
基于改进DNN的糖尿病预测模型设计
2021-05-20 07:02:48林建君朱习军
计算机工程与设计 2021年5期
李 仪,林建君,朱习军
(青岛科技大学 信息科学技术学院,山东 青岛 266061)
0 引 言
近年来,许多研究者对糖尿病医疗数据进行了大量的研究,对于医疗结构化数据,使用了许多机器学习算法来构建预测模型[1,2]。传统的机器学习算法如K均值、决策树、SVM、贝叶斯算法等,都对糖尿病结构化数据进行了分析并构造了糖尿病预测模型,取得了较好的效果[3-5]。除了传统的算法外,研究者提出将深度学习应用于结构化医疗数据中,该研究者利用深度神经网络模型,构建了糖尿病分类模型,也取得了良好的分类效果[6-8],这表明深度学习技术在处理结构化医疗数据来预测疾病时的有效性。同时机器学习和深度学习的混合模型也逐渐得到应用。机器学习和深度学习的混合,结合了其技能和优势,可以有效辅助医生进行糖尿病预测诊断[9]。
利用深度学习进行结构化医疗数据研究的方法不多,CNN、RNN等深度学习模型适用于非结构化数据,本文采用深度神经网络(deep neural networks,DNN)对结构化数据进行研究,提出将深度神经网络与批归一化(batch normalization,BN)层相结合,利用改进的DNN模型结合机器学习技术,对结构化糖尿病数据进行分析,并对该模型进行评估。
1 数据预处理
本文使用UCI公开提供的皮马印第安人糖尿病数据集(PIMA indians diabetes data set,PIDD)进行实验,该数据集由美国国立糖尿病、消化和肾脏疾病研究所提供。PIDD数据集包含768个样本,有8个特征属性和1个标签属性,所有属性都是数值型数据,其中8个特征属性见表1。

表1 数据集特征属性
标签属性值为0和1,其中0代表未患有糖尿病,1代表患有糖尿病。通过统计分析,标签值为0的样本个数为500个,标签值为1的样本个数为268个,分布情况如图1所示。
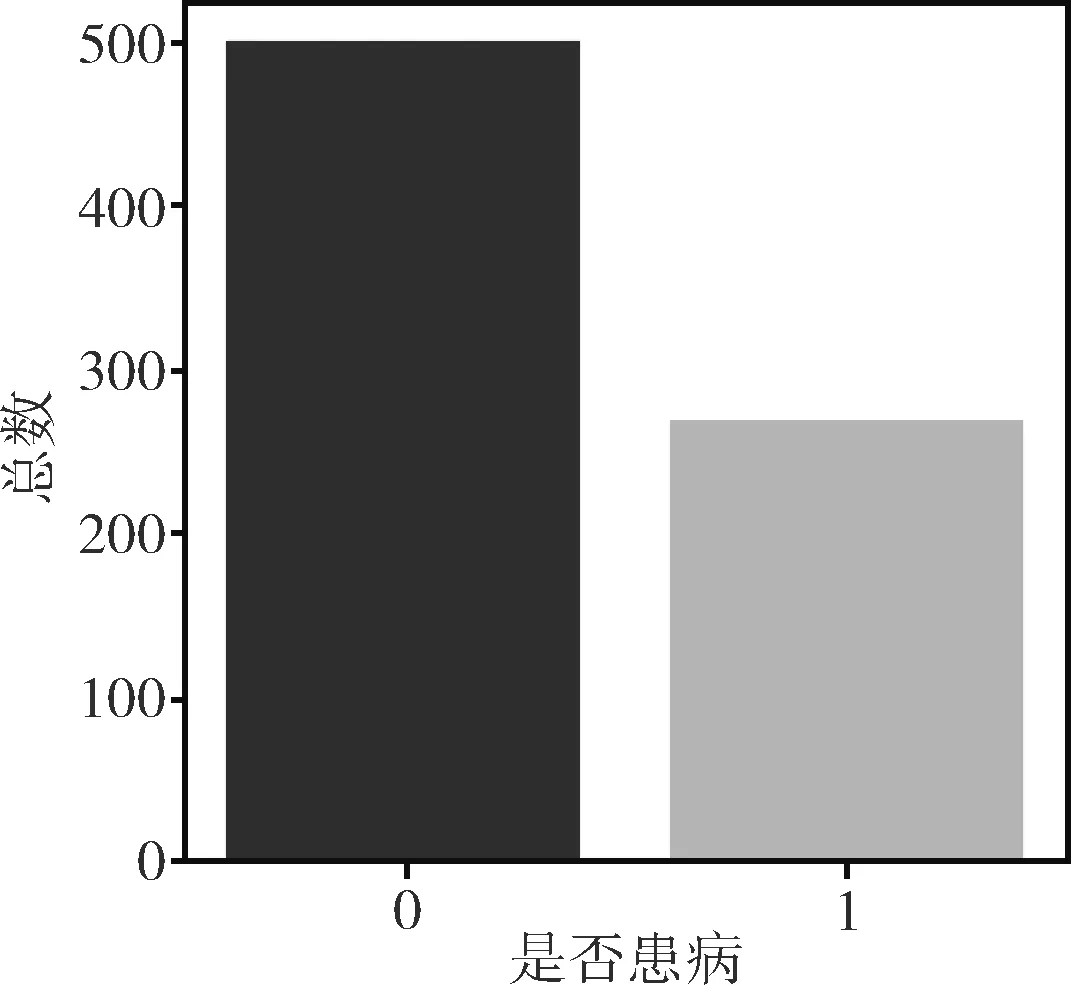
图1 数据集标签分布
本文对数据进行预处理主要包括两个方面:缺失值处理、数据标准化。
(1)缺失值处理常用方法包含删除法、插补法。删除法主要用于删除缺失数据,适用于样本数据量大的情况。插补法利用缺失值变量的均值、中位数或众数来填充变量中的缺失值。
PIDD数据集包含大量为零的数值,如舒张压为零、胰岛素含量为零、体重指数为零等,这些零值是没有意义的,需要进行缺失值处理。因为该数据集数据量不大,本文采用均值插补方法进行缺失值填充。将原始数据集分为糖尿病组和非糖尿病组,计算每组各属性的平均值,然后用各属性平均值代替其缺失值,同时对于异常值,也用平均值代替。将处理后的数据集合成一个新的数据集用于后续建模。
(2)数据标准化是将原始数据按比例缩放,使之落入特定区间,去除数据的单位限制,对其进行无量纲化处理,本文采用区间缩放法进行标准化,将不同属性列的数据转换为同一量纲,将数据映射到[0,1]区间上,常见的有min-max方法,可利用python sklearn模块中的StandardScaler()、MinMaxScaler()等函数进行计算,计算公式如下
(1)
其中,max是样本属性最大值,min是样本属性最小值。
2 特征选择
2.1 特征关联性分析
对数据集的特征进行处理,分析特征之间的关联程度,使用python pandas包中的corr函数计算特征之间的皮尔逊相关系数,相关系数趋向于1时,表明两者关联程度大;相关系数为0时,表明两者相互独立。通过热力图的形式展示各特征的关联情况,如图2所示。图中横轴和纵轴特征之间的颜色越浅表明特征之间相关系数越小,其关联程度越小;颜色越深表明特征之间相关系数越大,其关联程度越大。对图1进行分析可以得出,该数据集中大部分特征之间的相关程度较弱,说明大部分数据之间冗余较小。但是个别特征之间的颜色较深,如Age(年龄)和Pregnancies(怀孕次数),代表这两个特征之间相关程度较大,存在冗余。对于关联程度较强的特征需要进一步判断其对预测结果的贡献程度,再进行处理。
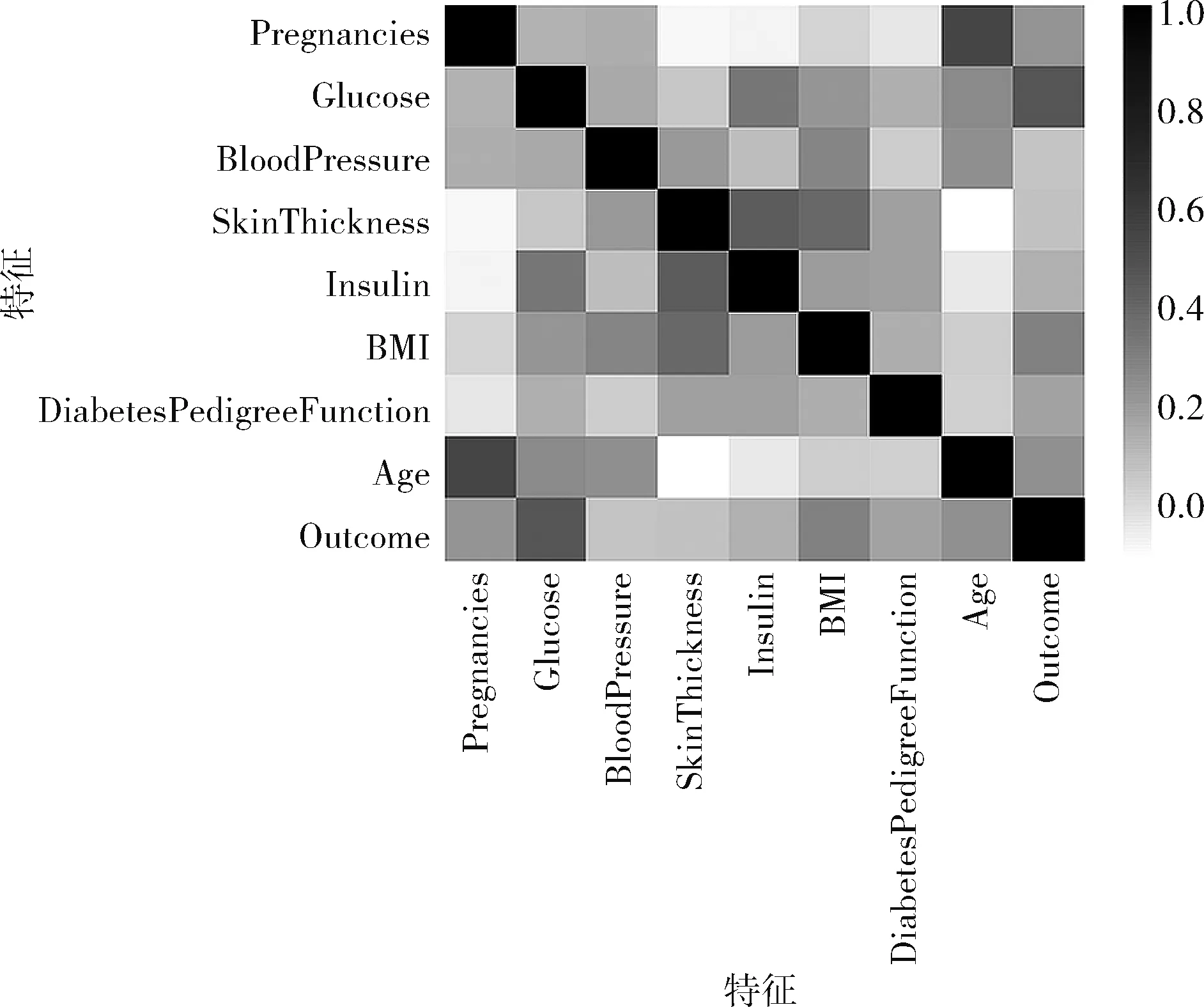
图2 特征关联性分析
2.2 特征选择算法
根据特征关联性分析,得到个别特征之间存在一定的冗余,说明数据集中有的特征对实验的实现没有作用,需要筛选出有用的特征。特征选择就是从数据集所有特征中除去冗余的特征,选择最优特征的过程。特征选择可以把高维数的特征转化为低维数的特征,经过处理后的特征作为模型的输入,可以提高模型的稳定性和准确率。
XGBoost算法是GBDT(gradient boosting decision tree)算法的改进,以CART树为组合,负梯度为学习策略的一种基于boost的集成学习算法。具有高效率、高准确率、高并发的优点,在分类、回归、特征选择等方面得到广泛应用。在特征选择方面,XGBoost算法可以通过计算特征的重要性对特征进行选择,特征重要性表示特征在构建提升树起的作用。如果一个特征在所有树中作为划分属性的次数越多,表明该特征越重要,由算法中评判特征重要程度指标weight表示。通过计算特征和预测结果之间的关联性,得到每个特征对预测结果的影响权重,以此得到每个特征的重要性,并对特征重要性进行排序[10,11]。
本文运用XGBoost算法对PIDD数据集中8个属性进行特征选择,输出每个特征对预测结果的影响程度,并输出影响程度的排名即特征重要性排名。实验结果如图3所示,通过图示可得Glucose(血糖值)、DiabetesPedigreeFunction(糖尿病谱系功能)、BMI(体重)、Age(年龄)、BloodPressure(舒张压)、SkinThickness(皮脂厚度)、Pregnancies(怀孕次数)、Insulin(胰岛素含量)对预测结果影响程度依次减小。本文实验选择得分最多的前五名,Glucose(血糖值)、DiabetesPedigreeFunction(糖尿病谱系功能)、BMI(体重)、Age(年龄)、BloodPressure(舒张压)为重要特征,组成特征子集用于模型的训练。
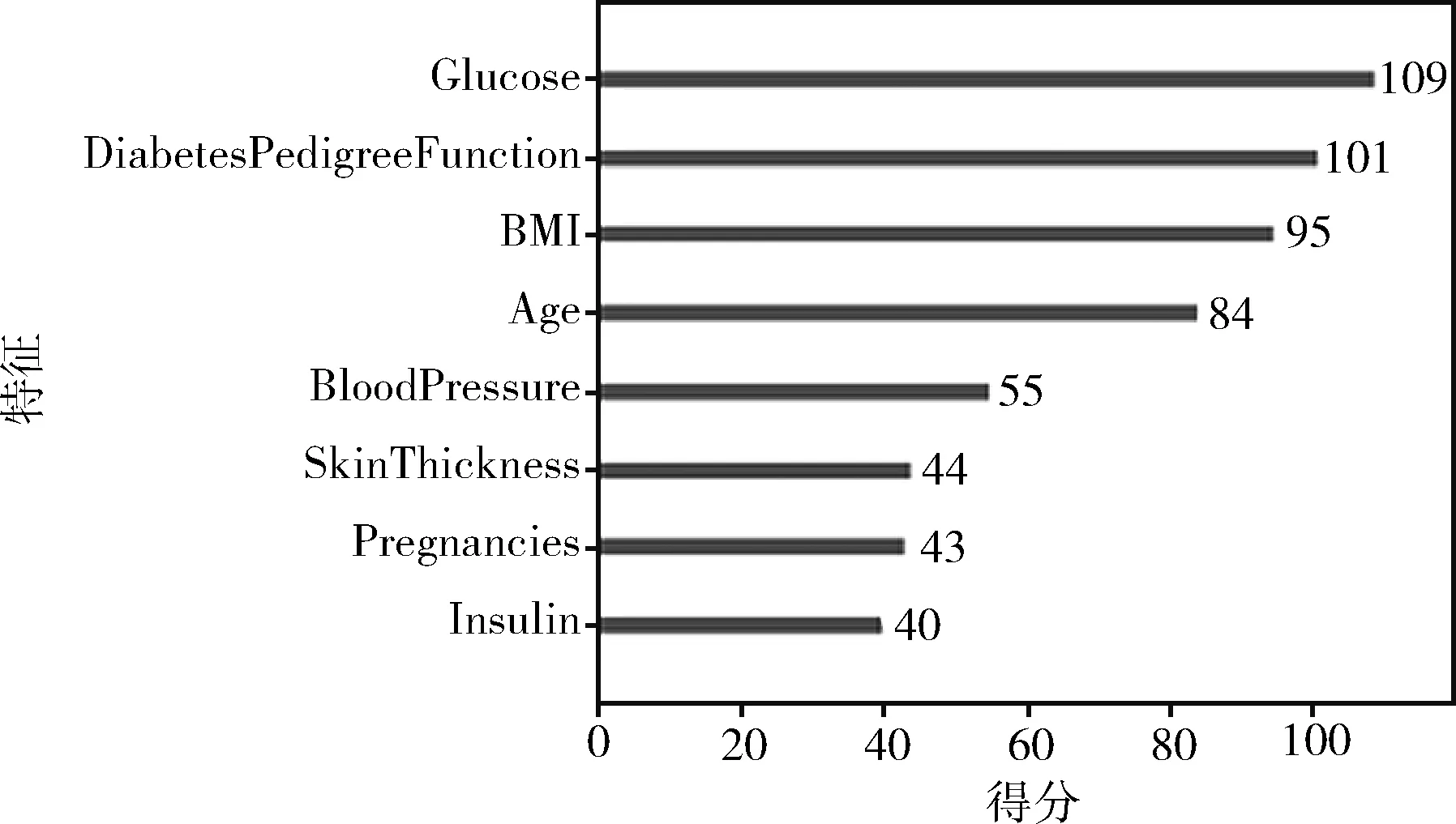
图3 特征影响程度排名
3 模型设计
3.1 模型体系结构
本文模型体系结构主要包括数据预处理、特征选择,搭建改进的DNN模型-BNDNN模型,并进行训练,将测试数据集输入训练好的模型用于预测,最后进行模型性能评估,模型体系结构如图4所示。

图4 模型体系结构
3.2 DNN网络结构
深度神经网络(deep neural networks,DNN)为包含多个隐藏层的神经网络,有时也叫多层感知机。感知机模型由若干个输入和一个输出组成,输入和输出之间为线性关系,如图5所示。
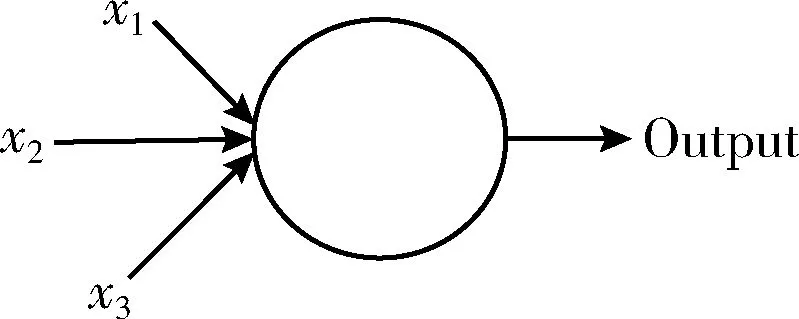
图5 感知机模型
计算得到中间输出结果
(2)
中间输出通过神经元激活函数,得到分类结果。感知机模型只能进行二元分类,无法用于复杂的非线性模型,因此神经网络在感知机模型基础上进行了扩展。增加隐藏层,增强了模型的计算能力,提高了模型的复杂度;增加输出层神经元个数,以此增加输出,可以应用于多分类、回归等问题;增加激活函数,如Sigmoid、tanx、softmax、ReLU函数等,不同的激活函数可以增强神经网络的表达能力。
DNN神经网络结构如图6所示,包含1个输入层、1个输出层和n个隐藏层,层与层之间神经元为全连接。DNN分为前向传播和反向传播。对数据进行预处理后,进行前向传播,将数据从输入层输入经过n个隐藏层得到计算结果最后传入输出层,利用输出层得到的结果与期望结果进行比较得到误差,反向传播通过梯度下降将误差从输出层经过隐藏层传入输入层,这一过程为一轮神经网络的训练[12]。
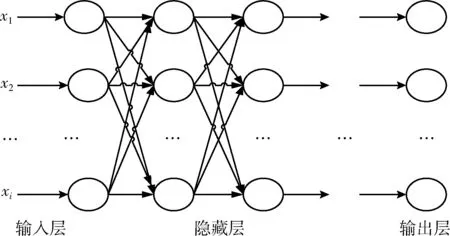
图6 DNN网络结构
3.3 批归一化
DNN的输入在进行非线性变换前,随着网络层数的增加,在训练过程中其分布会逐渐往非线性函数取值区间的上下限靠近,会导致梯度消失,优化函数越来越容易陷入局部最优解,这些问题的出现使得模型训练速度变慢,准确率降低。批归一化BN层在神经网络层中进行预处理操作,将每个神经网络层的输出结果进行归一化处理后再进入下一层,将每层神经网络的输入值分布重新拉回标准正态分布,使其落在激活函数的敏感区间。同时降低了对神经网络参数初始化的要求,增强了网络层之间的独立性,增大反向传播的梯度,因此可以有效地避免梯度消失等现象,与Dropout相同可以防止过拟合现象,加快了网络训练,提高模型的准确度[13]。BN算法流程如下所述:
输入:数据x1…xm
输出:(1)计算每一个训练批次数据的均值μβ
(3)
(4)
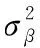
(5)
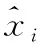
(6)
(5)数据完成批归一化操作后进入下一个网络层。
z=g(wx+b)
(7)
DNN引入BN层时,其作用于非线性激活函数之前,如式(8)所示
z=g(BN(wx+b))
(8)
3.4 Adam优化算法
Adam(adaptive moment estimation)算法通过计算梯度的一阶矩估计和二阶矩估计对不同参数学习率的取值进行调整,Adam算法是一种替代随机梯度下降的优化算法[14]。Adam的每一次迭代,学习率都被限制在一个大致的范围,使得参数平稳,解决学习率消失、稀疏梯度、噪声等问题。Adam算法更新公式如下
(9)

(10)
(11)
β1和β2为常数,mt为对梯度的一阶矩估计,vt为对梯度的二阶矩估计。mt、vt的更新如下,其中gt为一阶导
mt=β1×mt-1+(1-β1)×gt
(12)
(13)
3.5 L2正则化
若数据量较少、网络参数权重过大时,在网络训练过程中会存在训练过度产生过拟合现象,可以通过正则化方法对网络模型参数设定先验,防止模型过拟合。L2正则化方法为在损失函数中增加一个正则化项,对权重参数进行影响,如以下公式所示
(14)
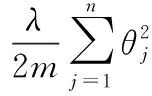
3.6 DNN模型的改进
为解决DNN网络模型易出现的局部最优解、梯度消失等现象,本文对普通DNN网络结构进行了改进,增加了BN层构建BNDNN模型,BNDNN网络结构如图7所示。该模型构造了5个全连接层,包含3个隐藏层,1个输入层,1个输出层。从输入层到输出层神经元个数分别为70、20、20、5、1,在输入层后和输出层前增加了BN层。本文采用的糖尿病数据集中每个特征均为数值型数据,经过数据预处理和特征选择后,形成6维的标准化数据集,将数据输入到BNDNN模型,其中输入数据为5维,代表数据集中的5个特征。数据从输入层经过全连接层进入BN层时,BN层经过计算使得数据重新分布在[0,1]之间,对数据进行变换重构,再传入下一层,提高了模型的准确率。

图7 BNDNN网络结构
训练网络模型,配置多个参数并进行优化:
(1)采用Adam优化算法,设置参数学习率为0.001。
(2)经过多次实验进行准确率对比,设置迭代次数参数Epoch为100次。
(3)隐藏层激活函数选择ReLU函数,输出层激活函数选择Sigmoid函数。
(4)增加Dropout层,使神经网络每次训练时随机忽略一部分神经元,这样会使神经网络对某个神经元的权重变化不敏感,增加了泛化能力,减少过拟合。Dropout参数默认值设为0.2。
(5)在dense层中添加正则项,L2参数设置为0.01。
4 实验结果与分析
本文对PIDD数据集进行缺失值处理,数据标准化等一系列数据预处理操作后,利用XGBoost算法进行特征选择,筛选出重要性比较高的5个特征属性,即Glucose(血糖值)、DiabetesPedigreeFunction(糖尿病谱系功能)、BMI(体重)、Age(年龄)、BloodPressure(舒张压),将其作为新的输入数据。采用Keras框架搭建BNDNN模型用于进行糖尿病预测。将数据集按照8∶2的比例分为训练集和测试集,训练集样本数为615,测试集样本数为153。通过对训练集进行交叉验证,并根据模型评价指标调整网络参数来训练网络模型,在测试集上评估训练好的模型准确率。
4.1 评价指标
使用交叉验证评估模型的泛化能力。K-fold交叉验证是将数据集分成K组,将K-1组子集作为训练集,剩下的子集作为测试集,进行K次训练和测试,将K次测试结果的平均值作为最终结果。
在医学诊断中,通常利用以下常用指标评估模型:
准确率(Accuracy):表示分类器做出正确预测的样本个数与样本总数的比率[15]
(15)
其中,TP为真阳性、TN为真阴性、FP为假阳性、FN为假阴性。如果数据集中样本标签为正,并且分类器预测这个样本标签也为正时,称其为真阳性;如果数据集中样本标签为负,预测也为负时,称其为真阴性;如果数据集中样本标签为正,但分类器预测为负,称其为假阴性;如果数据集中样本标签为负,分类器预测为正时,称其为假阳性。
灵敏度(Sensitivity)即召回率(recall):表示阳性病例正确分类为阳性与所有阳性病例的比率
(16)
特异度(Specificity):表示阴性病例正确分类为阴性与所有阴性病例的比率
(17)
精准率(Precision):表示阳性病例正确分类为阳性与所有预测为阳性病例的比率
(18)
F1值表示精确值和召回率的调和均值
(19)
ROC曲线:接受者操作特征曲线,纵坐标为灵敏度(Sensitivity),横坐标为特异度(Specificity),当曲线向坐标轴左上角靠近时表明模型准确度越高[16]。AUC表示ROC曲线下的面积,AUC值越大表明模型性能越稳定,利用这两个指标可以用来衡量模型的分类性能。
4.2 实验结果分析
本文利用10倍交叉验证对模型进行训练和评估,经过100次迭代测试集准确率基本稳定在80%左右,实验结果如图8所示,表明该模型对糖尿病的诊断预测是可行的。
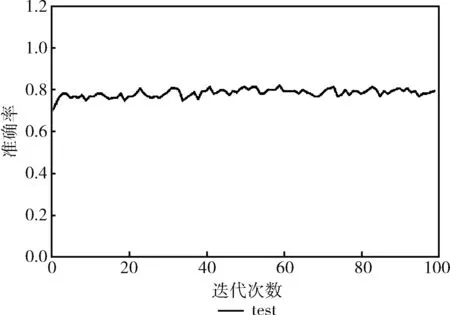
图8 预测结果
为了验证模型的有效性,将XGBoost-BNDNN模型与其它传统机器学习算法决策树(DT)、随机森林(RF)以及利用PCA进行特征选择的PCA-DNN模型和XGBoost-DNN模型进行对比,实验结果见表2。
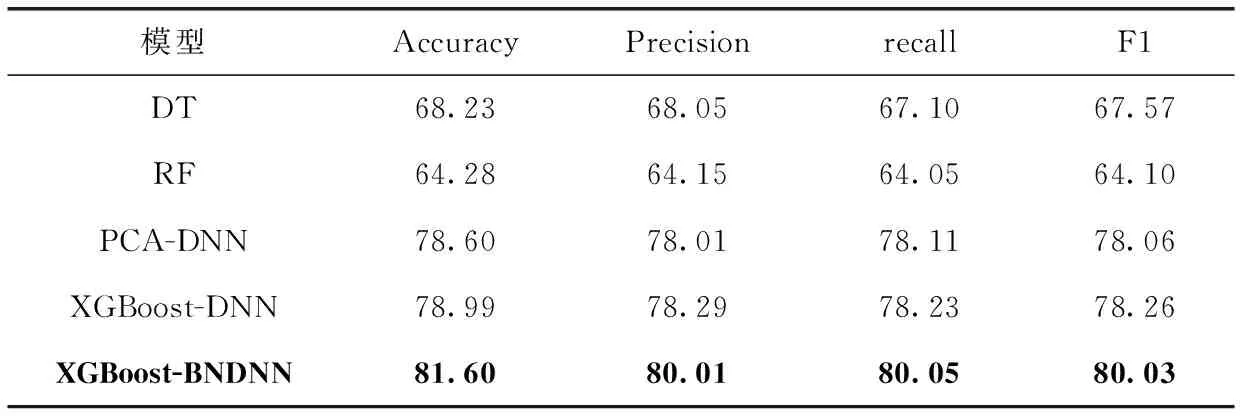
表2 不同模型分类准确率/%
从实验结果可以看出,在准确率方面,XGBoost-BNDNN模型准确率为81.60%,比DT提高了13.37%,比
RF提高了17.32%,比PCA-DNN模型提高了3%,比XGBoost-DNN模型提高了2.61%;在精准率方面,XGBoost-BNDNN模型精确率为80.01%,比DT提高了11.96%,比RF提高了15.86%,比PCA-DNN模型提高了2%,比XGBoost-DNN模型提高了1.72%;在召回率方面,XGBoost-DNN模型召回率为80.05%,比DT提高了12.95%,比RF提高了16%,比PCA-DNN模型提高了1.94%,比XGBoost-DNN模型提高了1.82%;在F1值方面,XGBoost-BNDNN模型F1值为80.03%,比DT提高了12.46%,比RF提高了15.93%,比PCA-DNN模型提高了1.97%,比XGBoost-DNN模型提高了1.77%。表明增加BN层对模型性能的提高是有效的。
为了更进一步对比不同模型的性能,对其进行ROC曲线比较,结果如图9所示。从图9可以看出,XGBoost-BNDNN模型的ROC曲线最靠近坐标轴左上方,ROC曲线下的面积最大,表明其AUC值最大,同时从表3可以得到验证,XGBoost-BNDNN模型AUC值为0.822,与其它模型相比值最大。表明该模型具有更好的预测效果,可以对糖尿病进行有效的预测来辅助医生进行诊断。
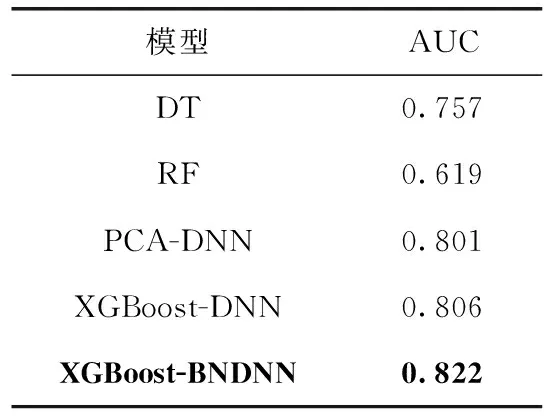
表3 不同模型AUC

图9 各个分类模型ROC曲线
5 结束语
本文围绕糖尿病预测问题,对糖尿病结构化数据进行处理,运用XGBoost算法进行特征选择,提出对DNN进行改进,构建XGBoost-BNDNN模型用于糖尿病的预测。该
模型在普通DNN网络结构上增加了BN层,可以有效防止梯度消失、训练速度慢等现象,提高模型准确率。增加Adam优化算法、Dropout层、L2正则化对BNDNN模型进行优化。通过10倍交叉验证以及各种评价指标评估该模型,验证了模型的优越性。由于本文使用的数据集数量少,特征维数低,不能保证该模型适应大数据、特征维数高的情况。针对这一问题,下一步将使用大数据集对模型进行优化,以取得更高的准确率。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年19期)2019-11-23 08:42:00
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子制作(2017年23期)2017-02-02 07:17:06
重型机械(2016年1期)2016-03-01 03:42:04
西北工业大学学报(2015年4期)2016-01-19 03:31:47
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
