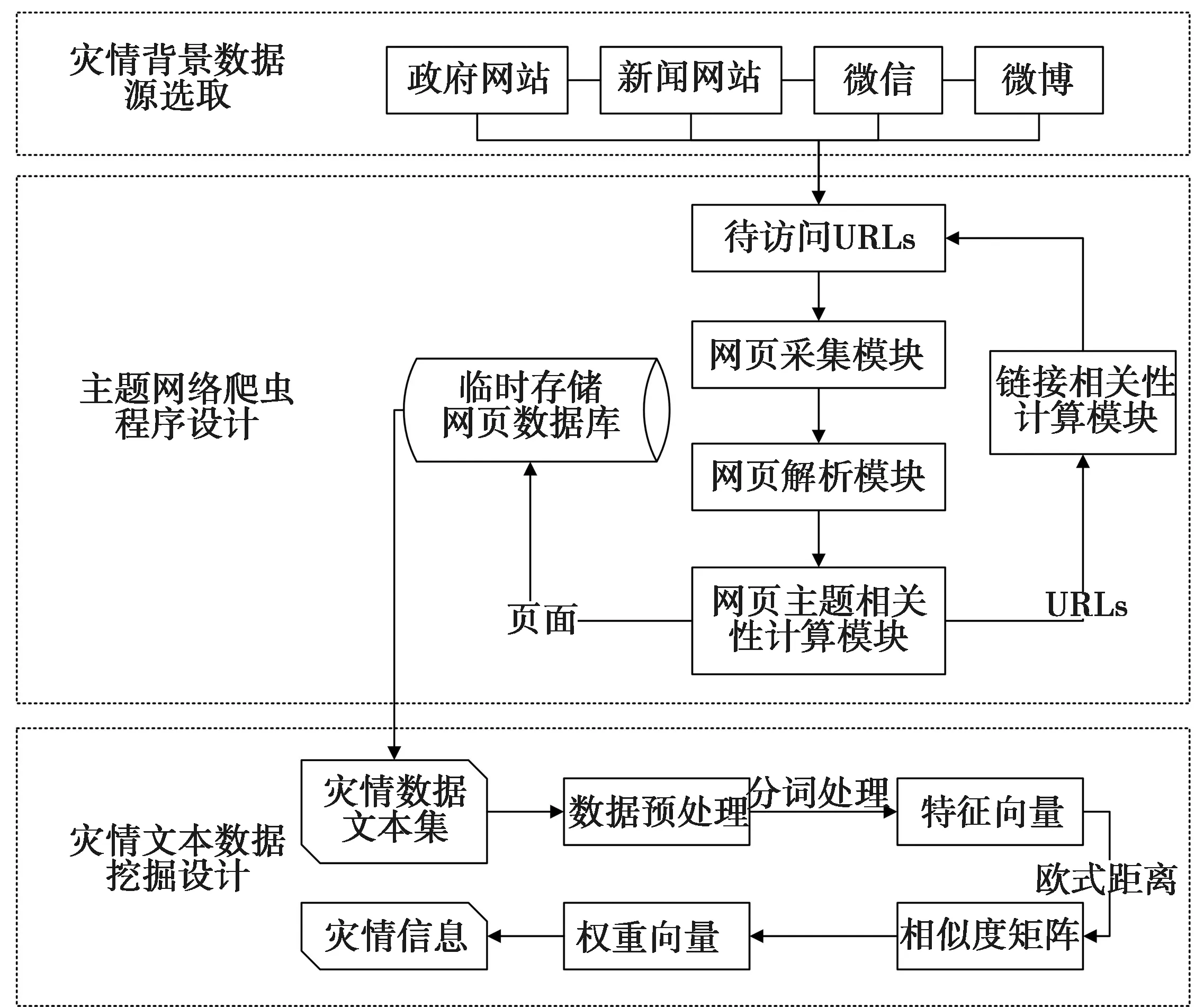
图2 灾情数据获取路径Fig.2 Path of disaster data crawler
3 用空间信息扩散模型推测救助需求
在重大自然灾害救助中出现信息孤岛时,有两条途径来获得信息。一条途径是尽快同孤岛中的灾民取得联系;另一条途径是用数学模型进行插值。由于时间或成本的制约,途径一常常走不通;由于有一定跨度的相邻地理单元上的大多数地理特征的属性值并不连续,插值法生成的数据,并无价值。
用地理空间信息扩散模型来推测信息孤岛的救助需求,基本原理是将信息孤岛周边的救助需求信息,扩散到信息孤岛中去。灾区各地理单元中的背景数据,为信息扩散起到桥梁作用。
不失一般性,假设某一重大自然灾害发生后,待救助区域G由n个地理单元g1,g2, ...,gn组成,其中q个地理单元的救助需求已知,n-q个的救助需求未知,且n-q远远小于q。救助需求已知的地理单元称为已观测单元,救助需求未知的地理单元称为空白单元。信息孤岛是救助需求未知的空白地理单元,量不多,有n-q个。同时,我们假设所有地理单元的自然地理特征、人口、经济状况、自救能力等背景数据已知。这类与救助需求有关且能在灾害发生前就能收集备用的数据,称为背景数据。
设一个地理单元的背景数据有t个分量,记为x1,x2,…,xt。救助需求记为y。于是,重大自然灾害发生后,我们能获得个一个数据集:
W={w1,w2,…,wq}
={(x11,x12,…,x1t,y1),(x21,x22,…,x2t,y2),…,(xq1,xq2,…,xqt,yq)}.
(1)
式中,wi=(xi1,xi2,...,xit,yi),i=1,2,…,q,是第i个地理单元的背景数据和救助需求数据。我们称W为救助需求学习样本。
用空间信息扩散模型推测救助需求,就是用信息扩散方式从W中学习y与x1,x2,...,xt的模糊关系,从而由信息孤岛地理单元的背景数据,推测救助需求。类似的工作,由传统的统计回归和人工神经元网络,都可以做。但多元统计回归的样本须很大,人工神经元网络遇到样本点之间不协调时无法收敛。信息扩散模型则同时解决了这两个问题。
空间信息扩散模型由多维正态扩散、模糊关系生成和近似推理三部分组成。
3.1 多维正态扩散
将式(1)W中第j个背景数据分量组成的集合记为Xj,即
Xj={x1j,x2j,…,xqj},j=1,2,…,t.
(2)
W中所有救助需求组成的集合记为Y,即
Y={y1,y2,…,yq}.
(3)
设Uj,j=1,2,...,t是用于扩散背景数据Xj,j=1,2,...,t的监控空间,而Ut+1是用于扩散救助需求数据Y。令λ=t+1,则背景数据监控空间和救助需求监控空间构成了一个λ维监控空间:
U1×U2…×Uλ.
(4)
式中,Uj={uj1,uj2,…,ujmj},j=1,2,…,λ理论上讲,监控空间中的监控点个数mj,可以因j的不同而不同,但为方便起见,通常所有监控空间中的监控点个数都用同一个数,并记为m。
令xiλ=yi,i=1,2,…,q,式(1)中W的样本点wi=(xi1,xi2,…,xit,yi),记为λ维样本点:
xi=(xi1,xi2,…,xiλ)∈W.
(5)
式(4)中的一个λ维监控点记为,
u=(u1k1,u2k2,…,uλkλ)∈U1×U2…×Uλ.
(6)
(此处kj∈{1,2,…,m},j=1,2,…,λ),我们用式(7)的λ维正态扩散公式,将x的信息扩散到u.
(7)
式中的扩散系数hj根据式(1)中的背景数据和救助需求数据,分别用式(8)进行计算[10]。
(8)
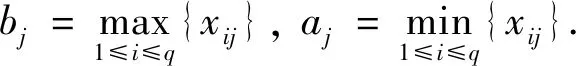
3.2 模糊关系生成
令
(9)
我们获得了一个U1×U2…×Uλ上的,由已观测单元得到的救助需求学习样本W的信息矩阵,如式(10)所示:
(10)
∀kλ∈{1,2,…,m},令
(11)
和
(12)
我们依据学习样本W,构造出了背景数据x1,x2,…,xt和救助需求y之间的因果型模糊关系矩阵:
(13)
3.3 近似推理
设z=(z1,z2,…,zt)为空白单元的背景数据,且
uλ-1=(u1k1,u2k2,…,uλ-1kλ-1)∈U1×U2…×Uλ-1.
我们可以用式(14)的λ-1线性信息分配公式将此z变为论域U1×U2…×Uλ-1上的一个模糊集,并取其隶属度最大值用式(15)进行归一化。
(14)
式中
(15)
ak1k2…kλ-1,kj=1,2,…,m,j=1,2,…,λ-1.
(16)
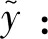
(17)
需要说明的是,在推测信息孤岛中救助需求时,我们使用的是多维线性信息分配公式将背景数据转化为模糊输入,而不是通常空间信息扩散模型中使用的多维正态信息扩散公式[35]。主要原因是,当可学习的样本点只有10个或稍多一点的话,统计规律并不明显,用较为粗糙的线性信息分配公式,符合反精确原理[36],可达到更好的效果。
3.4 救灾智联网中的空间信息扩散模型
以背景数据作为推测空白单元的桥梁,可以将已有观测数据的地理单元上的信息扩散到空白单元。只有背景数据与救助需求存在显著的因果关系,用地理空间信息扩散模型得出的救助需求才能较好地反应真实情况。根据大量数据分析,我们选用相对暴露度、人口,以及GDP作为推测救助需求的背景数据。空间信息扩散模型在救灾智联网的作用如图3所示。
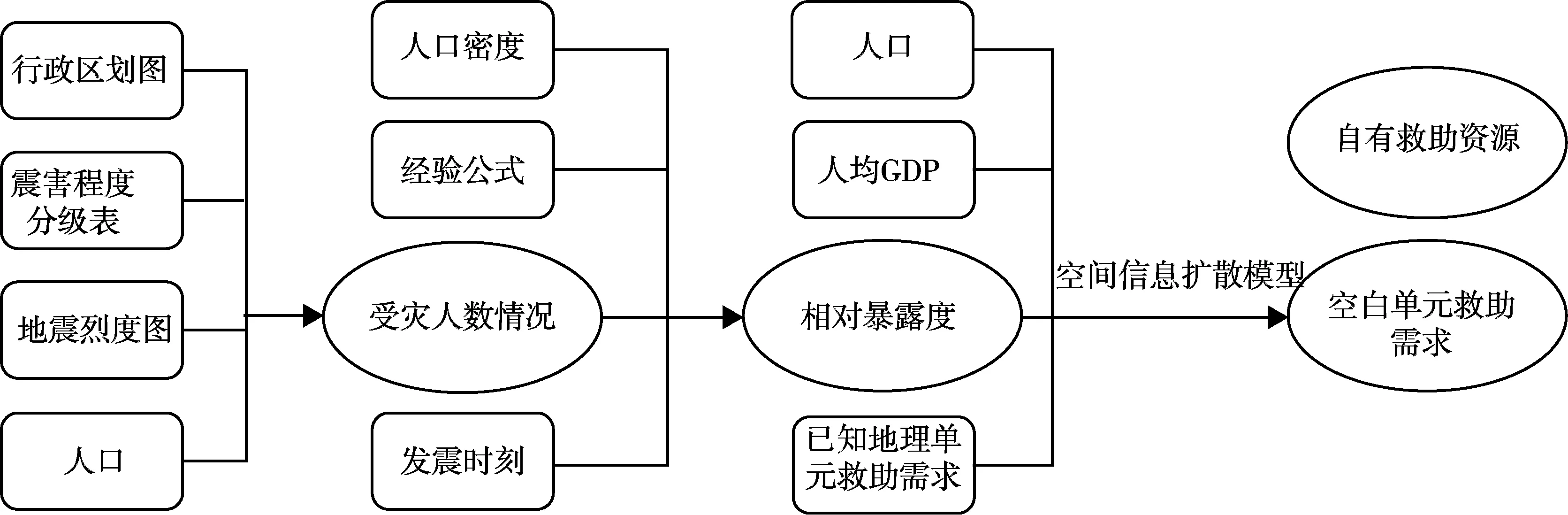
图3 空间信息扩散模型在救灾智联网推测救助需求的示意图Fig.3 Inference of rescue need in Internet of Intelligences based on geospacial information dissusion technology
这里的暴露度,是指提自然灾害风险暴露度,即,生命和财产在未来是否容易遭受自然事件或力量打击的一种状态。度量“相对暴露”比度量“暴露”容易一些。设A,B是两个面对同一风险源的风险承受体。如果此风险源暴发时,A比B更容易遭受打击,称A的相对暴露比B高[37]。
例如,对易发洪水的某一河流而言,离河较近的村子,相对暴露较高;地势较高的村子,相对暴露较低。约定相对暴露度最高的村子其相对暴露度为1,其它村子的相对暴露度,就可以通过与最高者的比较而确定下来。只有两个风险承受体与同一风险源的关系完全相同时,他们自身的属性,才会左右各自的相对暴露度。在同一设防水平下,人口和财富较多的风险承受体的相对暴露度比人口和财富较少者高。
4 长宁地震信息孤岛中救助需求强度的推测
4.1 地震案例及研究区域简介
2019年6月17日22时55分,四川省宜宾市长宁县(北纬28°34′N,104°9′E)发生6.0级地震,震源深度16 km。这是当年我国大陆地区震级最高、灾情最重的地震。地震灾害造成四川省宜宾、乐山2市16个县(市、区)35.9万人受灾,13人死亡,9.5万人紧急转移安置,3 500余间房屋倒塌,22.3万间不同程度损坏,直接经济损失56.2亿元。
长宁县位于四川盆地南缘,宜宾市腹心地带,经济发展以农业和旅游业为主,受自然灾害影响较为严重,应对灾害的能力有限。对于地震灾害来说,该区域处于较为活跃的云南昭通东侧到宜宾北东向地震带,地震灾害风险较高(长宁县地处江安、合江东西向断裂附近,又是华莹山、岷江、江安、合江断裂的复合区,地下介质破碎,不易积累大量应变能量,故以弱震形式释放),但其历史上未发生过破坏性地震。
根据已经获得数据的情况,我们以长宁县的梅硐镇、双河镇、龙头镇、硐底镇、花滩镇、竹海镇、老翁镇、古河镇、井江镇、梅白镇、铜鼓镇、铜锣镇、长宁镇等13个镇为地理单元展开研究。
4.2 救助需求强度数据
由于2020突发新冠病毒疫情的影响,本文的研究小组无法按计划前往长宁县,查实2019年6月17日地震发生后上述13个镇各种应急物资的具体需求量。我们用启动应急响应3小时内网络爬虫数据中受灾乡镇名字出现频率的强弱表征应急救助需求强度。老翁镇、古河镇和梅白镇在网络爬虫数据中没有出现,被视为信息信息孤岛。
(1)数据来源
数据来源于基于Python的网络爬虫模块,通过设置“长宁”、“长宁地震”、 “长宁6.0级地震”、“四川省长宁县6.0级地震”为主题关键词向量,以2019年6月17日22:55-2019年6月18日2:00为搜索时间段,以四川地区微博、新闻网站、长宁县政府网站为数据源,共获得四川地区微博数据17 547条、官方网站数据751条。
(2)数据处理
根据初步的改进TextRank算法对数据进行处理。通过增加属性向量,即通过灾害发生区域内的乡镇名称进行构造,记为Pi。对于给定的文本W,其中包含n个句子,经过预处理,即通过调用python的jieba库进行分词处理,得到词向量,并进一步得到各个句子的特征向量Si,进一步得到文本的特征向量矩阵,记为D={S1i,S2i,…,Sni};根据各个句子的特征向量,通过欧氏距离计算句子之间的相似度,最终得到相似度矩阵Q;对于特征空间中的每一个特征词Ki,通过TF-IDF(term frequency-inverse document frequency)算法进行评估,确定出词频较高的前n个词向量Fn;通过计算Fn中各个词与Pi的相似度,并对其进行从(0-1]等步长赋值,得到权重向量Wn;通过相似度矩阵Qi与权重向量Wn相乘得到向量Ai,即可以选择得分较高的几个句子产生文摘,并对应输出词向量Fn中的关键词。通过处理爬虫所得每条数据,获得文摘数据,部分灾情数据如表1所示。
(3)背景数据和救助需求强度
对于各项背景数据指标值,其中,人口数据、GDP数据来源于2017长宁县年鉴以及长宁县委县政府官方认证平台;相对暴露度为通过震中距计算所得[38],计算方法为首先通过经纬度计算各个地理单元震中距,根据震中距与相对暴露度成反比的情况[37],假设该地震的地震波衰减80km后,不会再对村镇建筑物造成破坏,设A为所研究地理单元建筑物,B为震中区域建筑物,以单元1梅硐镇为例,震中距αA=10.815 km,αB=0 km,则相对暴露度EA(B) = (80-10.815) / 80 = 0.865。相对暴露度的结果列入表2中。对于损失指标值,由于灾后1~3个小时人口伤亡数据仍是未知数,而地理单元名称的出现频率一定程度上能够反映灾害严重程度[39],因此,根据数据处理所得文摘,对地理单元进行词频统计,得到部分地理单元的出现频率次数,通过将其进行标准化,并计算各个乡镇出现频率占总频率的比例,得出能够一定程度上反映灾情严重级别的指标值,同时也反映了救助需求强度。数据结果如表2中的“救助需求强度”列所示,其他3个未知地理单元将带入地理空间信息扩散模型进行计算。
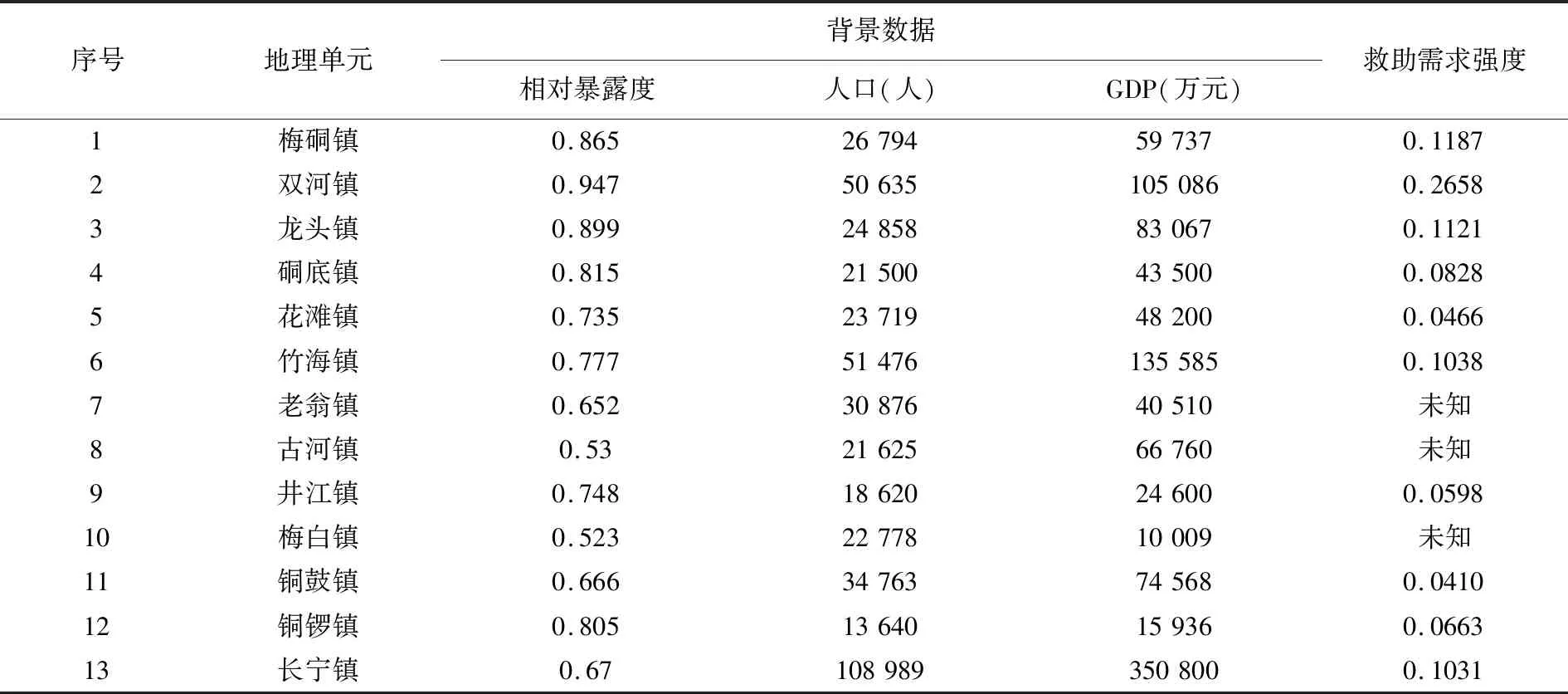
表2 四川省宜宾市长宁县6.0级地震灾情背景数据和救助需求强度Table 2 Background data and rescue need data to Changning Ms 6.0 earthquake
4.3 信息孤岛救助需求强度的推测
由表2,我们得到容量为10的损失学习样本:
W={w1,w2,…,w10}
={(0.865,26794,59737,0.1187),(0.947,50635,105086,0.2658),…,(0.67,108989,350800,0.1031)}
我们用空间信息扩散模型来学习此W, 构造出以相对暴露度、人口和GDP为因,以救助需求为果的模糊关系矩阵,推测老翁镇、古河镇和梅白镇的救助需求。
根据W中的各分量的最大、最小值,向左右各延长0.67倍,即,(最大值-最小)/1.5,在其上取20个等长的监控点,构成监控空间来进行信息扩散:
U1={u1,1,u1,2,…,u1,20}={0.479,0.513, …,1.134}, 步长3.4508776E-02
U2={u2,1,u2,2,…,u2,20}={-49926,-38216.473,…,172555}, 步长11709.53
U3={u3,1,u3,2,…,u3,20}={-207306.672,-166183.016,…,574042.750}, 步长41123.65
U4={u4,1,u4,2,…,u4,20}={-0.109,-0.081,…,0.416}, 步长2.7607016E-02
这些监控空间中的一些点,并不在其参数的定义域内。例如,相对暴露的定义域是[0,1],但U1中的最大值是1.134。这类监控点称为辅助监控点,以确保两边样本点和其它点有相同的信息价值。增加延长幅度和监控点密度,除了增加计算量之外,并不会提升模型的精度。
由式(8)计算出的相对暴露度、人口、GDP和救助需求的信息扩散系数是:
h1=0.0839,h2=28471,h3= 99990,h4= 0.0671.
对表3给出的,容量为10的救助需求学习样本W,用式(7)进行4维正态扩散,我们得到一个20×20×20×20的信息矩阵Q={Qk1k2k3k4}20×20×20×20。4维矩阵的书写非常复杂,通常用降维方式来表达。对监控点u1,10=0.789,u2,11=67169.266而言,对应信息矩阵的k1=10,k2=11, 于是4维矩阵降维为一个二维的20×20的信息矩阵{Q11k3k4}20×20。由救助需求学习样本W得到的此20×20信息矩阵的中间部分是:
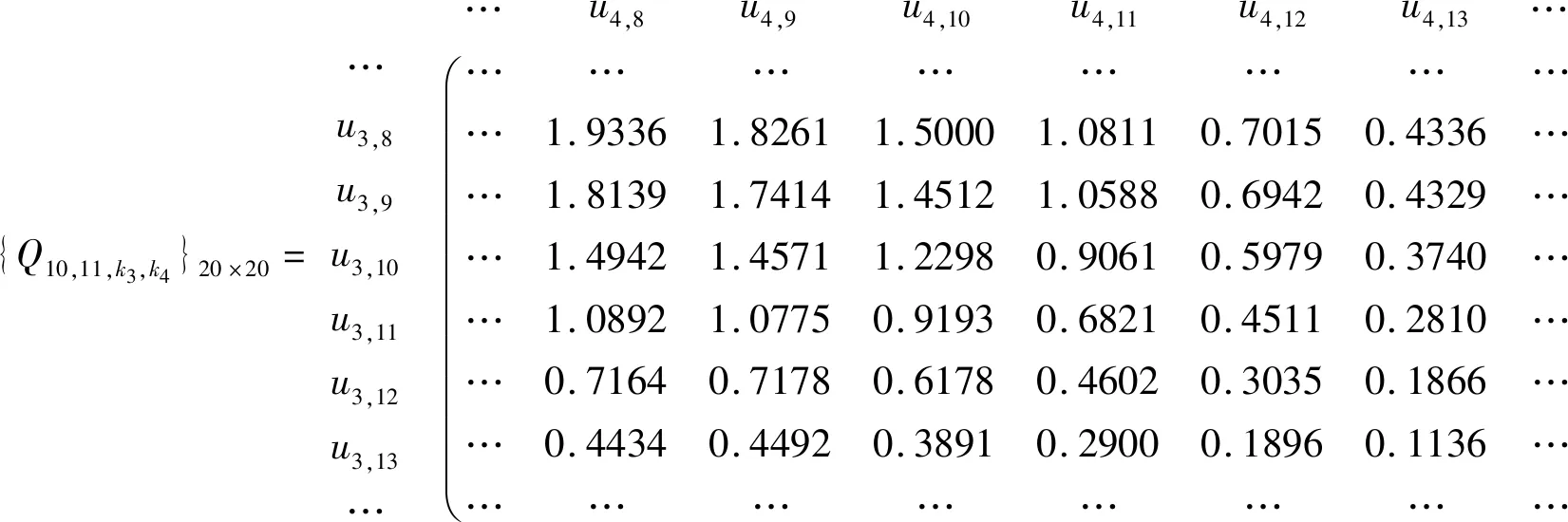
{Q10,11,k3,k4}20×20=…u3,8u3,9u3,10u3,11u3,12u3,13……u4,8u4,9u4,10u4,11u4,12u4,13…………………………1.93361.82611.50001.08110.70150.4336……1.81391.74141.45121.05880.69420.4329……1.49421.45711.22980.90610.59790.3740……1.08921.07750.91930.68210.45110.2810……0.71640.71780.61780.46020.30350.1866……0.44340.44920.38910.29000.18960.1136………………………æèçççççççççç
用式(11)、(12)将其转化为模糊关系矩阵,{r11k3k4}20×20的中间部分是:
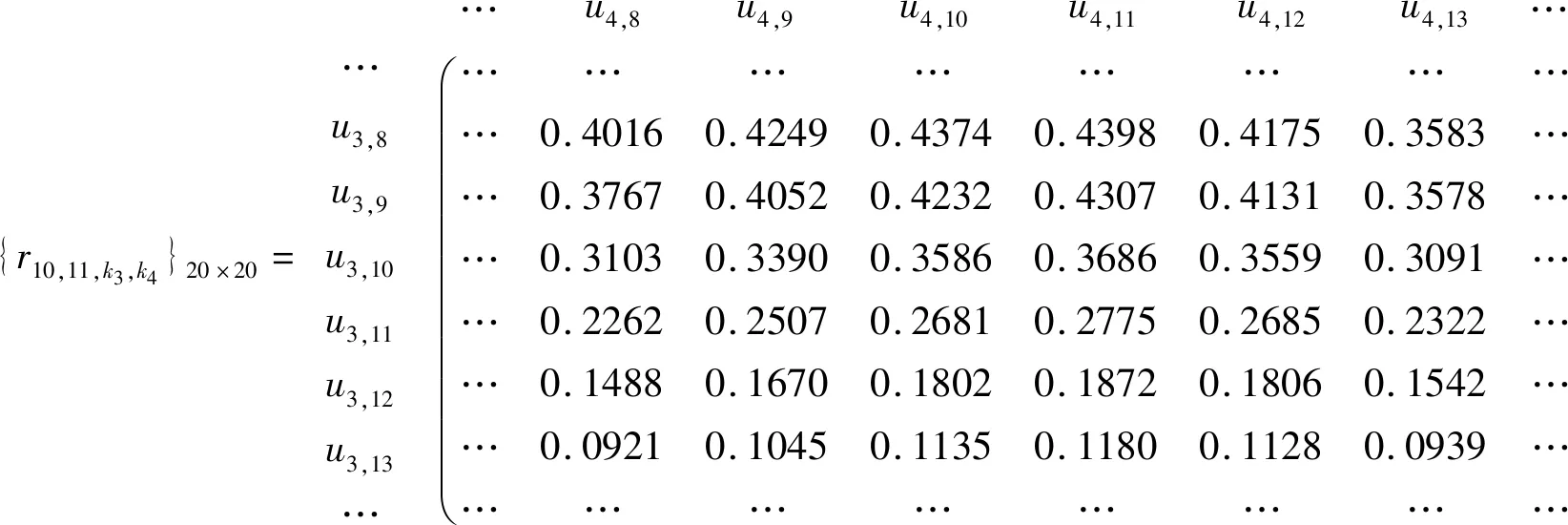
{r10,11,k3,k4}20×20=…u3,8u3,9u3,10u3,11u3,12u3,13……u4,8u4,9u4,10u4,11u4,12u4,13…………………………0.40160.42490.43740.43980.41750.3583……0.37670.40520.42320.43070.41310.3578……0.31030.33900.35860.36860.35590.3091……0.22620.25070.26810.27750.26850.2322……0.14880.16700.18020.18720.18060.1542……0.09210.10450.11350.11800.11280.0939………………………æèçççççççççç
对空白单元老翁镇、古河镇和梅白镇的背景数据:
z老翁镇=(0.652,30876,40510),z古河镇=(0.53,21625,66760),z老翁镇=(0.523,22778,10009)
在式(14)、(15)中令λ-1=3,进行3维线性信息分配,分别得模糊输入老翁镇,古河镇,梅白镇。例如,老翁镇中的元素a6,7,7=0.1105,a6,7,8=0.002964,a6,8,7=1。由式(16)得相应的模糊输出。例如,
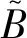
再由式(17),我们们推测出老翁镇、古河镇和梅白镇的救助需求强度分别是:
y老翁镇=0.01925,y古河镇=0.004999,y梅白镇=0.005328
。
4.4 救助需求强度展示图
根据计算结果将长宁县各乡镇救助需求进行分级,并导入救灾智联网平台制作灾情图,如图4所示,可以直观的看出此次地震各乡镇的救助需求紧迫程度。其中,红色表示紧迫度高,橙色较高,蓝色表示较轻。
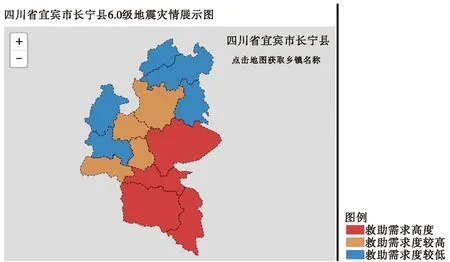
图4 救灾智联网系统中长宁县6.0级地震救助需求紧迫程度展示图Fig.4 Map of rescue need intensity of Changning Ms 6.0 earthquake(make in Internet of Intelligences)
5 结论与讨论
以“隔空判灾”的方式快速评估重大自然灾害中的救助需求,所得结论精度过低,难以支撑精准救助。在互联网普及的今天,以“采点外推”的方式获得部分地理单元上的数据,采用空间信息扩散模型推测空白地理单元中的灾情情况,精度大大提高。
应急响应精准救助要求时效性强,因而“采点外推”必须依托互联网,才能及时采集和处理数据,在规定的时间之内,推测信息孤岛中救助需求。任何离线系统,都无法实现这项任务。本文将空间信息扩散模型嵌入智联网,形成救灾智联网中的救助需求模块,能较好地完成这一任务。
大灾后的第一时间是尽最大努力减少人员伤亡,无法统计并核实各种应急物资的具体需求量。用空间信息扩散模型推测出与应急救助需求相关的某种表征量后,即可根据表征量与需求量回归关系,评估出具体应急物资的需求量。
以网络爬虫数据中受灾乡镇名字出现频率的强弱表征应急救助需求强度,对2019年长宁6.0级地震中信息孤岛镇的救助需求强度的推测说明,用嵌入空间信息扩散模型的救灾智联网,在“相对暴露度”、“人口”和“GDP”等背景数据库和网络爬虫工具的支持下,推测信息孤岛救助需求强度是可行的。
大量的计算仿真实验结果已经证明:空间信息扩散模型具有普适性。对于填补存在较大面积空白地理单元的区域而言,通过平均预测误差和平均基准误差比较的方法已经证明:地理空间信息扩散模型比地理加权回归和反向传播神经网络更有效[33]。主要原因有三,一是该模型具有识别非线性关系的能力;二是该模型不同于许多空间插值模型,受空间参数连续性假设的约束;三是在采点得到的样本中,允许存在矛盾样本点,不同于人工神经网络,出现学习不收敛的问题。
虽然根据大量的历史救灾实践和数据,很容易统计出救助需求强度与各种应急物资需求量的关系,但本文限于支撑项目无法提供历史数据的情况,并没有提供这方面的研究成果。有兴趣并有条件开展这方面工作的读者,不妨一试。
猜你喜欢
江苏安全生产(2022年8期)2022-11-01
北京航空航天大学学报(2022年8期)2022-08-31
水上消防(2021年4期)2021-11-05
江苏安全生产(2021年6期)2021-08-05
江苏安全生产(2020年5期)2020-06-15
河南水利年鉴(2020年0期)2020-06-09
河南水利年鉴(2017年0期)2017-05-19
地理空间信息(2017年2期)2017-03-06
四川党的建设(2014年10期)2014-08-23
测绘科学与工程(2014年3期)2014-02-27
