
深度辨别性增强网络高分影像语义分割
2021-05-18 11:27刘艳飞丁乐乐孟凡效孙叔民
遥感信息 2021年2期
刘艳飞,丁乐乐,孟凡效,孙叔民
(1.天津市勘察设计院集团有限公司,天津 300000;2.万方星图(北京)数码科技有限公司,北京 102218)
0 引言
随着对地观测技术的快速发展,高分辨率遥感影像已经可以大量获取,为地理国情普查、精细农业、环境监测等提供了坚实的数据基础。相较于中低分辨率遥感,高分辨率遥感呈现了更加精细的空间细节信息[1-3],使得遥感地物目标的精细识别成为可能。然而随着空间分辨率的提高,高分辨率影像也面临着可用波段少、地物目标可变性大等问题,为其分类带来了挑战[4]。如何提取有效特征提高地物识别精度已经成为当前高分辨率遥感影像处理领域的研究热点之一。目前高分辨率遥感影像已经发展出了基于频谱变换的分类方法[5]、基于条件随机场的方法[6-7]、面向对象的分类方法[8-10]等。如Zhao等[11]利用面向对象的方法对条件随机场的分类结果进行融合,提高了高分辨率遥感影像分类结果。Li等[12]将面向对象用于地表覆盖提取,获得了比基于像素的方法更高的分类精度。然而以上方法都需要人工设计特征,特征设计过程依赖专家先验知识,且特征表达能力有限。
深度学习作为一种数据驱动的模型方法,可以有效地从数据中自动学习特征,无需专家先验,已经被成功应用于道路提取、建筑物提取[13]、目标检测[14-15]、场景分类[16-17]等领域。如Lu等[18]通过构建多任务卷积神经网络同时提取道路和道路中心线,利用任务之间的相关性来提高道路提取精度。为融合多层卷积特征,Mou等[19]提出空间关联模块和通道关联模块用于构建深度卷积网络模型,学习、推理任意2个空间位置或特征图之间的全局关系,提取关系增强特征。Tong等[20]利用网络迁移技术采用已经在其他数据集上经过预训练的网络作为初始化参数进行微调训练,获得了比传统方法更优的语义分割精度。
相较于传统方法,基于卷积神经网络的高分辨率影像分割方法已经取得了更优的语义分割效果,但是由于高分辨率遥感影像中存在同类地物方差增大、类间方差减小的问题,利用深度卷积神经网络进行高分辨率影像语义分割仍然面临分类混淆的问题。针对这一问题,本文提出了基于深度辨别性增强网络的高分辨率影像语义分割算法(discriminability improved convolutional neural networks,DICNN),用于提高深度特征的可辨别能力。在DICNN中,在传统分类器Softmax的基础上加入相似度惩罚因子,使得同类像素样本特征向量向其类别中心靠近,从而增加深度特征的可辨别性。
1 基于卷积神经网络的高分辨率影像语义分割
传统卷积神经网络主要包含卷积层、池化层、全连接层等构成单元。卷积层、池化层用于提取局部特征,全连接层对卷积层和池化层得到的局部特征进行聚集,获得全局特征。然而将卷积神经网络用于高分辨率影像语义分割时,需要分类的对象是像素,即基于卷积神经网络的高分辨率影像语义分割是像素级别的分类,一般不需要影像全局特征。同时,为了保证输入数据和输出数据的大小一致,需要将全连接层从卷积神经网络中剔除。图1为基于卷积神经网络的高分辨率影像语义分割的基本流程,主要包括数据预处理、深度特征提取和分类3个部分。

图1 基于卷积神经网络的高分辨率影像语义分割一般流程图
数据预处理阶段主要指归一化处理,使像素值落在某一区间。本文将每一像素除以255,使其落在[0,1]区间。
深度特征提取阶段对输入的图像通过卷积、池化等操作进行逐层特征提取。在利用卷积层和池化层进行特征提取阶段会造成细节信息的丢失,为保证影像细节信息,提高分类精度,目前已经发展出了Unet、D-LinkNet[21]、HRNet[22]等网络模型。
分类部分负责输出像素分类分布概率,常用Softmax作为分类器。Softmax作为二元逻辑回归的扩展,主要用于多元分类。对于一个具有n个类别的分类任务,分类器Softmax输出n元向量,每一元素代表待分类样本属于某一类的概率。
卷积神经网络的训练过程分为前向与后向阶段。前向阶段主要包括预处理计算、特征提取和分类概率预测。后向阶段是根据分类器Softmax计算损失误差,然后利用链式求导法则进行梯度计算和网络参数更新。高分辨率遥感影像往往呈现出同类地物方差大、类间方差小的问题,限制了基于深度卷积神经网络高分影像语义分割的进一步提升。针对这个问题,本文提出了深度辨别性增强网络用于高分辨率遥感影像语义分割。在分析了基于卷积神经网络语义分割原理的基础上,在分类器Softmax中加入相似度惩罚因子,使得像素样本对应的特征向其类别中心靠拢,增加特征辨别性,进而提升基于卷积神经网络的高分辨率语义分割精度。
2 基于深度辨别性增强网络的高分辨率影像语义分割
为提高深度特征的可辨别性,本文提出了基于深度辨别性增强网络的高分辨率影像语义分割分类方法,其训练流程图如图2所示,主要包括数据预处理、深度特征提取、相似度计算、最小化损失函数计算4个部分。
设卷积神经网络中每一层的输出为zl∈RHl×Wl×Cl,其中l为每一层网络的序列号。对一个具有L层的网络来说,l的取值为1至L。Hl、Wl和Cl分别代表该层网络输出特征图的行、列和通道数。记输入影像为z0∈RH0×W0×C0,其中H0、W0和C0分别为输入影像的行、列以及通道数,在本文中使用RGB三通道影像,因此C0为3,输入影像大小设置为300像素×300像素,因此H0和W0都设置为300。
在数据预处理阶段,本文将原始高分辨率影像像素值除以255使其落在[0,1]区间,同时为了增加数据的多样性对其进行随机左右翻转以及镜像等操作,之后将经过上述处理的数据输入到深度网络中进行特征提取。
在特征提取阶段,本文采用HRNet用于高分辨率遥感影像特征提取,其网络结构如图3所示。HRNet包含4个网络分支用于提取不同尺度的特征,在最后一层将多尺度特征进行叠加融合,其基本构成主要包括卷积层和上采样层。
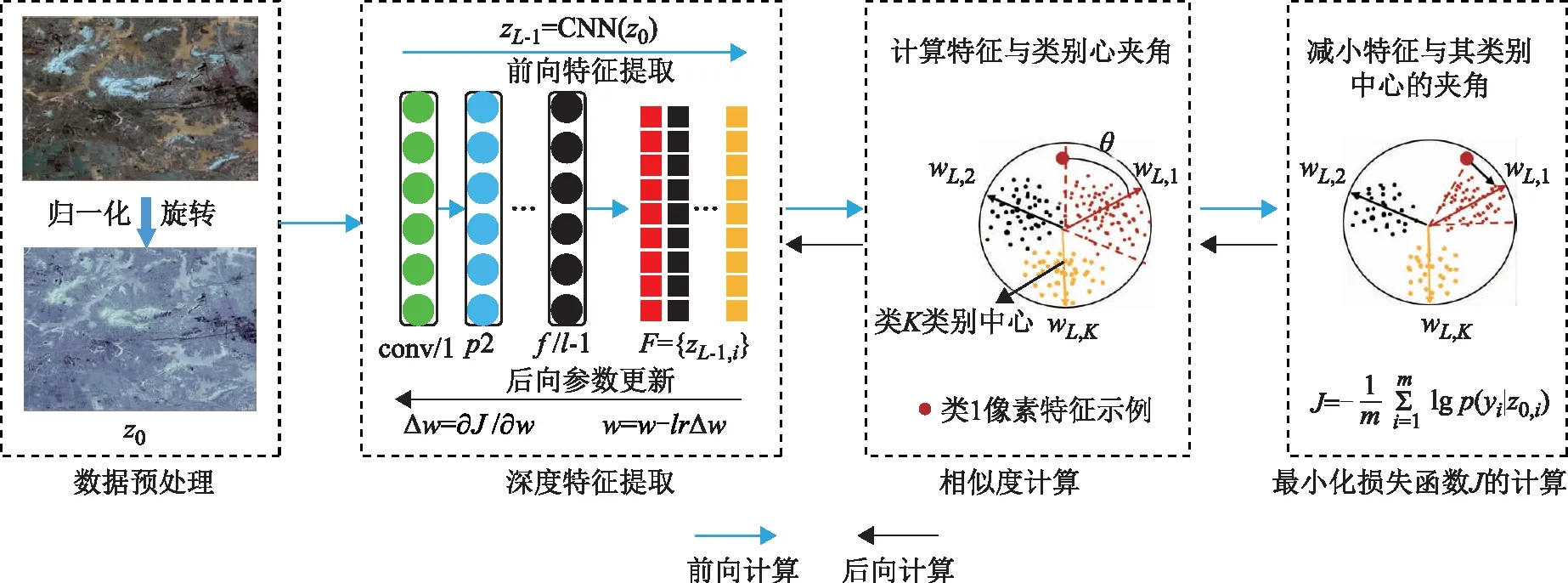
图2 基于深度辨别性增强网络的高分影像语义分割训练流程图
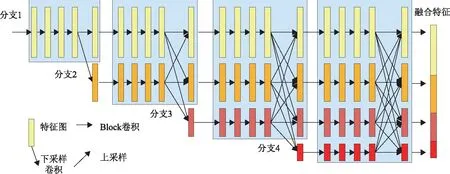
图3 本文采用网络HRNet
对于第l层卷积网络,假设其输入数据为zl-1∈RHl-1×Wl-1×Cl-1(Hl-1、Wl-1和Cl-1分别代表输入数据的行、列以及通道数),具有Cl个卷积核,其第s个卷积核为wl,s∈Rker×ker×Cl-1(ker为卷积核的大小),则该卷积层的卷积过程可表达为式(1)。
al,s=zl-1*wl,s+bs
(1)
zl,s=f(al,s)
(2)
式中:bs表示卷积核wl,s对应的偏置;al,s表示卷积核wl,s对应的卷积结果。式(1)表达的函数为线性函数,为增加模型的复杂度,将非线性函数f(·)作用于卷积计算结果al,k,得到该卷积核对应的最终输出结果zl,k。假设该卷积层卷积核移动步长为str,则该卷积层的输出特征图zl的行Hl和列Wl可由式(3)、式(4)得到。
Hl=(Hl-1-ker)/str+1
(3)
Wl=(Wl-1-ker)/str+1
(4)
由式(3)、式(4)可知,通过设置卷积核移动步长在特征提取过程中会造成数据空间维度的减小,为使得特征图和原始输入影像具有相同空间尺度,往往会采用上采样对特征图进行空间维度的扩展。常采用的上采样层包括反卷积、插值法等。HRNet利用双线性差值来恢复特征图的空间维度。卷积神经网络通过叠加卷积层、上采样层等网络来逐层地获得每一个像素对应的深度特征向量。
在经过深度特征提取阶段之后,HRNet利用Softmax对提取到的特征进行分类。假设采用的卷积神经网络一共有L层,第L层网络为分类器Softmax,其分类过程如式(5)所示。
(5)
式中:z0,i表示输入影像第i个像素;p(k|z0,i)表示样本像素z0,i属于k类的概率(k=1,2,…n);wL,t为Softmax中t类对应的参数向量;zL-1,i为像素z0,i在第L-1层网络输出的深度特征。
通过分析式(5)可知,Softmax分类过程本质是一个相似度计算过程,其通过计算像素z0,i的特征向量zL-1,i与每一类的参数向量wL,t的内积作为相似度来判断像素z0,i属于类别,因此每一类的参数向量wL,t可以看做该类对应的类别中心。当每一类的参数向量wL,t的模相等时,其分类过程如图4(a)所示。此时,待分类像素的深度特征与类别中心的内积相似度转化为比较像素的高维深度特征与每一类的类别中心的夹角,即通过计算待分类像素的深度特征与类别中心的夹角来判断其类别。在图4(a)中,因为特征点zL-1,i与类别中心wL,1的夹角θi,1最小,小于与其他类别中心wL,2、wL,K的夹角θi,2和θi,K,所以像素z0,i被分为1类。此时,Softmax变为式(6)。
(6)
式中:Sc为类别中心向量wL,t与像素z0,i的深度特征向量模的乘积,即Sc=|wL,t|·|zL-1,i|;θt,i代表二者之间的夹角。
因此,为增加深度特征的可辨别性,使得同类像素的深度特征向其对应的类别中心靠拢,本文将Softmax中类别中心wL,t与像素的深度特征之间的夹角作为相似度度量,加入一个夹角惩罚因子β,迫使在训练阶段,训练样本与其对应的类别中心之间具有更小的角度。因此在相似度计算阶段,本文首先计算特征向量与类别中心wL,t的夹角(式(7))。
θt,i=arcos(wL,t·zL-1,i)
(7)
式中:θt,i代表像素i的特征向量zL-1,i与类t的类别中心wL,t之间的夹角。对于任一像素z0,i,假设其类别为t,由式(7)导出其属于类t的概率,如式(8)所示。
(8)
式中:β为惩罚因子。
在损失计算阶段,根据最大似然法则使得分类概率最大,则得到分类损失函数J,如式(9)所示。
(9)
式中:m为参与训练的像素样本个数;yi为像素i的类别。在最小化式(9)时,为取得最小值,损失函数会更加倾向于迫使该类样本向其类别中心移动,使得夹角更小,以弥补惩罚因子β本身带来的角度增加量,如图4(b)所示。对比图4(a)与图4(b)可知,通过式(6)和式(8)分别计算2个图中像素z0,i属于类1的概率,在二者得到相同概率时,图4(b)中像素z0,i与类别中心wL,1的夹角比图4(a)中夹角小(差值为β)。因此在训练阶段,可利用式(8)代替式(6),使得像素样本特征向其对应的类别中心靠拢。本文在实验部分对β的取值进行了分析。
在训练阶段,通过交替执行前向运算、后向运算更新网络参数。在后向阶段,本文采用梯度下降算法对网络参数更新,如式(10)所示。
(10)
式中:w代表卷积神经网络中的各层参数;lr为学习率,用于控制网络参数更新的步长。
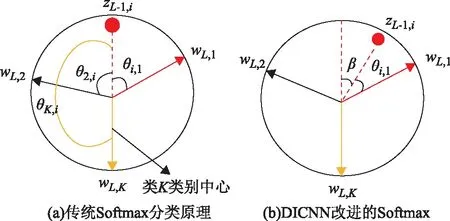
图4 传统Softmax与DICNN改进的Softmax分类原理
3 实验与分析
3.1 实验设置
为验证提出算法的有效性,采用2个数据集进行实验。数据集1为高分二号数据集GID[20],包含建筑物、农田、森林、草地和水域5个类别,有150张影像,每张大小为6 800像素×7 200像素。在实验中随机抽取120张影像用于训练,剩余30张用于测试。数据集2为The SpaceNet Buildings数据集,该数据集主要用于建筑物提取,大小为650像素×650像素。本文选取上海和拉斯维加斯2个城市的建筑物数据,分别从这2个城市选取60%(5 059张影像)作为训练集,剩余的40%(3 374张影像)作为测试集。图5为实验数据代表样本。本文利用HRNet作为特征提取网络,在这个网络的基础上施加所提出的角度惩罚项进行实验,并将HRNet作为对比方法验证所提方法的有效性。
为了使网络获得一个较好的初始化,首先,在cityscapes数据集[23]上对HRNet网络进行预训练,获得一个较好的参数初始化结果;然后,在实验数据集上进行网络微调。对数据集1,采用Kappa系数、总体精度OA和生产者精度作为评价指标。对数据集2,采用准确率Precession、召回率Recall以及F1 Score作为评价指标。

图5 实验数据示例样本
3.2 实验结果与分析
1) 数据集1。表1给出了HRNet以及本文所提出的DICNN在β=0.5时于GID上的分割结果。从表1可以看出,本文提出的方法相较于对比方法HRNet,Kappa系数提高了1.8,总体精度OA提高了1.3,而且在建筑、农田、森林、草地、水域等类别相较于对比方法均有所提高,在农田和水域2个类别上精度提高明显,分别有1.4和2.3的提升。
图6给出了HRNet和DICNN在GID上的分类混淆矩阵。从混淆矩阵可以看出,DICNN降低了农田错分为水域和水域错分为森林的比例,将农田错分为水域的比例由2.35降至0.9,将水域错分为森林的比例由4.37降至1.33。然而,DICNN同时也增加了草地错分为农田的比例,将其比例由1.7扩大至3.67,这可能是因为在训练数据集中农田的数据样本多于其他类别,呈现出数据不平衡现象,而利用DICNN的损失函数相较于HRNet中采用的Softmax对样本不平衡更敏感。图7给出了2种方法在GID数据集上的分类结果可视化对比。从图7的第一行可以看出,相较于HRNet,DICNN减少了草地错分为森林的现象,在区域1、2、3、4得到更纯净的分类结果。在第二行中HRNet将部分农田错分为水域,而DICNN减少了该类错分,在区域1和区域2完全消除了农田错分为水域的现象,在区域3也有部分消除。
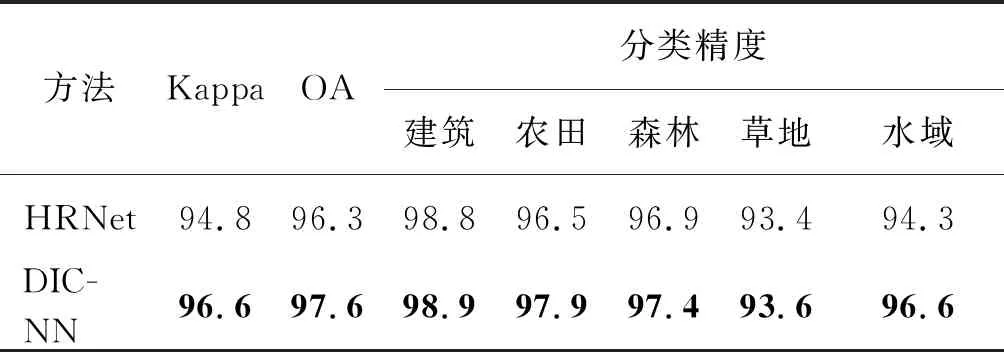
表1 数据集1分割结果评价表 %
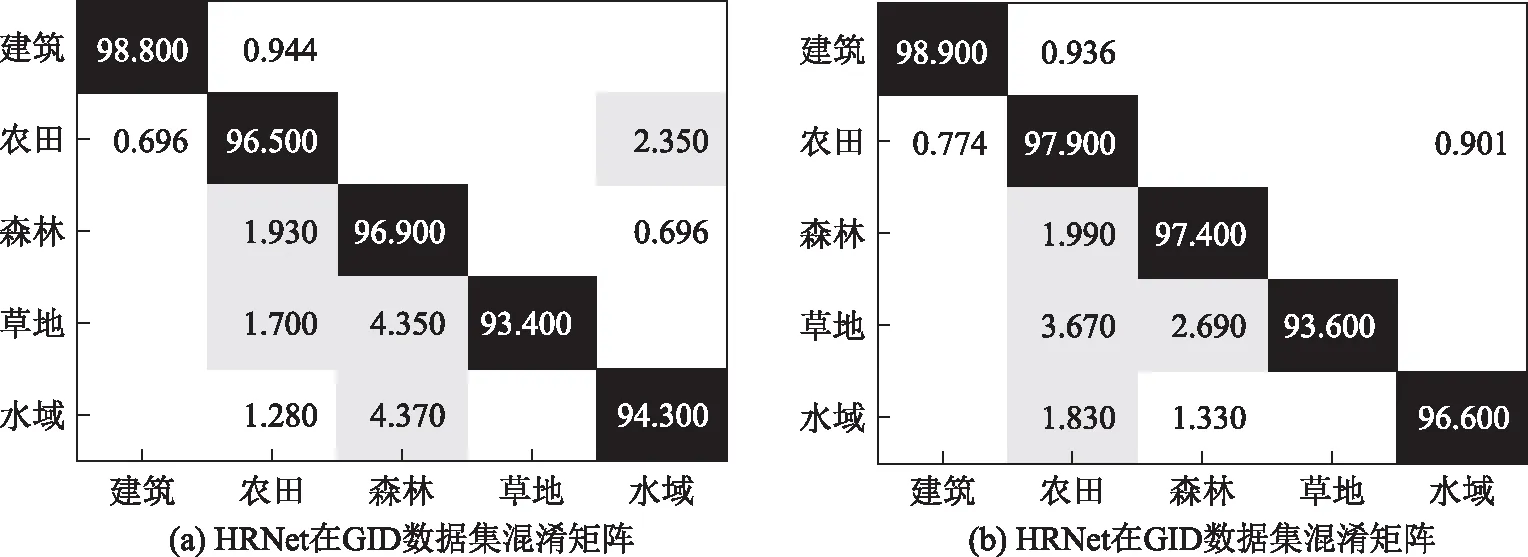
图6 HRNet和DICNN在GID数据集上混淆矩阵
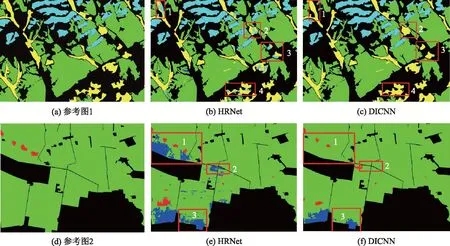
图7 DICNN与HRNet在数据集1上的分类结果可视化对比
2)数据集2。数据集2包含上海、巴黎、拉斯维加斯和喀土穆等地区的建筑物目标。本文选用上海和拉斯维加斯2个城市的图像作为实验数据进行验证。表2给出了HRNet和DICNN在β=0.3时于数据集2上的实验结果。从表2可以看出,DICNN在准确率Precession、召回率Recall以及F1 Score 3个评价指标上均高于HRNet。相较于HRNet,DICNN在准确率Precession、召回率Recall以及F1 Score 3个指标上分别提高1.7、1.3和1.6,证明了其在提高特征辨别性方面的有效性。
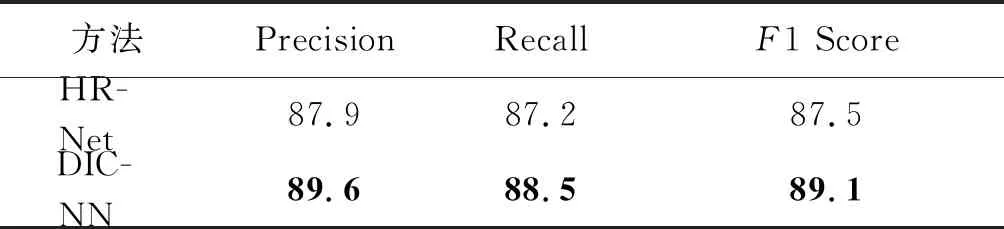
表2 数据集2分割结果评价 %
图8给出了HRNet和DICNN在数据集2上的可视化分割结果。对于图8中的区域1、区域3,HRNet将背景区域错分为建筑,而DICNN有效地消除了这一错分现象。对于区域4,HRNet无法将建筑正确识别,造成遗漏,而DICNN识别出了部分区域,消除了部分遗漏。对于区域2,HRNet和DICNN都错误地将背景错分为了建筑,可能是因为区域2对应的影像与建筑过于相似,无法有效识别。另外,从图8可以看出,与2个参考图相比,基于HRNet和DICNN预测的建筑在边界区域的分割效果不理想,这主要是因为卷积神经网络采用卷积和池化的操作,造成空间信息的丢失,使得网络最后的分割结果无法精确定位物体的边界信息。在以后的工作中应当考虑加入边界约束,改善预测结果的边界。
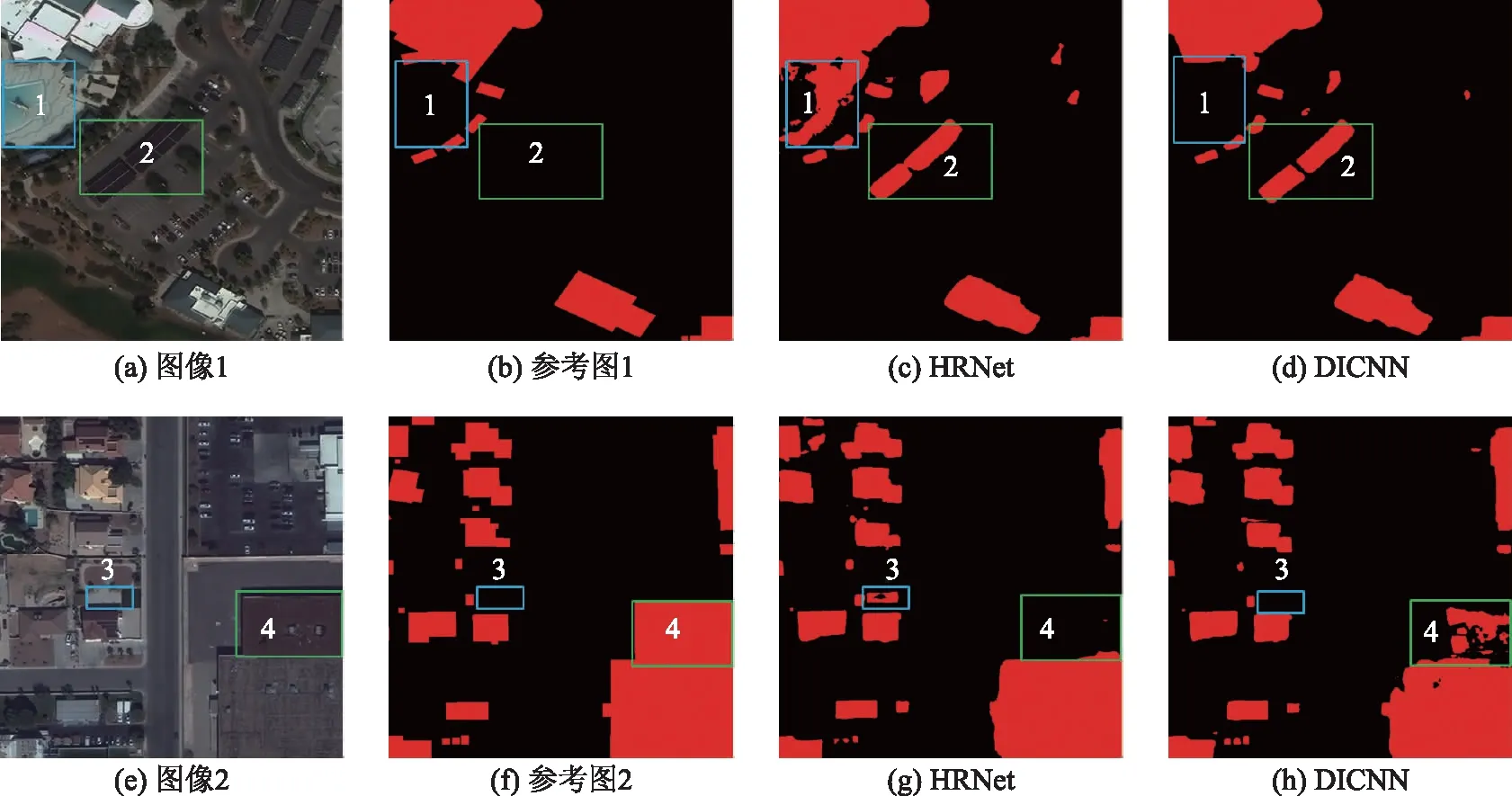
图8 HRNet和DICNN在数据集2上的分割结果对比
3.3 参数分析

图9 β不同取值时DICNN在2个数据集上的分割结果变化
在DICNN方法中,夹角惩罚项β决定了像素特征向其类别中心靠拢的程度,即决定了所学特征的辨别性。为研究β对遥感影像语义分割的精度影响,分别令β取值{0.1,0.3,0.5,0.7,1.0,1.2}进行分析。图9给出了DICNN在β不同取值下,在2个数据集上的精度变化。从图9可以看出,对于数据集1,在β从0.1增加至0.5的过程中,分割精度不断提升,在β=0.5时取得最优值,随后随着β的继续增加,分割精度不断下降。对于数据集2,指数Precision在β从0.1升至1.3的过程中不断下降,指数F1 Score于β为0.3时取得最大值。当β从0.1升至0.7时,Recall增加,随后随着β的继续增加而下降。
4 结束语
当卷积神经网络用于高分辨率遥感影像语义分割时,高分辨率影像所呈现出的类间方差小、类内方差大的问题,往往会造成错分。针对这一问题,本文在Softmax的基础上引入夹角惩罚项,使得同类像素样本特征向量向其类别中心靠近,增加深度特征的可辨别性,提高高分辨率遥感影像语义分割的精度。在GID和The SpaceNet Buildings 2个数据集上,本文所提出的算法分别将语义分割评价指标Kappa和F1 Score 提高1.8和1.6,证明了其有效性。然而,所提出的方法在类别不平衡和边缘保持方面表现不佳。在未来的研究中将考虑通过自适应加权技术解决类别不平衡问题。针对分割边缘不完整的问题,将考虑在初步语义分割结果的基础上,利用边缘提取技术对语义分割图进行约束优化,获得完整分割边缘。
猜你喜欢
雷达学报(2020年3期)2020-07-13
开放教育研究(2020年2期)2020-03-31
现代语文(2016年21期)2016-05-25
新校长(2016年8期)2016-01-10
太空探索(2015年8期)2015-07-18
浙江大学学报(工学版)(2015年1期)2015-03-01
大连民族大学学报(2015年2期)2015-02-27
航天返回与遥感(2014年4期)2014-07-31
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
