
用于组态软件实时数据库的快速数据定位算法研究
2021-05-18 06:05:56宫护震
西安工程大学学报 2021年2期
宫护震
(1.西安理工大学 计算机科学与工程学院,陕西 西安 710048;2.陕西国防工业职业技术学院 计算机与软件学院,陕西 西安 710302)
0 引 言
实时数据库是自动化系统的核心,也是新一代系统标准化和组件化的关键技术之一[1],其基础功能包括数据储存、数据查询和访问控制[2]。
目前,国内的有关学者应用实时数字仿真系统(real time digital simulation system,RTDS)与ADSC机制相结合的方式设计了实时数据库的分布式存储方法[3],将主动机制加到实时数据库中,在实时数据库中有规律性地对实时数据进行分布式存储,并利用PLC的选择性控制储存过程。文献[4]设计了一种应用遗传算法和实时数据库规则结合的数据库查询优化方案,在分析嵌入式实时数据系统的基础上,建立实时数据查询处理系统,并基于内存数据库建立RTQP关系系统实现查询处理。文献[5]基于量化行为的实时数据库备份系统访问控制模型则引入了量化属性及信任度的概念,使用量化函数动态量化数据属性,并为访问行为分配相应的信任度,从而判断是否将特定权限授权给该访问行为。
随着数据储存、数据查询和访问控制技术的革新,实时数据库的储存和管理能力也在不断增强,一种应用组态软件的实时数据库得以广泛应用。组态软件是一种能够对数据进行监测、控制与处理的系统开发工具,用户在应用过程中需要对数据库中的数据进行快速提取与识别,提升系统的运行效率[6]。由于组态软件的数据体系较为庞大,用户在应用的过程中仅仅依靠组态软件的本身运行能力已经难以满足对数据的提取需求。因此,相关的数据定位算法应运而生。
文献[7]在极大似然估计的基础上,将主动探测与被动截获协同过程相结合,对数据展开融合定位。文献[8]首先计算初始锚点与定位目标数据的距离,然后利用加速度计和陀螺仪解算姿态阵和位置,结合无迹卡尔曼滤波器实现数据融合定位。然而上述算法主要通过周期性的操作对数据库中的数据进行定位,需借助判断控制才能实现定位,导致最终的数据定位效果差。文献[9]基于数据库隐蔽数据密度分析结果,利用增量子空间数据挖掘算法计算数据流之间的相关度,从而获取待定位的数据,再采用融合异构异质定位方法将数据信息转换到相同的区域内实现信息融合,再结合蜂窝融合定位算法实现数据高效定位。然而在该算法的实现过程中,各步骤难以独立运行,导致该算法在运行过程中需要耗费大量的空间资源。
为此,本文基于Web设计了新的组态软件实时数据库快速数据定位算法,旨在改善传统定位算法中存在的定位效果差、运行空间不足的问题。
1 定位算法设计
1.1 基于Web的数据快速采集
若想实现组态软件实时数据库快速数据定位,首先要解决数据的采集问题。只有具备一定量的数据储存才能够实现快速数据定位的功能。
数据采集指标主要根据组态软件实时数据库的吞吐量和数据传输的平衡性能设定,2个影响因素与数据传输协议之间存在着密切关联性。因此,在数据快速采集网络拓扑结构的基础上,为了提升数据采集指标的精准度与快捷性,应用S-XNQ2数据采集协议对数据进行分配和采集。S-XNQ2数据采集协议能够快速将数据中的信息划分为多帧的形式,在便于数据传输的同时,还能够以周期性的形式间接从数据库中提取数据,从而减少数据采集的能耗和对系统空间资源的占用率[10]。然后将多帧数据打包分配给传输平台,再将数据资源以最小量的形式分配给不同的网络链路,避免因链路拥塞而降低数据采集的速度。
在Web环境下,组态软件实时数据库数据采集过程常出现吞吐量不平衡的现象[11-12]。为解决这一问题,本文利用MKL-30算法降低数据采集过程的不平衡程度。MKL-30算法在实时数据库中建立通信协议,应用通信协议向数据包传达数据调度指令,使数据有更多的机会接触到不同采集途径,并随着网络节点的移动而改变快速数据的储存地点,进而有效平衡了数据在实时数据库中的储存位置。疏散密度较高的储存位置后,可使实时数据库中的数据吞吐量逐渐恢复至平衡状态。MKL-30算法主要通过建立网络节点的效用函数来实现,并引入拉格朗日变换原理计算数据在组态软件实时数据库中的平衡采集规律。效用函数F可表示为
F=∂vL/n
(1)
式中:L为网络中数据帧的长度;∂为效用函数在不同快速数据采集链路中的参数,且∂∈(0,1];v为不同链路中数据传输的平均速率;n为数据采集链路数量,且n=1,2,…,i。在此基础上,利用效用函数得到组态软件实时数据库中的数据采集结果X,可表示为
(2)
式中:s为网络节点数量;Xn为链路中待采集的数据。根据式(2)可以计算出网络链路中数据采集的效用函数,据此实现数据采集,可有效节省数据采集过程的运行空间,减小对系统资源的占用率。
1.2 数据特征分析
组态软件实时数据库能够为用户提供数据采集、数据提取、数据储存等服务,以Web形式向实时数据库中发送的数据可表现为图片、文字、音频等多种格式。同时,组态软件实时数据库还为用户提供数据访问端口等服务,支持实时数据库数据的恢复、备份等操作,满足各行业对数据高容量的需求[13-14]。
在Web环境下,组态软件实时数据库必须具备数据部署灵活、数据层次清晰等功能。为了对实时数据库中的数据展开快速定位,必须要分析数据特征及其运行流程[15-17]。首先,采用TCP协议实时压缩并传输数据,节省数据提取的过程中所占用的网络内存,最后,应用网络数据访问端口初步分析实时数据库中现存的数据类型,根据数据的不同类型选择相应的数据压缩方式与传输途径。
组态软件实时数据库中数据共包括4种特征类型,分别为Int32(形式为储存符号,帧长为1 B)、Int64(其中不含符号,帧长为6 B)、Bolb(形式为字符格式,帧长为8 B)、Strting(用于数据储存,帧长为500 B)。在确定数据的类型后可以实现对数据的精准查找与统计,用户可以查询的形式向组态软件发送查询请求,实时数据库做出相关反应并对查询信息进行同步备份,并保存查询记录。为有效实现数据备份,应用专业的备份软件Veritas,根据实时数据库资源基础制定相应的备份流程。Veritas备份软件工作原理简单、运行稳定性高,还能够实现数据逆方向备份,将目标数据直接储存到实时数据库中并完成格式转换。
1.3 快速数据定位
在Web环境下,为实现对组态软件实时数据库中数据的快速定位,本文设计链路测距定位算法来降低节点之间的链路距离,通过坐标的变化来简化传统的距离测量算法,构造新型的距离测量矩阵与序列[18-19],再通过减小测量距离的误差来提高定位精确度,使得数据通过最短链路从而实现数据定位。
假设基于Web的组态软件中具有A个网络节点,分别为A1,A2,A3,…,AI,…,AN,网络节点均位于三维空间坐标中,节点中数据的标识可以被其他系统的硬件设备快速检测到,能够存在于所有具备坐标矩阵的数据检测器序列中。数据检测器测得的节点距离即为节点自身位置与检测器位置间的距离。三维空间中的矩阵能够从不同的角度获取同一节点到另一节点之间的距离,通过获取其平均值来缩小单独测量距离的误差[20-21]。对数据的精准定位需要提取节点中的信息,并集中到下一个网络节点,在这个集合了大量数据的节点中实现快速数据定位。在三维空间中将所有的节点平移,假设坐标系中的坐标原点为x0,快速数据检测器的数量为M,则网络节点中数据之间的评价距离D可表示为
D=[(dAN-AN-1+dAN-1-AN-2+…+dA3-A2+
dA2-A1-x0)N]/M
(3)
由于测量距离结果存在误差,因此需要在三维坐标系中快速将数据中的相关性向高维空间扩展,方便融入大量的实时数据。为此,取不同类型的数据特征值进行特征向量对比,从而确定数据在高维坐标系中的相对位置[22],为最终的数据定位奠定基础。
综上,得到数据定位流程如下:将数据资源分配到数据采集网络链路、测量数据距离、获取平均误差、高维空间扩展、特征对比、确定数据相对位置。
2 实验与结果分析
实验过程中,需判断节点测距技术接收到的信号强弱程度,利用信号的强弱程度改变节点测距的测量范围。本文基于Matlab平台完成实验,并采用26 GHz射频数据处理芯片。设定组态软件实时数据库的运行电流损耗为32 mA,数据提取的过程中电流损耗为30 mA。在实验过程中,网络节点的距离平均值会随着实时数据库中信道传输质量的改变而改变,如图1所示为节点距离与信道质量的关系(信道质量可通过信号强度来表示)。
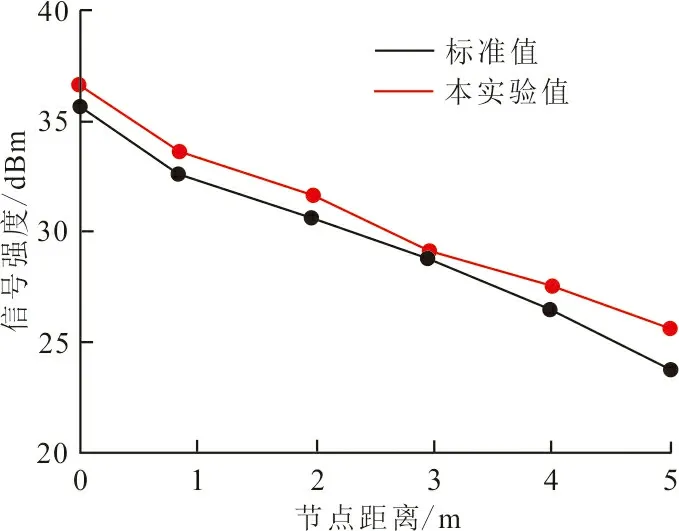
图1 节点距离与信道质量的关系图Fig.1 Relationship between node distance and channel quality
一般来说,随着节点间距离的增加,信号强度会有所减弱,信道质量也会随之减弱。从图1可以看出,本次实验中,节点距离与信道质量的关系接近于理想值,可保证实验结果的有效性。
实验过程中的网络节点与三维空间中的检测器存在着脉动波动信号,检测器与范围内的节点距离越远,则两者信道之间产生的脉冲信号越弱。该实验在以节点为中心的1 m2、2 m2、3 m2范围内的信号强度进行测量,周期性地识别检测器内部信号格式的变化情况。如图2所示为不同范围内的节点脉冲信号随时间的变化而发生的波动。
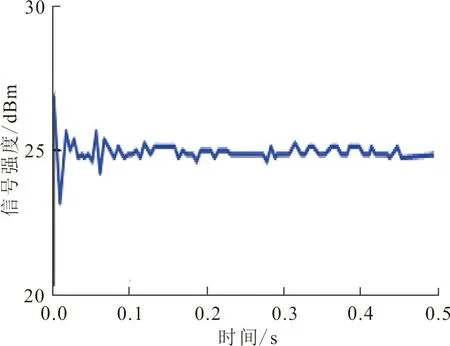
(a)1 m2范围内波动图
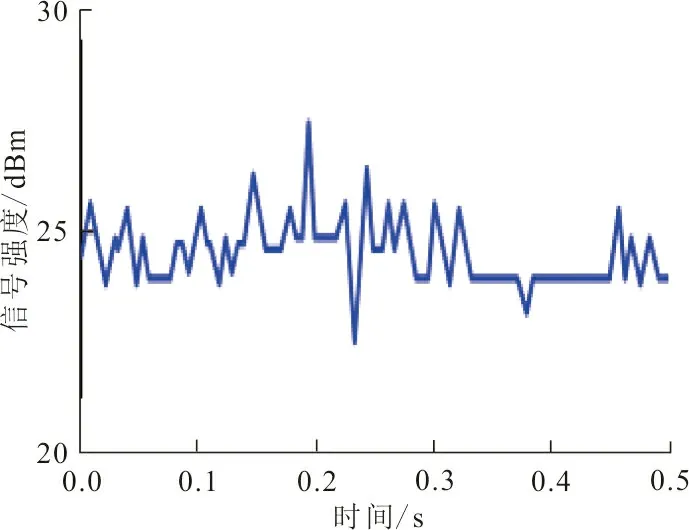
(b)2 m2范围内波动图
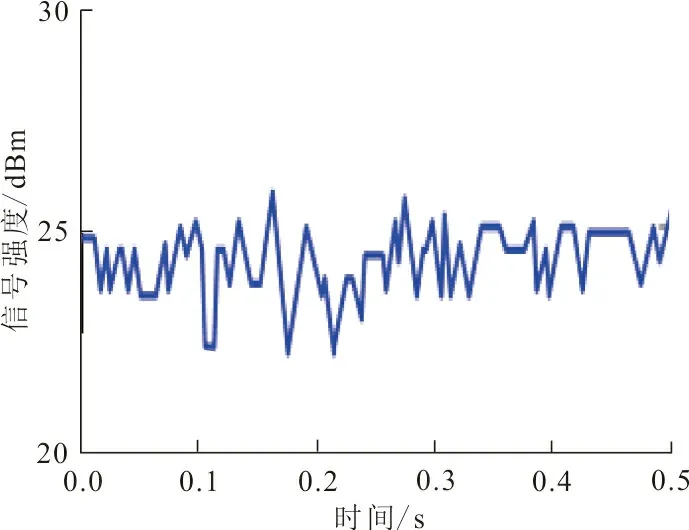
(c)3 m2范围内波动图图 2 节点脉冲信号随时间变化的波动图Fig.2 The fluctuation diagram of the node pulse signal changing with time
根据图2可知,不同范围内的节点脉冲信号随时间的变化而发生的波动较为平稳,信号强度基本维持在25 dBm左右,可保证实验结果的有效性。
在上述环境设定及检验的基础上,设组态软件实时数据库的整体范围在20 m×20 m区域内,在数据库辐射区域内随机标记20个待定位数据节点,利用本文算法对其展开快速定位。
为避免实验结果的单一性,将传统的基于主动探测与被动截获协同的数据融合定位算法和基于无迹卡尔曼滤波的数据融合定位算法作为对比算法,与本文算法共同完成性能验证,得到相同时间内,不同算法对标记数据的定位结构如图3所示。图3中,红色圆圈代表有效定位的数据,绿色圆圈代表未能准确定位的数据。
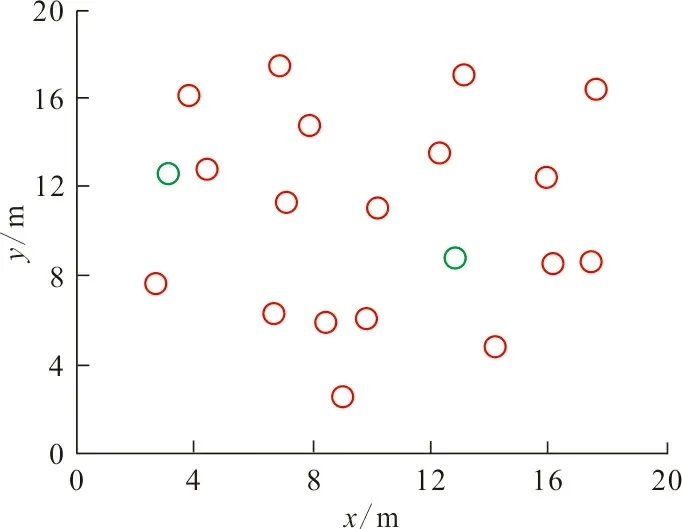
(a)本文算法
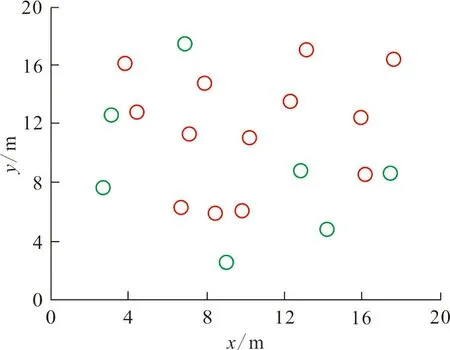
(b)基于主动探测与被动截获协同的算法

(c)基于无迹卡尔曼滤波的算法图 3 不同算法的数据有效定位数量比较Fig.3 Comparison of effective location quantity of data under different algorithms
从图3可以看出,在相同的运行时间内,本文算法能够有效定位标记18个数据节点,而基于主动探测与被动截获协同的算法和基于无迹卡尔曼滤波的算法分别标记了12、10个数据节点。这是因为本文算法应用了专业的数据检测技术,并通过坐标的变化来简化传统的距离测量算法,通过减小测量距离的误差来提高定位准确度,增强定位效果。
在此基础上,以定位过程空间资源占用率为检验指标,对不同算法的性能加以验证,经实验测试可知,随着测试时间的增加,不同算法定位过程空间资源占用率也在不断变化。本文算法的定位过程空间资源占用率介于6.0%~8.5%,而基于主动探测与被动截获协同的数据融合定位算法的空间资源占用率介于10.0%~12.0%,基于无迹卡尔曼滤波的数据融合定位算法的空间资源占用率介于13.0%~15.0%。这是因为本文算法应用S-XNQ2数据采集协议对数据进行采集,在方便数据对外传输的同时还能够以周期性的形式从数据库间接提取数据,从而减少了数据采集的能耗和对系统空间资源的占用率。
3 结 语
数据定位技术已经逐渐地从军事领域拓展到民用环境中,但是这种技术的实现对网络环境的要求较高,且需要能够具有高效性的算法来匹配相应的数据处理过程。为此,本文基于Web环境设计了组态软件实时数据库快速数据定位算法,实现了实时数据的高效、快速采集,并对具有特征的数据进行分析,最终实现数据准确定位。在研究中发现,应用S-XNQ2数据采集协议能够在方便数据对外传输的同时,周期性地从数据库间接提取数据,从而有效减少了数据采集能耗,还缓解了对空间资源的占用情况。在接下来的研究中,将考虑提高算法定位过程的时效性,从而实现对算法的进一步优化。
猜你喜欢
纺织科学研究(2023年9期)2023-10-23 11:18:10
移动通信(2021年5期)2021-10-25 11:41:48
河北农机(2020年10期)2020-12-14 03:13:42
魅力中国(2019年6期)2019-07-21 07:12:10
凿岩机械气动工具(2017年2期)2017-07-19 10:21:13
工业设计(2016年11期)2016-04-16 02:49:22
中国铸造装备与技术(2015年5期)2015-12-10 10:23:41
武汉理工大学学报(交通科学与工程版)(2015年5期)2015-12-05 02:19:55
中国交通信息化(2014年3期)2014-06-05 03:07:09
自动化与仪表(2014年10期)2014-02-26 08:21:17
