
一种在线医疗社区问答文本实体识别方法
——基于卷积神经网络和双向长短期记忆神经网络
2021-05-25 06:45廖开际邹珂欣席运江
科技管理研究 2021年8期
廖开际,邹珂欣,席运江
(华南理工大学工商管理学院,广东广州 510641)
1 研究背景
自2012 年谷歌提出了“知识图谱”的概念至今,知识图谱这一领域一直是科学研究和科技应用的前沿热点,其应用也涉及了从搜索到推荐等众多领域。目前,医学是知识图谱应用最广的垂直领域之一,也是国内外人工智能领域研究的热点,在如疾病风险评估、智能辅助诊疗、医疗质量控制及医疗知识问答等智慧医疗领域都有着很好的发展前景[1]。构建医疗领域的知识图谱可以分为3 个步骤:医疗实体识别、实体关系抽取、实体对齐与知识融合,其中医疗实体识别一直是构建知识图谱过程中的重难点。
在医疗领域,随着互联网的快速普及,网络技术的创新与发展已逐渐影响医患双方的行为方式,越来越多的病人在网上寻医问药,医生和医院也更加重视通过互联网进行医患之间的交流和沟通[2],例如寻医问药网等用户规模较大的在线医疗社区中,已积累了大量医患问答文本,若能通过这些问答文本进行医疗实体识别,便可以更准确且更加深层次地挖掘患者的需求,清晰地展现患者所关心的医疗问题,从而推动医疗行业进一步发展。然而,此类在线医疗社区问答文本不仅具有传统社区类文本体量大、数据稀疏的特点,还具有医疗文本的专业性和复杂性,同时由于个人语言习惯不同,医患问答文本中还有大量简写、略写甚至模糊的表达,给医疗实体识别工作带来了巨大的挑战。
2 相关研究
命名实体识别(named entity recognition,NER)是指识别文本中具有特定意义的实体。医疗实体识别,就是从文本中识别出具有医学意义的实体,如疾病名称、治疗手段、检查方法、药物名称等。对于医疗实体识别,目前采用较多的有基于词典和规则的识别方法、基于浅层机器学习的识别方法以及基于深层神经网络的识别方法。
早期的医疗实体识别,多采用基于词典的方法。基于词典的方法是原理比较简单但也是最有效的方法之一,其基本思路是通过遍历词典进行字符串匹配而实现实体识别[3]。如,Kristina 等[4]结合来自UMLS、MeSH 等医学平台的信息,开发了用于识别文本中的小分子和药物的词典,并将其予以应用于识别医疗实体;宁时贤[5]通过生物医学词典识别了医学实体,经过实验验证表明,词典特征有助于生物医学实体的识别。上述基于词典的方法虽然能对医学实体进行有效识别,但由于对医学词典和医疗知识库的依赖程度较高,导致该方法的灵活程度较低。
近几年,随着人工智能与其相关技术的快速发展,“机器学习”这一概念逐渐进入人们的视野,基于浅层机器学习的实体识别方法也随之得到快速发展。浅层机器学习方法主要包括条件随机场(conditional random fields,CRF)模型、隐马尔可夫模型(HMM)、最大熵 (ME)模型、支持向量机(SVM)等[6]。王若佳等[7]针对电子病历分词后的文本,采用条件随机场机器学习算法进行实体识别,结果表示该算法对医疗实体中“检查”和“疾病”两类实体的识别效果较好。龚乐君等[8]基于领域词典和条件随机场模型,从中文电子病历文本中识别出了4 类医疗实体,该模型在测试数据中的精确率达到了96.7%
2006 年Hinton 等[9]创建了一种多层次的神经网络训练方法,完成了神经网络从浅层到深层的转变,深度学习由此诞生。基于深度神经网络的实体识别方法在近几年成为了实体识别领域的热点,如曹明宇等[10]使用双向长短期记忆神经网络模型(bi-directional long short-term memory,BiLSTM)对医学药物类实体进行了识别,结果明显优于针对相同数据集所采用的其他识别方法;李纲等[11]采用BiLSTM-CRF 模型,针对全国知识图谱与语义计算大会(China Conference on Knowledge Graph and Semantic Computing,CCKS)提供的中文电子病历做医疗实体识别,结果表明该方法能够显著提升传统CRF 方法的实体识别效果;李双丽等[6]提出一种基于卷积神经网络(convolutional neural networks,CNN)-长短期记忆神经网络模型(long short-term memory,BLSTM)-CRF 的医学实体识别方法,通过卷积神经网络抽取英文的字符特征和单词特征来进行实体识别,并在Biocreative ⅡGM 和JNLPBA2004生物医学语料上验证了该方法的有效性。
虽然采用上述方法均能有效识别有关文本中的医疗实体,但是以上识别方法大多是针对语言专业化和结构化程度较高的电子病历文本或者医学语料库而进行的。相比于去实体医院,目前越来越多的患者选择直接在医疗社区平台或者社交媒体上进行在线的专业咨询和健康经验分享[12],此类医患问答文本数据是患者最真实、最直接的需求和想法反馈,但针对在线医疗社区中的患者编写文本做医疗实体识别的研究仍然相对较少。因此,本研究将以在线医疗社区中的问答作为文本数据源进行医疗实体识别工作。由于在线医疗社区中的问答文本非结构化程度高、文字表达因个人语言习惯也有较大差异,因此本研究提出一种基于CNN 和BiLSTM 的医疗实体识别方法。
3 基于CNN 和BiLSTM 的实体识别方法模型
图1 为本研究提出的实体识别方法的整体框架示意图,模型整体可分为3 个模块,分别为CNN 模块、BiLSTM 模块以及CRF 模块。模型先利用字向量通过CNN 识别出中文单个字的汉字级特征,再采用BiLSTM 识别出结合上下文信息的特征,然后将以上两种特征相结合放入CRF 模型中进行训练,最后采用寻医问药网在线医疗社区中有关乳腺癌的医患问答对方法的有效性进行验证。
首先对文本数据进行清洗去重等预处理操作,之后选取处理好的部分数据,根据定义好的实体类别采用BIO 标注法对文本数据进行逐字标注,然后将标注好的数据分为训练集和测试集,其中80%为训练集,20%为测试集。接下来将训练集中的数据分别放入CNN 和BiLSTM 模型中抽取汉字级别的特征以及结合上下文信息的特征,并将抽取得到的特征利用连接函数融合,放入CRF 模型中输出预测结果,将标注好的测试集的数据对结果进行验证,从预测结果的准确率、召回率和F值3 个指标评价模型的质量。经过对上述模型中的参数多次设置和调整,选取预测结果指标最优的模型作为最终的预测模型,最后将前期未被标注的文本数据放入已训练好的预测模型中去,经过所选模型的计算,得到最终的实体识别结果。
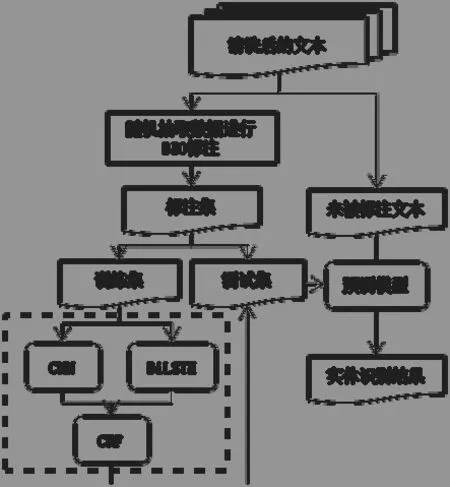
图1 医疗实体识别方法框架
3.1 CNN 模块
20 世纪60 年代,科学家们在研究猫的脑皮层局部的神经元时发现,其独特的网络结构可以有效地降低反馈神经网络的复杂性,从而提出了“卷积神经网络”的概念。卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络[13],是深度学习的代表算法之一。自提出以来,卷积神经网络已大量应用于图像、视频等文件的处理领域中。2014年Kim[14]对CNN 的输入层做了改进和调整,提出了适用于文本的处理的模型,自此CNN 也被广泛应用于对文本的处理中。如,陶源等[15]结合门控线性单元和卷积神经网络在中文数据集SIGHAN2006上进行了实体识别,识别准确率达到了91.05%;曹依依等[16]采用卷积神经网络针对中文电子病历进行了实体识别,识别结果F 值达到了90.31%。所以,本研究提出采用卷积神经网络模型来识别文本中的特征进行医疗实体识别。由于医患问答文本中可能由于个人语言习惯导致医疗实体间距离较远,如“我最近嗓子疼,不光是吃东西的时候疼,有时候就连喝水的时候也觉得疼,吃了阿莫西林等消炎药之后感觉好多了”这句话中,疾病实体“嗓子疼”就与药物实体“阿莫西林”距离较远,而且词向量难以处理长距离的依赖关系,因此本研究采用字向量与卷积神经网络结合的方式,首先对在线医疗社区中的问答文本进行特征抽取。
卷积的表达式用矩阵表示见式(1)。其中:s代表卷积函数;*表示卷积操作;X为输入,A为卷积核,n代表词的数量。

在卷积神经网络中,若是二维的卷积则表示如式(2)所示。其中:i和j分别代表二维矩阵的长和宽。

卷积神经网络可以分为输入层、隐藏层和输出层。在适用于文本的卷积神经网络中,输入层是句子中的词对应的词向量或字向量依次排列的矩阵,假设句子有n个词(或字),向量的维数为k,那么输入层的向量矩阵就是n×k。通常用户图像识别的卷积神经网络使用的卷积核的宽度和高度是一样的(见图2),但在处理文本数据卷积神经网络中,卷积核的宽度与词向量或字向量的维度一致(见图3),只有高度可以任意设置,输入的每一行向量代表一个词或字。

图2 图像识别的CNN 卷积核
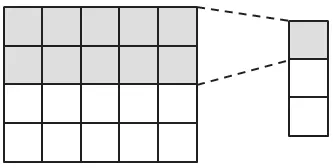
图3 文本处理的CNN 卷积核
本研究采用文本的字向量作为输入层。数据通过输入层后抵达卷积层,模型设置3 层卷积,卷积后的数据将会依次通过归一化处理和ReLU 激活函数,后转化形状输出。其中ReLU 函数的公式见式(3):

3.2 BiLSTM 模块
长短期记忆神经网络模型是为了解决循环神经网络中的长期依赖问题和梯度消失问题而衍生出来的模型,而双向长短期记忆神经网络模型包含了两个方向的长短期记忆神经网络模型,如图4 所示。

图4 BiLSTM 模型结构
在BiLST 模型中,每个细胞内部结构如图5 所示。其中:ht为当前隐藏层状态;xt为当前输入;ct为当前细胞状态;δ为Sigmoid 激活函数。从RNN 改进而来的长短期记忆模型利用门机制可以克服RNN 的缺点[17],这种门机制即通过遗忘门、输入门和输出门的引入,可以有效解决梯度消失等问题。

图5 BiLSTM 的单元内部结构
由图5 可见:
(1)遗忘门原理:上一阶段的ht-1与当前的输入xt级联之后,经过 Sigmoid 函数后与ct-1相乘。若δ函数的输出ft接近 0,则表示ct-1这个信息被忘掉了。ft的计算公式见式(4),其中W和b分别为模型的权重和偏置向量。

(2)输入门原理:上一阶段的ht-1与当前输入xt级联之后,经过Sigmoid 函数后与 tanh 的输出相乘,并与之前的细胞状ct-1×ft相加,得到ct。若it接近 0,则表示此输入被丢弃。

(3)输出门原理:上一阶段的ht-1与当前的输入xt级联之后,经过Sigmoid 函数后与 tanh(ct)的输出相乘,得到ht。其中O代表输出。若Ot接近 0,则表示输出细胞信息不会进入到隐藏层状态中。

3.3 CRF 模块
由于CRF 能更有效地限制输出的序列位置,因此可以避免前期CNN 和BiLSTM 特征抽取输出的结构错误,所以在实体识别模型的最后会将数据输入线性CRF 中。2001 年Lafferty 等[18]首次提出一种判别式概率——条件随机场模型,是在给定一组输入序列条件下另一组输出序列的条件概率分布模型,在自然语言处理中得到了广泛应用。即给出输入序列,便可以通过线性CRF 得到对应的序列的概率,即。其概率的计算公式见式(9),其中wk为权重值。
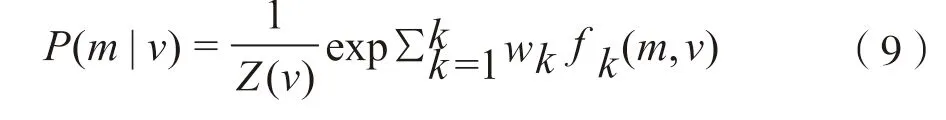
综上,本研究提出的基于在线医疗社区问答文本的医疗实体识别方法的流程可表示为如图6所示。

图6 医疗实体识别方法流程结构
4 实验和结果
4.1 实验环境
本研究的实验采用Python 语言(版本3.7),在Pytorch 深度学习框架下进行。Pytorch 是Facebook 开源的神经网络框架,相比于其他深度学习的编程框架而言,具有简洁、高速、易用等特点。
4.2 实验数据
爬取了寻医问药网问答模块中关于乳腺癌的12 000 条患者提问及其对应的医生回复,经过清洗去重等预处理操作后,保留了10 673 条有效问答文本(以下简称“样本”)(即10 673 条提问和10 673 条回复)。为了使数据格式统一规范以及保证问答数据一一对应,将患者提问和对应的医生回复拼接成一条数据,并将所有拼接后的文本数据作为实验数据,文本拼接格式为“患者病情描述(Q)+医生对应回复(A)”,如表1 所示。

表1 样本实验数据示例
4.3 实体类别确定
根据ICD-10 和各百科网站对医疗实体的划分,并参考杨锦锋等[19]和杨文明等[20]对医疗实体的分类方式,将医疗实体分为疾病(disease)、症状(symptom)、药物(medicine)、治疗(treatment)和检查(check)这5 项基础类别。因患者在描述自身病情和症状时常会提及对应的身体部位,如“胸部有硬块”“淋巴结那里疼”“手指也有明显的肿胀”,若只将“硬块”“疼”“肿胀”等词标记为症状,则会遗漏部分信息或扭曲患者原有的描述意图,所以增设身体部位(body)类别,以提高症状类别识别的精确度。实体细分类别如表2 所示。

表2 医疗实体细分类别
4.4 文本标注
采用BIO 标注法对预处理好的数据进行实体标注,随机选取了共计2 000 条数据进行标注。BIO标注是将每个文本中的每个字标注为“B-X”“I-X”或者“O”的形式[21]。其中:B 即Begin,表示开始;I 即Intermediate,表示实体的中间或结尾;O 即Other,表示其他;X 表示实体的名称。则“B-X”所标注的字是X 类型并且是该实体的开头,“I-X”所标注的字是X 类型并且是该实体的中间部分,“O”表示不属于任何类型。如,对于“经过钼靶照相确诊了乳腺癌,现在在接受化疗”这个短句,根据BIO 标注规则,其标注后的结果如表3 所示。其中“钼靶照相”为检查类的实体,“乳腺癌”为疾病类的实体,“化疗”为治疗类的实体,其余均不属于任何实体类别。将标注后的2 000 条数据中的1 600 条作为训练集、400 条作为测试集,供后续模型的训练和检验使用。

表3 样本BIO 标记结果示例
4.5 实验结果
在本研究给出的医疗实体识别模型中,样本的参数设置如表4 所示。

表4 样本医疗实体识别模型参数设置
对实验结果采用准确率、召回率和F值进行评价。其中:准确率又称为查准率,它表示实体识别的正确程度;召回率也称为查全率,它表示识别实体的覆盖度;而F值则综合考虑了准确率和召回率。上述3 个指标的计算公式分别如下:

为验证模型中CNN 模块的有效性,选取BiLSTM-CRF 实体识别模型作为对比,实验结果如表5 所示。可以看出,基于CNN 和BiLSTM 的模型识别方法,总体和各个实体类别的指标结果准确率均优于BiLSTM-CRF 实体识别模型,其中疾病和治疗类别的结果有较大提升,召回率和F值指标也有明显提升,说明本研究提出的基于的CNN 的医疗实体识别方法在针对在线医疗社区问答文本的数据集上是有效的。

表5 样本基于卷积神经网络模块的有效性验证结果
为验证模型中BiLSTM 模块的有效性,选取CNN-CRF 实体识别模型作为对比,实验结果如表6所示。可以看出,基于CNN 和BiLSTM 的模型识别方法,各指标结果均优于CNN-CRF 实体识别模型,说明本研究提出的基于的BiLSTM 的医疗实体识别方法针对在线医疗社区问答文本的数据集是有效的。

表6 样本基于双向长短期记忆神经网络模块的有效性验证结果

表6 (续)
5 结论
随着互联网不断深入人们生活的方方面面,以及人们对于健康的重视度逐渐提高,互联网医疗领域的研究也是当下的热点,其中通过对文本中的医疗实体识别从而构建医疗领域的知识图谱更是研究的热门。目前,在线医疗社区为广大患者提供了方便、及时的咨询平台,越来越多的人通过在线医疗社区寻医问药、查询病情,其中的医患问答对话反映了患者最真实、最直接需求,但此类文本结构化程度不高且融合了个人的语言习惯,分析较为困难,为此,本研究聚焦于此类问答文本数据,提出一种基于CNN 和BiLSTM 的医疗实体识别方法,致力于通过CNN 和BiLSTM 两种深度学习算法,分别抽取文本特征并进行融合,多方位地获取文本中的信息,以提高医疗实体识别的效果。
通过针对寻医问药网平台上关于乳腺癌疾病问答文本进行实验,结果表明本研究提出的模型方法优于BiLSTM-CRF 和CNN-CRF 方法,且总体识别准确率达到92.3%、召回率达到89.3%、F值达到90.8%,即表示此方法是有效的。虽然本模型方法取得了较好的识别结果,但研究数据所涉及的疾病仅包含乳腺癌,疾病类别比较单一,今后的研究将结合更多类型的疾病和医疗社区平台进行。
猜你喜欢
现代电力(2022年2期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
中国外汇(2019年18期)2019-11-25
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
当代陕西(2019年5期)2019-03-21
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
领导决策信息(2017年9期)2017-05-04
