
面向不平衡数据集的应用系统识别方法
2021-05-27 06:51:36董燕辉肖军弼张红霞杨勇进计志滨
计算机与现代化 2021年5期
董燕辉,肖军弼,张红霞,杨勇进,计志滨
(1.中国石油大学(华东)计算机科学与技术学院,山东 青岛 266580;2.胜利油田物探研究院信息技术研究室,山东 东营 257022)
0 引 言
随着互联网技术的飞速发展,基于局域网的应用系统层出不穷,在涉及国家资产和安全的重要领域,及时发现并监管这些应用系统对提升企业网络安全至关重要[1-3]。目前油田局域网内应用系统众多,存在登记不完全、IP变动频繁等问题,很难及时发现并对所有应用系统进行监测,为信息化部门的监管监控带来了极大的不便。为此,应用系统的自动化识别对于油田内应用的安全运行起到了重要的作用。基于网页的应用系统被湮没在海量的Web网页资源中,从中自动化识别少量的应用系统[4-6]是一个典型的类别不平衡问题[7-8],不平衡数据会导致分类器偏向多数类,从而影响分类效果。因此,如何在不平衡数据情况下解决应用系统的自动化识别具有重要意义。
近年来,针对数据不平衡问题的研究逐渐成为热点,王超学等人[9]将支持度和轮盘赌选择引入SMOTE提出了SSMOTE方法,结合K最近邻(K-Nearest Neighbor, KNN)分类方法证明了其有效性。覃朗等人[10]提出了基于信息增益理论的关键指标扩展方法进行过采样,并结合支持向量机(Support Vector Machine, SVM)分类算法对指标寻优来确定最终分类结果。王忠震等人[11]提出基于改进SMOTE和AdaBoost算法相结合的不平衡数据分类算法(KSMOTE-AdaBoost),平衡了类内与类间数据。虽然以上方法在一定程度上提高了SMOTE的采样效果,但还存在以下不足:1)改进的采样倍率依赖于样本个体的分布特点,对于噪声数据不能很好地处理;2)个体采样倍率必须经过大量计算寻优,需要消耗大量时间和计算成本。
基于以上不足,本文提出一种面向不平衡数据集的应用系统识别框架(Web Classification, WEBCLA),该框架综合考虑了数据不平衡和网页内数据异构性[12]的问题。为了缓解过采样过程中引入噪声的问题[13],通过将特征的全局基尼增益引入距离计算公式对SMOTE方法进行改进,提出基于基尼增益的改进SMOTE方法(Gain SMOTE, GSMOTE),将特征加权后的过采样技术和数据清洗技术最近邻规则(Edited Nearest Neighbours, ENN)[14]相结合,对样本数据预处理,然后结合XGBoost算法解决基于网页的应用系统的识别问题,最后通过在真实数据集上的大量实验结果表明,WEBCLA框架对基于网页的应用系统识别问题的处理较其他分类方法在召回率指标上表现更优。
1 WEBCLA框架构建
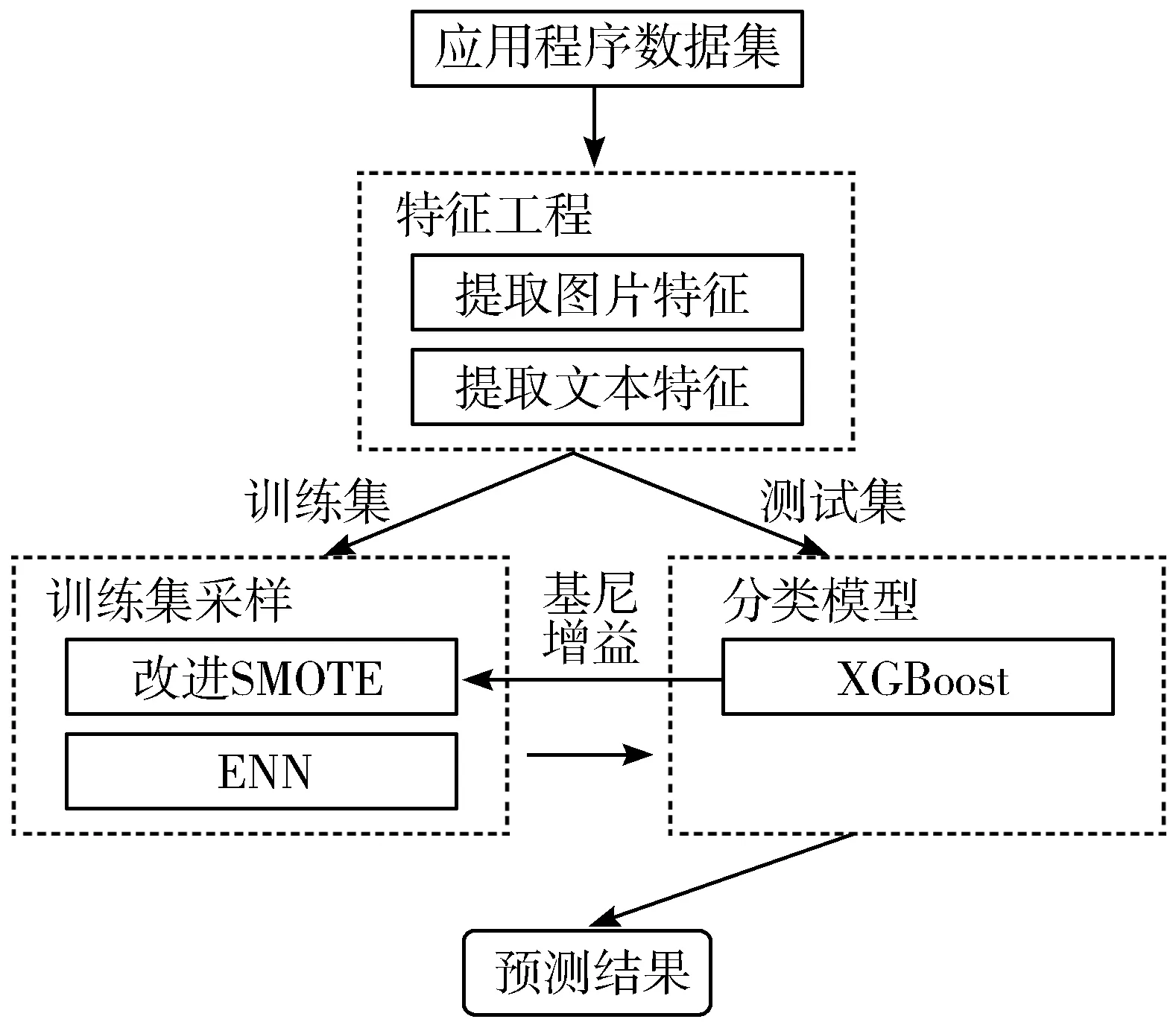
图1 WEBCLA框架流程图
WEBCLA框架流程如图1所示,首先通过爬虫技术获取网页内的HTML文本和图片,通过敏感词正则[15]分别提取HTML文本中的敏感特征和图片文字特征,然后利用XGBoost计算出每个特征的基尼增益值,通过将基尼增益引入距离计算公式改进SMOTE过采样并结合ENN欠采样技术对训练数据进行预处理,最后利用采样后的数据训练XGBoost分类模型,训练完成后输出链接属于应用程序的概率,进而发现众多网页中的应用程序。具体算法原理如第1.1节、第1.2节所述。
1.1 基于基尼增益的特征选择算法
根据网页特征值和标签建立训练样本数据集,表示如下:
(1)
其中,X表示所有训练数据的特征值,Y表示所有训练样本对应的标签,即网页是否属于应用程序,yi=1表示样本是应用程序网页,反之,yi=0表示该样本是普通网页。
XGBoost[16]是一种以树模型为基学习器的集成方法,通过引入正则化项来控制树的复杂度,从而缓解模型的过拟合问题[17],模型能自动利用CPU进行多线程并行计算,提高运算速度,并且对损失函数进行泰勒二阶展开使得预测精度更高,在损失函数后面增加正则项,可以约束损失函数的下降和模型整体的复杂度。以X和Y作为XGboost模型的输入和输出,建立由k棵决策树组成的加法模型:
(2)
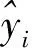
加入正则化后,模型的目标函数为:
(3)
其中,T为决策树叶子的个数,w为叶子的权重,γ和λ分别为叶子和权重的惩罚项。对目标函数二阶泰勒展开,泰勒展开将ft(xi)看作Δx,则目标函数为:
(4)
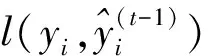
(5)
对式(4)中的wj求偏导并令其等于0,可以得到每个叶子节点的权重值为:
(6)

(7)
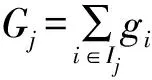
对于训练好的每棵树,计算每个特征维度f的平均增益:
(8)
其中,K为特征f在所有树中的分裂次数,Gaini为第i次分裂得到的基尼增益,计算公式如下:
(9)
其中,GL、GR分别为该分裂点左、右子节点的一阶导数,HL、HR分别为该分裂点左、右子节点的二阶导数。
1.2 GSMOTE算法
由于基于网页的应用系统在总样本中属于少数类,造成了特征数据样本的不平衡,若直接应用模型处理数据,可能会发生过拟合现象,从而使分类性能下降。因此,本文提出一种网页自动识别方法,该方法首先采用GSMOTE方法对样本数据进行过采样处理,在此基础上,采用ENN对结果进行去重叠,达到增强类间差异性的效果。虽然通过GSMOTE方法可以使样本集中的类别平衡,但是SMOTE的线性插值过程容易产生与多数类样本重叠的点,容易导致后续的分类算法分类效果变差[18]。为了缓解此问题,使用ENN对生成的数据进行去重叠,主要思想是对于属于多数类的一个样本,如果其K个近邻点有超过一半都不属于多数类,则这个样本会被剔除。
对于特征数据集中已标记为应用程序的网页通过GSMOTE方法产生与少数类样本相似特征的扩充样本,以改善分类性能。D表示样本数据集中已经存在的少数类样本,记作D={(xi,y)|y=1},其中xi表示某个样本的特征值。
GSMOTE方法原理如图2所示。使用改进GSMOTE对少数类过采样的具体步骤如下:
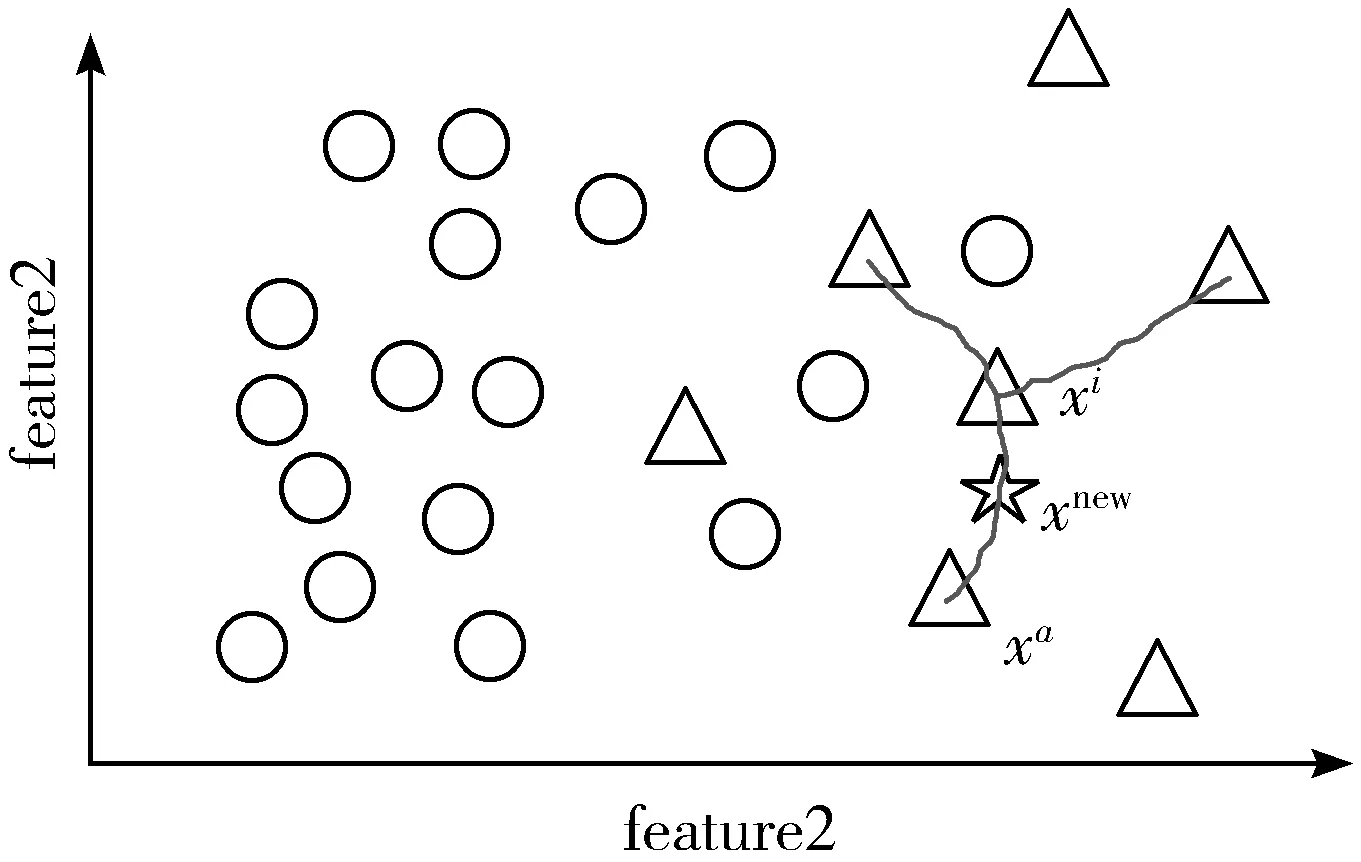
图2 二维特征下GSMOTE方法原理
1)取少数类样本中任意一个样本特征xi,计算xi到少数类中其他样本特征xj的距离,xi到xj的距离计算公式为:
(10)
其中,F为特征向量xi的维度。
2)以xi为中心,选出k个欧氏距离最近的样本,得到xi的k个近邻。
3)从k个近邻中随机选择一个样本xa,计算xi至xa之间的线性插值,得到和xi近似的样本xnew,计算公式为:
xnew=xi+(xa-xi)δ
其中,δ为0~1之间的随机数。
4)根据多数类和少数类样本不平衡比例设置采样比例值,以确定采样倍率。针对每个少数类样本,重复上述的线性插值过程,最终使少数类样本数目与多数类样本数目相匹配,实现样本集的平衡。
5)利用ENN技术,取少数类样本中的一个样本,计算该样本的k个近邻点,若对于该样本的近邻点中有超过一半不属于多数类,则剔除该样本。对样本中所有少数类样本重复此过程,直至对所有少数类样本完成清洗。
2 实 验
为了验证本文提出的GSMOTE方法和WEBCLA框架的有效性,设计了多组对比实验,对各类参数进行有效性验证。
2.1 数据集介绍
实验数据采集于某油田局域网,通过爬虫采集2万余条的网页链接及其含有的文本和图片。数据的详细信息如表1所示,其中文本信息通过正则匹配提取敏感词信息(例如管理、系统等),图片通过谷歌开源图片识别工具pytesseract[19]实现文字提取,然后通过正则做敏感词分析。通过分析可以发现,数据集存在严重的数据不平衡问题,在20686条有效链接中仅有161条链接是应用程序,仅占所有链接数的0.77%。

表1 数据集详细信息
2.2 实验结果
2.2.1 WEBCLA框架有效性分析
为了说明WEBCLA框架中GSMOTE采样对于解决应用系统识别问题的有效性,设计了不同采样方法的对比实验,选择未经过采样预处理的数据训练的模型作为基本模型,计算加入ENN欠采样、SMOTE过采样和改进SMOTE对召回率recall指标[20]的提升率,实验数据采用十折交叉实验取平均值来减小误差影响,结果如图3所示。从图3可以发现,通过对多数类样本进行欠采样对于应用系统识别问题的recall指标提升较低,对少数类样本进行过采样可以大幅提高recall指标,将过采样和欠采样结合比单独采用欠采样或过采样对recall指标提升效果要好,提升了大约9.8%,采用改进SMOTE方法结合ENN对recall指标提升率最高,达到10.8%。对原始实验数据集进行主成分分析[21]得到特征二维可视化如图4所示。从图4可以发现,属于应用程序的网页和其他网页样本分布差距较大,对其他网页样本数据的欠采样虽然减少了多数类的样本数量,但不能增强应用程序网页样本数据的分布,而对应用程序网页样本的过采样可以增强少数类的分布表示,所以改进的SMOTE过采样比欠采样对于提升问题的recall指标更有效。

图3 WEBCLA框架不同方法recall指标增长率实验结果
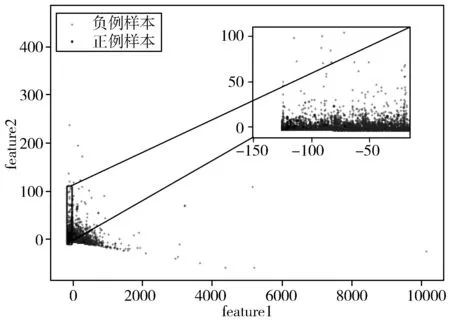
图4 原始样本分布图
2.2.2 分类算法对于WEBCLA的影响分析
在实际场景中,将应用系统识别为普通网页造成的损失比将普通网页识别为应用系统网页导致的损失大得多,对少数类的分类错误可能会导致严重问题[22],因此recall指标的优劣对应用系统识别非常重要。为了分析XGBoost分类器对WEBCLA框架的影响,将XGBoost算法与GBDT、SVM[23]分类算法在recall、accuracy、F1等指标的效果进行对比,如图5所示。结果表明,采用XGBoost算法的recall值最高,比GDBT高出约112.8%,比SVM高出约42.2%,说明WEBCLA方法能够有效地发现应用系统。此外,XGBoost的其他指标表现良好,表明在WEBCLA框架中采用XGBoost算法可以大幅提高应用系统识别问题的召回率,在油田应用系统识别问题中的意义就是可以发现更多的隐藏应用程序,有效提高管理人员筛选应用程序的效率。

图5 WEBCLA选择不同分类算法对比实验结果
2.2.3 XGBoost参数对分类结果的影响
由于XGBoost分类算法内置了对于不平衡类的惩罚函数,此类惩罚也是处理数据不平衡分类的一种有效方式[24],为了分析算法对于少数类的惩罚参数对于WEBCLA框架分类效果的影响,分别对算法中指定正反样本权重的scale_pos_weight参数取不同值的分类效果进行实验,实验中取scale_pos_weight=[1,2,5,10,50,100,200],实验结果如图6所示。从图6可以看出,召回率recall值随着参数取值的变大有明显提升,在参数scale_pos_weight=50时,recall值趋向平稳,说明对于不平衡数据集,样本的正反例权重对于recall指标具有较大影响,对于其他分类指标没有明显提升,说明适当加大正反样本权重在一定程度上可以缓解不平衡样本对于分类器的影响。
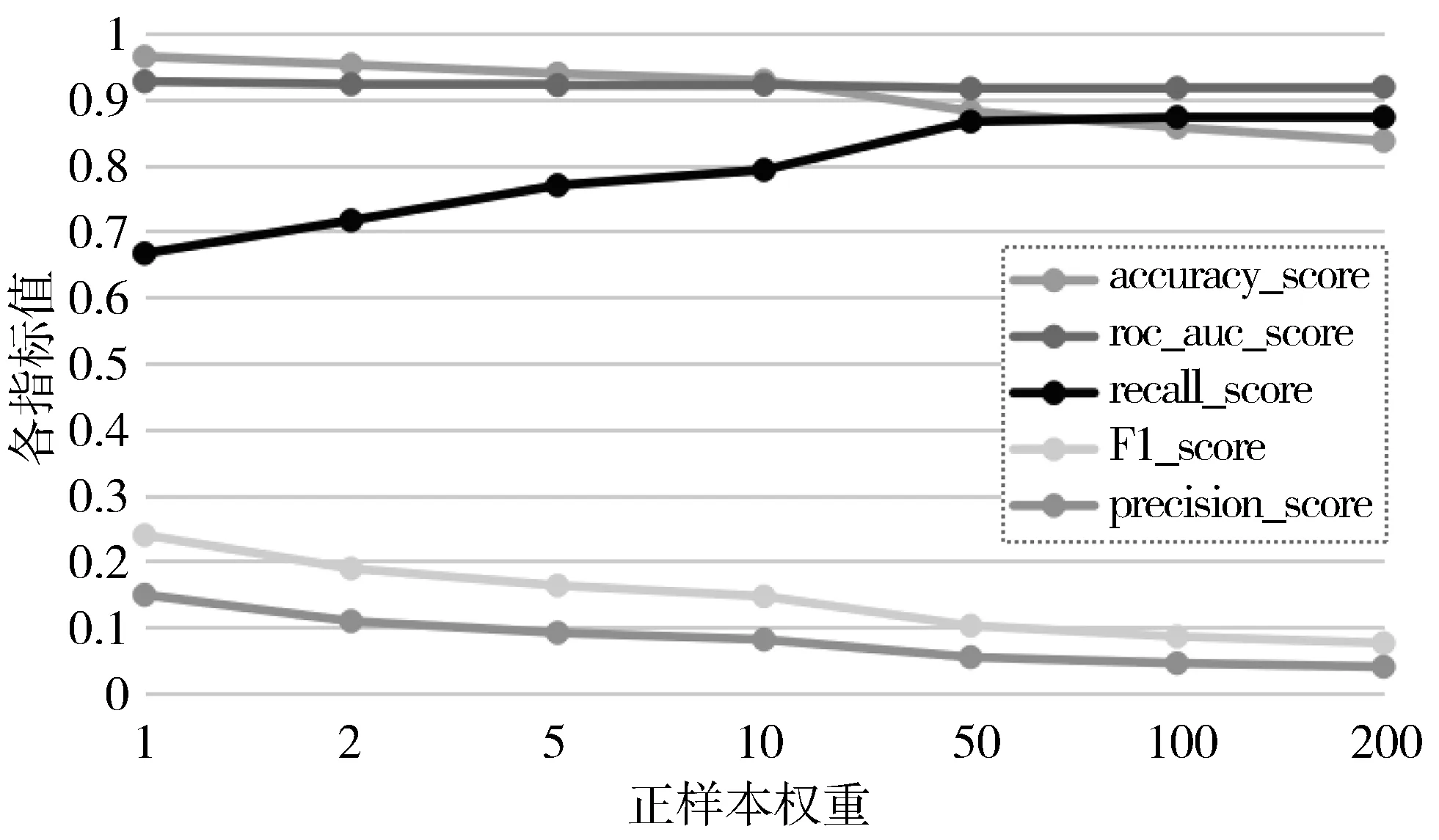
图6 XGBoost参数对分类性能的影响
2.2.4 网页特征分析
对于网页分类问题而言,采集的特征是否有效对于提高应用系统识别的准确性至关重要。针对网页中HTML文本和图像内容设计基于敏感词的特征值,利用XGBoost作为模型,对每个特征值的权重即在所有树中一个特征被用来分裂数据的次数,进行可视化分析,如图7所示。从图7可以发现,HTML文本中的超链接标签个数对于应用系统识别分类的权重最大。这是由于大部分应用程序页面内不会存在过多的列表展示内容,取而代之的是各种交互表单。另外,由于应用程序网页比较重要且不会经常随日期变动,所以网页链接的目录级数以及其中的数字个数对于应用分类也很重要;特征重要性中排第4的为图片中“管理”出现的个数,表明网页中图片文字存在“管理”短语时有很大概率为应用程序。
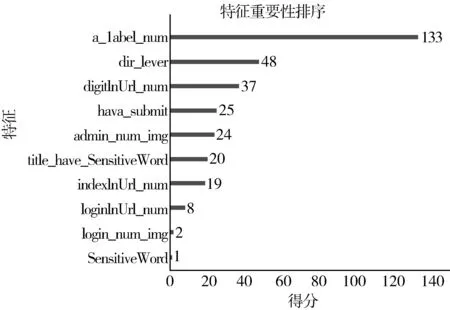
图7 特征值权重可视化
3 结束语
数据不平衡是分类场景中的常见问题,针对油田局域网中基于网页的应用系统自动化识别这一典型的不平衡数据集的分类问题,本文提出了一种基于基尼增益的改进SMOTE过采样方法GSMOTE,并结合XGBoost分类器建立了网页应用系统识别WEBCLA框架模型。通过GSMOTE方法对训练数据进行混合采样以缓解类别不平衡问题,结合XGBoost分类算法提出了网页应用的自动化识别方法,并在真实环境中进行了测试,结果表明,WEBCLA的recall值相对传统方法可以达到更优。同时对应用程序数据集的特征进行了重要性分析,解释了权重较高的特征在实际场景中的意义,验证了WEBCLA框架处理应用系统识别问题的有效性,说明此模型可用于应用系统的自动化发现识别领域,可以极大地减少人工筛查量,节省人力成本并提高工作效率。
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11 00:49:59
数学物理学报(2020年3期)2020-07-27 01:19:46
电脑报(2019年12期)2019-09-10 05:08:20
电子制作(2018年10期)2018-08-04 03:24:38
电子制作(2017年2期)2017-05-17 03:54:56
法大研究生(2017年1期)2017-04-10 08:55:06
电子测试(2015年18期)2016-01-14 01:22:58
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:21
计算机与网络(2014年7期)2014-03-25 10:57:07
电脑迷(2012年15期)2012-04-29 17:09:47
