
基于深度可分离卷积的人脸表情识别
2021-05-20 07:02:16李春虹
计算机工程与设计 2021年5期
李春虹,卢 宇
(四川师范大学 计算机科学学院,四川 成都 610101)
0 引 言
近年来,深度学习在图像处理等领域的发展,丰富了人脸表情识别研究,使人脸表情识别成为计算机视觉、模式识别领域的研究热点[1,2]。但现有主流的人脸表情识别模型往往存在泛化能力不足、识别率不高等问题,其主要原因是:当数据集处于复杂环境下时,容易受到人脸的姿势、遮挡及光照背景等与表情识别无关的非重要因素影响。为此,Wen等[3]提出利用人脸表情相关区域引导网络学习表情特征,从而减少与表情无关的非相关因素影响,但该模型只能达到基准精度。Jung等[4]提出利用两个浅层的基分类器分别提取图像的不同特征信息,但只适用于少样本数据集。Kim等[5]通过融合多个深度CNN的基分类结果进行指数加权决策融合来判定人脸表情类型。但是该方法复杂的网络结构和连接方式使得训练过程相当繁琐。
因此,本文研究一种即可以简化网络结构又能够较好地提高复杂环境下表情识别精度的方法,即基于深度可分离卷积的人脸表情识别(depthwise separable convolution-based facial expression recognition,DSC-FER)。首先,该方法结合相关全卷积神经网络理论,通过构建人脸分割网络提取出人脸表情中感兴趣区域。其次,利用深度可分离卷积构建VGG19和ResNet18基分类器,提取不同特征信息。最后,采用联合微调方法融合基分类器进行人脸表情识别。实验结果表明,与文献[6-12]相比,该方法能有效地提高人脸表情识别算法的鲁棒性和识别率。
1 理论基础
1.1 卷积神经网络
至AletNet网络提出以来,随着十几年的发展,卷积神经网络已经成功应用于计算机视觉等相关任务中,它是有效提取深度图像特征的深度学习模型,主要包含卷积层、池化层、激活函数、损失函数等[13]。卷积层是由若干卷积核组成,主要通过卷积操作实现局部特征响应,使用相同卷积核扫描整个图像进行特征提取。卷积层进行卷积操作公式如下
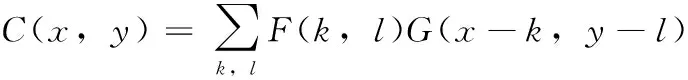
(1)
式中:C(x,y)=Fk×l⊗Gu×n为卷积操作,Fk×l是大小为k×l的卷积核,Gu×n是u×n的输入矩阵,C是卷积后的输出矩阵,∀x∈[0,u),∀y∈[0,n)。
池化层是对特征进行聚合统计,目的是提高特征的表征能力、减少特征维度。一般常用池化层有:随机池化、平均池化和最大池化。最大值池化取池化域中的最大特征值,最大池化公式如下

(2)
平均池化即取池化域中的特征均值,公式如下
(3)
式中:S(x,y)=Fs×tGu×n为最大池化操作,M(x,y)=Fs×tGu×n为平均池化操作,Fs×t是大小为s×t的池化核,Gu×n是大小为u×n的输入矩阵。
激活函数定义请参见文献[13]。其中,Softmax函数是将神经元映射到(0,1)区间。Relu函数收敛速度比sigmoid函数和tanh函数快,是最简单的激活函数,解决了梯度消失问题,并使模型的收敛速度保持稳定状态。Relu函数公式如下
F(x)=Max(0,x)
(4)
式中:F(x)为Relu激活函数,当x<0时,F(x)=0; 当x∈[0,x],F(x)=x。
损失函数定义请参见文献[13],其中均方误差损失函数公式如下
(5)
式中:y表示样本真实标签,y′表示样本预测标签,N表示样本个数。
1.2 模型融合
模型融合是将多个基分类网络解决同一任务的结果进行整合,以提高模型的泛化能力,目前已经被广泛地运用在机器学习的多个领域。模型融合关键的问题是考虑如何更好地融合基分类模型。常见的融合方式有投票法、加权求和、bagging、boosting、stacking等,其中最常用的是加权求和
Yi=αpi+(1-α)qi, 0≤α≤1
(6)
式中:pi,qi分别是不同的基学习网络输出值,Yi是最终预测值,i=1,…c,c是类别总个数,参数α是权值。加权求和的优点是合适的参数α能够提升模型的识别率和泛化能力,缺点是无法最大限度地利用两种模型性能。因此,本文采用联合微调方式进行融合,取得了比加权平均更好的效果。
2 基于深度可分离卷积的人脸表情识别方法
本文依托VGG19和ResNet18经典模型,构建了DSC-FER方法的流程如图1所示,它主要分成预训练、表情识别模型两部分,其中预训练包含RROI部分和基分类模型,表情识别模型中灰色框表示冻结训练好的网络权重值。
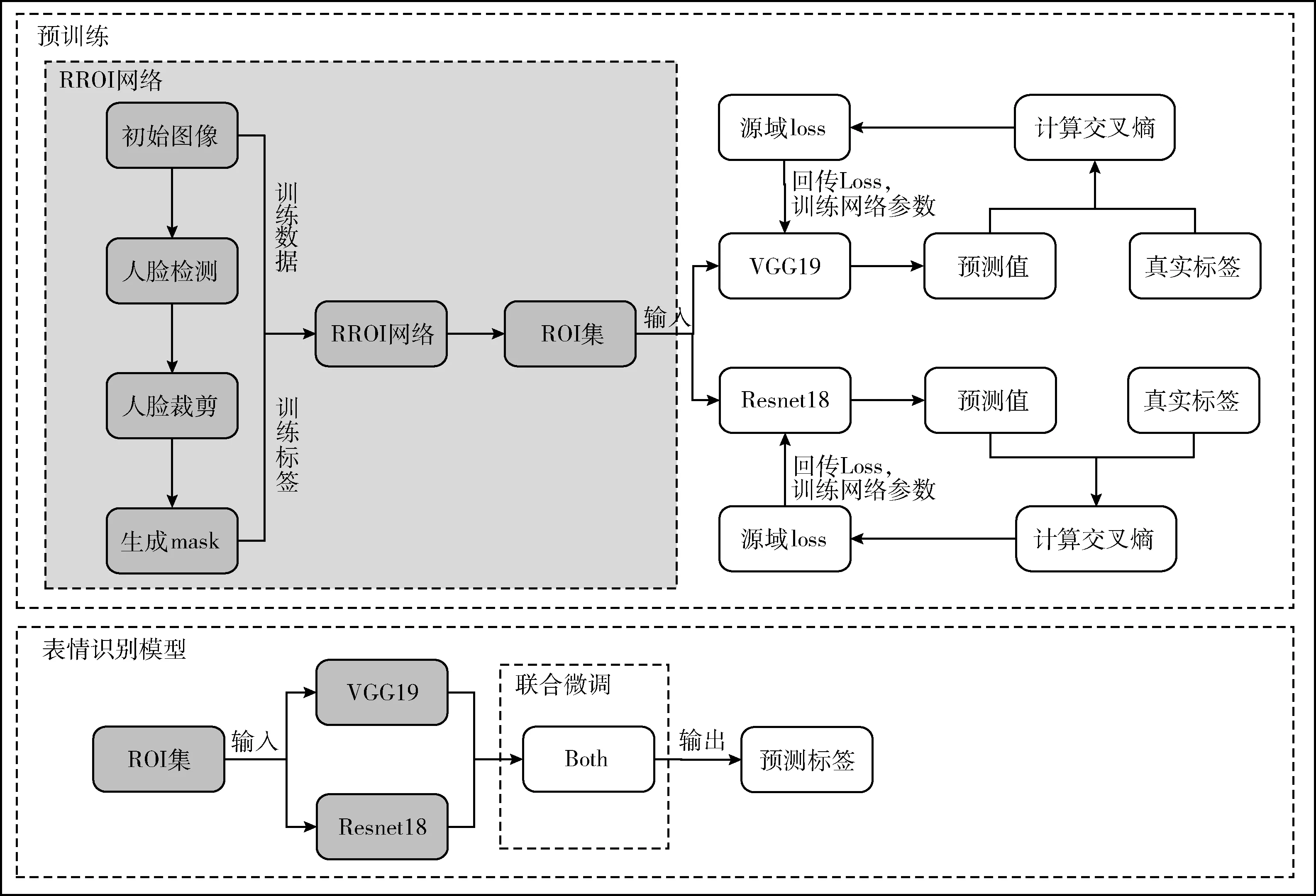
图1 DSC-FER模型描述
2.1 本文算法实现
算法描述如下
算法1: DSC-FER方法
输入: 数据集D=(X,Y) 以及参数Time、θ; //X为输入图像集合、Y为类别标签集合、Time代表最大训练次数、θ表示损失函数收敛的一个阈值
输出: 人脸表情识别模Ω;
步骤1 从已有数据集D1中划分出训练集Ts1, 测试集Te1;
步骤2 (1) Fori=1 To len(Ts1)
根据Dlib提取面部标识, 裁剪相应区域, 并生成mask实例;
添加mask到MS集合中;
End For
(2)以Ts1为源数据、MS为源标签训练RROI网络;
步骤3 (1)利用训练好的RROI, 对数据集D提取ROI, 再划分出训练集Ts, 测试集Te;
(2) 随机初始化基分类模型Ω1和Ω2的所有参数; //VGG19为Ω1, ResNet18为Ω2
(3)取出训练集Ts中所有实例Xa作为输入, 分别输入到Ω1和Ω2中, 计算的图像特征;
(4)记所有的预测标签为y′, 真实标签为y;
(5)如式(11)所示, 采用交叉熵公式作为Ω1、 Ω2的损失函数Li;
(6)利用梯度下降法反向传播Li值, 调整Ω1、 Ω2中的参数;
(7)if(Time>0||Li>θ)
Time=Time-1
转至(3), 继续训练基分类网络
End if
(8)输出当前训练好的基分类网络模型Ω1、 Ω2;
步骤4 采用联合微调方法, 如式(10)-式(12)所示, 融合基模型Ω1、 Ω2得到最终面部表情识别模型Ω;
步骤5 输出人脸表情识别模型Ω, 算法停止。
上述DSC-FER算法的主要思想是:首先,利用实例生成mask分别做训练数据和标签训练RROI网络生成感兴趣区域ROI(region of interest,ROI)数据集;其次,采用深度可分离卷积代替二维卷积分别训练出基分类网络模型;最后,利用联合微调方法融合基分类模型。
2.2 预训练
在开始训练表情识别模型之前,需要先对两个基分类网络模型进行预训练。先利用RROI网络提取人脸表情感兴趣区域,再利用pytorch深度学习框架和VGG19与Resnet18基分类网络结构(参照文献[14]中图3的结构)分别建立深度学习网络,其中两个基分类网络中的每层卷积均由深度可分离卷积代替并在其后均添加BN层和Relu层,目的是加快网络的训练速度及避免梯度消失。最后,利用交叉熵损失函数分别计算出VGG19和Resnet18基分类网络预测值与训练集真实标签之间的误差值,并将该值作为模型损失值回传给对应的基分类网络,利用梯度下降法反向传播,更新网络参数。
2.2.1 RROI网络
RROI(recognition region of interest)是一个基于u-net[15]语义分割算法的人脸分割网络,其中u-net是个端到端的U型全卷积网络结构,不同于传统CNN,该网络用卷积层代替全连接层,使结构分为编码器、解码器两部分。其中编码器由3次下卷积层组成,其中一个下卷积层包括2个卷积层和1个最大池化层,主要用于提取深层次特征;解码器包含3次反卷积层,其中一个反卷积层包括1个反卷积、1个连接操作和2个卷积层,主要用于对特征映射进行上采样,其网络结构如图2所示。
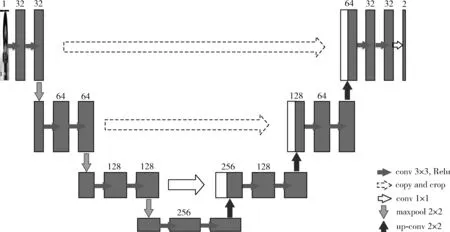
图2 RROI网络结构
RROI目的是提取出人脸图像中与表情识别最相关的感兴趣区域,使复杂环境因素对人脸表情分类影响降低、精简网络结构,提高识别精度。本文的做法是:首先,人脸检测并提取现有的实例中的人脸特征点,根据68个特征点坐标构成的凸包裁剪出ROI区域,将ROI区域处理成Mask图像作为网络的训练标签,原始人脸图像作为网络的训练数据;其次,利用编码器提取出图像的特征,再利用解码器上采样学习补充信息;最后,使用二维卷积将每个特征向量映射到所需数量的类。
2.2.2 深度可分离卷积
自2013年Sifre提出卷积层通道间相关性和空间相关性是可解耦合性的,深度可分离卷积已经是很多高效神经网络框架实现模型轻量化的关键构建块,主要由深度卷积和逐点卷积两部分组成。其中,深度卷积是对输入的每个通道上单独执行通道卷积,将普通卷积在空间上分离;逐点卷积是应用1×1卷积将深度卷积的特征图谱映射成新特征。公式表示如下
S(x,y)=P(Fp,D(Fd,G))
(7)
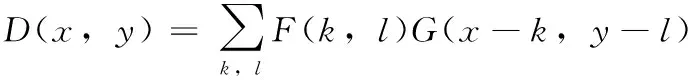
(8)
(9)
式中:D(x,y) 是深度卷积操作,P(x,y) 为逐点卷积操作,Fp是大小为1×1的卷积核,Fd是大小为k×l的卷积核,G是大小为u×n的输入矩阵,m为通道数。
与普通卷积相比,当在H×W×N的特征图上使用卷积核大小为k×k、深度为d的标准卷积操作时,计算参数量为:H×W×N×k×k×d,而深度可分离卷积的计算参数量为:H×W×N×(k×k+d)。 由此可见,标准卷积的参数量是深度可分离卷积的k×k×d/(k×k+d) 倍。
2.3 联合微调
本文采用联合微调的方式代替加权求和整合基分类模型,如图1中所示。首先,VGG19和Resnet18两个基分类网络使用相同训练数据集完成预训练阶段;其次,在表情识别模型中重用预训练好的两个基分类网络,并将两个基分类网络提取的特征重新构建成特征ξ3;最后,特征ξ3输入到both网络进行再训练分类,其中both是由一个全连接层和softmax函数组成的网络,并使用dropout方法减少过拟合。
在训练步骤中使用了3个损失函数,并定义DSC-FER的损失函数LDSC-FER为
LDSC-FER=λ1L1+λ2L2+λ3L3
(10)
式中:L1,L2,L3分别是VGG19,Resnet18,both的交叉熵损失函数值,λ1,λ2,λ3是平衡系数,其值的大小决定了联合微调方法对模型的影响程度,通常λ1=λ2, 0<λ3<λ1,λ2<1。 本文实验中设置λ1,λ2,λ3分别为1,1,0.1。其中,交叉熵损失函数如下
(11)
式中:yj表示第j类的真实标签,pj表示样本y属于j类的概率,N表示总样本个数,C表示样本种类
y=σ(ξ1⊕ξ2)
(12)
式中:y是both模型的输出值,ξ1,ξ2分别是基分类网络的特征,⊕是代表ξ1,ξ2特征串行连接,σ(x)是softmax函数。
3 实验及结果分析
3.1 数据集
为了验证本文表情识别方法的有效性,采用FER-2013、CK+和JAFFE这3种经典人脸表情识别数据集,三者均包含7个表情标签(愤怒、厌恶、恐惧、快乐、悲伤、惊讶、中性)。其中,FER-2013数据集是由35 886张采集于不同复杂环境因素下的人脸表情图像。CK+数据集包含123个用户的327个连续表情帧,由于连续帧之间相关性较强、数据冗余,因此本文选取每个表情峰值最高的最后3帧图片,共981张表情图像。JAFFE数据集提供了10名日本女生的7种不同表情,共214张表情图像。
3.2 数据增强
在训练表情识别网络之前,为了防止网络过快地过拟合进行数据增强:在训练阶段,将图像随机裁剪成44×44像素大小,并以0.5的概率随机水平翻转扩大数据集。
3.3 评价准则
为了说明本文所提出算法的有效性,实验结果采用的评价准则为识别率。一般来说,模型的识别率越高表示识别效果越好。识别率公式如下所示
(13)
式中:定义数据集(X,Y),X,Y分别表示数据集的实例和标签,Y′表示利用模型训练出来的预测标签,|Y|为总标签个数。当Yi=Y′i为真时,值为1,否则为0。
3.4 RROI网络实验结果
在RROI人脸ROI区域分割网络实验中,人脸图像和Mask标签均处理成48×48像素大小,再将mask像素值归一化到[0,1]之间。在FER-2013数据集上达95.52%分割率,CK+数据集上达96.63%,并对比RROI网络分割效果与人脸特征点裁剪人脸区域效果如图3所示,其中图3(a)为人脸原始图像,图3(b)为对应生成的mask标签,图3(c)为根据特征点裁剪的结果图,图3(d)为经过RROI网络得到的结果图,从图得出RROI网络具备与利用特征点裁剪人脸基本相同的分割效果。

图3 RROI效果
3.5 与现有表情识别算法的对比实验
在训练基分类网络时采用随机化初始权重和偏值,批大小设置为128,初始化学习率为0.01。
FER-2013数据集利用训练集来训练模型权重参数,将公共测试集作为验证集、将私有测试集作为最终测试集。然后,将DSC-FER方法在FER-2013数据集上的识别率与Liu、Guo、Yan和MSSD-KCF做实验对比,实验结果见表1。从表1中可知,DSC-FER方法的识别率达到了75.15%,比MSSD-KCF的识别率高出了2.15%,超过了其它网络的识别率,并且比FER-2013数据集上的识别基准线(71.2%)高出了3.95%。将DSC-FER方法的识别率与本文预训练的两个基分类网络,可得出经过联合微调后该方法比基分类网络平均高2.11%。实验结果表明了DSC-FER方法在人脸表情识别的有效性。
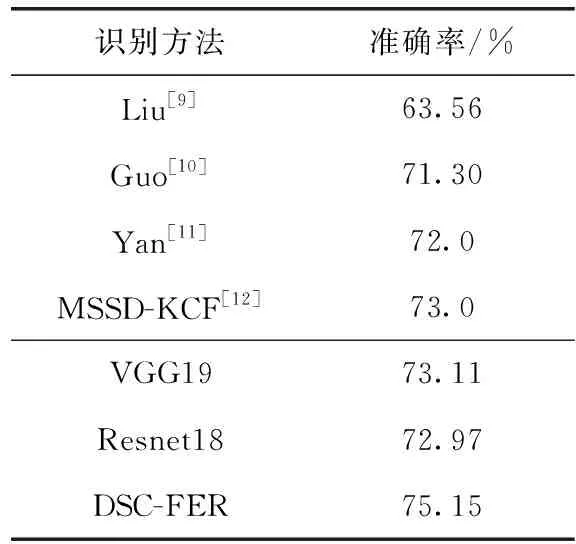
表1 FER-2013数据集上不同识别方法准确率对比
DSC-FER方法在FER-2013数据集上的识别结果混淆矩阵见表2。从表2可以看出,高兴和惊讶识别率较高分别达92%、84%,而愤怒、恐惧、悲伤3种表情识别率相对较低,愤怒中有13%识别成悲伤、恐惧中14%识别成悲伤、悲伤中11%识别成恐惧,如图4所示,可知这3种表情确实容易相互混淆。
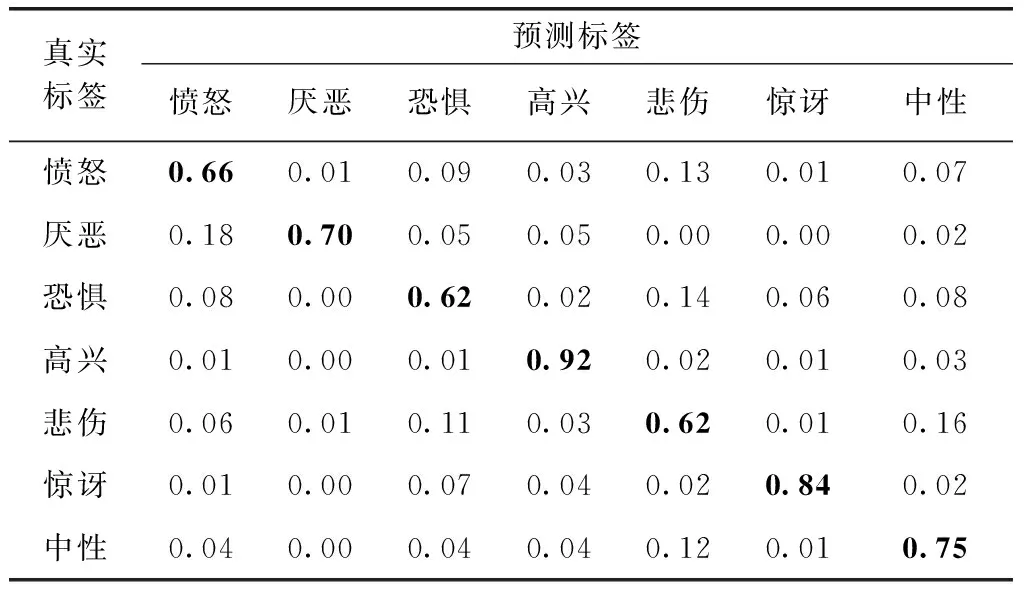
表2 FER-2013识别结果混淆矩阵

图4 混淆表情实例
同样,DSC-FER方法在CK+数据集上采用10折交叉验证,并与DAGN、DTGN、MSCNN、WGAN和WMDNN不同模型的识别率做实验对比,实验结果见表3。从表3可以看出,DSC-FER方法的识别率达到了98.98%,比WMDNN的识别率高出了1.96%,且超过了其它网络的识别率,将DSC-FER方法的识别率与本文预训练的两个基分类网络,可得出经过联合微调后该方法比基分类网络平均高4.63%。实验结果表明了联合微调方法的有效性。
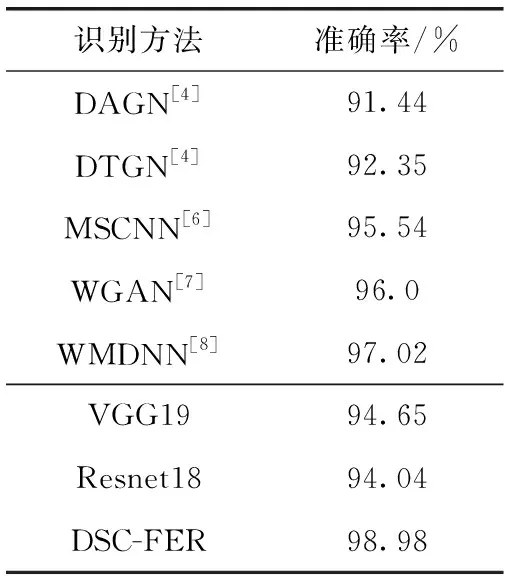
表3 CK+数据集上不同识别方法准确率对比
DSC-FER方法在CK+数据集上的识别结果混淆矩阵见表4。从表4可以看出,该方法将惊讶表情中的4%识别为恐惧,因其数据集量较小且表情图像噪声较少,所以除惊讶表情外其它表情均能正确分类。
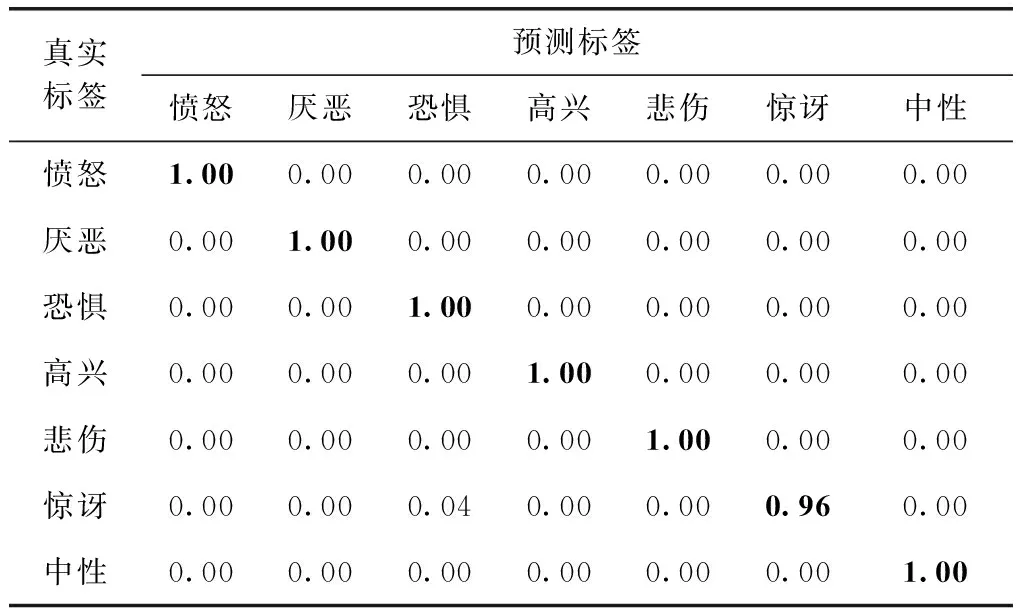
表4 CK+识别结果混淆矩阵
同样,DSC-FER方法在JAFFE数据集上采用5折交叉验证,并与DCMA-CNNs、ROI-KNN和WGAN的识别率做实验对比,实验结果见表5。从表5可以看出,DSC-
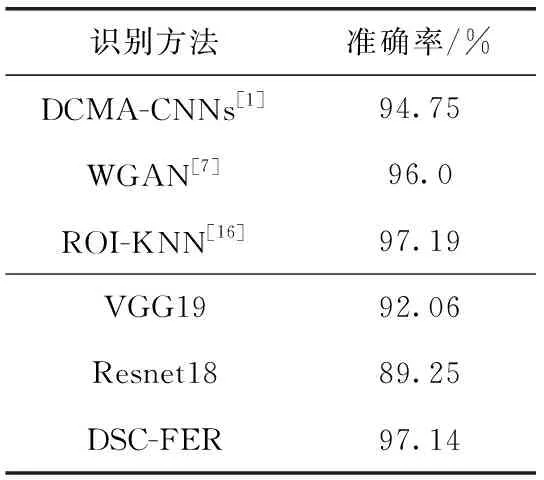
表5 JAFFE数据集上不同识别方法准确率对比
FER方法的识别率达到了97.14%,比WGAN的识别率高出了1.14%,与ROI-KNN的识别率只相差0.05%,几乎持平。然而,将DSC-FER方法的识别率与本文预训练的两个基分类网络,可得出经过联合微调后该方法比基分类网络平均高6.49%,更能体现出联合微调方法的有效性。
DSC-FER方法在JAFFE数据集上的识别结果混淆矩阵见表6。从表6可以看出,因其数据集是少样本数据集且表情图像噪声较少,最终该方法将恐惧表情中的部分识别为悲伤,悲伤错误地识别成高兴,所以除恐惧和悲伤表情以外其它表情均能正确分类。
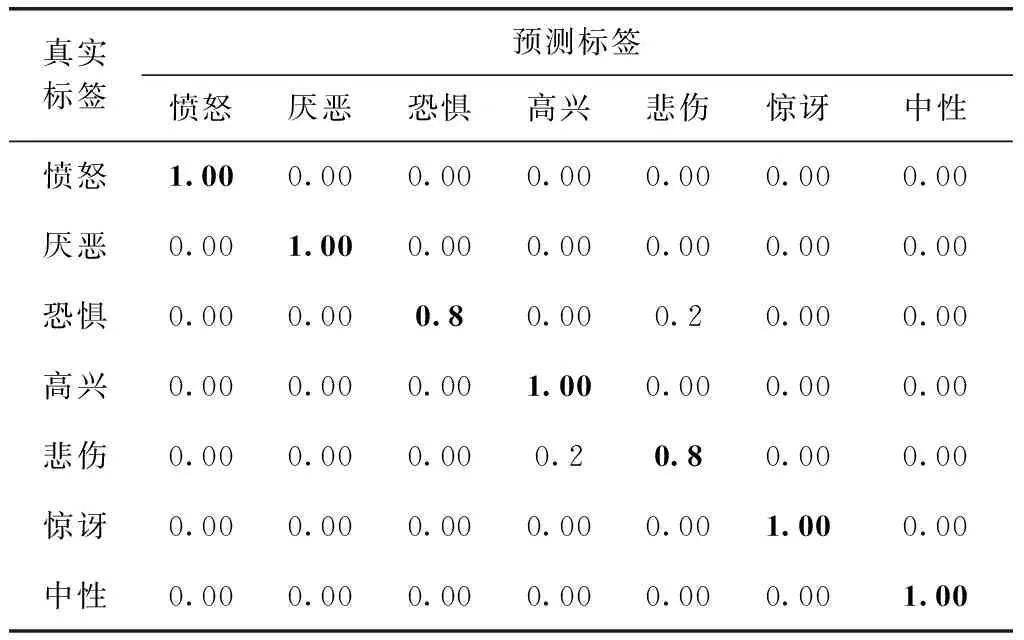
表6 JAFFE识别结果混淆矩阵
3.6 分析平衡系数λ对DSC-FER分类效果的影响
该实验目的是研究分析平衡系数λ对DSC-FER分类效果的影响,并对比联合微调和加权求和这两种不同的融合
方法的效果。对比表1和表3发现联合微调方法在CK+数据集上提升效果更大,因此,实验采用CK+数据集作为平衡系数影响实验的研究对象,并将λ依次取值0.05、0.1、0.2、0.3、0.4、0.5、0.6。
实验结果如图5所示,从图5中可以看出,在DSC-FER方法中联合微调比加权求和能更好地融合基模型,从而提高表情识别精度。随着平衡系数λ的增加,采用联合微调的DSC-FER方法在λ值为0.1时,模型准确率达到最高,当其值取0.05时,模型融合不见成效使准确率低于基模型达到最低,当其值超过0.1时,准确率开始明显下降;采用加权求和的DSC-FER方法在λ值为0.3时,模型准确率达到最高,当其值小于0.3时,模型准确率不足,当其值大于0.3时,模型准确率开始下降。实验结果表明了平衡系数λ对DSC-FER分类效果有很大的影响,当λ值过小时,不能达到较好的提升效果,当λ值过大时,模型准确率下降,所以平衡系数λ的选择对DSC-FER方法至关重要。
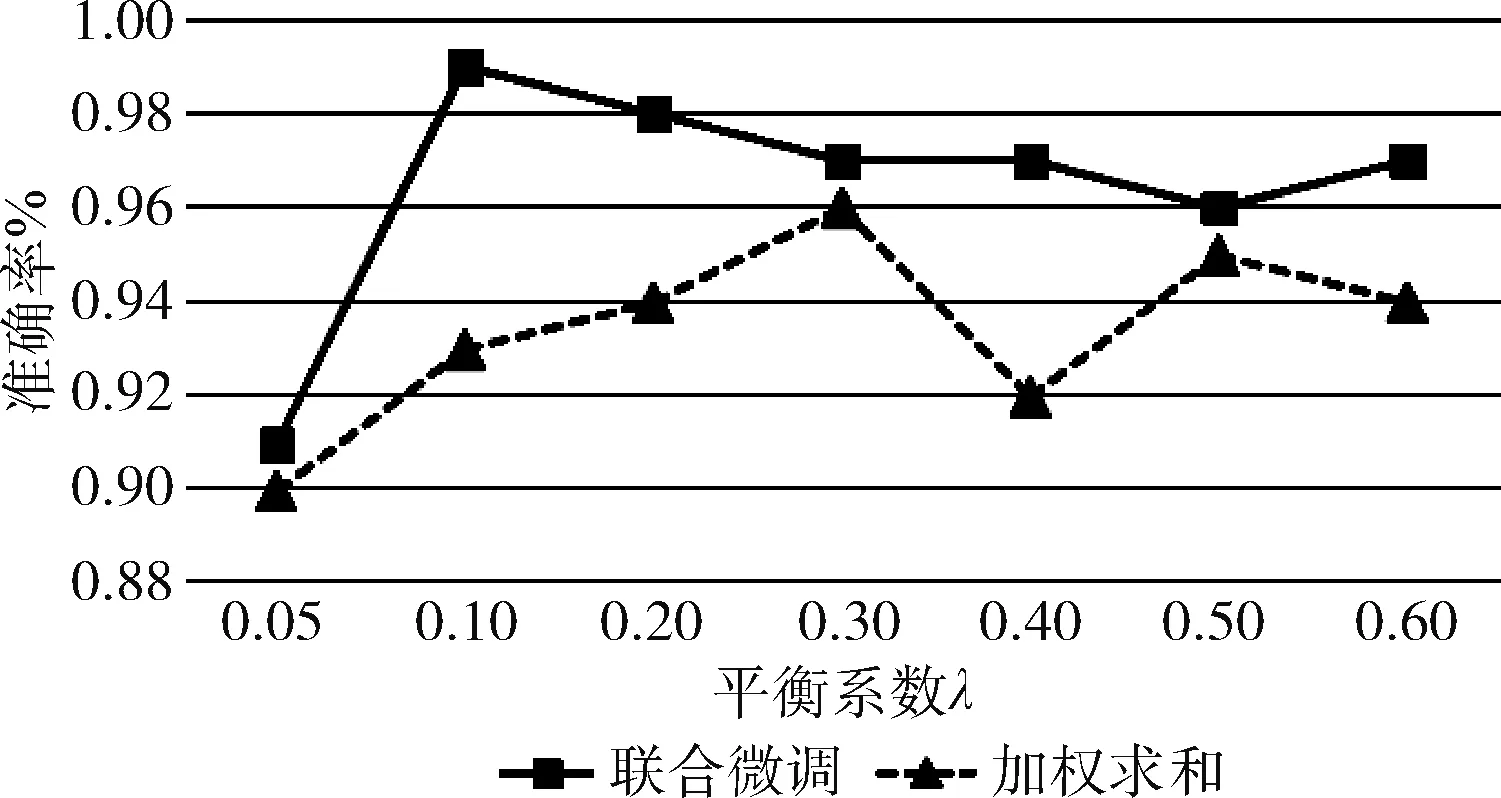
图5 平衡系数λ对DSC-FER分类效果的影响
4 结束语
人脸表情识别已经被众多领域广泛关注,但在实际应用环境下人脸表情很多是处于复杂环境下,从而导致表情识别泛化能力不足和识别精度问题。因此,本文利用人脸分割网络和模型融合方法来提高模型的识别率和泛化能力,进而提出一种基于深度可分离的人脸表情识别方法。通过构建一个基于U型全卷积网络的RROI网络,可以避免图像处于较小像素和复杂环境下利用特征点不能分割的情况,分割出与表情识别最相关的面部区域;通过结合深度可分卷积优点构建两个基分类网络,提升网络对表情识别率的同时保证模型的计算量与内存占用均为少量水平;其次通过联合微调方法融合后,最终在CK+、FER-2013和JAFFE数据集上识别率分别达98.98%、75.15%、97.14%,将这3个经典数据集与现有表情识别方法做实验对比,验证了DSC-FER方法的有效性;最后,本文对DSC-FER方法和加权求和方法中平衡系数λ进行研究分析,验证了选择适当的λ值对DSC-FER方法至关重要,联合微调方法比加权求和方法在DSC-FER方法中更有效。在接下来的研究中,考虑采集人脸数据的成本问题,将进行基于半监督学习或无监督学习的人脸表情识别。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
计算机工程(2020年3期)2020-03-19 12:24:50
电子制作(2019年11期)2019-07-04 00:34:38
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
动漫星空(2018年9期)2018-10-26 01:17:14
中国交通信息化(2018年3期)2018-06-13 03:27:58
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国交通信息化(2016年2期)2016-06-06 07:28:02
发明与创新(2015年33期)2015-02-27 10:40:09
