
Spark集群下基于关联规则的产品加工质量分析
2021-05-25 08:00:22李卓航荀亚玲薛晓鹏李元庆
太原科技大学学报 2021年3期
李卓航,荀亚玲,薛晓鹏,李元庆
(太原科技大学 计算机科学与技术学院,太原 030024)
制造业作为国民经济的支柱产业、作为一个国家综合国力的象征,依靠传统低成本战略的发展方式已经走到了可持续发展的尽头。全球市场竞争不断加剧,高质量的产品成为保证企业立于不败之地的关键,因此,企业必须实施全面质量管理[1-2],而企业在生产运营过程中积累的大量数据为企业进行有效的质量管理提供了新的机遇。尤其是近年来物联网技术和移动技术的发展,使制造业产品整个价值链都“生产”了海量数据,数据急剧膨胀,制造业面临着工业大数据时代带来的新挑战[3-5]。且制造业数据具有多源、大体量、异构、不确定和高噪声等特征,如此庞大和复杂数据背后隐藏的价值是不可估量的,对这些数据的有效挖掘将成为实现我国制造业在工业大数据环境下向智能制造转型的必要手段。
数据关联是数据集中存在的一类重要的知识,关联规则挖掘作为数据挖掘的关键技术之一是发现该类知识的有效手段[6]。关联规则的挖掘可以在不知道或数据间的关联函数或模型无法确定时,发现数据中不同属性取值之间存在的某种关联性和规律性,从而发掘隐藏在其背后的、对用户有用的关联知识。
Spark是继Hadoop之后的又一高效的并行计算框架[7],其是基于内存计算的,这正是Spark相比Hadoop更获取更大性能优势的原因所在。Spark尽量将数据及中间结果保存在内存中,而不需要读写底层的HDFS,因此,Spark能更好地适用于具有复杂迭代的算法。而Fp-Growth频繁项集挖掘正是一个不断迭代的过程。本文充分利用Spark对Fp-Growth具有复杂迭代过程数据处理的支持,设计并实现了一种高负载均衡的并行频繁模式挖掘算法HBPFP(High Balanced parallel Fp-Growth);并将其应用到产品加工质量分析过程中:利用关联规则挖掘产品加工过程中积累的大量“噪声”数据中包含的相关性知识,同时以生产加工顺序为约束,发现工序质量对产品质量及对后续工序质量的影响与规律,从而对加工过程的异常趋势提出预警,实现对质量影响因素的有效监控。从而为企业开展有效的产品质量控制提供新的方法和解决思路质量的影响与规律,从而对加工过程的异常趋势提出预警,实现对质量影响因素的有效监控。从而为企业开展有效的产品质量控制提供新的方法和解决思路。
1 相关工作
关联规则在制造业中的应用已经渗透各个部门和各个阶段,从原料供应商管理、客户需求关系管理到生产过程控制,再到产品销售和售后服务等产品的全生命周期阶段及相关部门[8-10]。
产品质量的提高是企业生存的根本,近年来,为应对传统统计学方法对海量数据处理的不适应性,关联规则挖掘已被广泛应用到企业产品质量管理和控制过程中。目前,快速识别那些最有可能导致产品质量问题且具有高产出的机组已经被很多尤其是规模较大的企业关注,孙广建等将关联规则用于企业质量信息流的管理,其主要是通过挖掘车身制造企业加工过程的各个环节与产品质量间的密切关联,并最终开发了企业质量信息流管理系统[11];段桂江等通过对质量成本数据的挖掘,寻找隐含的质量成本动态数据之间的相互联系,并基于此,将企业加工过程中的特征数据实现了模糊化处理,最后再利用模糊神经网络完成最终的质量成本预测性分析[12];文献[13]将关联规则挖掘应用到装配序列对产品质量的影响过程中,其研究结果表明,即使在有噪声的情况下,对产品质量产生影响的装配序列故障源也能通过关联规则被发现,从而免有风险的装配序列对装配操作质量造成的不良影响;郭钧等先通过分析确定影响产品质量的主要因素,然后利用关联规则挖掘这些因素之间的相互影响,从而将对管理者最有帮助的质量特性与其影响因素之间的相关性反馈到制造过程控制活动中[14];谭军利用关联规则发现不同部门的输入流程参数组合与产品最终质量特性之间的相关性,然后运用遗传算法对这些规则进行优化,从而辅助流程工程师对流程参数的设置进行调整[15];璩晶磊等将关联规则挖掘应用到制造过程质量监控过程,整个过程利用了有监督学习的思想,在规则中无论是前件还是后件,均以加工工序的先后顺序为约束,同时将工序质量信息定为规则的输入变量约束,而产品质量信息则为输出变量,最终获取生产加工工序间的隐含规则,在该挖掘结果的基础上,该研究采用复杂事件处理技术实施其整个离散制造过程的质量控制与管理[16]。
总之,智能挖掘方法的应用在制造业还是相对落后,很难从海量的复杂的与产品质量相关的数据中提取有效改善产品质量的信息。
2 Spark集群下负载均衡的Fp-Growth算法
2.1 基于Spark的Fp-Growth并行过程
经典的Fp-Growth算法将数据集压缩到一颗树结构中—Fp-tree,然后基于该树来挖掘所有的频繁项目,其执行效率远高于Apriori算法。Fp-Growth在Spark集群下的并行化过程主要分为五步(执行流程如图1所示):
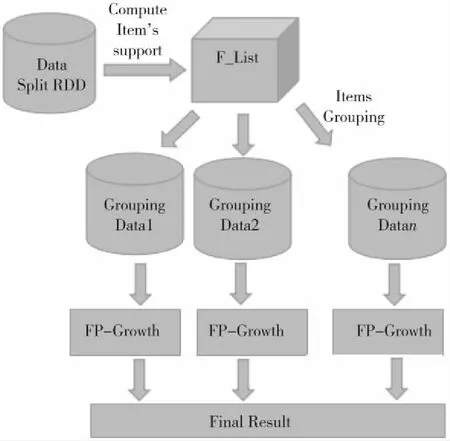
图1 基于Spark的Fp-Growth并行过程Fig.1 Spark-based Fp-Growth parallel process
(1)数据集分布存储。RDD是Spark可操作的记录分区的集合,因此,第一步需要将数据集上传至RDD;(2)并行计算F_list.这一步通过一对Map-Reduce完成,首先利用flatMap将原始数据集的每条事物映射成
2.2 负载均衡的分组优化策略
在上述并行挖掘过程中Step3的项目分组对算法性能有明显影响,因为项目进行分组后,每个节点负责一个分组相关数据的计算任务,分组的好坏直接决定了各节点的计算负载。为了获取均衡负载的项目分组策略,本文提出一个节点计算量预估模型。
Zhou等人针对该问题提出了一种负载均衡的分组优化方法[17],认为针对每个项目的挖掘负载取决于挖掘过程递归数,该算法将项目在F_list中的位置作为递归次数的判断依据,见式(1).
Cost(i)=log(P(i,F_list))
(1)
其中,P(i,F_list) 为项目i在F_list中的位置。
这种估算方式显然是不准确的。本研究旨在项目分组之前,建立更为精确的计算量预估模型,具体过程如下:
当在Step2中生成F_list后,每条事物Ti会基于F_list进行裁剪(删掉非频繁项)与重排(按照支持度降序排列),被处理后的事务被记作Ti′。本文提出的HBPFP(High Balanced parallel Fp-Growth)算法通过将每个项目的后缀长度信息作为该项的计算量估值。事物Ti′的后缀长度信息提取过程为:(1)遍历Ti′中各项到root的每条路径长度;(2)将各项的每条路径长度依次累加后产生该项最终的后缀长度信息。因此,该项对应的计算负载估值为:
(2)
在获取到每个项目的计算负载估值后,Step3中的项目分组策略将依据式(2)计算负载估值进行分组,以保证各计算节点分配任务的均衡化。
3 基于关联规则的产品加工质量控制模型
在生产制造过程中,每一道工序质量都会对产品质量形成产生直接或间接的影响,因此,工序质量成为了保证产品质量最基本的环节,也是产品加工过程质量控制的核心。企业在其生产加工过程中积累了大量的、杂乱的、分散的、类型复杂的、组织不一致的数据,且企业的生产模式也逐渐转化为多品种、变批量生产模式,致使影响产品质量的因素大大增加且动态多变,从而极大地增加了产品工序质量控制难度。基于该现状,提出一种基于关联规则的加工质量控制模型,如图2所示。
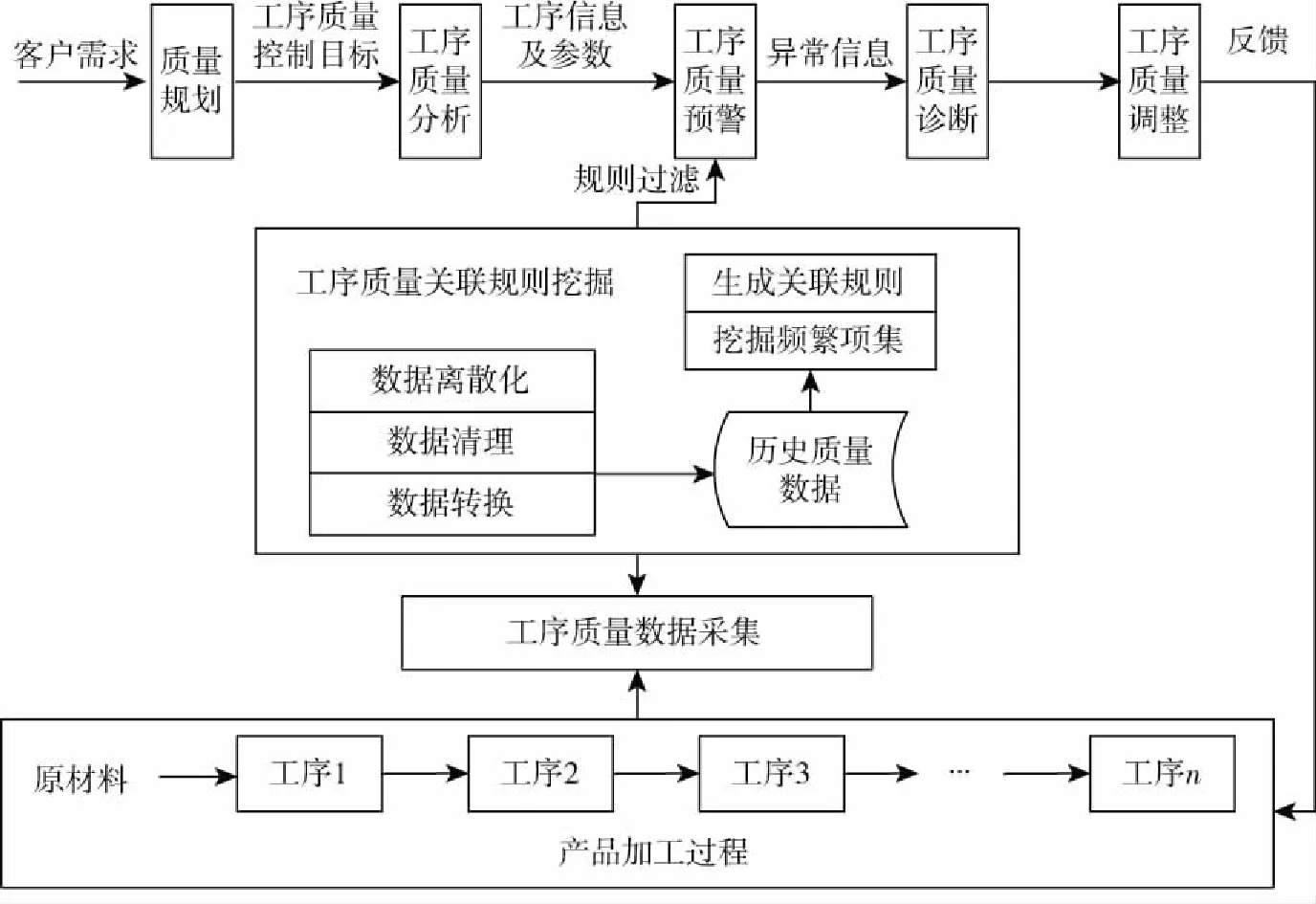
图2 基于关联规则的质量控制模型Fig.2 Quality control model based on association rules
该模型主要包括以下几部分:①数据的采集:通过传感器实时采集各工序上的质量指标参数及可能来自原始信息系统积累的数据;②关联规则生成:对上述采集的数据先进行预处理操作(例如:数据清洗、转换、离散化等)形成历史质量数据集,然后利用关联规则挖掘算法挖掘工序间的、工序与产品质量之间的相关性知识;③规则过滤:事实上,并不是所有直接挖掘出来的结果都是有意义的,因此,在生成规则的过程中,需要根据实际应用领域的背景知识提供一个过滤机制,以筛选出有用规则供进一步的质量监控分析;④反馈与调整:基于关联规则的质量监控模型将客户需求转化为产品加工过程中的关键工序及工序质量控制目标后,形成工序信息及质量过程控制参数与规范,然后将挖掘出来的相关性知识与每道工序的质量控制目标进行对比分析后,将决策信息反馈给产品加工过程,从而进一步帮助企业有针对性地调整生产过程参数和加工工艺。
4 应用案例
4.1 冷轧辊生产管理特点及系统架构
冷轧辊是典型的多工序制造过程,工序繁多且各工序间连续性很强、质量控制点多,整个生产过程50多道工序。冷轧辊的每道工序都有多个检测指标,比如精车外圆工序就涉及辊颈长度、辊身外圆直径、辊颈直径、直线度等多项指标,且加工过程会受到各种因素的影响,包括:加工过程中的人为因素、环境因素;组成工艺系统的各要素,比如机床、夹具、工件和量具等。当其中某个工序的一个或多个指标出现异常时,需要及时给予反馈,以避免产品加工工序之间误差传播的影响。在冷轧辊加工过程中,不同加工环节会存在若干关键工序,例如:锻造中的球化退火,铸造中的熔炼,热处理中的湿度和温度控制等。另外,在冷轧辊加工过程中,铸造和热处理属于更为特殊的加工工序,因为这些工序的质量反应具有某种程度上的时滞性,也就是说该类工序监测指标的合格并不意味着真正意义上合格,因为其对产品质量的影响只有在稍后的工序中才能体现出来,因此,该类工序也应是质量管理过程中需要重点关注的对象。
鉴于上述冷轧辊的产品加工特性和质量控制特点,基于关联规则的冷轧辊质量管理系统,通过关联规则挖掘其加工过程中加工工序间的隐含规则,及影响产品质量的关键工序,这样企业实施质量控制时将不再无的放矢。其系统架构图如图3所示:

图3 系统架构图Fig.3 System architecture diagram
图3中最底层为数据源层,数据可以来自应用程序、传统关系数据库、传感器等,为完成数据的并行处理过程,其经预处理后需要导入分布式文件系统HDFS中;HDFS中的数据一方面可以直接采用Hadoop并行计算框架的MapReduce编程模型来直接处理,也可以利用Spark从HDFS上创建RDD数据源并对其进行分析处理;经处理后的数据将通过数据访问接口呈现给最终用户。
4.2 系统实现与运行结果分析
企业获取的原始数据进行相应的预处理后,该系统将加工过程的关键过程参数作为系统输入,以产品质量或后续工序过程参数作为系统输出,抽取两者之间复杂的非线性关系,用以发掘问题产品的关键影响因素,并将得到的知识反馈到加工质量控制过程,进而实现产品加工过程质量的持续改进。其中为了保证规则的有效性一方面需要用户确定有效的置信度约束,另一方面需要对规则的前件和后件进行合理的限制,以避免产生毫无实用价值的规则。图4为原型系统的最终运行结果。
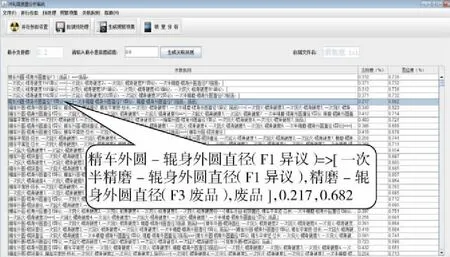
图4 质量分析结果Fig.4 Quality analysis result
5 总结
工业大数据时代,如何有效地利用这些数据,将这些数据背后隐藏价值转化成生产力,已成为一个企业提升企业竞争力、抢占新一轮先机的必要手段。本文在工业大数据环境下将关联规则应用于产品加工质量控制过程,以为企业在实际质量控制和生产决策过程提供依据。首先提出一种基于Spark并行计算平台的负载均衡的关联规则挖掘算法,并基于此构建了一个通用的产品加工质量控制模型,最后将其应用到某钢铁制造企业的冷轧辊生产过程,有效提高了产品加工直通率。
猜你喜欢
昆钢科技(2022年2期)2022-07-08 06:36:14
石材(2020年4期)2020-05-25 07:08:50
中国眼镜科技杂志(2019年9期)2019-11-11 12:15:30
劳动保护(2019年7期)2019-08-27 00:41:04
建材发展导向(2019年10期)2019-08-24 06:24:30
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:48
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:42
质量技术监督研究(2018年1期)2018-03-26 08:04:36
小学生导刊(低年级)(2017年1期)2017-06-12 12:07:42
新农业(2016年20期)2016-08-16 11:56:22
