
基于风格迁移的手势分割方法
2021-05-27 06:51:32陈明瑶李晓旋
计算机与现代化 2021年5期
陈明瑶,徐 琨,李晓旋
(长安大学信息工程学院,陕西 西安 710064)
0 引 言
手势是人际交往中不可或缺的一种方式,随着计算机软硬件的飞速发展,越来越多的学者关注基于手势的人机交互方法。早期的手势交互主要通过增加数据手套等外部设备来提高手势识别准确度,但较高的硬件成本妨碍了其推广。计算机视觉领域近年来的研究成果,使基于视觉的手势交互成为一种新的解决方案。
手势分割是视觉手势交互的关键步骤。2019年Amirhossein等人[1]提出了一个专门解决手势分割和识别问题的HGR-Net模型。HGR-Net模型由第一阶段的手势分割网络和第二阶段的手势识别网络组成。其中手势分割网络借鉴全卷积网络(Fully Convolutional N etworks, FCN)的思路[2],引入残差网络[3](Residual Networks, ResNet)结构,结合空洞空间金字塔池化[4](Atrous Spatial Pyramid Pooling, ASPP),完成了手势分割任务,手势分割结果较FCN模型更加准确。但是该模型对于光照和手部颜色不均匀的图像,手势分割区域内部会出现空洞;对于某些背景包含脸部等类肤色的图像,则会将类肤色区域误检为手势区域。而且该方法过分依赖于精准标注的训练样本,对于与训练样本差异较大的手势图像,手势分割结果难以令人满意。
针对上述类内不一致和模型泛化能力弱的不足,本文提出以下改进方法:
1)在基于HGR-Net的手势分割网络[1]的主干网中增加上下文信息增强模块,对主干网相邻两层特征进行全局均值池化操作,使用通道注意机制,增加显著性特征通道的权值,保证上下文信息的连续性,解决分割结果存在的类内不一致的问题。
2)将图像风格化迁移[5]应用于领域自适应[6]问题中,提出一种基于风格迁移的领域自适应方法,在图像预处理阶段进行图像风格迁移,对源域测试样本进行数据重构,使其同时具有自身内容和目标域训练样本的风格特征,从而提高本文手势分割网络的泛化能力。
1 相关工作
手势分割最初主要依据肤色特征进行。文献[7]使用椭圆肤色模型进行手势分割,为了减少光照的影响,首先对图像进行颜色均衡处理,然后对亮度分量进行阈值分段判断,在高亮度区域扩大椭圆模型的长短轴。该方法比传统椭圆模型可以分割出更加准确的手势区域[7]。文献[8]在YCbCr空间建立肤色分布的高斯模型,增加亮度阈值化和RGB三分量阈值化操作,并结合手势掌心的几何特征,以降低模型的误检率,最终将手势与背景准确分离。基于肤色特征的分割方法在光照不均或有类肤色区域干扰时,分割准确度难以令人满意。在基于肤色分布特性的基础上常常融合运动信息[9]、轮廓信息[10]、深度信息[11]等其他信息,以提高算法的鲁棒性。
随着深度学习的不断发展,涌现出了很多语义分割的模型,在手势分割这一具体问题中,取得了较传统方法更加准确的结果。为了实现在无限制场景中准确检测手部区域,文献[12]提出了一个两阶段的基于深度学习的手部区域检测方法。在第一阶段采用Faster-RCNN(Faster Region-based Convolutional Neural Networks)检测手部区域,第二阶段使用肤色检测算法去除误检区域[12]。文献[13]提出了一个Network-in-Network网络模型,用于检测肤色区域。该模型由4个卷积层和8个改进的感知模块,最终输出肤色概率图。文献[14]提出了一个轻量级的肤色检测网络,该网络能够捕获多尺度的上下文信息,并对分割结果中的肤色边界进行重新定义,从而保证了分割精度。
基于卷积神经网络的语义分割算法常常需要通过对大量标记的样本进行学习,实现像素级的语义分割。一方面,对数据进行人工标注将会耗费大量的时间和精力;另一方面,分割结果过分依赖于标记样本,对于与训练集有较大差异的样本,结果难以令人满意[15]。领域自适应是迁移学习的一种代表性方法,其目的是用于解决源域和目标域之间的数据集跨域问题和标注数据获取困难的问题。目前,领域自适应方法主要包括以下3种方法[6]:1)基于数据重构自适应的方法,在保证源域内部差异性的同时,减小域间差异,对源域数据进行重构[16-17];2)基于差异自适应的方法,利用目标域标签数据和源域数据对模型进行微调,减小2个域之间的偏差,类准则、统计准则是常用的微调方法[18-19];3)基于对抗学习自适应的方法,通过与判别器对抗,将源域和目标域数据在数据或特征空间对齐,学习具有域不变性的特征[20-21]。
图像风格迁移是将一幅风格图像的风格应用于另一幅内容图像的过程,主要应用于卡通动漫制作、电影动画制作等图像艺术风格绘制领域[5]。传统的风格迁移通常将目标域图像视为一种纹理,使用图像局部特征的统计模型描述纹理,利用图像重建方法将纹理和内容图像结合,实现图像的风格迁移[22]。基于纹理统计模型的风格迁移方法难以描述高层抽象纹理特征,在处理颜色和纹理较复杂的图像时,风格迁移效果难以符合实际需求。卷积神经网络可以提取高层抽象纹理特征和语义特征,并可独立处理这些高层特征,实现图像的风格迁移,近年来被广泛应用于风格迁移中。基于图像迭代[23-24]和基于模型迭代[25-26]是常见的2种基于深度学习的图像风格迁移方法。
基于模型迭代的方法调参过程繁琐,且需要大量数据训练。而基于图像迭代的方法合成图像的质量高,易于调参,无须训练,适用于解决本文中手势分割的领域自适应问题。因此,本文将风格迁移应用于领域自适应中,采用VGG网络,分别提取源域图像、源域白噪声图像和目标域图像各层特征,采用图像迭代的方式,不断优化风格化总损失函数,最终重构源域非训练集图像,提高了本文手势分割模型的泛化能力,实现了跨域手势图像的分割。
2 基于风格迁移的手势分割网络模型
本文的基于风格迁移的手势分割网络模型包括风格迁移数据重构模块和手势分割模块,手势分割模块由主干网络和上下文信息增强模块2个部分组成,本文的网络结构如图1(a)所示。风格迁移数据重构模块使用基于卷积神经网络的风格迁移方法,重构源域测试图像,解决无标记样本的跨域分割问题;主干网络采用五层网络结构,提取手势图像的多尺度特征;上下文信息增强模块增加特征中的上下文信息,解决分割结果类内不一致问题。
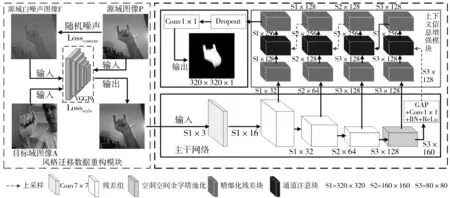
(a) 网络整体结构
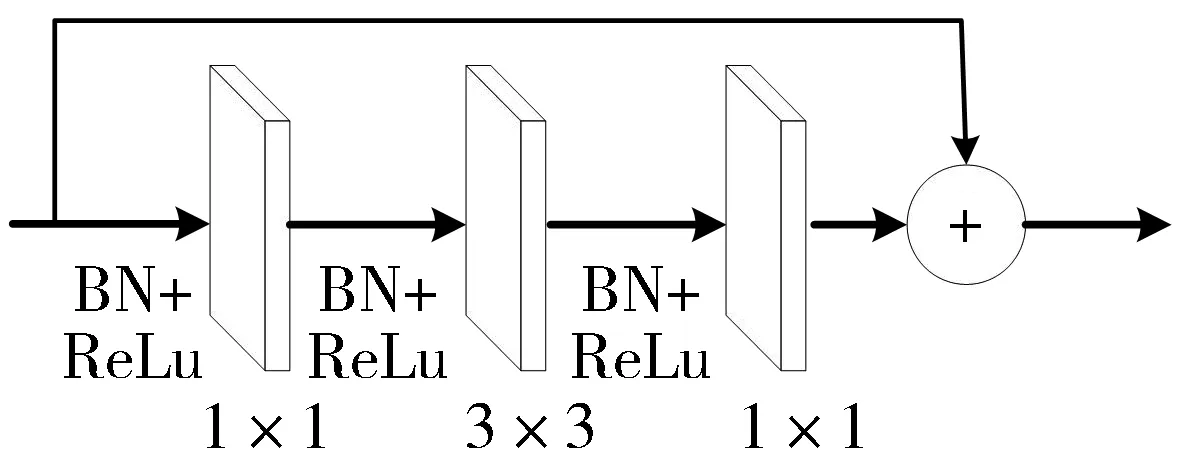
(b) 残差块

(c) 空洞空间金字塔池化组
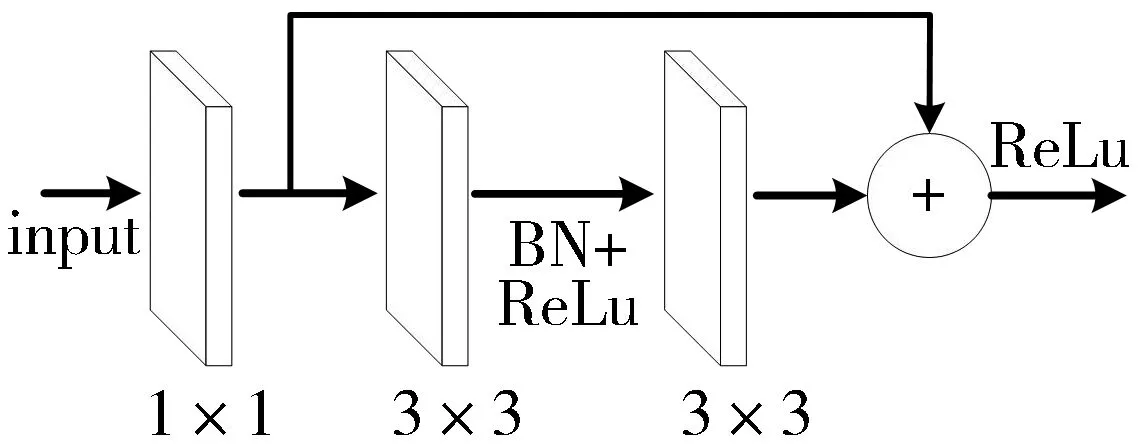
(d) 精细化残差块

(e) 通道注意块
2.1 手势分割模块
手势分割模块包括主干网和上下文信息增强模块这2个部分。主干网是一个基于HGR-Net手势分割网络构建的多尺度卷积残差网络(Multiscale Fully Convolutional Residual Network, MFCRN),包括一个7×7的卷积层、3个残差组和一个空洞空间金字塔池化组。每个残差组包含3个残差块,用于特征学习,并解决网络加深出现的梯度消失问题;空洞空间金字塔池化组用于提取不同尺度的图像特征;残差块和空洞空间金字塔池化组结构如图1(b)、图1(c)所示。上下文信息增强模块(Context Information Model, CIM)用于增加特征中的上下文信息,具体描述如下:
手势分割结果中常常出现手势内部区域空洞或类肤色区域分割为手部等类内不一致问题。类内不一致问题主要是由于特征中丢失了过多的上下文信息,目前多用全局均值池化操作提取上下文信息。而上下文信息通常隐藏在各层特征图的空间信息和语义信息中。一般而言,较低层特征中含有更多的空间信息,语义信息相对较少。由于感受野增大,较高层特征中含有更多的语义信息,空间信息相对较少。因此本文采用全局均值池化操作提取主干网相邻两层的上下文信息向量,用该向量作为相邻2层特征融合的权重,提取显著特征,增强特征中的上下文信息。
本文在主干网的后4层均连接上下文信息增强层,每个上下文信息增强层包含2个精细化残差块和一个通道注意块。在基本残差块结构之前加入1×1卷积层构成精细化残差块,1×1卷积层用于统一提取特征的通道数,基本残差块结构补充输出特征的信息,精细化残差块的结构如图1(d)所示。通道注意块连接相邻两层特征,提取相邻2层的上下文信息,增加语义上下文信息和空间上下文信息的连续性。4个上下文信息增强层逐层嵌套连接构成上下文信息增强模块。
通道注意块首先使用全局均值池化(Global Average Pooling, GAP)操作,提取相邻2层特征中的上下文信息向量α1。
α1=GAP[Inputlow,Inputhigh]
(1)
然后对α1进行归一化操作,得到归一化向量α。
α=Activation(ω×α1+bias)
(2)
其中,Activation为激活函数,ω为权重,bias为偏置。
接着使用向量α对低层输入特征进行加权操作,并与高层特征进行融合,最终输出含有上下文信息的显著性特征。
Out=(α×Inputlow)+Inputhigh
(3)
通道注意块结构如图1(e)所示。
2.2 风格迁移数据重构模块
本文在数据预处理阶段增加风格迁移数据重构模块,使用基于卷积神经网络的风格迁移方法,通过图像迭代的方式,对源域测试样本图像进行数据重构,使其同时具有自身内容和目标域训练样本的风格特征,从而提高本文手势分割模型的泛化能力。本文的风格迁移数据重构模块结构如图1(a)所示。具体方法如下:
对测试集中的源域图像加入白噪声,分别将源域图像P和加噪源域图像F输入到预训练好的含有5个池化层和16个卷积层的五层VGG(Visual Geometry Group)[27]网络中,获得每一层的响应图Pl和Fl。由于网络较高层的特征响应图能够捕捉输入图像中目标及其布局等内容信息,而网络较低层的特征响应图中则保留更多输入图像的像素值。本文的手势分割任务需要保留自采样本中更多的手势及其布局等内容信息,因此,本文计算第4层源域图像特征响应图P4和加噪源域图像特征响应图F4的误差,将其作为内容损失Losscontent。
(4)
选取训练集中分割结果最好的一幅图像作为目标域图像A,将其也输入到该VGG网络中,获得目标域风格图像的特征响应图Al,计算Al与Fl的Gram矩阵Gl的均方误差El:
(5)
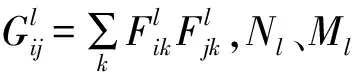
将每层误差值的加权和作为风格损失Lossstyle:
(6)
总损失函数Losstotal定义为内容损失和风格损失的加权和:
Losstotal=αLossstyle+Losscontent
(7)
其中,权重α表示源域图像的风格化程度。
最后通过Adam优化器,不断进行图像迭代,最小化总损失值,获得源域测试图像风格化迁移后的输出图。
3 相关实验
3.1 数据集及模型训练
本文将OUHANDS公开数据集[28]作为基础数据集,加入本文自采的样本数据构成扩展数据集。OUHANDS数据集共3000个样本,其中2000张图像为训练集、500张图像为验证集、500张图像为测试集。该数据集由23位实验人员参加制作,包括10种手势,这些手势图像分别在不同光照、不同背景下采集,同时具有手势尺度多样性。自采样本共390个,由8位志愿者在实验室、宿舍等室内自然手势交互场景中采集。将其中的280张加入OUHANDS训练集中构成扩展训练集,110张用来验证本文方法的性能。本文自采样本及其真值图如图2所示,其中真值图是使用标记工具LabelMe标记生成的。

(a)图例1 (b)图例2 (c)图例3 (d)图例4 图2 自采集图像样本中的4个图例
本文实验均是在CPU为Intel(R) Core(TM) i7-8700,内存为16 GB,显卡为NVIDIA GeForce GTX 1060 6 GB的硬件环境下,使用Python3.7和深度学习框架Keras完成。训练阶段中,batch_size设置为1,epoch设置为150,选用交叉熵损失函数(Cross-entropy cost function),并使用自适应矩估计(Adaptive moment estimation, Adam)算法作为优化算法,其参数分别为lr=0.001,β1=0.9,β2=0.999。风格迁移数据重构模块中,由于目标域图像不同层的特征响应图包含不同的风格特征,为均衡地保留目标域图像在网络各阶段的风格表达,公式(6)中的权重均设置为1。此外,110幅自采样本调参实验表明,公式(7)中风格化参数的取值与自采样本的背景复杂度和光照条件有关,且合理取值区间为[0.1,1]。
为简化标记,将本文手势分割模块标记为MFCRN+CIM(Multiscale Fully Convolutional Residual Network+Context Information Mode)。首先使用OUHANDS数据集依次训练FCN[2]、HGR-Net[1]和MFCRN+CIM,并使用该数据集的测试样本进行测试,来验证本文手势分割模块的性能。然后使用扩展数据集,再次训练MFCRN+CIM,并将其标记为MFCRN+CIM+ADD,使用自采样本进行测试。最后在MFCRN+CIM中加入风格迁移数据重构模块,使用自采样本进行测试,验证本文领域自适应方法的有效性。
3.2 实验结果
使用椭圆肤色模型[7]、FCN-8s[2]、HGR-Net[1]和MFCRN+CIM在OUHANDS数据集的手势分割结果如图3所示。可以看出,使用椭圆肤色模型受类肤色区域和光照的影响最严重,手势分割结果最差;使用FCN-8s模型得到的分割结果存在严重的类内不一致和边缘模糊的问题;使用HGR-Net模型得到的分割结果优于FCN-8s,但存在误检以及手势内部存在空洞等类内不一致问题;MFCRN+CIM的分割结果中手势内部区域完整度和手势边缘清晰度较HGR-Net模型更好,类内不一致问题也得到了解决。

(a) 原图

(b) 真值图

(d) FCN-8s模型分割结果

(e) HGR-Net模型分割结果

(f) MFCRN+CIM分割结果图3 OUHANDS数据集上部分测试结果
本文使用均交并比值(Mean Intersection over Union, mIoU)和平均像素准确率(Mean Pixel Accuracy, MPA)作为分割精确程度的评价标准[29],使用上述4种方法在500张OUHANDS测试样本上测试,mIoU和MPA值如表1所示。可以看出,本文的MFCRN+CIM的mIoU值、MPA值均为最高,较HGR-Net模型分别提高了3.2个百分点和1.8个百分点。

表1 4种方法的分割结果
实验结果表明,本文的手势分割模块可以解决手势内部空洞和脸部类肤色区域误检等类内不一致问题,手势分割结果的准确度高于HGR-Net、FCN-8s和肤色模型。
使用本文自采样本对MFCRN+CIM和MFCRN+CIM+ADD模型进行测试,实验结果如图4所示。由图4(c)、图4(d)对比可知,MFCRN+CIM的检测结果中,仅有一小部分自采图像可以较准确地分割出手势区域,对于某些背景复杂度高、光照不均匀的样本,几乎检测不到手势区域;MFCRN+CIM+ADD的分割结果有所改善,但依然不能得到完整的手势区域。

(a) 原图

(b) 真值图

(c) MFCRN+CIM模型分割结果
(d) MFCRN+CIM+ADD模型分割结果图4 自采集样本的部分测试结果
在本文手势分割模块之前加入风格迁移数据重构模块,对110张自采集图像进行测试,部分手势分割结果如图5所示。由图5(d)和图5(e)对比可以看出,风格迁移后的手势分割准确度比未迁移的准确度有较大程度的改善,迁移后的分割结果可以得到更为完整的手势区域。图6给出了110张自采集样本风格迁移前后的mIoU值和MPA值曲线,可以看出,110张自采样本迁移后的分割结果均有不同程度的提高。110张自采集样本迁移前后mIoU的平均值分别为0.6034和0.7931,迁移前后的MPA平均值分别为0.6589和0.8899,分别提高了19个百分点和23个百分点。

(a) 原图

(b) 风格迁移后的结果图

(c) 真值图

(d)MFCRN+CIM迁移前图像的分割结果

(e) MFCRN+CIM迁移后图像的分割结果图5 自采集图像风格迁移前后的部分测试结果

(a) mIoU值曲线
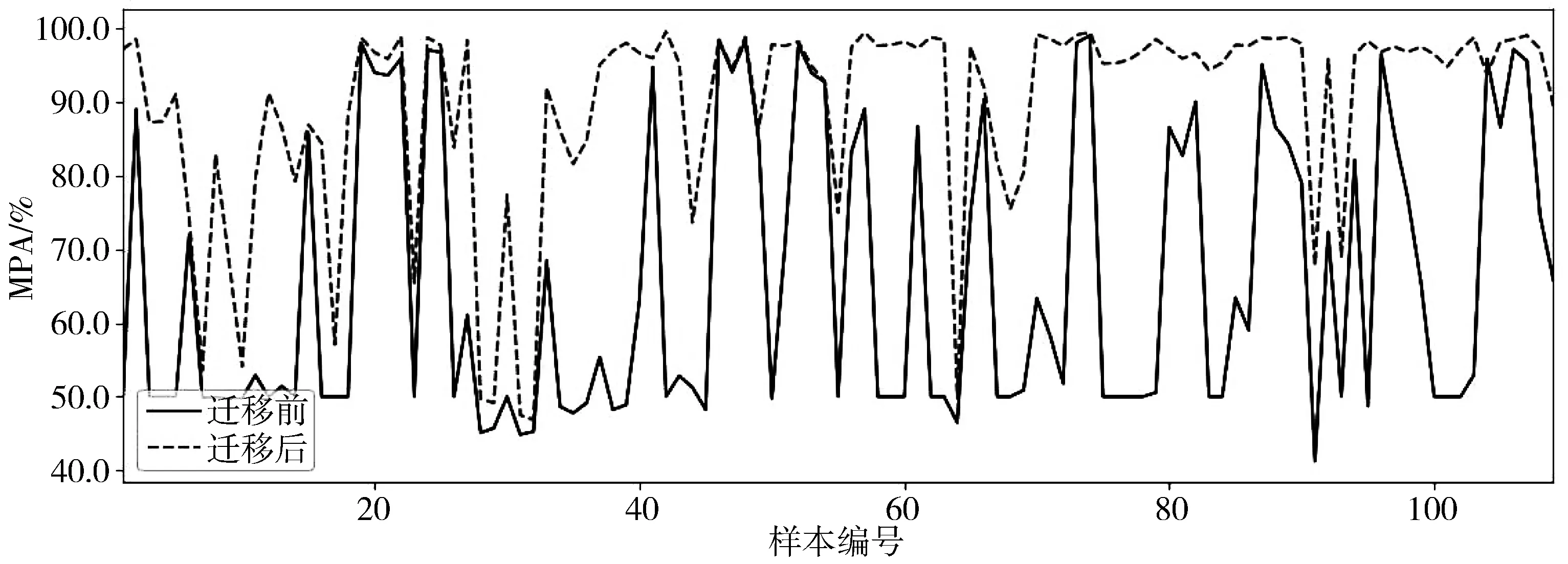
(b) MPA值曲线图6 风格迁移前后自采样本的mIoU和MPA值曲线
4 结束语
针对HGR-Net手势分割网络模型存在类内不一致和模型泛化能力较弱的问题,本文提出了一种基于风格迁移的手势分割方法。首先选择HGR-Net手势分割网络前5层作为本文的主干网,并引入上下文信息增强模块,使用全局均值池化操作,提取相邻2层的上下文信息向量,使用归一化向量加权并融合相邻两层特征,增加显著性特征通道的权重,增强特征中上下文信息的连续性。在OUHANDS数据集的测试结果表明,均交并比和平均像素准确率分别达到0.9143和0.9363,较HGR-Net手势分割模型分别提高了3.2个百分点和1.8个百分点。然后在数据预处理阶段加入风格迁移数据重构模块,使用VGG网络,通过图像迭代方式,将源域测试样本迁移到目标域训练样本图像中,使其具有自身内容和目标域图像的风格特征,实现了源域数据重构。在自采集测试集的实验结果表明,本文方法可将非训练集样本的分割结果均交并比和平均像素准确率分别提高19个百分点和23个百分点,可以大幅度提高模型的泛化能力。本文提出的风格迁移领域自适应方法为无标记样本的跨域分割提供了一个新的思路。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
计算机技术与发展(2020年11期)2020-12-04 07:50:46
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
红领巾·萌芽(2019年9期)2019-10-09 03:42:56
当代陕西(2019年10期)2019-06-03 10:12:04
小学科学(学生版)(2018年12期)2018-12-19 05:13:50
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
小学阅读指南·低年级版(2017年6期)2017-06-12 01:39:24
电子与信息学报(2015年12期)2015-08-17 11:14:42
河南科技(2014年23期)2014-02-27 14:19:15
