
Rapid qualitative and quantitative analysis of strong aroma base liquor based on SPME-MS combined with chemometrics
2021-05-20 08:53ZongboSunJunkuiLiJinfengWuXioboZouChiTngHoLimingLingXiojingYnXunZhou
食品科学与人类健康(英文) 2021年3期
Zongbo Sun, Junkui Li, Jinfeng Wu, Xiobo Zou, Chi-Tng Ho,Liming Ling, Xiojing Yn, Xun Zhou,
a School of Food and Biological Engineering, Jiangsu University, Zhenjiang 212013, China
b Department of Food Science, Rutgers University, New Brunswick, New Jersey 08903, USA
c Jiangsu King’s Luck Brewery Co. Ltd., Lianshui 223411, China
Keywords:
SPME-MS
Strong aroma base liquor (SABL)
Chemometrics
Grade identification
Ester compounds
ABSTRACT
To objectively classify and evaluate the strong aroma base liquors (SABLs) of different grades, solid-phase microextraction-mass spectrometry (SPME-MS) combined with chemometrics were used. Results showed that SPME-MS combined with a back-propagation artificial neural network (BPANN) method yielded almost the same recognition performance compared to linear discriminant analysis (LDA) in distinguishing different grades of SABL, with 84% recognition rate for the test set. Partial least squares (PLS), successive projection algorithm partial least squares (SPA-PLS) model, and competitive adaptive reweighed samplingpartial least squares (CARS-PLS) were established for the prediction of the four esters in the SABL.CARS-PLS model showed a greater advantage in the quantitative analysis of ethyl acetate, ethyl butyrate,ethyl caproate, and ethyl lactate. These results corroborated the hypothesis that SPME-MS combined with chemometrics can effectively achieve an accurate determination of different grades of SABL and prediction performance of esters.
1. Introduction
There are many brands of liquors globally such as whisky, vodka and gin among others. Liquors in China are very different from others in terms of flavor and taste. Chinese liquors are generally made with grains as main raw materials using four processing method, namely,cooking, saccharification, fermentation and distillation. These liquors make up the sixth-largest distilled spirits, as it is embedded in the Chinese long history of ‘liquor culture’. Almost all the liquors are made by blending different base liquors. The base liquors are unblended and made directly from the distillation of fermented grains with 60%-70% alcohol concentration.
Strong aroma liquor (SAL) is one of the most important liquors cultivated in China, with the largest market share and the most consumed volume in China’s current liquor market. SAL belongs to a distilled liquor with their aroma compounds mainly composed of ethyl caproate. Moreover, this liquor is produced by using grains such as sorghum as the raw material, and processed by solid-state fermentation, storage and blending [1]. The grades of the SABL are mainly determined by following process. Firstly, the grade of the SABL preliminarily determined by experienced and skilled liquor workers during the distilling process as well as an evaluation based on preliminary grade identification. Secondly, different grades of SABL initially determined by workers are subjected to sensory analyses by professional panelists. During sensory evaluation,some SABLs which have a poor coordination or a peculiar smell are downgraded. The result of sensory evaluation, which is easily affected by subjective factors (experience, emotion, physiological conditions, and environmental factors) are full of uncertainty and limitation. Additionally, researchers have shown that the main aroma components in Chinese liquor are esters with a fruity aroma [2] that account for 60% of the total flavor components with a strong aroma.Ethyl caproate, ethyl lactate, ethyl acetate, and ethyl butyrate are the 4 main esters which play an important role in forming the characteristic flavor of strong aroma liquor. The content of the 4 esters need to meet relevant standards in different grades of SABL [3,4].
In addition to the sensory evaluation being used for liquor classification of different grades and quality assessment, fluorescence spectra combined with simulated annealing algorithm are used for the prediction of mild aroma Chinese liquors. Yin et al. [5] have applied an electronic nose in the spirit classification. Near-infrared spectroscopy and ensemble classification have also been exploited for discrimination between authentic and adulterated liquors [6]. Although the above classification methods are considered to be faster, their poor stability, weak reproducibility and cross interference have limited their accuracy and broad application. Ester content can be generally detected by gas chromatography (GC) method. Notwithstanding,the GC method is tedious, time-consuming, and cannot achieve realtime and rapid detection. Therefore, it is necessary to establish a fast,accurate and stable classification and ester content determination method for the grade evaluation of SABL.
A non-separative mass spectrometry (MS) method, based on a direct combination of the mass spectrometer and solid-phase microextraction (SPME) has been developed [7]. In the non-separative MS method, the chromatographic column of the gas chromatographymass spectrometry (GC-MS) instrument is replaced by a fused silica tube. The volatile portion of the sample is immediately desorbed at the injection port at a high temperature and subsequently injected into the ionization chamber without a chromatographic separation[8]. In spite of the limit from the poor volatility and high polarity of target analytes due to a poor partition and reduced recovery into the gas phase [9], SPME has unique advantages of a solvent-free, easy to operate and high reproducibility [10,11]. The use of solid-phase microextraction-mass spectrometry (SPME-MS) has become an effective and rapid detection technique [12-14]. In particular, SPMEMS coupled with one or more chemometrics is widely used in the food industry and has tremendous potential for classification and identification according to quality grades [15-18], geographical origin[19,20], pesticide residue [21], raw materials species [22] and others[23-25]. It has been applied for the quantification of benzoic acid in beverages for many years [27].
Selecting the most appropriate method from a plethora of chemometrics techniques is very important. The method of principal component analysis (PCA), can eliminate unimportant data resulting in a dimensionality reduction. PCA is applied in the first stage of data processing to extract principal components (PCs), which are used for sample analyses and group visualization. Nevertheless, precise clustering in PCA cannot be provided [28,29]. In qualitative analysis,linear discriminant analysis (LDA), a supervised pattern recognition method is used to provide clustering information. The back propagation artificial neural network (BPANN) method is a multilayer forward feedback neural network used for prediction. In quantitative analysis, partial least squares (PLS), successive projection algorithmpartial least squares (SPA-PLS), and competitive adaptive reweighed sampling-partial least squares (CARS-PLS) can reduce time and effort in model calculation thus effectively improve the precision of the model.
This study aimed to utilize the HS-SPME-MS method combined with multivariate analysis to discriminate grade quality and predict the ester content of SABL. The research goals were focused on 5 key points: (1) to obtain the ion intensity of SABL samples via HSSPME-MS technology; (2) to screen out irrelevant information using PCA, develop LDA and BPANN models, compare the two models and find out the optimal model for discriminating grade quality of SABL; (3) to obtain the true value of esters including ethyl caproate,ethyl lactate, ethyl acetate and ethyl butyrate by GC, combine the ion intensity of SABL samples with the true value of esters to build PLS model, analyze and predict performance; (4) to select optimal feature ions according to SPA and CARS, and used to develop esters prediction model; and (5) to compare the prediction performance of PLS, SPA-PLS, CARS-PLS models built by different ion selection methods and find out the optimal ions election method and model for predicting ester profiles in the SABL.
2. Materials and methods
2.1 Samples and chemicals
Seventy-five SABL samples were collected from different production workshops of King’s Luck in the Huaian City of Jiangsu Province with about 70% ethanol content. All samples were stored at room temperature and the analysis conducted within 15 days after sample collection. Standards of ethyl acetate, ethyl butyrate, ethyl caproate, ethyl lactate and amyl acetate (internal standard) with 99.5%purity were purchased from Tianjin Guangfu Fine Chemical Research Institute (Tianjin, China).
2.2 Grade identification of SABL
The employees with experience in the process separated the SABL into 3 grades as it was produced: G1 (best), G2 (middle), G3(worse). Then, the expert assessors evaluated G1 and G2 according to its coordination, aroma, and peculiar smell. In G1 and G2, some unqualified SABL samples with poor coordination or a peculiar smell were downgraded. Each round of 6 samples was evaluated by 3 expert assessors that were selected randomly from 10 expert assessors.
2.3 GC analysis
The content of esters was measured in a GC (7890A, Agilent,Santa Clara, CA, USA) with a flame ionization detector (FID). The carrier gas was nitrogen with a flow rate of 2.0 mL/min. A total of 1 μL sample was injected in the split mode (1:40) into a CP-Wax 57CB column (50 m × 0.25 mm i.d., 0.2 μm film thickness, Varian, CA,USA). The programmed temperature was 35 °C for 3 min, increased to 90 °C at 4 °C/min, then amplified to 130 °C at 10 °C/min, finally ramped to 210 °C at 15 °C/min and held for 10 min. Injector and detector temperatures were 200 °C and 210 °C, respectively.
2.4 SPME-MS analysis
The SPME fiber (2 cm, 50/30 μm DVB/CAR/PDMS) was purchased from Sigma (St. Louis, MO, USA). Before using, the fiber was placed in GC injector port at a temperature of 270 °C to eliminate any probable contaminants.
The SPME was carried out according to the following procedures.SABL (1 mL), 4 mL of distilled water and 2 g NaCl were placed in a 15 mL vial and tightly capped with a silica gel pad. Then the vial was placed on a magnetic stirrer (Corning, NY, USA) at 50 °C for 5 min and extracted for 20 min by the extraction fiber at the same temperature. After the extraction, the fiber was inserted into the inlet of GC and the components were desorbed for 5 min at 250 °C in the splitless mode.
The SPME-MS was carried out using an GC (6890N, Agilent,USA) equipped with an MS detector (5973, Agilent, USA). A fused silica capillary column without a coating (1 m × 0.15 mm i.d, Agilent Technologies Inc., Shanghai, China) that replaced the capillary chromatographic column was inserted directly to MS. Helium (He) was chosen as the carrier gas at a constant flow rate (0.4 mL/min). The oven temperature was set to 200 °C to prevent the volatile components from recondensation and maintained for 5 min. The spectrometer operated in electron impact (EI) mode (70 eV). The ion source temperature was 230 °C, and the interface temperature was 250 °C. Detection was carried out in scan mode in a range ofm/z33-400.
2.5 Chemometric analysis
All the data processing and analysis were performed using MATLAB R2009a software. PCA was used as the first step of data analysis to visualize information and to detect patterns in data whereas LDA was used to calculate classification rules for sample discrimination. Also, BPANN was used to predict the SABL classification. Besides, PLS, SPA-PLS, and CARS-PLS were used to reduce the amount of calculation and improve the precision of the model in the quantitative analysis. Each data set was randomly divided into a training set (used to calculate the classification rules for two-thirds of the samples) and a test set (used to evaluate the prediction ability of rules and models for one-third of the samples).
3. Results and discussion
The SPME-MS method employed only MS to collect data within a few minutes to obtain the ion abundance. Then, an average mass spectrum (Fig. 1) including the abundance of allm/zof 33-400 ions were generated by HP-ChemStation system. Almost all the average mass spectrum had similarm/zions. For example,m/z45 ion was a base peak which is a characteristic of ethanol, andm/z88 ion can be ascribed to ethyl esters. Ethyl esters have a fruity aroma and it is of great importance in the quality assessment of liquors. Meanwhile,ethyl caproate, ethyl lactate, ethyl acetate and ethyl butyrate are the main esters for strong aroma liquor and were analyzed quantitatively by GC with n-amyl acetate as the internal standard. Firstly, these esters were identified by their respective retention times (RT) based on a mixture of their standards, and the concentration ranges of these four esters’ are shown in Table 1. The standard curve was calculated by concentration (X) of esters as theX-axis and the peak area ratio (Y)of the esters to the internal standard asY-axis. Table 1 showed thatXandYhad a linear relationship with a correlation coefficient greater than 0.999 6. Finally, the ester content was calculated according to the standard curve.
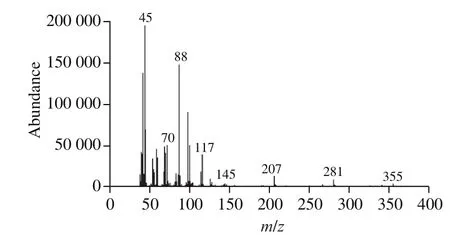
Fig. 1 The average mass spectrum in the range of m/z 33-400 of the SABL generated by SPME-MS.

Table 1Concentration range, retention times, standard curves and correlation coefficients of esters.
3.1 Qualitative analysis of different grades of SABL
The samples were divided into G1 (32 samples), G2 (24 samples),and G3 (19 samples). In G1 samples, 10 good samples (GG1) not only had a pure rich aroma and no peculiar smell but also tasted sweet and fragrant. However, 22 bad samples of G1 (BG1) had a bad smell(bitter, astringent, burnt, and other unacceptable smells).
For G2 samples, 10 good samples (GG2) had a rich aroma,elegant and lasting and no off-smell and 14 bad samples (BG2) had also recorded an off-smell. Therefore, a total of 5 grades, GG1, BG1,GG2, BG2, and G3 were evaluated.
It was difficult to intuitively differentiate various grades of the SABL according to the average mass spectrum although the ion abundance of every grade from the average mass spectrum was subtly different. To classify and evaluate the SABL of different grades objectively, the PCA method was applied in the first stage of data processing. This was followed by the LDA and BPANN model to identify the grade of SABL. From the average mass spectrum, the 75 samples were listed as rows and 368 ion abundance as columns,thus a 75 × 368 data matrix was generated while 50 samples for the training set and 25 samples for the test set were submitted to establish the model.
PCA is one of the most frequently used chemometric methods and it is applied in the first stage of data processing. It works by replacing a large number of potentially correlated variables with a new linear set of fewer uncorrelated variables, namely PCs, which represent the majority of the original data. These new variables permit the construction of a multivariate model where it is possible to extract useful information from the original mass spectrum data by eliminating overlapping information [30]. Hence, PCA was implemented to determine the particular grade within the 5 grades of the SABL in this study.
The PCA results (Fig. 2) could broadly reflect the distribution of the 5 grades of the SABL samples in the original variable space.Fig. 2 showed clearly a three-dimensional (3D) space of the SABL samples represented by PC1, PC2, and PC3. PC1, PC2 and PC3 showed 50.43%,18.29% and 10.96% of the variance, respectively.Segregation was observed only in the G3 samples but overlapping appeared in other grades. This might be duo to the G3 samples having some different qualities compared with the other grades. Therefore,PCA cannot de fine the boundaries of the other grades or used directly as a tool for determining the grade of the SABL sample unless the grade of the sample is in G3.

Fig. 2 3-Dimension score plot of five grades of the SABL after PCA.
To improve the classification of investigated samples, LDA which is probably the most frequently used technique was carried out to obtain a suitable classification of the SABL of various grades. LDA is a supervised classification technique based on the determination of linear discriminant functions which maximize the ratio of betweenclass variance and minimize the ratio of within-class variance [31].
It was essential to use a PCA to determine a reduced-dimension of the mass spectrum data to extract optimal PCs as the input variable of the LDA identification model. The reduced-dimension data not only held enough of the original information but also achieved the compression of a certain amount of the original data which was available for subsequent processing. In Fig. 3A, the result of the training set and test set of different grades of the SABL based on SPME-MS analysis showed that the number of PCs affected the results of the training set and the test set in LDA. When the number of PCs was less than 7, the recognition rate of the model was not stable.As the number of PCs reached 7, the established LDA model obtained the best effect on the classification of SABL with discrimination rate of 86% for the training set and 84% rate for the test set. Besides, the minimal gap of the rate between training set and test set demonstrated good versatility of the LDA model with the principal component of 7.Although the prediction effect of the model was improved when the principal component is 15 compared to when the principal component is 7, it will increase the amount of data calculation and have the great possibility to cause over fitting. Additionally, from the 2-dimension score plot of 5 grades of the SABL after Fisher- LDA in Fig. 3B, the contribution rate of the first discriminant factor (LD1) and the second discriminant factor (LD2) were 88.98% and 9.82% respectively, and the cumulative contribution rate reached 98.80%. Samples of G3 were separated from all other samples. Additionally, discrimination between good samples and bad samples in the same grade was also satisfactory. Yet, LDA could not de fine the boundaries of the samples of GG1 and GG2 due to the existence of overlapping portions. In general, the proposed method improved the recognition performance of SABLs’ recognition performance.

Fig. 3 (A) Discriminant result of LDA of the training and test set in the different PCs; (B) 2-Dimension score plot offive grades of the SABL after Fisher- LDA.
BPANN, a familiar neural network model, is capable of dealing with many complex problems including nonlinear problems. BP is a commonly used learning algorithm in ANN applications, which uses the back-propagation algorithm as the gradient descent technique to minimize network error [32]. A neural network composes of an input layer, one or more hidden layers, and an output layer. Each layer in the BPANN has several neurons and each neuron transmits input values and processes to the next layer [33]. The number of neurons in the hidden layer could affect the error and convergence rate of the network to some extent. Similarly, the number of PCs also had a direct impact on the prediction performance of the model. Moreover, BPANN parameters such as the learning rate factor, the momentum factor, the target error and iteration times also have some influence on the performance of BPANN model. Therefore, it is crucial to optimize factors.
The optimal BPANN model was achieved when the learning rate factor was set to 0.1, momentum factor at 0.7, target error from 10-8,and iteration times selected as 1 000. Table 2 shows the result of the training set and test set performed by BPANN using different numbers of PCs. As observed, when the number of PCs was increasing, the recognition rate of the training set and the test set always fluctuated.Compared to other BPANN results, better recognition performance was witnessed when the number of PCs and neurons were 4. Under those conditions, the recognition rate of the training set and the test set obtained 90% and 84% respectively. Hence, SPME-MS combined with the BPANN method yielded almost the same recognition performance compared to LDA in distinguishing different grades of SABL, with 84% recognition rate for the test set.

Table 2Discriminant result of BPANN in the training set and test set under different PCs.
3.2 Quantitative analysis of ester content
The content of 4 esters (ethyl acetate, ethyl butyrate, ethyl caproate, and ethyl lactate) needs to meet corresponding GRADE criteria in different grades SABL. Therefore, a quick and accurate determination of the 4 esters plays a critical role in the grading of SABL. Table 3 showed the reference value of the ester content.The concentration range of these ester compounds was wide.This corroborates its high representativeness and could be used to establish a model.

Table 3Reference values of esters of SABL samples in the training and test set.
PLS is a well-known multivariate calibration method based on factor analysis and mostly used for multivariate analysis methods in quantitative analysis. It not only maps the original dependent variable data into a few latent variables whose information is very focused but also selects the latent variables which are greatly correlated with the dependent variables as the principal component variables to establish the model [34,35]. SPA can minimize the collinearity among variables and largely reduce the number of variables. By comparing the magnitude of the projected vector between different wavelengths,SPA takes the wavelength with the largest projection vector as the candidate wavelength and uses the robustness of the training model to determine the final characteristic wavelength. CARS, a feature wavelength selection method is based on Monte Carlo (MC) sampling and PLS regression coefficient [36,37]. CARS first establishes the corresponding PLS model through the sample of calibration set selected by MC sampling, establishes the absolute weight of the wavelength regression coefficient in this sampling, and removes the wavelength variable with smaller absolute value, The number of removed wavelength variable is then determined by exponential decrease function (EDF). Based on the remaining wavelength variables, the PLS model is established by selecting the wavelength using adaptive reweighted sampling (ARS). The corresponding wavelength of the PLS model with the smallest RMSECV is the selected characteristic wavelength of the PLS model [38].
The best models are chosen based on the lowest root mean square error of cross-validation (RMSECV), the lowest root mean square error of prediction (RMSEP), and the highest correlation coefficients for the calibration data set (Rc) as well as the prediction data set(Rp). RMSECV is mainly used for the evaluation of feasibility and the predictive ability of the PLS, SPA-PLS, and CARS-PLS model.RMSEP is mainly used to evaluate the prediction ability of the model to the external sample. The size ofRshows the correlation between the predicted value and the measured value [39].
The PLS, SPA-PLS, and CARS-PLS models were established for 4 ester compounds of different grades of the SABL. This study takes ethyl acetate as an example to analyze the established model.
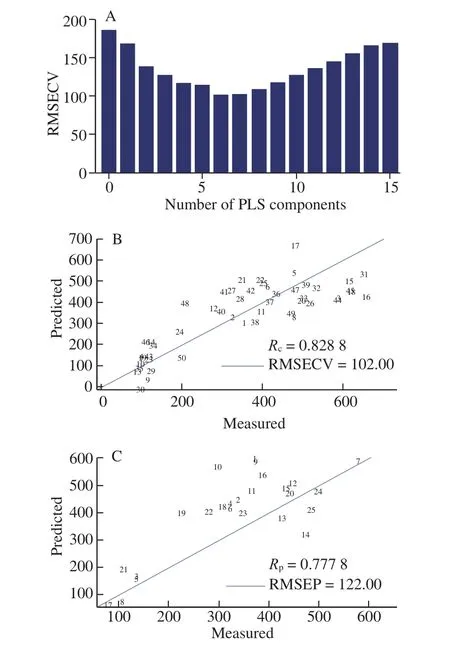
Fig. 4 Prediction results of the PLS model for ethyl acetate content. (A)Selection of optimum PCs. (B) Results of training set of PLS model based on full variables. (C) Results of test set of PLS model based on full variables.
In the process of establishing the PLS model using full variables,two-thirds of the SABL samples were randomly selected as a training set and the other one-third of the trials were used as a test set. Fig. 4 demonstrated that the established PLS model yielded the best predictions, under the condition of utilizing the first 6 principal components by obtainingRc(0.828 8),Rp(0.777 8), RMSECV(102.00), and RMSEP (122.00). TheRcandRpgenerated by the PLS model established by full variables were less than 0.9, which demonstrated the ineffectiveness of the model in the prediction of the ethyl acetate in the SABL. This may be due to the existence of many ionic variables that are not related to ethyl acetate content which resulted in the degradation of prediction performance and screening of characteristic variables appeared to be a feasible strategy to solve this problem.
The range of the number of characteristic variables was set to 1-18 when using SPA to select characteristic variables that were determined by the root mean square error (RMSE). The selection result is shown in Fig. 5A. When the number of variables was 13, the obtained RMSE value was the smallest. The 13 variables selected by SPA were used to develop the PLS model. Fig. 5B-5D illustrated that the established SPA-PLS model yielded the best predictions under the condition of utilizing 9 principal components by achieving Rc(0.848 4),Rp(0.803 2), RMSECV (96.90), and RMSEP (110.00). Compared to the PLS model, SPA-PLS obtained a higher Rcand Rp.
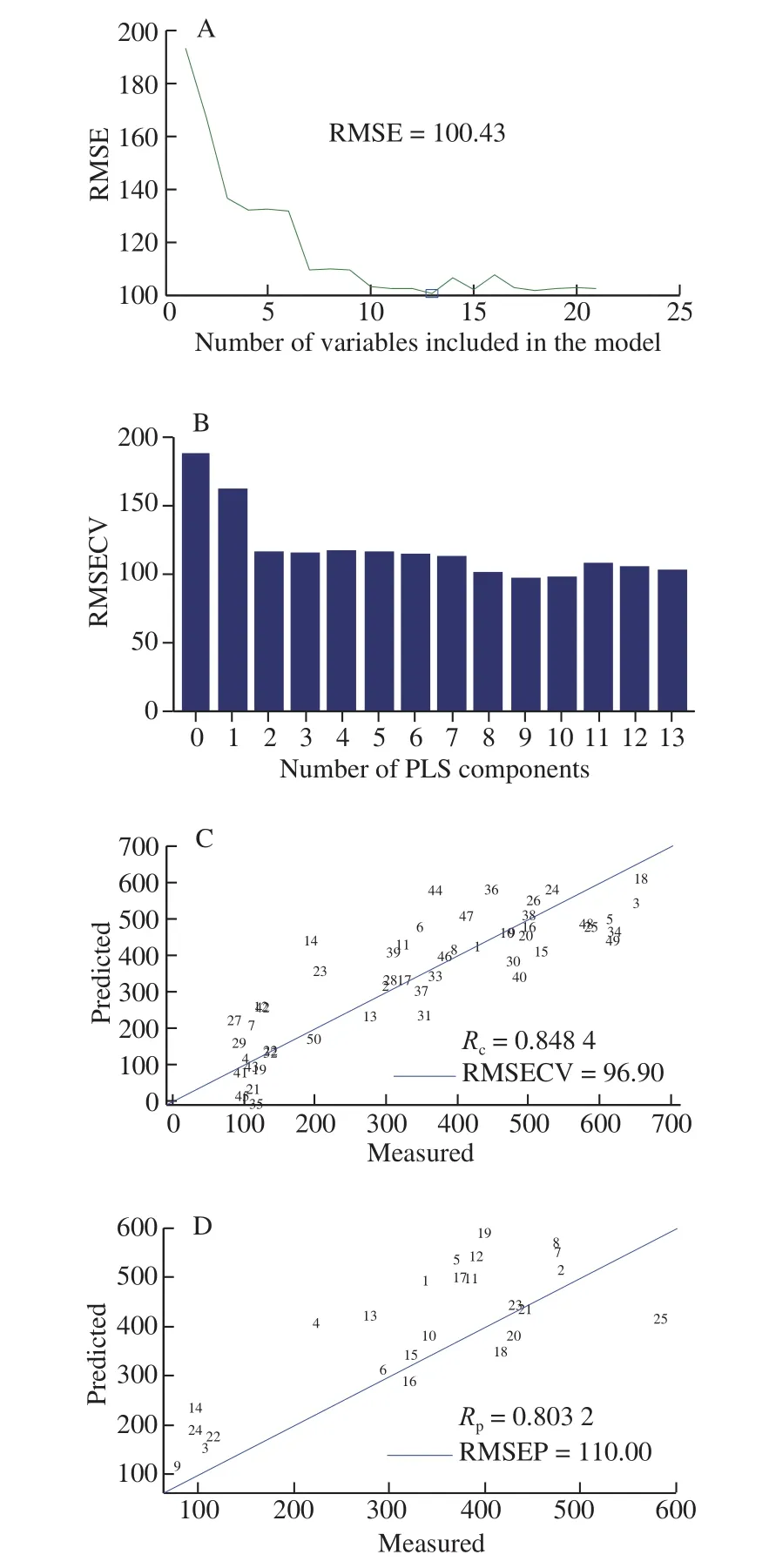
Fig. 5 Prediction results of SPA-PLS model for ethyl acetate content. (A)Process of screening characteristic variables by SPA. (B) Selection of optimum PCs. (C) Results of training set of PLS model based on SPA. (D) Results of test set of PLS model based on SPA.

Fig. 6 Prediction results of CARS-PLS model for ethyl acetate content.(A) Process of screening characteristic variables by CARS. (B) Selection of optimum PCs. (C) Results of training set of PLS model based on CARS. (D)Results of test set of PLS model based on CARS.
As shown in Fig. 6A1, A2, A3, after sampling the MC (19 times), 35 optimal variables were screened out to establish the PLS model. As shown in Fig. 6B, with the growth of number of PLS components, RMSECV changed in a ‘V’ shape and finally achieved the minimum value when PLS components were 7 and the established CARS-PLS model yielded the best predictions with the RMSECV (51.50) of the training set,Rcof 0.956 3,RMSEP of 52.90 for the test set, andRpof 0.937 0 in the test set under this condition, which showed in Fig. 6C, 6D. Compared to PLS and SPA-PLS model, CARS-PLS shown greater probability of models to predict ethyl acetate in SABL. In addition, 30 PLS models developed by randomly selected sample set which have the same characteristic variables asm/z36, 41, 50, 53, 54, 57, 61, 76, 81, 85, 90, 100, 103,112, 114, 115, 116, 118, 129, 133, 134, 150, 151, 173, 186, 189, 191,197, 251, 255, 264, 283, 285, 341 and 342. Statistical analysis showed that the averageRcof 0.955 8, andRpof 0.928 6 and RMSECV of 50.75, RMSEP of 63.38, which may convey an important message that the PLS model developed by characteristic variables selected from CARS possess excellent stability and high fitting performance.
The prediction results from the model developed by PLS, SPAPLS, and CARS-PLS in ethyl butyrate, ethyl caproate, and ethyl lactate are shown in Table 4. CARS-PLS possessed the best prediction result amongst these 4 esters followed by SPA-PLS except ethyl lactate. After variable selection, the CARS-PLS model displayed elevation prediction performance while SPA-PLS showed degradation compared to the PLS model built with full variables in ethyl lactate.This may indicate that the SPA removed some variables related to the content of ethyl lactate in the process of variable selection. This inference was also attested by the phenomenon that, the characteristic variables selected by CARS are significantly higher than by SPA in screening the results of the characteristic variables of the other three esters. Besides, it is worth noting that PLS model combined with CARS showed the lowest RMSECV and RMSEP compared with PLS and SPA-PLS, which demonstrated that the model established by the variables extracted by CARS is closer to the true value of the predicted value of the ester content in the base liquor. Therefore, CARS as a variable screening method can be well applied to the establishment of a prediction model for the characteristic ester content of SABL.

Table 4The optimal model of the four ester compounds.
4. Conclusion
The SPME-MS technique combined with chemometrics resulted in high classification accuracy for the SABL from 5 different sensory grades. The results indicated that SPME-MS combined with the BPANN method yielded almost the same recognition performance juxtaposed to linear discriminant analysis (LDA) in distinguishing different grades of SABL with 84% of the recognition rate of the test set.Additionally, it was found that the CARS-PLS model showed a greater advantage in the quantitative analysis of ethyl acetate, ethyl butyrate,ethyl caproate, and ethyl lactate compared to PLS and SPA-PLS model.
Therefore, by overcoming the complex and time-consuming problems of the traditional detection technique, SPME-MS technology combined with chemometrics successfully demonstrated as a tool for distinguishing the quality of different grades of the SABL and quantitative analysis of four main ester compounds.
conflict of interest
The authors declare no conflict of interest.
Acknowledgments
The study was supported by the Key Research and Development Program of Jiangsu Province (BE2020312), National Natural Science Foundation of China (31671844), Open Project of National Engineering Laboratory for Agri-product Quality Traceability (AQT-2019-YB7), Science Foundation for Postdoctoral in Jiangsu Province(1501100C), Priority Academic Program Development of Jiangsu Higher Education Institutions (PAPD).

- 食品科学与人类健康(英文)的其它文章
- Moringa oleifera Lam. leaf extract mitigates carbon tetrachloride-mediated hepatic inflammation and apoptosis via targeting oxidative stress and toll-like receptor 4/nuclear factor kappa B pathway in mice
- Potential of peptides and phytochemicals in attenuating different phases of islet amyloid polypeptide fibrillation for type 2 diabetes management
- Zein as a structural protein in gluten-free systems: an overview
- Spectrum-effect relationship of immunologic activity of Ganoderma lucidum by UPLC-MS/MS and component knock-out method
- A red pomegranate fruit extract-based formula ameliorates anxiety/depression-like behaviors via enhancing serotonin (5-HT) synthesis in C57BL/6 male mice
- Purification, characterization and hypoglycemic activity of glycoproteins obtained from pea (Pisum sativum L.)