
基于多维度特征的Android 恶意软件检测方法*
2021-05-20 12:07徐玄骥张智斌
通信技术 2021年5期
徐玄骥,张智斌
(昆明理工大学,云南 昆明 650500)
0 引言
Android 操作系统是使用人数最多的移动操作系统。统计信息显示,截至2020 年12 月,Google Play 共有超过350 万款应用可供下载,每月平均下载人次超过500 万。然而,广阔的使用场景也为恶意软件发展提供了温床。另有统计显示,2020 年1—3 月间,共发现Android 恶意软件超过48 万款,其中木马为最主要的类型。种种数据都表明,恶意软件检测是一个重要的亟待解决的问题。然而,随着时间的推移,Android 恶意软件也展现出了更强的伪装性,传统检测手段是否奏效存疑。
本文针对上述提到的问题,提出了一套基于多维度特征的Android 恶意软件检测方法。通过反编译Android 应用程序、抽取权限、使用应用程序编程接口(Application Programming Interface,API)、网络证书时效性、代码混淆程度等不同特征并将其组成向量,之后使用随机森林与支持向量机算法训练分类器,来实现对Android 恶意代码的自动化识别。
目前,关于Android 恶意代码检测的文献较多,主要思路可归结为基于权限与特征API、基于程序控制流与数据流以及基于动态行为分析3 种。文献[1]考虑了不同权限之间的组合与恶意代码的关系,提出了一种基于随机森林的静态恶意代码检测方法。代码控制流信息也常常被用来进行恶意代码检测。文献[2]提出了一种Dalvik 字节码插桩方案,通过对控制流的监控实现对应用恶意行为的识别。相比于静态分析,动态分析对软件的运行状态有更强的捕捉能力,因此也经常被应用于恶意代码检测。文献[3]使用污点分析技术追踪多个敏感数据源的数据流动,从而判断应用是否存在威胁用户隐私的操作,但污点分析开销大,运行效率较低。文献[4]将静态反编译特征与动态运行特征相结合,使用卷积神经网络与长短期记忆网络混合的方法对恶意应用进行检测。
由于Java 语言易于逆向的特征,代码混淆技术被广泛应用于Android 程序开发的过程中。代码混淆通过去除代码中的语义信息,用等效的代码替换原有代码结构等方式,使得混淆后的代码难以理解,从而增加逆向的成本。文献[5]通过对Google官方市场,中国第三方应用市场以及恶意软件等3个数据源的10 余万应用程序包(Android application package,APK)进行大规模扫描,统计了常见的3 种代码混淆技术的使用情况。统计结果显示,Android 恶意软件对于代码混淆技术的使用与普通应用程序有较大差别。
1 基本原理
1.1 代码混淆在Android 恶意软件检测中的使用
1.1.1 标识符重命名
在软件开发过程中,开发者通常赋予变量名较多的语义信息,以保证程序的较高可读性。然而,充足的语义也为逆向者提供了方便,在变量名的帮助下,逆向者可以轻易理解原作者的意图,窃取其中重要的实现,从而对开发者的知识产权产生威胁。
标识符重命名通过将变量中的语义信息抹除,可以有效增加逆向者的攻击成本,从而被广泛使用。根据文献[5]所述,有超过70%的中国开发者和超过60%的恶意软件开发者会使用标识符重命名的方式进行混淆。但是二者的混淆实现存在较大差异。普通开发者通常使用Android Studio(Google 官方推荐的Android 开发集成环境)中内置的proguard 工具进行标识符重命名,然而其策略较为简单,通常只按照字典顺序将标识符重命名为“a”“b”“aa”“ab”……,恶意软件开发者则会使用更具有迷惑性的策略,如形状相近的字母组合,如“Ill1I1ll”或“00OoOO0”等,甚至出现英语以外的字符(Unicode)。除此之外,恶意软件还经常将重载特性与标识符重命名结合起来,比如将某些敏感函数重命名为Android 软件开发工具包(Software Development Kit,SDK)中定义的一些关键API,由于参数不同,不会影响程序的正常运行,但往往会误导逆向工程师。
1.1.2 字符串加密
由于应用中的字符串包含了非常多的语义信息,逆向者通常会将其作为理解程序语义的突破口。下面的程序片段表明,即便混淆了程序中出现的标识符名称,有经验的逆向者仍然可以依靠字符串来猜测函数的功能。

为了防止程序中的明文对信息的泄漏,字符串加密被作为一种有效的混淆手段。在Android 应用开发的过程中,字符串加密可应用在多个阶段,包括Java 代码编译阶段、Java 字节码转Dex 文件阶段等。
对于恶意代码开发者来说,字符串加密能够有效地抹除程序语义信息,抵御部分基于硬编码特征的扫描工具的检测,假如加密算法实现得足够复杂,还能够有效地增加逆向过程的时间成本。根据文献[5]所述,普通软件开发者极少使用字符串加密。
1.1.3 Java 反射
反射是Java 语言的一种高级用法,提供了一种灵活的交互方式,使得开发者能够在程序运行时了解类、方法和变量的信息,甚至动态地创建类的实例或调用方法。在Android 程序开发领域,Java 通常被用来调用Android SDK 中的非公开方法(标注有hidden 注解的API)。以下代码展示了如何通过反射,调用“android.telephony.TelephonyManager”类的“getNetworkTypeName”方法。

反射在普通程序与恶意程序中都会被使用,但是二者对反射的使用模式差异较大。普通软件通常会利用反射进行JNI 调用或后向兼容性的检测,然而恶意软件则会利用反射去隐藏控制流,从而抵抗静态分析工具的检测,或使用反射将原本正常的函数调用变得十分臃肿,加强对逆向者的干扰。
1.2 Android 恶意代码检测系统的设计与实现
1.2.1 权限特征选择及获取
Android 权限机制提供了对应用的访问控制。目前,Android 系统提供了超过170 种权限,覆盖应用行为的方方面面。然而,其中一部分权限可能会对用户的隐私或设备的运行状态产生影响,这部分权限被Android 标记为“危险”,需要开发者与用户谨慎对待。由于恶意应用往往觊觎用户的隐私或企图掌握对设备的全面控制,危险权限的出现频率通常高于普通应用。除此之外,还发现,部分恶意软件倾向于定义较多的自定义权限。基于以上两种观察,从Android 应用的清单文件中抽取权限列表,并统计其中危险权限以及自定义权限的出现次数,作为应用权限方面的特征。所选择的部分高危权限如表1 所示。
1.2.2 证书特征选择及获取
在Android 应用开发的过程中,需要对应用进行签名,签名后将会产生一个证书文件,通常以.RSA作为后缀。当应用被上传到应用市场上进行审核时,证书将会被用来证明程序的正当性。然而,某些恶意软件不能在正规市场中流通,他们所使用的证书也存在各种问题。在本文中,抽取了应用中的证书文件,并以其是否过期作为特征。

表1 所选择的部分高危权限
1.2.3 敏感API 调用特征选择及获取
Android SDK 提供了丰富的API 供开发者实现对应功能。与权限类似,部分API 的滥用也可能造成用户隐私被窃取或设备系统异常,这部分API 被称为敏感API,开发者在使用时需要特别注意。通常来讲,恶意软件对敏感API 的使用更加频繁,基于此观察,选择敏感API 的调用次数作为特征之一。除此之外,相比于普通软件,恶意软件对敏感API的调用方式通常较为单一,调用过程也更容易被触发,因此,选择敏感API 调用路径的平均长度作为特征之二。敏感API 调用路径平均长度的计算方法如下伪代码所示:


选择的部分敏感API 如表2 所示。

表2 选择的部分敏感API
1.2.4 程序混淆信息选择及获取
如第1.1 小节所示,代码混淆技术在正常应用与恶意应用的使用有较大差异。基于此,选择如下特征表示程序的混淆信息:
(1)应用程序中标识符名称的平均长度。由于Android 恶意软件倾向于对标识符进行复杂地重命名,其标识符名称的分布将不同于普通应用。除了标识符的平均长度以外,还可以使用信息熵来表征标识符名称上的差异。
(2)应用程序中字符串的信息熵。信息熵用于量化表示信息的不确定性,当某条信息被加密后,其信息熵将会增大。信息熵的通用计算公式如下:

式中,N表示事件的个数,Pi表示事件i的发生概率。在本系统的实现中,抽取一个Android 应用中出现的所有字符串并将其合并。假设合并后的字符串为S中出现的字符种类共为N,Pi表示第i个字符Xi出现的概率,则,其中S.count(Xi)表示Xi在S中出现的次数,S.length表示字符串的长度。最终的信息熵可以根据公式(1)计算出来。
(3)应用程序中Java 反射API 调用次数。根据文献[5],虽然Java 反射在Android 普通软件与恶意软件中均被广泛使用,但恶意软件对其的使用频率远远高于普通软件。遍历应用中的每个函数,恢复其smali 格式的代码,并与Java 反射API 作对比,统计其被调用的次数。选择的smali 格式的Java 反射API 如表3 所示。

表3 选择的Java 反射API 列表
1.2.5 分类算法
在从App 中提取特征之后,需要使用机器学习算法对特征进行学习,从而实现对Android 恶意代码的自动化鉴别。机器学习模型种类繁多,各具特点。经过调研,决定采用有监督二分类模型来进行实验,根据以往文献的经验,发现支持向量机与随机森林模型具有训练速度快、准确性高的优点,故针对两者进行了实验验证。
2 分析与讨论
本文采用androguard 作为Android 程序分析框架。Androguard 提供了丰富的功能与Python 开发接口,能够从Android 程序中自动提取出类、方法、成员等信息,并生成对象间的函数调用图。使用Androguard 抽取出每个Android 程序的七个特征组成向量,并使用scikit learn 库来对支持向量机模型与随机森林模型进行训练和预测。
为了使实验结果更具有说服力,采用文献中提到的数据源。这些正常的Android 程序均是从国内第三方市场以及Google Play 上下载,恶意程序主要获取于VirusShare 网站以及文献[6]从该数据源中随机抽取了2 000 个正常的Android 程序与2 000 个恶意的Android 组成了本实验的数据集。
为了验证本文所选择的特征的有效性,将特征分成了4 类。
(1)权限类特征:Android 程序中申请的高危权限数量以及自定义权限数量。
(2)证书类特征:证书是否已经过期。
(3)API 特征:敏感API 被调用的平均次数以及调用路径的长度。
(4)混淆特征:Android 程序中标识符平均长度、字符串的信息熵以及Java 反射的使用次数。
将数据集按照8:2 的比例拆分为训练集和测试集,并进行5 次的交叉检验。对于机器学习模型,均采用了scikit learn 库中提供的默认参数,具体的参数信息如表4 所示。
实验结果表明,当使用全部特征时,随机森林模型可以达到95.3%的准确率,94.4%的精确率以及98.0%的召回率,相比之下,支持向量机拥有62.6%的准确率,62.0%的精确率与100%的召回率。可以看出,虽然支持向量机能够将测试集中的全部恶意应用找出,但是同样存在非常多的误报,使得最终分类效果不理想。因此实际选择了随机森林作为本文的分类模型。确定分类模型之后,与只使用高危权限作为特征的传统方案进行对比实验。两种方案均采用随机森林作为分类模型,实验结果如表5 所示。

表4 分类模型默认参数

表5 在选用样本上的实验结果
可以看出,相对于传统方案,本方案的准确率、精确率以及召回率的提升分别为19.4%、16.5%以及13.3%,从而证明了特征与分类模型选择的有效性。为了更好地理解各个特征对分类结果的贡献度,输出了scikit learn 库中随机森林的特征重要性,结果显示,各个特征的权重如表6 所示。
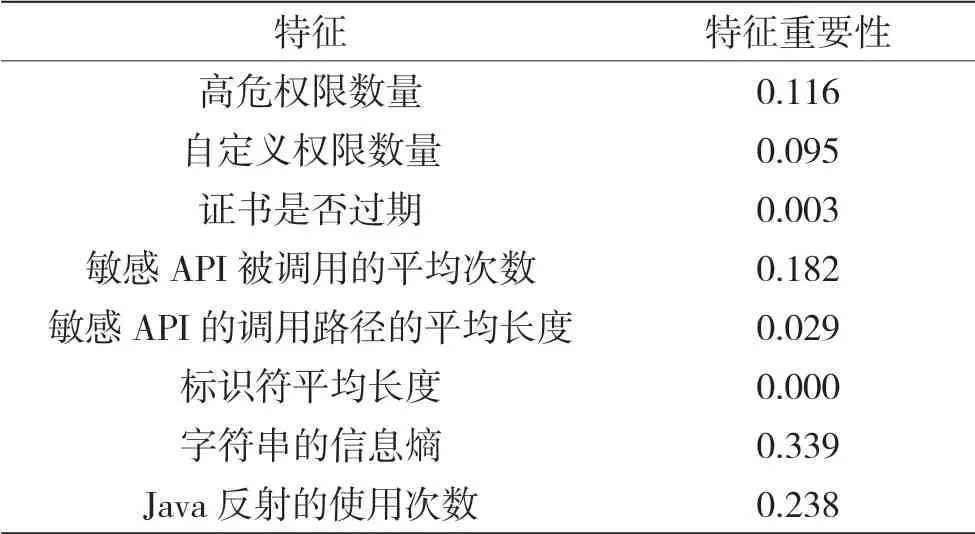
表6 实验中各个特征的特征重要性
可以看出,权限特征、API 特征以及混淆特征拥有较高的贡献度,混淆特征的贡献度甚至超过50%,证明了混淆方式的异同确实能够有效地鉴别一个应用程序的恶意性。但是标志符的平均长度未能表现出任何区分性,原因可能是测试集中使用复杂重命名方式的恶意应用数量过少,同时普通应用开发者更加注重混淆保护,使得二者的重命名模式难以区分。
3 结语
在本文中,提出了一种基于多种特征的Android恶意软件检测算法。与其他文章相比,在特征中融入了软件的代码混淆信息,实验结果表明:与传统只使用权限与API 特征的方法相比,代码混淆信息能够有效地提升检测算法的性能,其中准确率提升19.4%,精确率提升16.5%,召回率提升13.4%。在本文所使用的3 种代码混淆特征中,标识符的长度未能有效区分正常应用与恶意应用,这与越来越多的应用开始使用自动化工具(如proguard)进行标识符重命名有关。相比支持向量机算法,随机森林算法在Android 恶意软件的检测中表现出了更好的性能,精确率与召回率非常接近。
下一步的实验中,将会着重剖析Android 恶意软件在代码混淆上的使用,通过提取更多特征,来多维度地建立Android 恶意软件的画像,包括控制流混淆情况、虚假重载等。
猜你喜欢
计算机应用(2022年8期)2022-08-24
无线互联科技(2020年11期)2020-12-01
台湾农业探索(2020年4期)2020-10-29
计算机系统应用(2020年8期)2020-03-22
商品与质量(2019年34期)2019-11-29
台湾农业探索(2019年5期)2019-09-10
计算机系统应用(2019年3期)2019-03-11
科教导刊·电子版(2016年30期)2016-12-26
中国新通信(2016年17期)2016-11-17
中国信息技术教育(2015年21期)2015-09-10
