
结合数据增强和轻量化模型的YOLOv3木梁柱缺陷检测
2021-05-19 07:18:30王宝刚杨春梅夏鹏
电机与控制学报 2021年4期
王宝刚, 杨春梅, 夏鹏
(东北林业大学 机电工程学院,哈尔滨 150040)
0 引 言
木材缺陷的检测对有效降低有限森林资源的消耗,提高木材产品的商业价值有着重大意义。但是现阶段木材的缺陷检测主要是人眼检测,成功率在68%左右[1]。随着传感器迅速发展,X射线检测,核磁共振技术成为木材缺陷检测的主流,但是成本高,复用率差。21世纪,出现了大量基于传统机器视觉的木材检测方法。Ruz等[2]利用支持向量机对各类木材缺陷进行识别,准确率达到91%;Zhang等[3]利用主成分分析和压缩感知来识别木材缺陷;Xie等[4]针对木材本身纹理,采用灰度共生矩阵的方法来定位木材缺陷。传统的机器视觉方法通常采用人工设计的特征结合神经网络实现缺陷的检测,但是人工设计的特征总会有不足,对于新增的缺陷优化难以实现。
近年来,端到端的卷积神经网络在各种计算机视觉任务中取得了巨大的成功,包括图像分类[5-6],目标检测[7-9],语义分割[10]。缺陷检测实质属于目标检测的工业应用,文献[11]使用神经结构搜素(neural architecture search,NAS)和Mask-RCNN结合的模型对单板表面缺陷进行检测,实现了95.31%的平均精确度,一批50张图片仅需2.5 s,但采用的是组合模型的方法,模型十分复杂;文献[12]采用一种混合的全卷积神经网络对木材缺陷进行检测和定位;文献[13]使用Faster RCNN和迁移学习对木材表面缺陷进行检测,但是检测速度不能保证。
目前基于卷积网络的木材缺陷检测模型,往往存在模型复杂,参数计算量大,实时性差的问题,而且由于数据量的问题,模型泛化能力不能保证。YOLO(You look only once)算法由于检测速度和精度的优异,被广泛应用到水果质检[14],自动驾驶[15],CT图像识别[16]等领域。本文在YOLOv3的模型基础上,使用区域删除和图像混合的数据增强方法增强模型的泛化能力和鲁棒性,同时使用轻量化模型MobileNetv3来替换原网络的backbone,减少模型的参数量,方便工业嵌入式使用。最后采用COCO数据集上的评价指标,综合评价模型的性能。
1 数据集制作
使用工业相机从木材加工现场拍摄得到木材缺陷图像,将感兴趣区域提取出来,得到结节、裂缝、虫洞和无损图像各300张,总计1 200张。图像的像素为200×200,每张缺陷图片包括一个或多个缺陷。这是一个相对小型的数据集,因此采用数据增强技术来增强模型的泛化能力。通过对数据集的分析发现,数据集中没有面积大于96×96的大缺陷,只有小于32×32的小缺陷和在32×32到96×96范围的中缺陷(缺陷大小的划分参考COCO数据集),因此木梁柱的表面缺陷大小一般都属于小和中。所要识别的缺陷图像和标签如图1所示。

图1 部分缺陷图片和标签Fig.1 Partial defect pictures and labels
将得到的数据集使用labelImg软件进行标注,得到缺陷位置的信息,然后将其制作成COCO格式的数据集。在相关研究中,往往选择IOU=0.5时的Average Precision(AP)作为最终的评价指标,实践表明其不能完全反映一个检测器的性能。因此文中使用IOU=[0.5:0.05:0.95]的AP来评价模型,通过取10个IOU阈值,然后取AP的平均值,可以更全面的评价模型。
2 YOLOv3算法
YOLO[17-18]系列算法发展到现在被广泛应用的第三代YOLOv3,将目标检测作为一个端对端的回归问题,直接对锚框进行回归和分类,得到最终结果,检测速度有了大幅提升。YOLOv3的网络结构和多尺度预测如图2所示。Darknet53框架中每一个卷积部分都使用Conv2D结构,即图中的CBL部分。每次卷积后,进行标准化(Batch Normalization,BN)和Leaky ReLu激活函数处理。使用多个残差块堆叠的方式构成骨干网络Darknet53,从3个尺度预测模型输出。图2中以输入416×416为例,实际输入网络的大小从32×10至32×19中10个输入中随机选择。

图2 YOLOv3结构Fig.2 Structure of YOLOv3
3 数据增强
在图像数量获取难以达到充足和完善的工业检测领域,为避免卷积网络的严重过拟合问题,数据增强技术是解决该问题最有效的方法。本文使用随机亮度、随机对比度、随机颜色扰动、随机翻转、随机旋转、随机裁剪和添加噪声七种基本数据增强作为基本数据增强。同时使用基于区域删除的数据增强技术GridMask[19]和基于图像混合的数据增强技术MixUp[20]进一步增强网络的泛化能力。
3.1 GridMask数据增强方法
除了基本的数据增强方法,基于区域删除的数据增强方法得到了广范应用。Random Erasing[21]通过随机删除一部分区域来达到增强模型泛化能力,让模型学习到原本不敏感的信息。Cutout[22]通过删除连续的正方块区域,有效增加了数据集和部分被遮挡的样本。GridMask思想和前两种方法相同,但是前两种方法往往容易出现删除到整个目标区域的问题,所以GridMask技术通过产生一个均匀分布的掩膜来删除区域。如图3所示,通过生成一个和原图相同分辨率的掩膜(mask)图像,然后将该掩膜图与原图相乘,得到了特定区域信息删除的新图像。mask图中黑色区域值为0,表示删除区域。虚线框部分为基本的mask单元,(x,y)表示第一个mask单元离图像边缘的距离,r为保留图像的比例,d为mask单元的边长。通过删除均匀分布的正方形区域,既避免了过度删除图像中的目标信息,又避免了没有删除到目标信息而不能起到增加网络泛化能力的作用。

图3 Gridmask数据增强Fig.3 Gridmask data enhancement
3.2 图像混合增强
文献[23]中提出一种高效的图像混合方法Sample Pairing,可以将训练集规模从N扩大到N×N,将随机两副图像的像素相加求平均,而样本的标签不变。Mixup[20]从经验风险主义最小化和邻域风险主义最小化的角度出发,解释了为什么混合图像会对模型训练有效。Mixup使用方法如下:
x′=λxi+(1-λ)xj,y′=λyi+(1-λ)yj。
(1)
其中:x′,y′表示混合后的图片和标签;xi,xj代表从一个批次随机抽取的2种样本;yi,yj代表对应的标签信息。λ=beta(∝,∝)∈(0,1),∝为可以设定的参数。Mixup之后的图像如图4所示。img1、img2为批次中随机的两种图片,以λ比例混合,标签label以同样的方式混合。

图4 MixUp示例Fig.4 MixUp example
4 轻量化模型设计
YOLOv3由于其Darknet53结构多达106层的网络深度和其多尺度的设计,使用大量堆叠的残差结构,参数运算量巨大,难以在移动端嵌入,所以对其网络模型进行轻量化是必要的。常见的轻量化方法包括网络剪枝[24]、知识精馏[25]等,除此之外还包括使用高效的卷积结构来减少模型的参数量。在MobileNetV1[26]中提出深度可分离卷积(Depthwise Separable Convolution),将传统卷积分为DepthWish(DW)和PointWise(PW)两步,同时使用ReLU6作为激活函数,如图5(b)所示。标准卷积由卷积、批归一化和ReLu激活组成,MobileNetv1使用Depthwise Separable Convolution和ReLU6激活,MobileNetv2使用逆残差的线性瓶颈结构,如图5中所示。
当卷积核尺寸为DK×DK,输入特征图尺寸为DF×DF,传统卷积的计算量为F1=DK×DK×M×N×DF×DF(M、N表示输入和输出的通道数),而深度可分离卷积的计算量为F2=DK×DK×M×DF×DF+M×N×DF×DF,两者计算量之比F2/F1可由式(2)来描述。
(2)
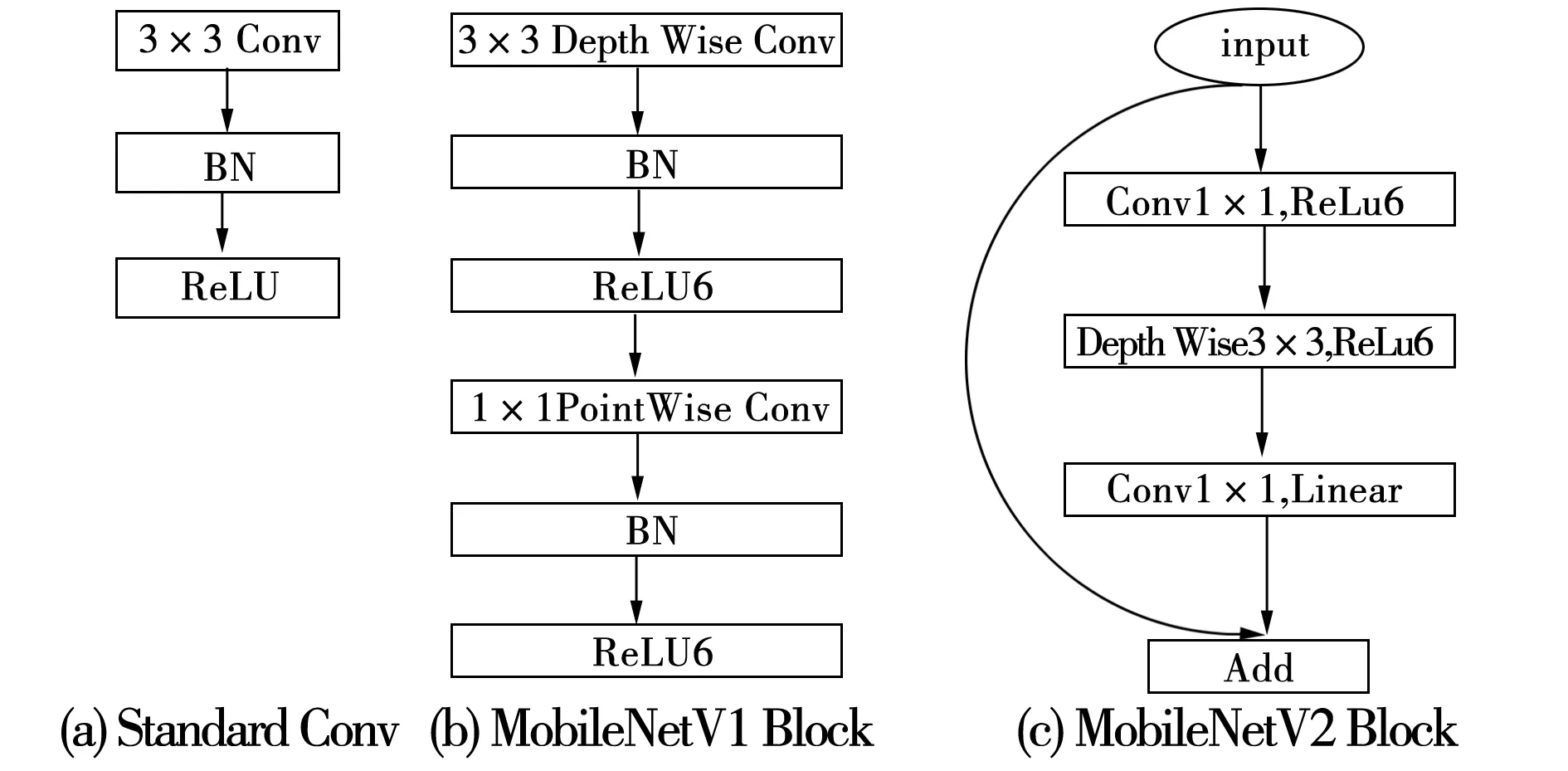
图5 标准卷积、MobileNetv1、MobileNetv1v2的基本结构Fig.5 Basic structure of standard convolution,MobileNetv1,MobileNetv1v2
MobileNetv2[27]和MobileNetv1 都是采用DW(Depth-wise)卷积搭配PW(Point-wise)卷积的方式来提取特征,但为了避免ReLU对特征的破坏。MobileNetv2在DW卷积前面加入了一个PW卷积并且在第二个PW结构使用线性激活,即线性瓶颈(Linearbottlenecks)结构。同时提出倒置残差Inverted residuals的结构,使用1×1的卷积将feature map升维,通过一个DW结构提取特征,最后再通过一个1×1卷积降维。先进行扩张再进行压缩如图6(c)所示。
MobileNetV3[28]为2019年提出,结合了前两个版本的优点,综合使用V1的深度可分离卷积和V2的具有线性瓶颈的逆残差结构,在V2的1×1卷积之后加入Squeeze-and-Excitation Networks(SE)[29]的attention模块。同时提出使用swish激活函数,可以有效地提高网络的精度,其具有无上界有下界、平滑、非单调的特性。其在模型效果上优于ReLU。Swish函数表示为:Swish[x]=x×sigmoid(βx),β为一个常量或者可训练的参数。由于swish的计算量太大,用图6中所示的H-Swish函数(hard version of swish)替代Swish激活函数,其描述如下:
(3)
ReLU是深度神经网络常用的激活函数,将负值置0,其余值保持不变;ReLU6通过抑制最大值的方式,来实现移动端高精度的应用。图6(b)为Swish和Hard-Swish激活函数。Swish激活函数的运算成本是非零的,所以用Hard-Swish来近似swish激活。

图6 激活函数的表示Fig.6 Representation of activation function
从图6(b)可以看出H-Swish无限逼近Swish函数,计算量更小,速度更快。所以选择移动端网络MobileNetv3替换Backbone,达到减少模型参数量、提高模型预测速度的目的。将YOLOv3的backbone替换成MobileNetv3的结构如图7所示。Exp size为扩展系数,SE表示是否使用SE模块,NL为激活函数,HS为Hard-Swish,RE为ReLU激活,Bneck为MobileNetv3的botteleneck,使用MobileNetv2的线性瓶颈结构,在特定层加入SE模块。
5 模型训练及实验
5.1 模型训练
所设计的木梁柱缺陷检测算法流程如图8所示,主要包括数据增强、骨干网络特征提取和检测头的检测三部分。
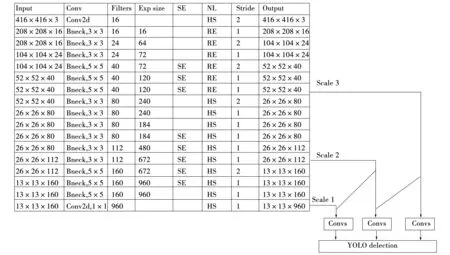
图7 backbone更换为MobileNetv3后的结构Fig.7 Structure after the backbone is replaced with MobileNetv3
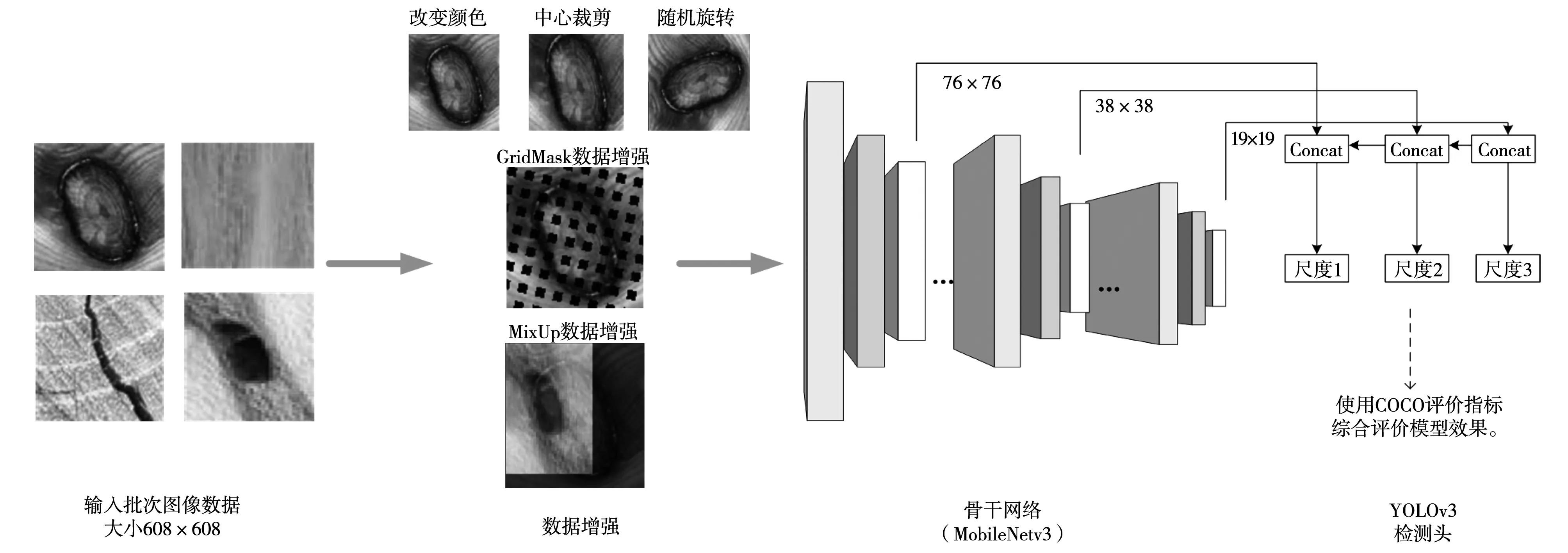
图8 算法整体流程图Fig.8 Algorithm overall flow chart
首先将收集到的缺陷图像按照8∶ 1∶ 1的比例划分训练集,验证集和测试集,制作成COCO格式。从三个尺度提取特征图像,进行融合,提取76×76,38×38,19×19三个尺度进行检测,使用COCO的评价指标来评价模型效果。采用基本的YOLOv3模型进行训练,训练时batchsize大小为8,测试时batchsize大小为1,训练时模型的输入从32×10至32×19,从10个数值中随机选择大小,测试时输入大小为608×608,每个批次中图像大小一致,使用学习率预热的方法,在两百次迭代后将学习率上升到初始学习率0.000 1大小,如图9(a)所示。总迭代次数为10 000次,在迭代次数的2/3和11/12处分别将学习率下降1/10,使用动量项为0.9的随机梯度下降方法。预热时学习率较小,模型可以慢慢趋于稳定,等模型相对稳定后在使用预定的学习率进行训练,可以使模型收敛的更快。图9(b)为训练过程的损失曲线,横轴500表示每20次迭代次数取一次数据,实线为训练集损失,虚线为验证集损失。从图中可以看出,通过数据增强后,虽然使用的是一个相对较小的数据集,模型没有出现过拟合现象,训练集和验证集的损失都是震荡下降。图9(c)、图9(d)分别为AP,AP50,在训练过程中的可视化,这里AP指的是选择IOU=[0.5:0.95]时的AP,AP50指选择IOU=0.5时的AP。可以看出YOLOv3网络AP最高达到0.41,AP50为0.83。
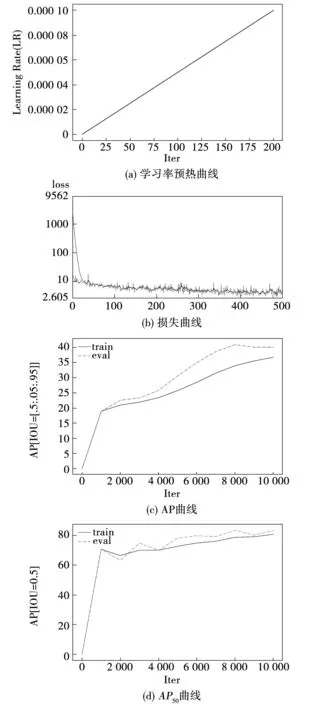
图9 训练过程的可视化Fig.9 Visualization of the training process
5.2 改进后模型实验
使用5.1中的基线模型作为对照,加入数据增强和更换backbone,在相同的实验条件下进行测试。使用python language来实现,深度学习框架为PaddlePaddle 1.84,所有的实验都是在一台配备了16G内存的NVIDIA Tesla V100 GPU上进行,使用CUDA10.0和CUDNN7.4配合GPU加速。得到表现最好的迭代次数时结果如表1所示。COCO代表使用COCO的评价指标,表1模型中,“+”代表在YOLOv3基础上使用的技术,数字编号代替本行中所用技术。S代表small object,M表示meidum object,AR为IOU=[0.5:0.95]的Average Recall,Parameter为模型的参数数量。
编号1、2、3分别为加入了MixUp,GridMask和两个同时使用时的实验数据。设置MixUp的参数λ=beta(0.2,0.2),GridMask设置概率p为0.7,随迭代次数的增加而变大,两种数据增强方法,都只在前9 000次使用,在最后1 000次停止使用,让网络微调。可以看出,加入MixUp后,AP没有变化,AP50增加了4.8%,在召回率方面均有提高,加入GridMask后,AP提升了1.4%,AP50增加了3%,两种数据增强技术同时使用时,AP增加了可观的3%,AP50达到了0.9,在APs,APM,AR,ARs,ARM均有不错的表现。
编号4为将原YOLOv3的backbone更换为MobileNetv3后的实验数据,参数数量减少了62.52%,预测速度提高了10.6FPS,同时得益于MobileNet高效的网络结构和注意力模块,模型在8个指标上均有不错的提升,其中AP50达到了0.91。不仅减少了参数数量,更提升了网络的性能。编号5、6是将数据增强技术使用到更换backbone之后的网络中,加入两种数据增强,实现了最好的模型性能,AP提升了5.9%,AP50达到了0.924实现了精度和速度的完美融合。综合来看,文中的改进效果提升显著,参数数量减少了62.52%,预测速度提高了10.6FPS,AP提升了6%,AP50提升了近10%,精度达到了92.4%。
图10为利用改进后的网络的部分检测结果,包括缺陷类型和缺陷位置。可以看出改进后的网络可以准确的识别出三种缺陷的类型,而且置信度都超过了90%。
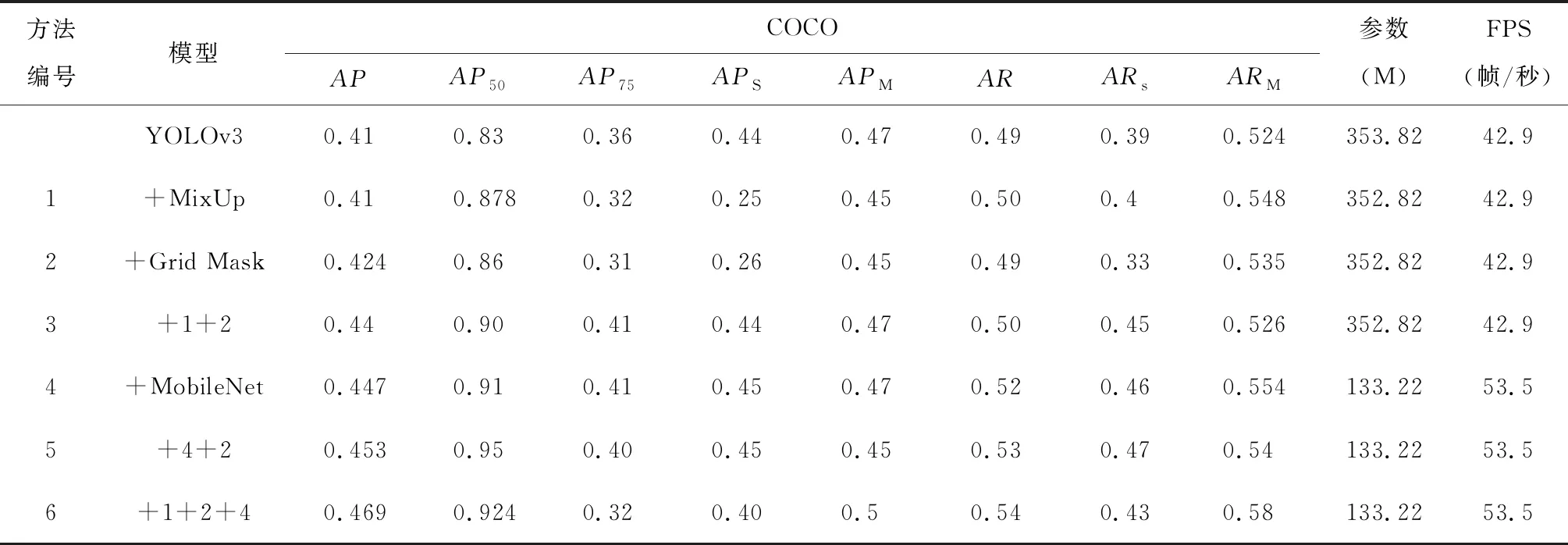
表1 使用数据增强和更换backbone的实验结果
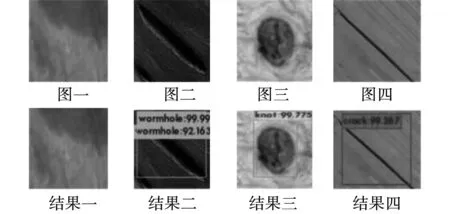
图10 部分缺陷的检测结果Fig.10 Detection results of some defects
5.3 模型参数的确定
为了找到模型最佳时的参数,在相同实验条件下,使用5.2中编号6作为基线模型,分别控制学习率(Learning Rate,LR)、批次大小(Batch Size,BS)、动量项的大小(Momentum,M)3个变量进行学习,得出的模型检测效果。
1)学习率(Learning Rate, LR),由于使用预训练模型,模型已经收敛,所以使用较小的学习率0.000 1取得了较好的结果,AP为0.47,AP50为0.92,而且采用了学习率梯度衰减的策略,后期学习率继续下降,以一个小的步长找到最优解,如图11所示(其中学习率0.000 1图例为最佳表现)。
2)批次大小(Batch Size, BS),一般在合理范围内,BS越大使得下降方向更加准确,但是过大的BS会出现局部最优的情况,太小的BS会使模型振荡,也不利于模型训练。将BS从4增加到16,在BS=4、16时模型效果明显不如BS=8、12,说明此时的模型BS太小或太大,而BS=8、12时,检测效果AP相同为0.47,但是BS=8时,AP50,AR相对BS=8时均表现更好,综合考虑选择BS=8作为最优BS。当BS=16时,模型的AP50达到了0.95,但是此时AP只有0.42,说明仅仅只以AP50作为评判标准可能是不够准确的,此时模型可能出现了局部最优的情况,如图12所示。
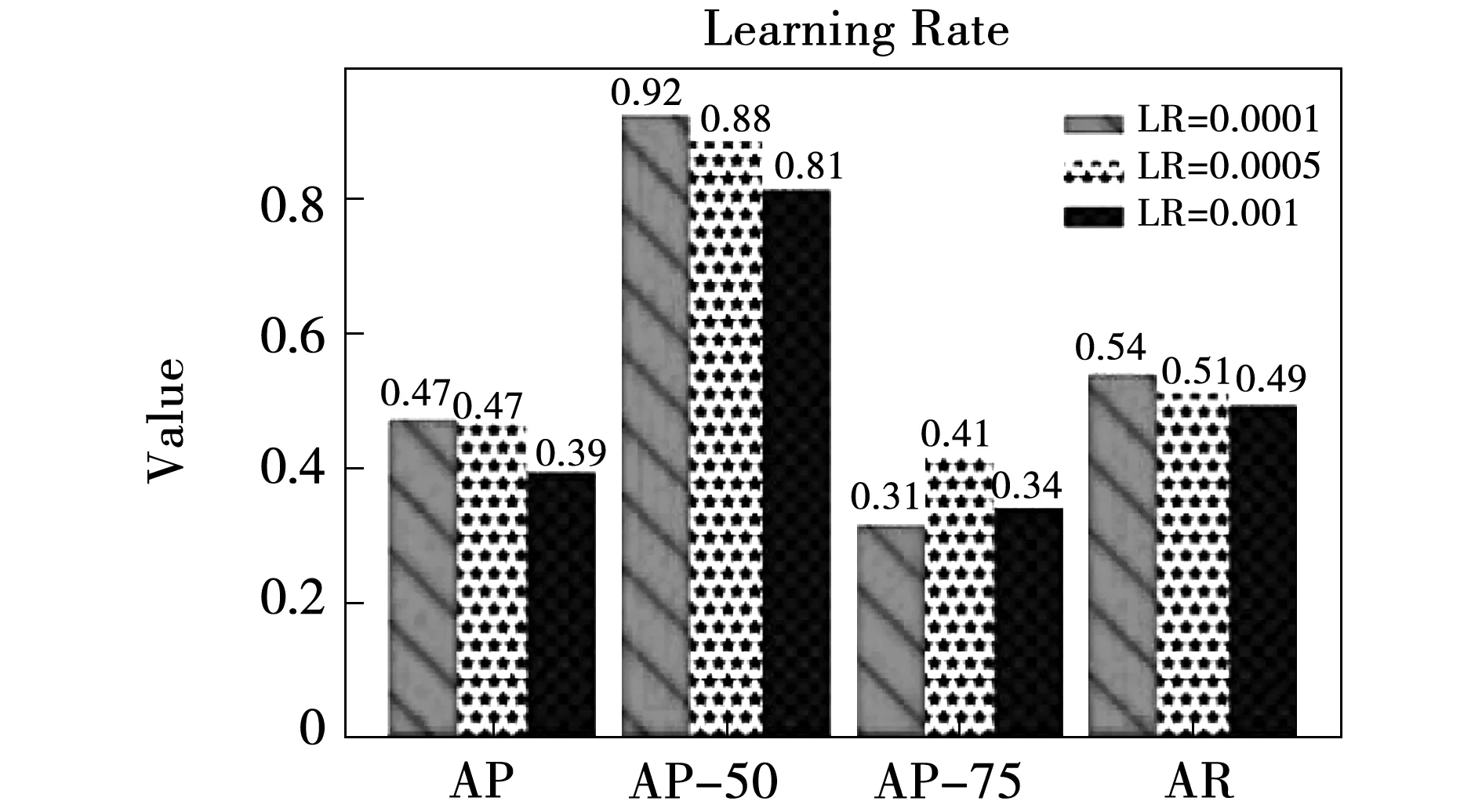
图11 随学习率变化模型的测试结果Fig.11 Test result of the model with the learning rate
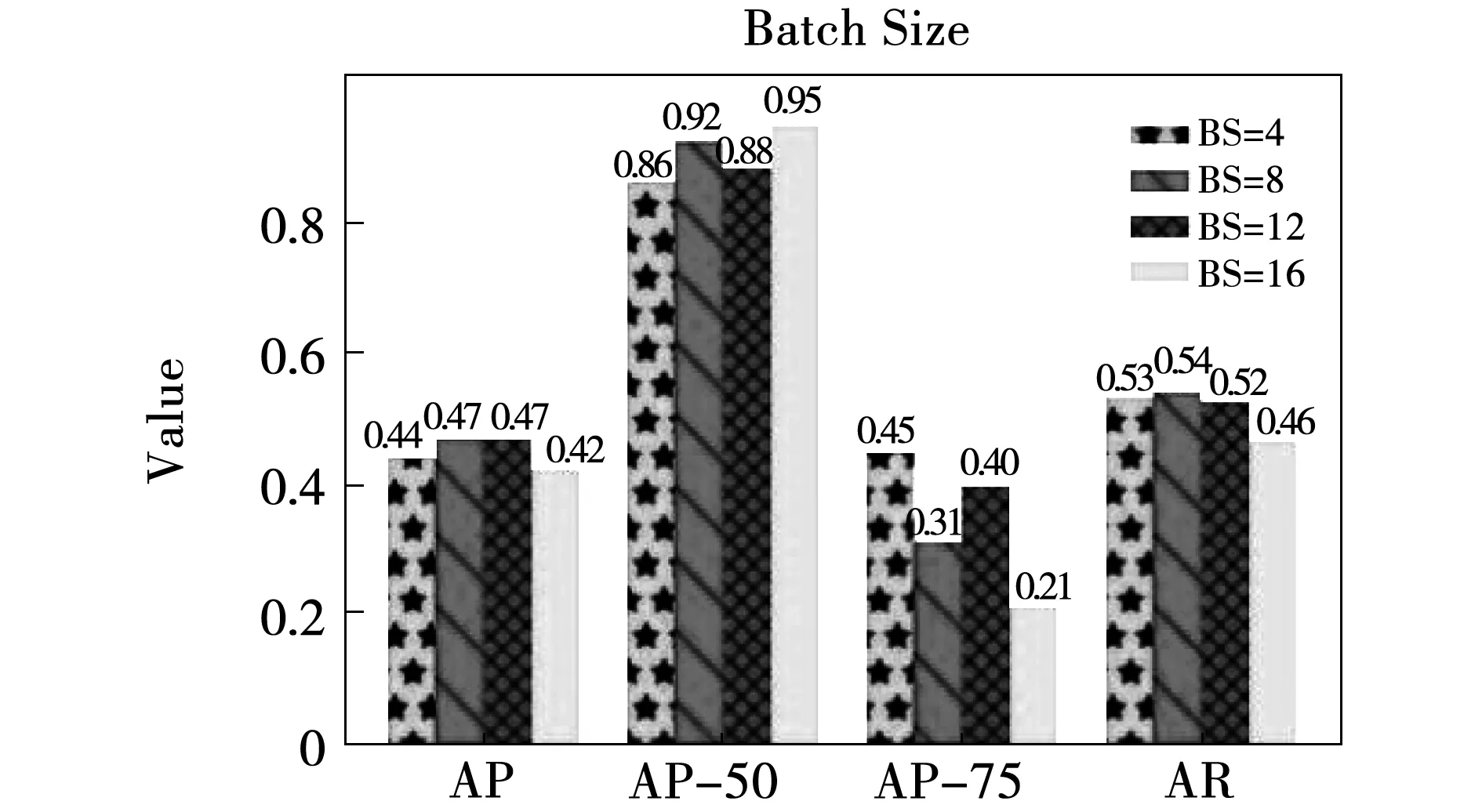
图12 随batchsize变化模型的测试结果Fig.12 Test results of the model with batchsize
3)动量项(Momentum,M)。优化器算法是深度学习中必不可少的一部分,其中Momentum由于有效性被广泛采用,M越大,就越可能摆脱局部最优的束缚。动量项从0.85上升到0.95,得到的结果如图13所示。当Momentum的值为0.9时,模型的性能最好,M=0.925时AP50达到了0.95,进一步证明使用AP而不是AP50来验证模型有效性,是很有必要的。

图13 随动量项的值变化模型的测试结果Fig.13 Test results of the model with the M value
5.4 不同网络的对比实验
为验证所设计网络的优异性,选择经典的模型作为对照组,分别选择Single Shot MultiBox Detector(SSD)[30],Faster-RCNN[7],Faster-RCNN+FPN[31]作为对照组。SSD和YOLO系列都是单阶段算法的代表,SSD分为SSD300,SSD512,输入分别是300×300,和512×512大小,使用VGG16作为backbone,在多层多尺度特征图上进行检测同时使用默认锚框的方式避免使用建议区域。
Faster RCNN先使用RPN(region proposal network)找到目标区域,然后在目标区域上进行边框回归和分类,得到目标位置和类别信息。FPN(Feature Pyramid Networks)采用金字塔结构提取融合特征,集成在Faster RCNN上实现了更好的效果。使用这四种算法和改进后的YOLOv3的测试结果如表2所示,括号里面为模型所使用的backbone。
表2给出了目标检测的几个经典网络和本文模型在数据集上测试的结果以及参数数量和预测速度,其中Faster-RCNN和Faster RCNN+FPN的预测速度都为20FPS左右,不满足工业实时检测最低30FPS的条件,因此不适合作为木材缺陷的实时检测算法。而SSD算法在预测速度上满足工业实时需要,但是表现最好的SSD300,AP也低于本文提出的算法,因此本文的算法处于绝对优势。

表2 不同网络的检测结果比较
6 实验结果分析
与使用其他方法在木梁柱表面缺陷检测方面的识别效果的比较见表3。与其他文献中的方法相比较,文中的方法在一个小型数据集上进行检测,使用更全面的评价指标,实现了46.9%的AP,92.4%的AP50,同时使用高效的轻量化模型,检测速度更具优势,在一秒内可以识别53.7张缺陷图片,实现了精度和速度的完美结合。而且参数量很小,可以实现在工业端的在线部署。

表3 检测结果比较
7 结 论
木梁柱表面缺陷的高效检测是工业木材单板生产中不可缺少的环节,只有实时准确给出木材表面缺陷信息,才能进入下一步的排样和木材加工环节。本文提出一种结合数据增强和轻量化模型的木梁柱表面缺陷自动检测和定位方法,采用数据增强和轻量化模型改进YOLOv3网络,实现了木材缺陷高精度的实时检测。使用基于区域删除技术的数据增强方法GridMask和基于图像混合的方法MixUp,来增强模型的泛化能力和鲁棒性,在一个较小的数据集上也能实现很好的检测精度。使用高效的MobileNetv3网络不仅实现了检测精度的进一步提高,而且大幅减少了模型的参数数量,提高了实时性能。最终结果表明:实现了53.5FPS的检测效率,AP为46.9%,AP50为92.3%,参数数量相比原模型减少了62.52%,完全满足工业实时木材缺陷检测的需要。此外,该方法还可以应用于数据较为稀缺的小缺陷表面检测领域。
文中的方法也为以后的工作提供了一些启发:首先使用数据增广技术是完全可以实现深度神经网络在小数据集上的识别效果,我们会继续探索使用更高效的数据增强方法,以期达到更好的效果。第二,轻量化模型是未来工业端使用的主流方向,探索实现更加高效的轻量化模型,是以后工作的重点。第三,期望木材检测方法可以直接提供缺陷的轮廓和加工方案,方便后续的缺陷处理。
猜你喜欢
建筑与预算(2024年2期)2024-03-22 06:51:36
大自然探索(2024年1期)2024-02-29 09:10:32
精密成形工程(2022年2期)2022-02-22 05:44:14
军事文摘(2021年16期)2021-11-05 08:49:06
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
智富时代(2019年2期)2019-04-18 07:44:42
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
专用汽车(2016年1期)2016-03-01 04:13:19
专用汽车(2015年4期)2015-03-01 04:09:07
