
面向对象的特征自动选择的建筑物信息提取
2021-05-18 11:27杨杰高伟段茜茜胡洋
遥感信息 2021年2期
杨杰,高伟,段茜茜,胡洋
(1.天津城建大学 地质与测绘学院,天津 300384;2.邯郸市恒达地理信息工程有限责任公司,河北 邯郸 056000)
0 引言
随着经济和社会的快速发展,各个地区的城镇化率迅速提高,在城镇化率提高的同时,建设用地占据城市土地资源的一大部分,对城市绿化及生态用地造成影响[1]。建筑物作为城市中主要的目标性地物,对其进行信息提取和目标识别会为城市管理提供准确的信息来源[2]。而面对复杂的城市结构,使用人工进行信息搜集必然会耗费大量的人力、物力且难以保证提取精度。近些年来,航天遥感向着高时间分辨率、高空间分辨率、高光谱分辨率的方向发展,为研究人员提供了高效率、高精度、低成本的地理空间数据来源[3]。高分遥感影像的出现提高了建筑物信息提取的精度,促进了各地区城市管理工作的开展。遥感影像数据的建筑物提取方法大致分为基于像元的建筑物提取和面向对象的建筑物提取2种[4]。基于像元的建筑物提取,没有考虑高分辨率遥感影像中具有丰富的地物信息,只考虑地物光谱单个特征信息,因此,利用该方法进行高分辨率遥感影像的建筑物信息提取时,容易产生椒盐现象,由于区分不同地物光谱亮度的差异不同,还会出现“同物异谱,同谱异物”的现象[5]。面向对象的建筑物提取方法全面分析地物的光谱特征、形状特征、纹理特征等多方面特征,能够在一定程度上缓解椒盐噪声和“同物异谱,同谱异物”现象的出现[6]。高分二号遥感影像具有高分特性,构建建筑物信息提取规则集时有很多特征可以应用,但是从众多特征中找到最佳的建筑物信息提取特征,构建有效的规则集是一个难题。为了解决这一问题,本文提出了一种方法。首先,依据样本采集原则采集研究区各类地物样本,创建训练集;然后,运用SEaTH算法进行特征优选;最终,自动化地确定最有效特征的阈值。这样选取的特征具有客观性和代表性,实现了建筑物信息提取特征阈值的自动化确定,加快了建立知识规则。
1 技术方法
1.1 面向对象的建筑物提取方法
面向对象的建筑物提取方法是信息提取的新思路。面向对象的建筑物提取首先将影像分割,不同影像对象特征属性不同,依据影像对象的独特性,对多个影像对象进行分类,构建合适的规则集,进行建筑物信息提取[7-8]。面向对象的建筑物提取流程如图1所示。

图1 面向对象的建筑物提取流程图
1.2 SEaTH算法的基本原理
SEaTH算法最初是为国际原子能机构基于高分辨率影像的核设施目标检测和监测提供一种自动化的方法,后来逐渐应用于高分辨率遥感影像的面向对象分类[9-11]。SEaTH算法是一种半自动化信息提取构建分类规则的方法,基于各个地物类别的样本,构建一套分类规则,用于信息提取。SEaTH算法包括特征优选和自动确定阈值2部分,在运用SEaTH算法之前首先要采集研究区的地物样本。
1)特征优选。SEaTH算法的基本思想是在依据对象特征符合其正态分布的基础上,利用J-M(distance of Jeffries-Matusita)距离来衡量地物类别之间的分离度[12],如果对象特征不符合正态分布,则该特征的分离性差,不用于分类。图2表示C1和C2基于B、A、C3个特征的分离度,依次为较差分离、部分分离和完全分离,这说明特征C用来区分C1和C2效果最好。

图2 类别C1和C2的分离度
在SEaTH算法中,衡量2个地物类别之间可分离性的一个有效手段是J-M距离。J的值域为[0,2],当J=0时,说明2个地物类别之间在某个特征上几乎都混淆;当J=2时,说明2个地物类别之间在某个特征上的分离度较好,可以完全分开[13]。然而,由于各个地物类别之间总是有一些交集,J=2的情况在实际应用中很少出现[14]。一般而言,使用最大分离度的前几个特征就可以满足信息提取的要求。J-M距离如式(1)所示。
J=2(1-e-B)
(1)
式中:B表示巴氏距离(Bhattacharyya distance),在保证各个地物的样本特征值符合正态分布的前提下,可以利用B通过错分概率的贝斯决策规则衡量2个地物类别之间的可分离性[15],C1和C22个地物类别的巴氏距离如式(2)所示。
(2)
式中:m1和m2是2个地物类别的某特征均值;σ1和σ2是2个地物类别的某特征标准差。
2)自动确定阈值。在eCognition 8.9上,利用知识规则提取地物信息需要人工反复尝试,并依据地物类别区分的目视效果不断地对阈值进行调整,最终找到合适的特征阈值。人工寻找特征阈值的方法具有效率低且易受主观因素干扰的缺点,所以寻找一种自动化的方法尤其重要。SEaTH算法不仅能够自动化地确定区别两两地物类别的最优特征,还能算出最优阈值。关于某一特征对于2个类别C1和C2的概率分布,本文采用高斯概率混合模型进行描述[16],其概率模型如式(3)所示。
p(x)=p(x|C1)p(C1)+p(x|C2)p(C2)
(3)
式中:x为随机变量;p(x)为随机变量属于C1、C2的概率;p(x|C1)、p(x|C2)分别为随机变量x在C1、C2条件下的概率;p(C1)、p(C2)分别为C1、C2的概率。
当随机变量x在C1、C2条件下的概率相同时,两两地物类别之间的混淆分类情况最少。如图3所示,当特征阈值T对应的是X1时,C1和C22个地物类别的分离性最佳。
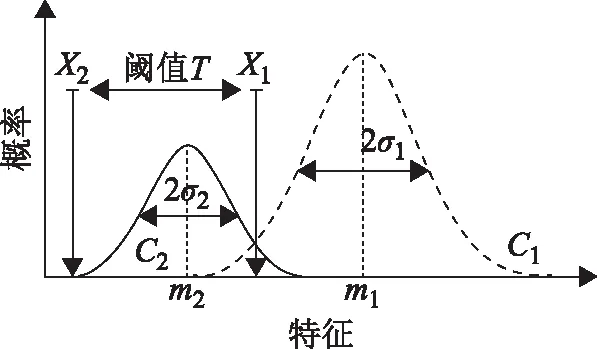
图3 C1和C2 2个地物类别的最佳分离阈值
特征阈值T的计算如式(4)、式(5)所示。
(4)
(5)
式中:n1、n2表示2个地物类别的样本数。
SEaTH算法基于样本特征值服从正态分布这一假设,所以当假设不成立时,运用此算法算出的特征阈值并不一定非常准确。因此,Marpu等[17]根据随机数据处理方法,提出了一种解决方法,再结合图3,最佳阈值T的计算规则如下。
若J≥1.75,则T′=T;
若1.25 若0.5≤J<1.25,则T′=m2; 若J<0.5,则忽略该特征值。 本文采用我国自主研发的高分二号卫星多光谱波段和全色波段的遥感数据,研究区域隶属于天津市西青区,数据大小为862像素×1 066像素。 研究区的地物类别可划分为建筑物、道路、植被、绿茵场、阴影和裸地6类。根据建筑物房顶材料的不同,研究区的建筑物可再分为3类:灰色屋顶、蓝色屋顶和红色屋顶,最终制作分类图时再将这3类并为建筑物。总体来说,研究区建筑物样式分布不规则,地物具有复杂多样性,作为研究区具有一定代表性。 1)研究区地物样本采集。训练样本的质量直接影响后续特征优选时分离度和特征阈值计算的准确性,甚至影响建筑物信息提取和建筑监测的精度。选择训练样本时应遵循以下3方面原则:①训练样本应包含研究区高分二号影像中所有的地物类型,主要包括建筑物、道路、植被、绿茵场、阴影和裸地6类地物类型;②每种地物类型的训练样本总数应与其分布面积成比例,并且均匀分布在该地物类型的区域内;③应选取地物类型分割较好的影像对象,含有混合地物的影像对象一般不选为样本。 2)训练集的创建。运用SEaTH算法构建知识规则。首先选取训练样本,并且将训练样本的特征值运用SEaTH算法进行自动确定特征优选和特征阈值。本文研究区的地物类别主要有6类,其中建筑物根据房顶材料的不同又分为了3类,根据训练样本的选取规则,以多尺度分割的结果图为基础选取各个地物类别的样本。 以各个地物类别的样本和特征为数据基础,计算出J-M距离来衡量两两地物类别之间基于某个特征的分离度,从中选出J-M距离值最大的特征。统计建筑物与所有非建筑物类别之间对应的最大J-M距离,建立建筑物的提取规则,如表1至表3所示。 表1 灰色屋顶建筑物的提取规则 表2 蓝色屋顶建筑物的提取规则 表3 红色屋顶建筑物的提取规则 表1至表3中,构建了每种建筑物子类的提取规则,所有的规则取交集提取建筑物,考虑到最终要把3种建筑物子类合并,在提取过程中只需保证提取出的是建筑物,并不一定是特别纯的建筑物子类。蓝色屋顶建筑物与植被和道路的最优特征都是Ratio_layer3,那么使用这个特征时,规则为Ratio_layer3≤0.210,其他地类亦是如此。 基于SEaTH算法建立知识规则,并将灰色屋顶、蓝色屋顶、红色屋顶的建筑物合并,得到建筑物信息初提取结果,如图4所示。 图4 建筑物初提取结果 在建筑物初提取结果中,存在一些细碎的噪声,这些细碎的斑点区域并不是建筑物,可以通过初提取结果中各个建筑物的像素数目进行判断。当小于某值时,则判断不是建筑物,并将这个小斑块过滤掉。 建筑物初提取结果中,建筑物的轮廓不够平滑和规整,本文基于像素对象调整进行建筑物边缘的平滑,进一步对初提取结果进行优化,其主要思路为:①遍历建筑物的轮廓;②设置建筑物轮廓在X、Y和Z方向上的像素值,形成一个大小为N×N的像素窗口,N为奇数,本文将X和Y都设置为5,Z设置为1;③设置一个阈值V,当像素窗口中建筑物部分所占比例大于V时,则该中心像素隶属于建筑物,本文将V设置为0.5。基于像素对象调整算法的示意图如图5所示。 图5 基于像素对象调整算法的示意图 将建筑物初提取结果进行优化后的影像如图6所示,优化后的建筑物轮廓得到了平滑,更加接近建筑物的轮廓,局部对比如图7所示。 图6 优化提取结果图 图7 优化前后局部对比 在遥感分类效果评价方法中,混淆矩阵是常用的一种方法[18],该方法将影像分类结果与地表真实信息进行对比,且单个混淆矩阵中可以显示影像分类结果精度[19],如式(6)所示。 (6) 式中:n表示类别数;mij表示i类像素被分到j类中的像素总数;mii表示正确分类数。当混淆矩阵对角线上的元素值越大时,分类精度越高;反之,分类精度越低。 分类精度的指标主要包括总体精度、Kappa系数、生产者精度、用户精度、Hellden精度和Short精度[20]。其中,Hellden精度是生产者精度和用户精度的调和平均值,可以作为综合考量生产者精度和用户精度的指标。 本文还应用了面向对象的最邻近分类法对建筑物进行了提取。为确保提取结果的可比性,使用同一分割尺度参数,并将初提取结果运用于像素对象调整的方法进行优化(图8)。 图8 建筑物提取结果比较 在ArcGIS中,根据遥感数据并参照天地图采集建筑物和非建筑物的样本点用于精度评定。针对本文数据,本文算法和基于面向对象的最邻近分类法的精度评定的混淆矩阵分别如表4和表5所示。 表4 基于本文方法的精度评价 由图8可知,基于面向对象的最邻近分类法将部分本该是道路的影像区域错分为建筑物,还存在建筑物漏分现象,而本文方法的错分和漏分现象相比较少。由表4和表5可以得出,本文方法的总体精度和Kappa精度都要高于基于面向对象的最邻近分类方法。 表5 基于最邻近分类法的精度评价 本文基于高分二号遥感数据,结合研究区的地物类别和建筑物房顶材料的不同特征,通过运用面向对象的分类方法和SEaTH算法的原理,构建建筑物提取规则,进行建筑物信息初提取及优化建筑物轮廓。精度验证表明:本文方法的总精度为87.29%、Kappa精度为74.63%,与基于面向对象的最邻近分类法相比,总精度提高了10.17%、Kappa精度提高了20.29%,表明本文方法在建筑物信息提取方面具有一定的可行性。2 数据来源与数据处理
2.1 数据来源
2.2 数据处理
2.3 基于SEaTH算法的建筑物信息提取知识规则




3 提取结果优化
3.1 小斑块处理
3.2 建筑物轮廓优化



4 精度评价
4.1 精度评价指标
4.2 精度评价实验



5 结束语
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
铁道建筑技术(2021年4期)2021-07-21
小学生学习指导(低年级)(2019年9期)2019-09-25
红领巾·萌芽(2019年8期)2019-08-27
电测与仪表(2017年24期)2017-12-19
中国与非洲(法文版)(2017年10期)2017-11-23
CHIP新电脑(2016年3期)2016-03-10
现代计算机(2016年12期)2016-02-28
小天使·二年级语数英综合(2015年12期)2015-12-04
中国交通信息化(2015年6期)2015-06-06
