
一种基于自注意力机制的欠定盲信号提取算法*
2021-05-20 12:07陈美均武欣嵘
通信技术 2021年5期
陈美均,武欣嵘,郑 翔,皮 磊
(陆军工程大学,江苏 南京 210007)
0 引言
盲信号提取(Blind Source Extraction,BSE)源于经典的鸡尾酒会问题[1],研究如何从未知先验信息的混合信号中分离出特定目标源信号的问题,是当前信号处理领域的研究热点。根据观测信号数量N与待分离源信号数量M之间的关系,可以将盲源提取模型分为超定(M<N)混合模型、正定(M=N)混合模型和欠定(M>N)混合模型。其中,欠定混合模型与实际情况最贴合,更具有实际应用意义。但是,早期盲信号处理的典型方法如独立分量分析(Independent Component Analysis,ICA)都不适用于欠定混合模型。
Ozerov 等人提出多通道非负矩阵分解算法(Multichannel Non-negative Matrix Factorization,MNMF)[2],用于处理欠定混合模型的BSE 问题。该算法利用了多通道信号空间信息辅助进行BSE,在低混响简单场景的欠定BSE 问题可以取得较为理想的结果,但当混响较高时无法以NMF 模型对源信号建模,致使算法结果不理想。
Nugraha 等人指出,可以利用深度网络替代NMF 模型对源信号进行建模[3]。Kameoka 等人提出了多通道变分自动编码器(Multichannel Variational Autoencoder,MVAE)[4]的BSE 算法。该方法预训练条件变分自码器(Conditional VAE,CVAE)[5]表示每个信号源的生成模型,将深度网络表示能力用于源信号时频图建模,使基于深度网络的数据驱动信号模型和具有可解释性的迭代投影更新分离矩阵的盲源分离算法相结合。然而,MVAE 算法采用独立低秩矩阵分析算法对部分参数进行更新,使其只适用于正定混合模型的BSE 问题。
为解决欠定混合模型的BSE 问题,本文将以MVAE 为基础的改进算法扩展MVAE 算法[6](Generalized MVAE,GMVAE)和基于X-vector 的说话人识别模块[7]结合,构建了一个两步欠定盲信号提取算法,并引入了注意力机制,提升了识别准确率。利用GMVAE 算法分离盲信号后,将输出的估计信号利用X-vector 系统进行目标语音提取。本文利用500 人清晰语音数据集训练CVAE,以提高GMVAE 说话人无关的信号分离能力,并在X-vector系统引入自注意力计算机制,以增强特征提取时对关键帧的信息处理,并进一步利用语音信号的自相关特性。
1 相关工作
1.1 问题描述
本文信号提取在短时傅立叶变换(Short-Time Fourier Transform,STFT)域中进行。在时频域中,卷积混合通常被近似地估计为每个频带线性瞬时混合模型。假设使用n个麦克风阵列捕获m个信号源的信号混合模型,如图1 所示。

图1 信号混合模型
信号经过短时傅立叶变换到时频域并忽略噪声后,将接收信号与源信号关系以线性瞬时混合模型表示为:
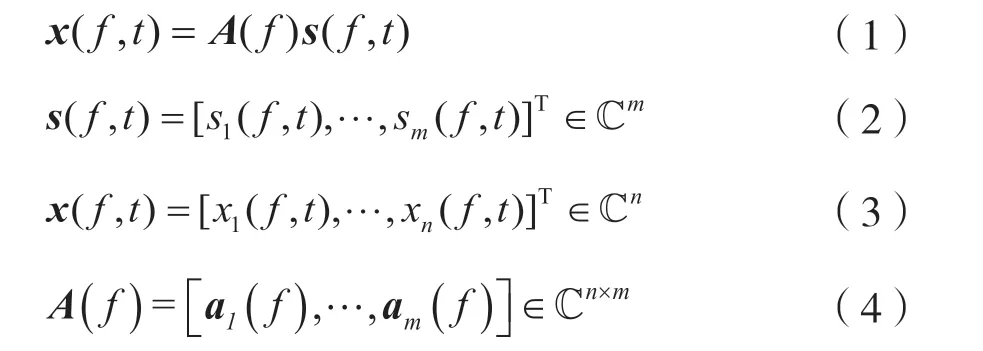
式中:f、t分别为频率与时间索引;sm(f,t)和xn(f,t)分别由第m个源信号和第n个观测信号经过STFT 得到;A(f)为n×m维混合矩阵。本文研究n<m的欠定混合情况。
在GMVAE 算法中,假设源信号符合局部高斯模型(Local Gaussian Model,LGM),即sm(f,t) 独立服从方差为vm(f,t)=E[|sm(f,t)|2]的零均值复高斯分布:

当m≠m´时,sm(f,t) 与sm´(f,t) 相互独立,s(f,t)分布为:
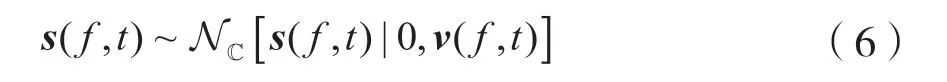
式中,v(f,t) 为对角矩阵,其对角元素为v1(f,t),…,vm(f,t)。根据式(1)和式(6),可以得到x(f,t)分布为:
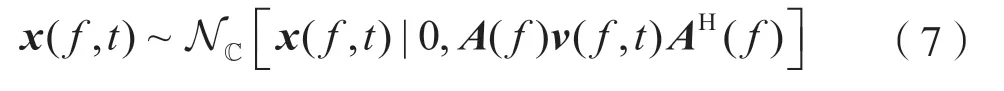
式中,(·)H表示共轭转置。给定观测信号x(f,t)时,混合矩阵A(f)与源信号模型参数v(f,t)的对数似然函数为:
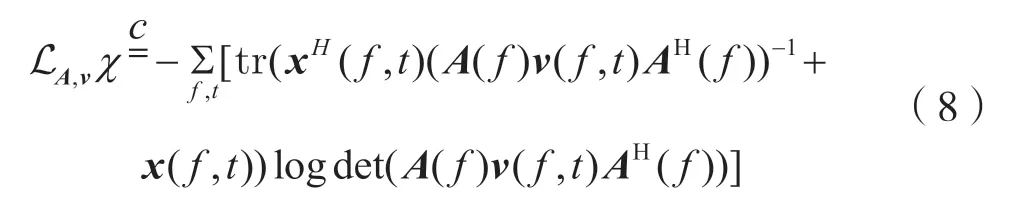
若不对vm(f,t)施加约束条件,则式(8)将转化为多个按频率划分的源分离问题。由于m的排列不会影响对数似然的值,此时混合信号的分离将存在排列歧义问题,因此需要在得到A之后进行排列对齐,以解决排列歧义问题。
1.2 多通道非负矩阵分解算法(MNMF)
在MNMF 算法中,将式(7)中A(f)v(f,t)AH(f)改写为:
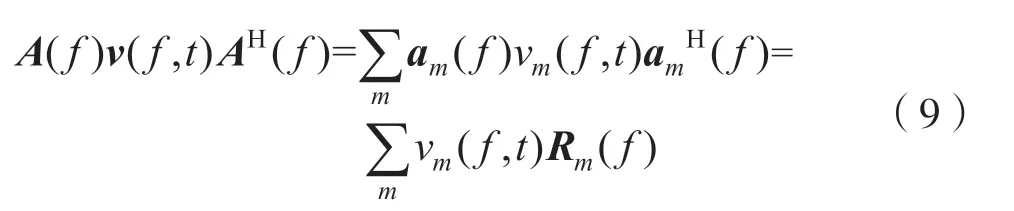
式中,Rm(f)表示第m个源信号的空间协方差矩阵。MNMF 算法利用独立向量分析的思想,通过将vm(f,t)建模为如式(10)所示Km个时变激活函数um,k(t)与频谱模板hm,k(f)乘积的线性和,从而对vm(f,t)施加约束来解决估计信号的排列歧义问题。
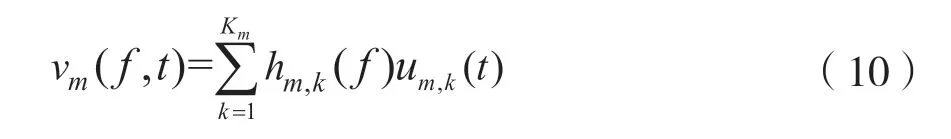
假设每个源的所有频谱模板都是共享的,以数据驱动的方式确定第k个频谱模板对第m个源信号的贡献,式(10)也可改写为:
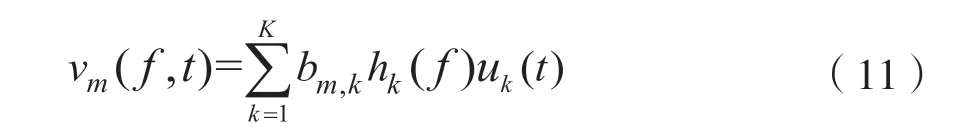
式中,bm,k表示第k个频谱模板的贡献指标,满足条件bm,k∈[0,1]且∑kbm,k=1。
MNMF 算法中包含迭代更新空间协防差矩阵R={Rm(f)}m,f、源模型参数H={hm,k(f)}m,k,f与U={um,k(t)}m,k,t估计。
1.3 条件变分自编码器(CVAE)
由于MNMF 算法处理信号只能处理能以NMF模型表示的信号,当信号频谱模型不符合式(10)时,MNMF 算法不能完成信号处理任务。在GMVAE 中,使用预先训练好的条件变分自动编码器(CVAE)替代式(10)。令表示源信号的时频图模型,GMVAE 利用带有辅助输入条件c的CVAE对其进行建模。辅助条件c代表源信号的类标签,使用one-hot 向量进行表示。
CVAE 包含了一组编解码网络,在用于分离前使用有标签样本进行训练。编码器分布为:
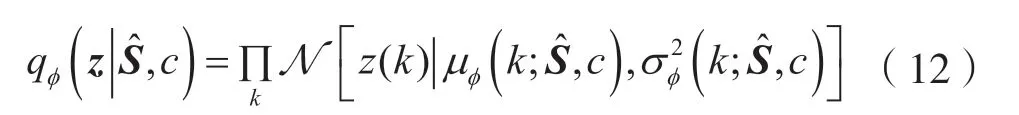
式 中,z表示隐层变量,和分别表示的第k个元素。
解码器分布为零均值复数高斯分布:

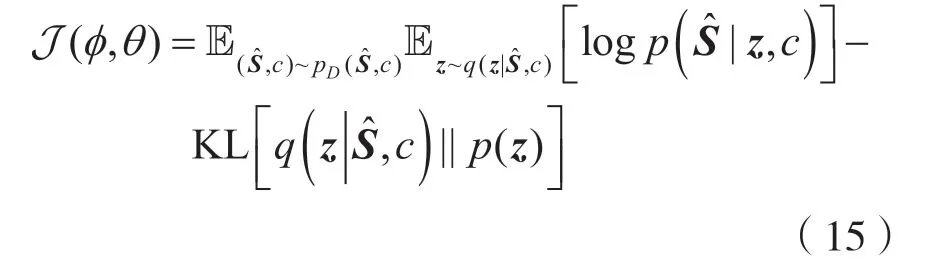
2 盲信号提取算法
图2 为提出的BSE 算法GA-X-vector 流程示意图。GA-X-vector 需进行两部分预训练,先训练CVAE 得到解码器作为GMVAE 部分源模型,后利用通过基于注意力机制的特征提取模块提取到的X-vector 训练得到概率线性判别分析(Probabilistic Linear Discriminate Analysis,PLDA)模型,用于信号提取判别。算法将两通道信号作为输入,经过GMVAE 部分得到3 个估计信号,并对其进行X-vector 提取操作后输入PLDA 模型。根据参考信号的注册信息利用PLDA 模型进行判别,系统将输出预提取的目标信号。
2.1 扩展多通道变分自动编码器
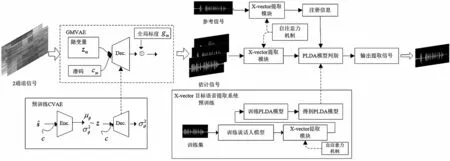
图2 GA-X-vector 算法流程
根据文献[8],可以证明以下公式:
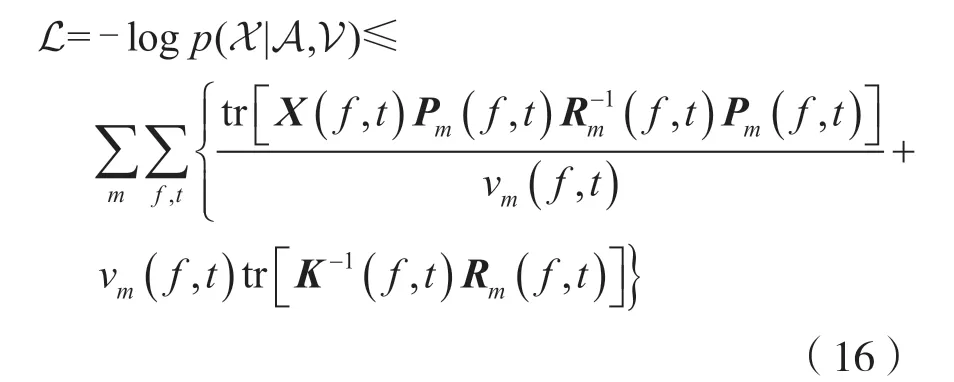
式(16)等号成立的条件为:

将式(16)右边作为L的推广,P={Pm(f,t)}m,f,t和K={K(f,t)}f,t是辅助变量。在对参数进行更新时,通过插入softmax 层对cm进行归一化:

将dm作为待估计的参数,G 更新公式如下:
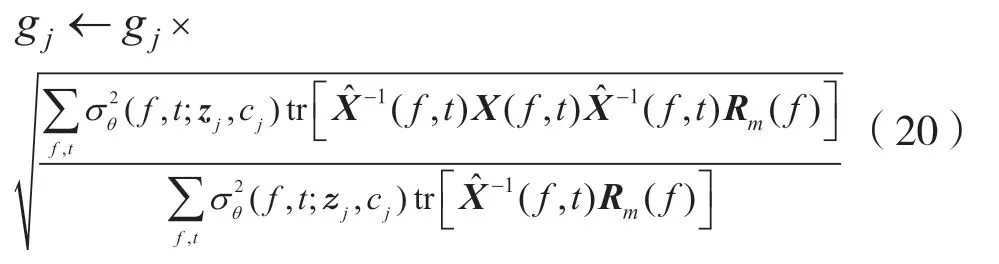
2.2 基于自注意力机制的X-vector 系统
X-vector 系统[9]是一种基于嵌入向量(embedding)由DNN 搭建的说话人识别系统。嵌入向量的本质是由训练后的深度网络提取到的说话人声纹特征。此系统中将嵌入向量用X-vector 表示。X-vector提取网络结构如图3 所示。该网络可以分为两个模块。第一个模块为帧级别特征提取模块,采用时延神经网络处理存在时序关系的语音信号帧,输出帧级别说话人特征。模块一的输出经过统计层计算均值与标准差,由帧级别特征过渡为语句级别特征输入模块二,即语句级别特征提取模块的两层全连接层中,将输出输入softmax 输出层,最终输出后验概率,其中输出神经元的个数和训练集的说话人个数一致。从全连接层中提取的特征向量即为说话人特征X-vector。
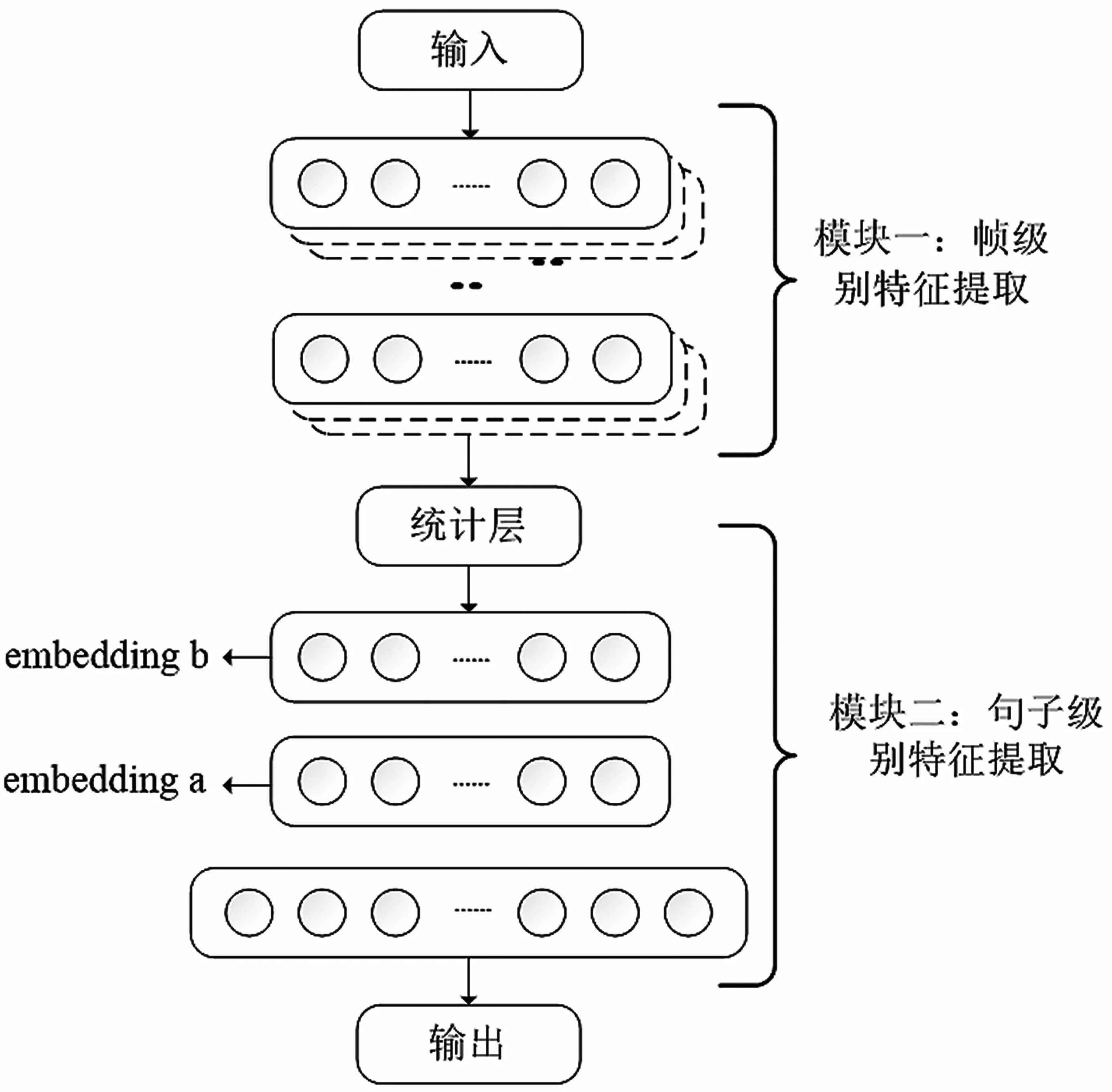
图3 X-vector 提取网络结构
在传统X-vector 系统中,统计层在计算均值与标准差时,认为不同帧的权重相同和语音信号的每一帧重要性相同。Zhu Y 等人指出不同帧能提供的区分信息量是不同的[10],如同人耳对一段声音的关注也有差异。本文在X-vector 系统的帧级别特征提取模块与统计层间引入多头自注意力机制,通过引入多头自注意力机制来解决统计池化算过程语音帧特征权重相同的问题。自注意力机制是一种特殊的注意力机制,通过对序列本身进行注意力计算,给不同元素分配权重来获得序列内部的联系,而多头的目的是关注信号的多个子空间信息。
图4 为引入注意力机制后帧级别特征提取后到统计层的流程。

图4 基于自注意力的统计层
引入自注意力机制[11]后,需要计算不同帧之间的权重。假设统计层输入T帧H={h1,h2,…,hT},每帧特征维度为dh,H维度为dh×T,注意力机制中利用缩放点积注意力(Scaled Dot-product Attention,SDA)计算权重,计算式如下:
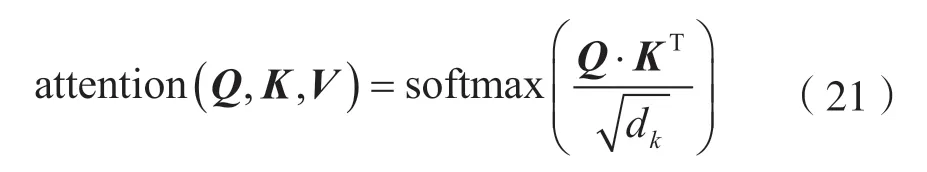
式中,Q、K、V分别为查询向量、键矩阵和值矩阵,dk表示键的维度。分母中的对权重进行缩放,防止向量维度太高时计算出的点积过大。在多头自注意力机制中,有Q=K=V=H。对H做线性变换如下:

3 仿真实验
3.1 数据集及处理
本文利用VoxCeleb1 数据集[12]进行仿真分析。VoxCeleb1 数据集中数据属于自然环境下的真实场景,全部音频来源于YouTube 网站,是真实的文本无关的英文语音数据集。数据集内涉及场景多样,男女性别比例均衡,年龄、职业、口音等都具有多样性。该数据集音频的采样率为16 kHz,格式为16 bit单声道的wav文件。语音中带有真实场景噪声。
实验目标为从两个观测信号中分离出3 个源信号并提取出目标语音信号。利用RIR-Generator[13]工具准备测试用的混合信号数据,图5 展示了在混合源信号得到待处理信号时,信源与麦克风的模拟位置。“+”表示麦克风,“○”表示信号源。测试用两通道混合语音信号采样频率为16 kHz,短时傅立叶变换帧长为256 ms,跳长为128 ms。
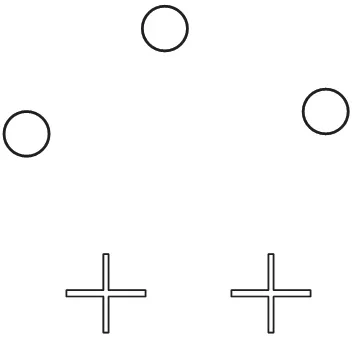
图5 麦克风与信号源位置示意
3.2 实验结果分析
针对本文提出的提取算法实验分析,目标信号提取质量评价主要使用BSS_Eval 工具[14],评估指标为信号失真比(Signal-to-Distortion Ratio,SDR)、信号干扰比(Signal-to-Interference Ratio,SIR)以及系统误差比(Sources-to-Artifacts Ratio,SAR),使用等错误率(Equal Error Rate,EER)评价目标语音提取存在误判的情况。
图6 展示了一组由本文提出算法提取的目标信号与干净源信号的时频图对比。可以看出,算法提取出的目标信号与源信号相似度极高,提取效果良好。
表1 展示了所提算法提取信号质量与基准模型的评估指标对比,对比采用的基准模型为基于使用式(10)作为源模型的MNMF-X-vector 系统结合的盲信号提取算法。GMVAE-X 表示GMAVE 与传统X-vector 系统结合算法,实验混响时间T60分别设置为78 ms 和351 ms。从表1 可以看出,与基准模型相比,应用GMVAE 的BSE 算法在各项指标都优于基于MNMF 的BSE 算法,各项指标提高2 dB。尤其在较高混响条件下,GA-X-vector 算法提取质量也高于基准算法在低混响条件下的提取质量。可见,利用VAE 建模提升了信号提取质量,增强了对复杂场景的盲信号处理能力,且表1 中数据也体现了增加注意力机制可以提升目标信号提取的质量。
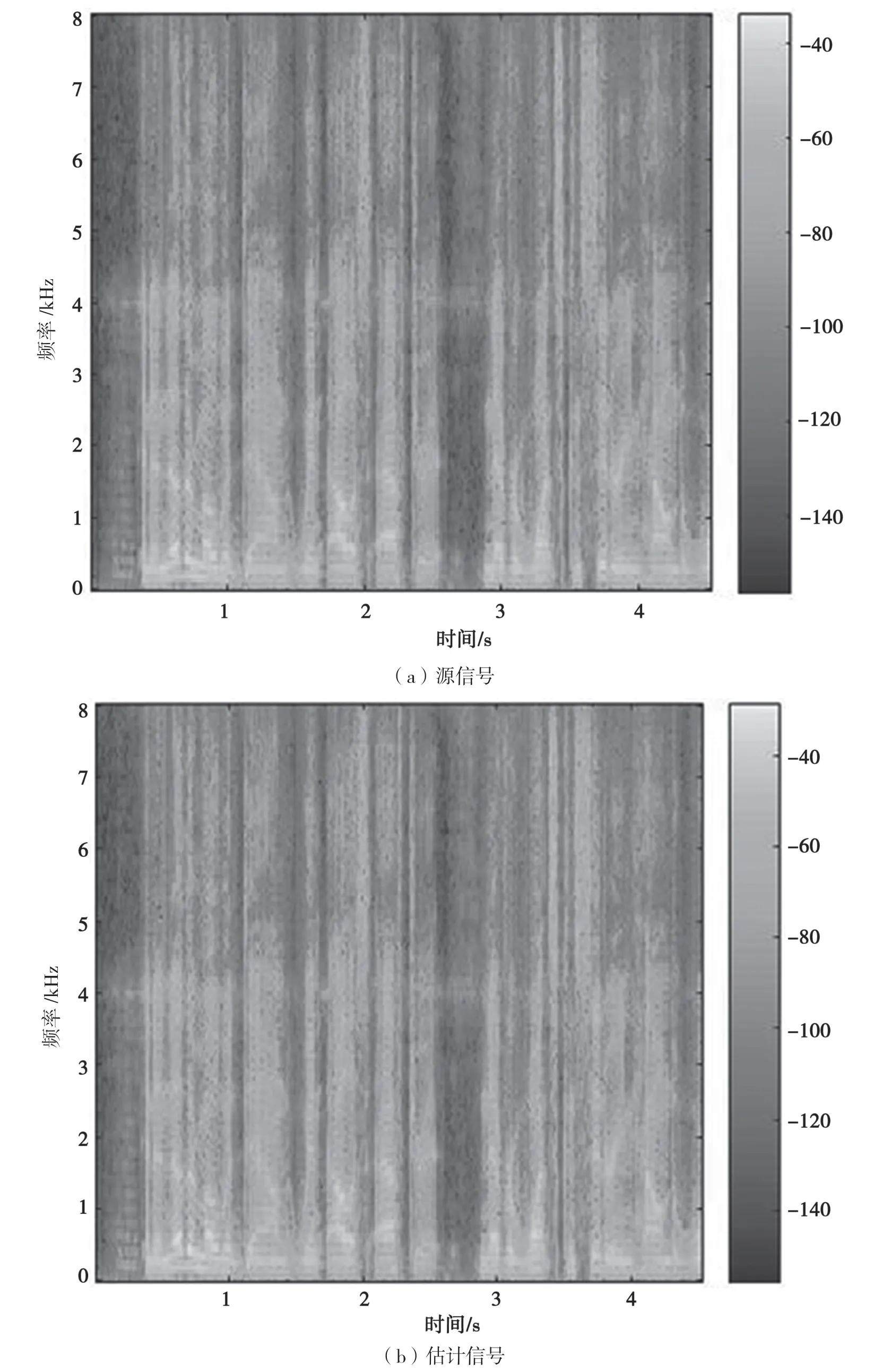
图6 源信号与提取出目标信号时频图
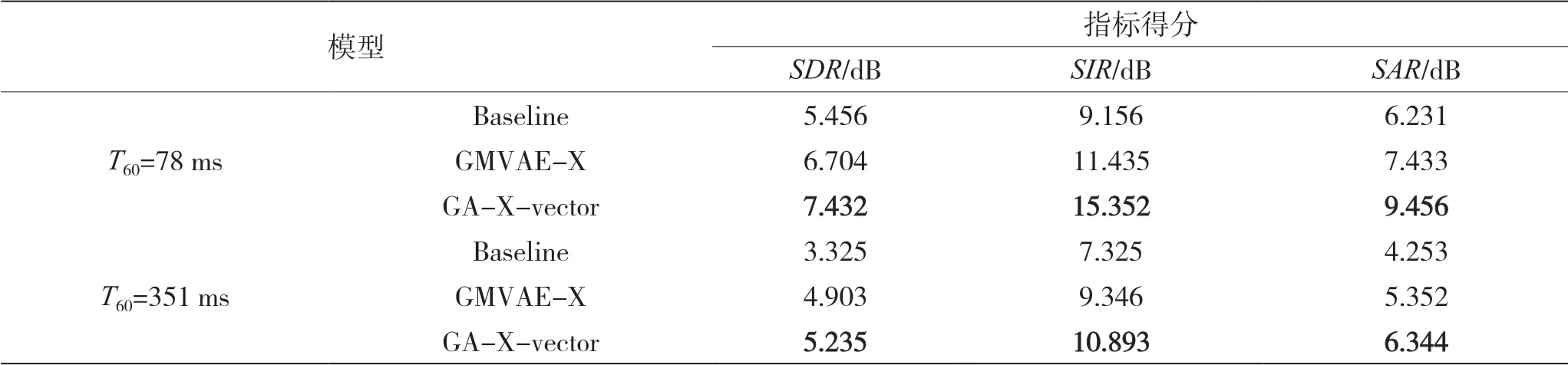
表1 目标信号提取质量比较
表2 反映了所提的多头注意力算法中注意力头数量对信号提取准确率的影响,其中attn-k 中k表示自注意力机制中的注意力头数量。从表2 可以直观看出,注意力头数量增加能够提升提取准确率。相较于不增加注意机制的算法,当注意力头数为5时,等错误率指标降低了1%。结合检测错误权衡(Detection Error Tradeoff,DET)曲线进一步分析自注意力头数量对X-vector 系统的目标信号提取准确率的影响,图7 展示了4 种算法的DET 曲线。DET 曲线刻画了算法“漏查”和“误查”两种错误的权衡。曲线越接近左下角,则表示判别算法越好。图7 中显示注意力头数量为5 时,判别算法的曲线最接近左下角,此时判别算法最优。结合图7 与表2,注意力机制中注意力头的数量与提取准确率呈正相关。每一个注意力头都能单独学习信号的不同依赖性,从模型训练的角度来看多头注意力,使模型能够处理来自不同子空间的信息,并利用帧与帧间的关联性来增强关键帧的信息,以达到提升识别性能的目的。

表2 注意力机制对于目标信号判别准确率的影响

图7 不同注意力头数的算法DET 曲线
4 结语
在复杂场景中准确提取特定信号具有重要的现实意义和研究前景。针对欠定混合模型的BSE 问题,本文提出了GA-X-vector 算法。将GMVAE 与引入自注意力机制的X-vector 目标信号判别系统相结合,利用深度网络的表示能力,使用CVAE 对源信号进行建模,提升了高混响复杂场景的信号提取性能,并利用MNMF 替代低秩矩阵分析对参数进行初始化,使其能够用于欠定混合模型的信号提取。在X-vector 系统中引入自注意力机制,增强特征提取时对关键帧的信息处理,并进一步利用语音信号的自相关特性提高目标信号提取的准确度。仿真结果表明,与基准算法相比,本文提出算法的信号提取质量指标均高2 dB 以上,提取准确率提高了1%。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
甘肃教育(2020年22期)2020-04-13
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
读与写·教育教学版(2017年10期)2017-11-10
第二课堂(课外活动版)(2016年2期)2016-10-21
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
