
机器口译软件翻译质量评估实验研究
——以中英旅游文本为例①
2021-05-20 12:09李双燕孙晔芃
英语知识 2021年2期
李双燕 孙晔芃
(首都经济贸易大学外国语学院,北京)
1.引言
随着人工智能技术与翻译领域的深度融合,机器翻译(MT)已成为人工智能翻译时代的新常态。机器口译App因其便捷性、灵活性逐步成为大众生活类翻译的主要选择。但当前机器口译的实验研究较少,主要侧重于使用计算机科学算法及建模评价标准对译文进行自动化、模式化的评分,较少涉及语用层面等语言学意义方面的研究(姜宝涵,2018;刘佳琛,2019),因此本研究拟将语用层面纳入进来,把语音识别、语言转换以及语音合成看作一个整体,以中国游客在英语国家旅游交流场景为例,评测有道翻译官在模拟真实场景下的机器口译输出质量,并且通过量化和质化分析,找出当前机器口译App存在的问题,并提出改进建议。
20世纪80年代中期,西方学者开始进行口译质量评估实证研究,试图将口译质量量化。Bhler(1986)指出衡量口译质量最重要的9个指标为后续口译质量实证研究奠定了基础。Moser-Mercer(1996)提出针对不同评测目的,口译评测的侧重应该不同。Angelelli(2000)从社会交际视角出发,探索只听取单方对话对口译质量的影响。中国则从90年代起,开始逐步关注口译质量的影响因素及其评估方式。胡庚申(1993)提出了CREDIT模型,并通过计算求出不同级别口译效果的数值范围。鲍刚(1998)采取定性、定量相结合的方式评估口译质量。刘和平(2002)结合科技口译制定了量化的科技口译评估方法。本世纪初,台湾辅仁大学翻译学研究所所长杨承淑(2005)提出了量化(quantitative evaluation)与质化(qualitative description)相结合的评估理论,并给出了相应指标的占比及分值,奠定了国内口译质量量化评估的基础(刘佳琛,2019)。
在机器口译评测方面,国内外对机器口译质量的评估研究相对薄弱(王华树 李智,2019)。当前机器口译对于重音、方言、背景音以及发音不清等要求都较为严格,缺乏人的判断力和文化储备(Emma,2016)。虽然当前已有学者对国内机器口译进行质量评估,但其文本都局限于科技、经济讲座或总理答记者问这类较为正式的口语材料(赵琳,2017;李雪菲,2018;姜宝涵,2018),较少探讨日常对话评测,难以全面反映口译软件在大众日常生活中的使用情况。
在杨承淑量化与质化评估理论中,量化与质化相辅相成,量化指出的数值往往代表比较负面的评价,因而需要质化来修正;质化所评但就目前机器口译的发展来看,日常对话是此类软件的主要应用场景,出国旅行使用比率较高。因而,本研究选取旅游类口语场景对话作为评测材料,分析国内主流机器口译App的翻译效果。
基于当前缺乏针对旅游类材料机器口译的质量评测标准,本文借鉴了大学旅游英语课程的部分口译评价标准,注重译员口译时的理解能力、语音语调、语法词汇、口语交流的得体性;考虑到中外文化的巨大差异,必要时还应对文化意象进行解释,并根据提示信息的类别调整译文(曾利沙,2005)。
由于对话翻译的日常使用频率高,适用范围广,应用难度小,因此本文选择日常对话类材料作为研究对象,所评测的机器口译交替传译是指通过机器口译的语音识别、翻译技术、文字转语音技术对使用者的语音进行识别、翻译并以AI语音的形式呈现。
2.理论基础与研究设计
本文将以杨承淑(2005:237-238)提出的口译专业考试评分表为基础,根据旅游口译的特点制定旅游类机器口译(汉译英)质量评估表。具定的结果由于无法记住所有细节往往趋于宽容,因而需要量化指针来补充整体判断(杨承淑,2005)。在表1中,量化的具体指标包括忠实层译次数、遗漏翻译次数和增译翻译次数;表达层面的逻辑不清次数、发音不清次数、赘音赘词个数和句型生硬次数;语言层面的语法错误个数、选词不当次数、语意不明次数、缺少文化转换次数;时间控制层面的译文时间是否超过原文时间、启动大于2秒次数。质化的具体指标包括忠实层面的信息是否等值、省略是否恰当和补充是否恰当;表达层面的逻辑是否清晰、发音是否清晰、语调节奏是否顺畅易懂和总体是否流畅清晰、转换自然;语言层面的风格是否一致和选词是否恰当;时间控制层面的时间长度是否恰当,启动是否及时。
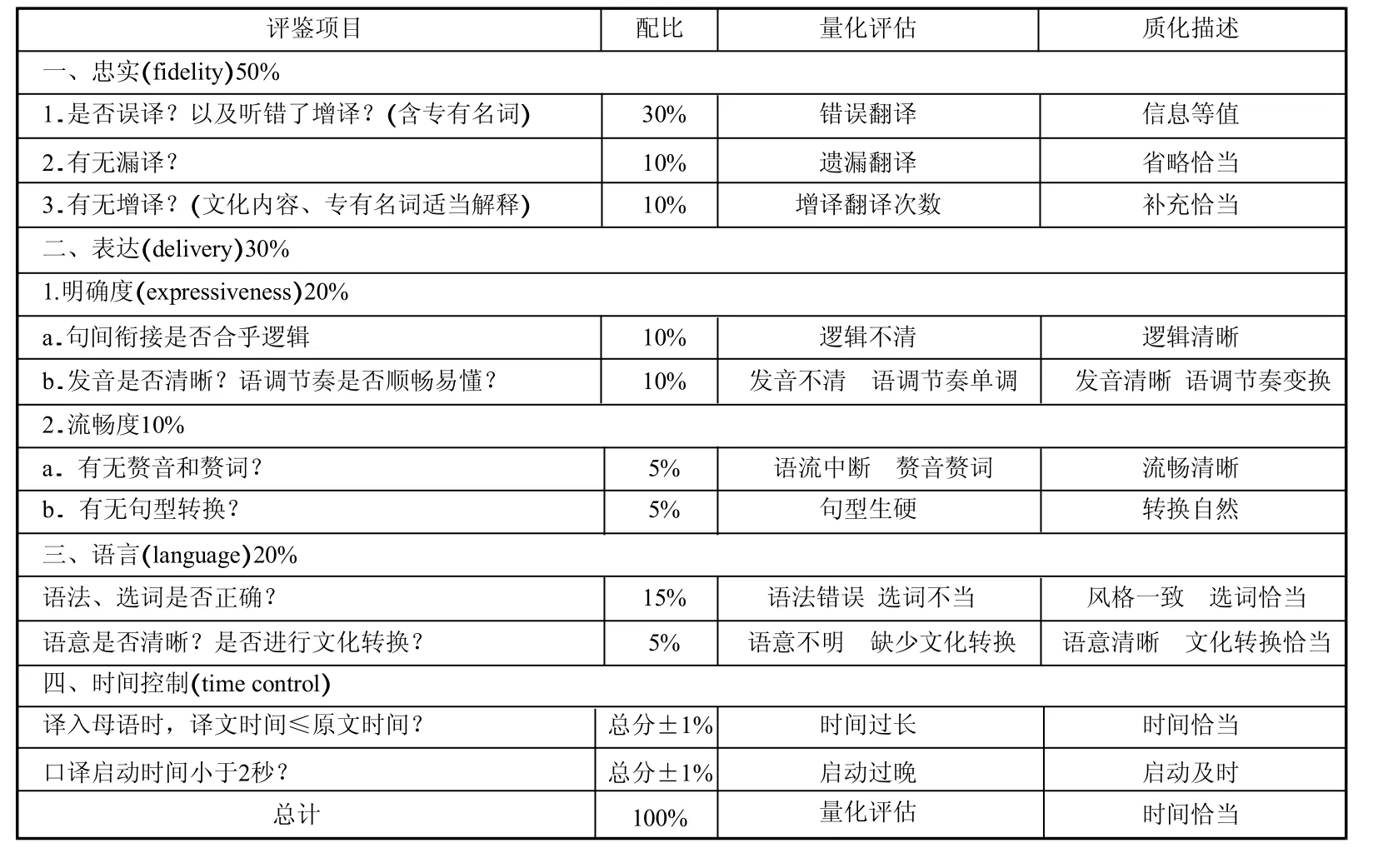
表1 旅游类机器口译(汉译英)质量评估表
在杨承淑的分数评定等级中,总分90分表示口译水准可独当一面,总分85分表示口译水准稳定,总分80分表示水准尚称稳定,可从事较简易的口译工作,总分75分表示略有语言和知识不足的问题,但已具备基本口译技巧,总分70分表示语言、知识或技巧中有某一项极弱,导致稳定度不够,不及格(杨承淑,2005)。由于本文对评价表只有少部分修改,整体类别和分值配比无变化,因此修改后的旅游类机器口译(汉译英)质量评估表依旧借鉴杨承淑的等级评定标准。
3 实验概述
3.1 实验假设
本文假设有道翻译官机器口译App在旅游对话中,中译英翻译质量良好,8组机器口译平均分在80分以上,分值浮动区间为70-90全部及格,且男女平均得分无明显差异(二者均分差值不超过5分)。质化方面,在忠实层面,机器口译信息等值、省略恰当和对文本略有补充;在表达层面,逻辑清晰、发音清晰、语调节奏较为顺畅易懂,总体流畅清晰、转换自然;在语言层面,选词较为恰当,风格一致;在时间控制层面,时间长度恰当,启动及时。
3.2 实验流程
本文主要采取了实验法以及定量与定性相结合的分析方法,通过旅游口译评价表对机器口译质量进行评价。这不仅使得分析结果符合口译交际目的,具有语言学意义,而且还借助分数使评价结果更为科学、准确、直观,弥补了之前传统语言学评价较为抽象的问题。
具体实验步骤如图1所示:

图1 实验流程
第一步:收集语音材料。笔者构建了9个具体旅游场景及31个需求点,与8位测试者进行模拟场景对话,收集真实语言状态下的中文语音材料。每名测试者每个需求点的语音回答为一组材料(由于不同测试者表述不同,一组材料可为单句,也可为多句),共计248组回答。
第二步:对语音材料进行打分并进行人工转录。转录文本包含测试者的口头禅等,之后统计字数。由于8名测试者身处环境、音频收集途径(现场或微信电话)、音频效果不同,所以本文对音频的音质、背景音、音量、吐字清晰度、语言完整度、语速、语言口语化程度等7个维度进行打分,分值范围为1-5分,总分共计35分。其中满分5分代表音质清晰、无背景音、声音洪亮、吐字非常清晰、语言非常完整、语速适中、语言口语度高;各项最低分1分则代表音质非常差,背景音非常大、声音弱、吐字非常模糊、语言非常碎片化、语速极慢或极快、语言口语化程度极差。
第三步:进行机器口译。逐句播放8位测试者的音频材料,通过有道翻译官的“对话翻译功能”进行中-英口译。
第四步:机器口译评估。根据表1构建的“评估标准”,逐句、逐项进行量化评估和质化描述。量化评估时,以每项指标所收集的数据为基础,通过先行扣分、再乘以占比的方式计算得分。其中每组材料测试者回答的语句数量会有不同,但由于各个需求点均可由一句话进行回应,因此本文将每组回答统一视为一个整体,按照“一错皆错”的原则,即一个句子中如果出现某一项错误,则将减去该句该项全部得分;质化评估时,针对得分结果,结合个别语言点进行质化描述。由于机器语音未识别的部分,口译App会自行补充相应内容,因此本文测试的机器口译还是以最终形成的英语语音为准。
第五步:数据分析。通过量化与质化分析、整体评估、对比分析得出相应结论。
3.3 实验软件
有道翻译官是网易有道公司出品的一款软件,该软件支持离线翻译功能的翻译应用,在没有网络的情况下也能顺畅使用。2019年12月,教育部办公厅公布第一批教育App备案名单,有道翻译官通过备案。
3.4 测试对象
测试者需满足以下几方面要求:满足机器口译App的使用条件,比如拥有智能手机,会安装软件,同时有出国旅游的机会,因此测试者年龄在12-74岁之间较为合适。参照联合国世界卫生组织的年龄分段和出国人群的实际情况,青年人与中年人的出国比例高于少年和年轻老年人。因此,8名测试者选取4名男性,4名女性,其他具体信息如表2所示。
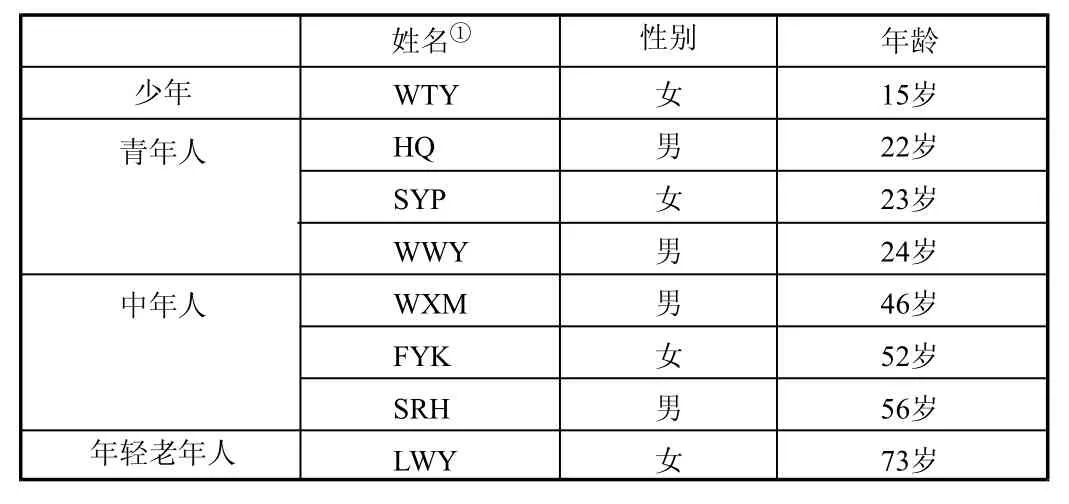
表2 8位测试者个人信息
3.5 实验材料
考虑到本次对比研究的实用性和创新性,笔者选取了2本有关旅游英语的书籍作为话题参考,分别为通用教材《旅游英语(第3版)》(李燕徐静,2018)和大众读物《一个人带着英语去旅行》(都述文 李艺璇,2017)。根据实验需要,共构建了9个具体旅游场景及31个需求点8名测试者的原对话音频质量如表3所示。

表3 测试者原对话音频质量
4 实验结果分析
4.1 实验结果的量化分析
本文利用有道翻译官对上述音频进行口译,并根据“评估表”进行评估,统计结果如表4所示。
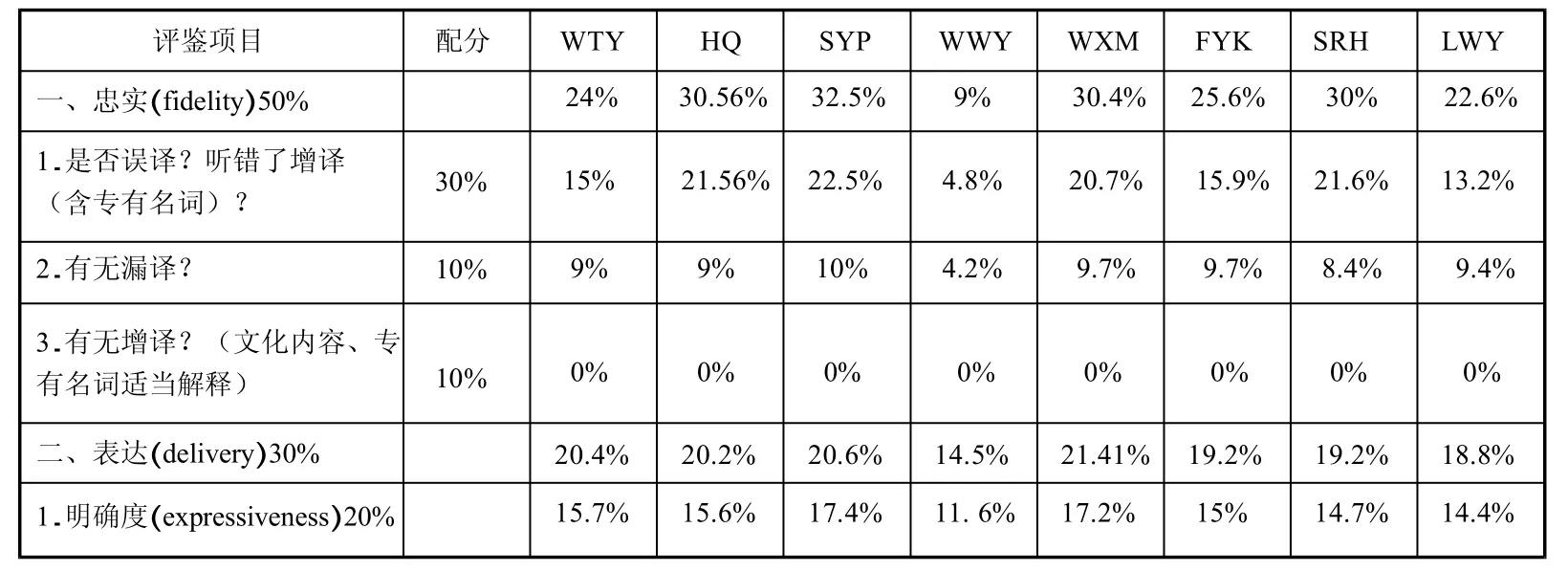
表4 机器口译(汉英)口译质量评分结果

续表
通过表4可知,整体机器口译平均分为55.95,低于预想平均分80分,且本次测验的分数浮动在31.1-67.3之间,远低于假设的70-90分,这说明当前机器口译在旅游方面的模拟应用效果还远未达到预期。
忠实方面,8组平均分为21.52(满分50分),最高分30.56,最低分9。表明当前机器口译App在传达正确信息方面很差,特别是在误译以及文化转化方面,本实验在误译方面平均得分在16.9(满分30分),接近一半的对话未被正确翻译,并且机器翻译没有文化转化的功能,主要按字面意思翻译。
语言方面,8组平均为9.58(满分20分),最高分12.4,最低分5.6。在短句密集或句子很长且没有明显语音停顿的情况下,机器口译的语法、同音词或同义词的选择比较随机,难有统一标准。在“语意及文化转换”的评分项中,平均分为2.23(满分5分),表示能正确传达语意的对话不足半数。
表达方面,8组平均分为19.21(满分30分),最高分为21.41,最低分为14.5。这一项相较忠实和语言两项的分数要高,机器口译App在“发音”以及“赘音赘词删减”方面做得不错,但在语言逻辑方面表现一般,平均分为5.59分(满分10分),发现句中的逻辑关系能力不佳。此外,“句型转化”一项表现最差,几乎都是按照中文进行逐字全部翻译,不能对句子元素进行有效挑拣重组。
时间控制方面,几乎所有的句子都能保证英语口译时长小于等于原语音时长,且启动时间小于2秒。只有1、2句会超时,可忽略不计。值得注意的是,机器口译App在使用一定时长后(翻译150句左右时),若原句长度多于50字,口译启动时间则明显加长,多于2秒,需退出后重启,方可缓解。
4.2 实验结果的质化分析
从量化分析结果可知,当前机器口译App在旅游领域模拟中译英对话中口译质量较低,在现实旅游场景中尚未达到预期效果。因此,下文将从质化角度逐一分析机器口译App当前存在的主要问题。
4.2.1 语音识别不佳
机器口译整体上翻译较为准确,但个别地方翻译得很离谱,原因主要是语句的核心词识别错误。
例1:
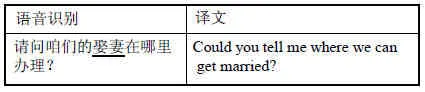
语音识别请问咱们的娶妻在哪里办理?Could you tell me where we can get married?
在该例句中,机器口译把句中关键词“值机”语音识别成了“娶妻”,并在翻译中并未纠正,因此该句口译质量受到很大影响。
4.2.2 文化转化不佳
在中国,客套话是一种常见的表达方式,很多顾客在商店、餐厅表达需求时会把“商店/餐多顾客在商店、餐厅表达需求时会把“商店/餐厅”表述为“咱们商店/餐厅”。
例2:

语音识别 译文请问咱们商店营业时间是什么时候呢?What are our shop hours, please?
在该例句中,“咱们商店”并不是表达这个餐厅是测试者和店主共同经营的,而是与对方拉近距离的客套说法。机器软件却难以识别这类客套话背后的语用含义,仍按照字面意思翻译,难以符合语用需求。
4.2.3 冗长信息删减不当
人们在口语表述中会有结巴的现象,为了节省时间应该删去这类因口误造成的无用或重复信息。在下面这句例句中,App没有识别出结巴“您好”,依旧照常翻译,在真实场景中耽误时间。
例3:

语音识别 译文您好,您您好,商场里有没有打折区啊?Hello, hello, is there a discount area in the shopping mall?
4.2.4 物品名称及称谓混乱
由于机器没有办法识别在场人员性别,因此在对话中遇到人称代词“她/他/它”时,App在选词上没有参考依据,会造成一系列错误。在例句中,“他”在语音情况下并没有说明是男士还是女士,被翻译成“he”欠妥,且“I and he are together”表达不地道。
例4:

语音识别 译文不好意思可不可以换下座位,因为我和他是一起的。And the new person is embarrassed can change the seat, because I and he are together.
4.2.5 数字翻译不恰当
语音识别数字表达不规范对机器口译产生很大负面影响(刘佳琛,2019)
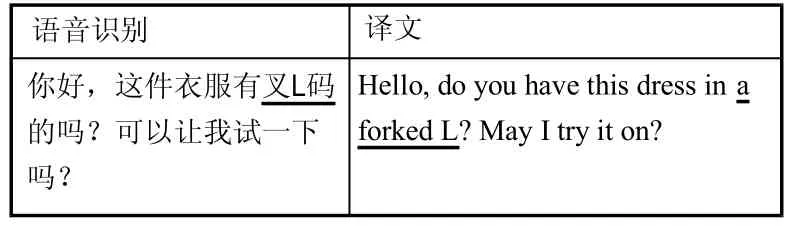
语音识别 译文你好,这件衣服有叉L码的吗?可以让我试一下吗?Hello, do you have this dress in a forked L? May I try it on?
例5:
在中国,衣服尺码是按S、M、L、XL等来记录码数的,在读音中“XL”中的“X”习惯被读成“叉”。在该例句中,“XL”没有被正确识别出来,对应的译文“Extra Large”也没有表达正确。
4.2.6 语音效果不稳定
机器口译在译文过长时还将导致语音输出不顺畅,遇到较长的句子会一口气念下来,单词发音也会变形,听者在理解上会受到影响。
4.3 其他相关研究
探究语音文字数量与口译质量的关系时,据图2所示,测试者表达的文字越多,口译质量相对越低,但由于口译质量在趋势线上下浮动较明显,可得出文字数量会产生影响,但不占主导地位。

图2 语音文字数量与口译质量的关系
将原语音质量和机器口译的得分进行对比分析,据图3所示,基本可看出随着原语音质量的下降,机器口译得分明显降低。
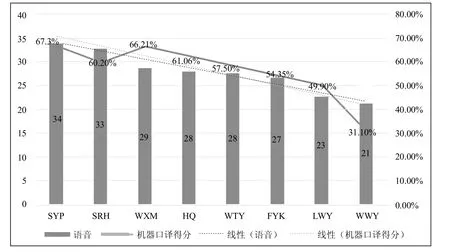
图3 原语音质量与机器口译质量的关系
由于8位测试者中只有WWY是通过微信语音电话进行机器交传,受设备影响噪音较大,音频评分与机器口译评分都明显低于其他同类数据。为了更好分析测试者性别和机器口译质量的关系,共分为有无测试者WWY两种情况,进行平均分比对。在包含WWY数据情况下,男测试者平均分为54.64,女测试者平均分57.26;在不包含WWY数据情况下,男测试者平均分为62.49,女测试者平均分57.26。机器口译质量在两种情况下均分差值均在5分以内,说明男女语音差异不会对机器口译质量产生明显影响。
5 研究结论
5.1 主要发现
本文通过实验研究发现机器口译App在模拟旅游场景的使用中翻译效果不佳,尚未达到预期效果。
从量化角度来看,机器口译App在“忠实”和“语言”两大项得分最少,不足50分;在“表达”上相对表现较好;“时间控制”表现最佳。从质化角度来看,机器口译App口译质量受到以下几方面影响:语音识别不佳、文化转化不佳、冗长信息删减不当、物品名称及称谓混乱、数字表达不当、语音效果不稳。
此外还发现,语音文字数量越多,口译质量相对越差;语音质量越高则口译质量越高;男女语音差异不会对机器口译语音质量产生影响。
5.2 研究局限
本研究有以下几点不足:1)笔者只选取了8名测试者,样本数量不够大。2)这8位测试者都使用普通话,没有探究方言对旅游汉英机器口译交传质量的影响。3)由于语言材料较多,评分标准按照“一错全错”的原则进行评分,没有根据错误程度进行更为细致的打分,使得最终得分比较低。未来可以在本研究的基础上增加测试者的数量,收集方言语音素材,细化旅游汉英机器口译质量评估标准。
5.3 研究建议和启示
本文通过分析实验结果,对当前机器口译App的交传功能提出以下改进建议:
第一,使用机器口译App前,先选出对应国家、场景及身份等。不仅可以有效避免不同国家对于同一单词释义不同的尴尬、同音词的听译误差,还可以有效辨别对方性别。
第二,规范旅游常用语。旅游口译评测还应包含检验旅游常用句型,旅游机器口译App可以尽可能地规范表达基础需求的旅游常用语,避免产生歧义。
第三,增强机器理解能力,删除无用信息。汉语口语的短句较多,表述时先进行描述,最后说出需求。而英语国家正好相反。因此机器口译需要像人工口译学习,抓住句子主干进行翻译,而不是逐字完全翻译。
第四,研发机器口译App浮窗翻译功能。当前机器口译App在进行对话翻译时,屏幕无法离开翻译界面,可实际情况却是人们有时需要配合手机上的图片、地图或其他App进行表述。未来机器口译App可与整个手机或其他软件融合,成为一种集成性服务程序,而不再是单一应用软件。
当前,机器翻译蓬勃发展,许多商家在宣传机器口译时都会声称机器口译可以代替人工口译,但通过本研究发现其实不然。一旦脱离清晰明确的语音材料,回归日常口语交流,机器口译则会暴露缺点。对机器口译来说,其语音语调区域单调,无法传递情绪,无法像人类一样对沟通对象进行预判,这些都是未来需要攻破的技术难题,因此,机器口译App技术研发任重而道远。身为口译员面对不断完善的机器口译技术,也要不断学习,充分发挥主观能动性,拓展知识面,增强信息综合处理能力。如此,人机优势才能互补,共同提升未来口译质量。
猜你喜欢
教育教学论坛(2022年29期)2022-10-31
意林·作文素材(2021年9期)2021-07-06
阅读(快乐英语高年级)(2019年5期)2019-09-10
阅读(快乐英语高年级)(2019年2期)2019-09-10
小说界(2018年5期)2018-11-26
发明与创新·中学生(2017年12期)2017-12-11
卷宗(2017年26期)2017-10-17
英语学习(2016年2期)2016-09-10
校园英语·下旬(2016年5期)2016-06-07
环球时报(2014-10-08)2014-10-08
