
面向功能信息的相似专利动态聚类混合模型
2021-05-14 03:57马建红张少光曹文斌王晨曦
计算机应用与软件 2021年5期
马建红 张少光 曹文斌 王晨曦
(河北工业大学人工智能与数据科学学院 天津 300401)
0 引 言
科技创新在某种意义上来说即为功能的创新,利用相关的聚类技术可以将各个行业中的专利进行基于功能的自动聚类,有利于研究人员便捷地获取相关技术领域中的集成专利信息,帮助他们了解当前最新技术的发展趋势,提高企业的自助研发能力和企业竞争力,具有重要的现实意义。
近年来,为了打破专利的限制,提升自身的创新能力和竞争力,研究人员在专利领域开展了大量研究,并产出了大量的研究成果。江屏等[1]利用专利自身原有的结构化信息,利用国际专利分类号(International Patent Classification,IPC)聚类分析和当前领域相关技术成熟度结合,从而有效地确定了待规避的专利群和专利规避目标,突破创新,对打破专利壁垒具有重大意义。功能的创新进而引起产品技术的变革,陈旭等[2]将专利处理为技术功效对的形式,利用聚类技术,对技术功效矩阵进行聚类,能够清楚地了解当前的技术热点和研发热点,为研究人员指明了技术创新方向。这些方法主要是应用统计学模型进行的专利聚类,如词袋法和词频-逆文档频率,它们都舍弃了文本中大量的语义信息,并且存在步骤繁杂、聚类时间较长等缺点。
目前,深度学习算法在自然语言处理领域中取得了十分出色的成果,将深度学习应用到专利领域也逐渐成为一种趋势。有研究人员开始将词向量[3]引入到专利文本表示方面,很好地弥补了传统算法在表达词语和语义方面上的不足,挖掘出了词语与词语之间更深层次的联系,取得了不错的效果。Lee等[4]以最新的BERT模型为基础,对模型进行微调,之后利用其进行专利分类。由于卷积神经网络(Convolution Neural Network, CNN)具有很好的学习复杂、高维和非线性映射关系的能力,所以结合CNN和词嵌入的方法进行实验,实验分类效果得到很大提升。循环神经网络(Recurrent Neural Network, RNN)能够有效地利用序列数据的序列信息,但是记忆能力因为距离的增长而变得越来越弱,存在梯度爆炸和梯度消失等相关问题。循环神经网络的变体——长短期记忆网络[5](Long Short-Term Memory, LSTM)能够解决因距离而导致的依赖问题。Xiao等[6]建立了基于Word2vec和LSTM的分类模型,提取专利文本的序列化特征,学习序列之间更深层次的关系,能够更好地对专利进行分类。近年来,注意力机制逐渐成为深度学习领域研究的一个热点,被大量应用于QA 、情感分析、句子级别摘要[7]等方面,都获得了不错的效果。与此同时,注意力机制也在专利领域进行了应用,马建红等[8]利用长短期记忆网络与基于注意力机制联合双向LSTM相结合提取专利特征,进行专利文本分类,准确率也达到了70%以上。
传统的特征提取和聚类过程通常是分开执行的,许多研究倾向于特征提取[9-10]或者聚类算法的研究[11]。针对以上问题,本文结合深度学习技术,提出多角度特征提取(Multiple Angle Feature, MAF)混合模型,其能够融合功能信息对专利进行动态聚类,在聚类过程中动态调整网络参数以获得更好的性能。
1 MAF动态聚类混合模型框架
本文提出的模型框架图如图1所示。首先对专利文本进行前期预处理工作,包括数据清洗、分词去除停用词等相关操作;然后标注出专利文本中的功能语句,经过MAF混合模型提取出专利文本的特征表示;最终利用K-means算法对专利文本进行基于功能的聚类。为了优化网络结构和获得最好的聚类效果,可以将聚类结果的倒置轮廓系数的对数视为神经网络的损失函数,以共同优化特征提取和聚类过程中的参数,通过调整网络损失函数实现动态聚类。
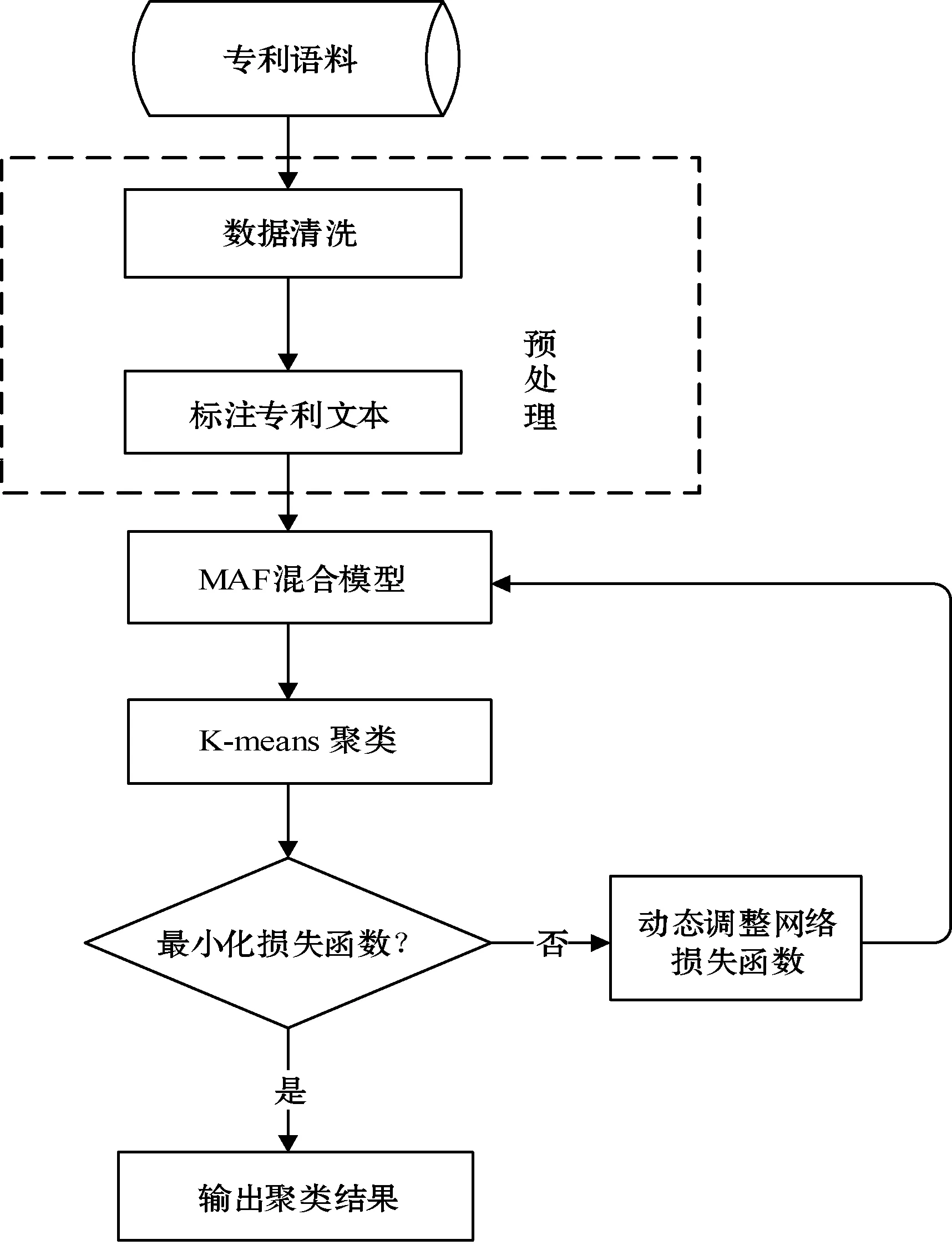
图1 模型框架图
2 模型设计
2.1 预处理
本文使用的原始语料是专利的摘要和标题,在语料处理方面,本实验采用结巴分词对专利文本进行分词,此外为了增加分词的准确性,百度百科条目也被添加到系统的同义词库中。例如“有利于石墨烯规模化生产”进行分词后,得到“有利于 石墨烯 规模化 生产”。同时为了避免向量冗余,需要对文档进行停用词处理。
接下来进行标注工作,对于不是功能信息句的专利语句标注0,例如“0 将 金属 镁粉 装入 管式 高温炉 内”,该语句并没有表达出任何功能信息。将功能信息句分为9类,例如将“提高 生产效率”“适宜 大规模 生产”“有利于 规模化 生产”等归为一类。
2.2 MAF混合模型
MAF混合模型结构如图2所示。底层主要是专利文本的向量化表示。中间层主要由深层语义表示和功能词语关注两部分组成。其中深层语义表示部分由双向长短期记忆网络联合注意力机制(BiLSTM-Attention)部分、CNN卷积神经网络部分、改进的权值潜在狄利克雷分布(Weight Latent Dirichlet Allocation,WLDA)主题提取部分,来共同学习专利文本的深层语义。功能词语关注部分使用注意力机制加强对重点功能词语的关注,最后采用并行融合的方式对特征向量进行融合,构造全局特征向量,作为聚类实验的输入。
2.3 词嵌入
词嵌入是将文本中的每个词表示为空间中低维、稠密的向量。在当今自然语言处理的各项任务中,它能够包含更多的词与词之间的含义,相对于基于传统的TF-IDF词频向量或者LSA潜在语义向量效果更好,更适用于进行深度的语义挖掘工作。
Word2vec是谷歌在2013年提出的词嵌入训练方法。作为一种无监督学习方式,它可以从大量文本语料中以无监督的方式学习文本的语义知识。通过一个语义空间使得语义上相似的词语在该空间内距离很近[12-13]。为了充分利用专利文本的信息,扩充词向量的表示能力,本文最终使用Skip-Gram[14-15]方式来训练,得到200维的词向量。
2.4 MAF提取功能信息特征
考虑到功能信息句长度和数量的限制,不能仅仅通过词频、词性等特征进行聚类,本文结合深度学习的方式提取了功能信息句的各种特征,最终的特征表示如下所示:
Vsemantic=VB⊕VC⊕VWL
(1)
VK=[Vsemantic,VAtt]
(2)
式中:VK代表聚类的输入;Vsemantic表示深层语义特征;VAtt代表功能词语特征;VB代表序列特征;VC代表文本嵌入特征;VML代表主题特征。
2.4.1深层语义表示
(1) BiLSTM-Attention提取序列特征。长短期记忆网络是在RNN的基础上进行改进的,它以RNN为基础加入了门的思想,由输入门、遗忘门、输出门和一个cell单元组成。通过门的输入、遗忘和输出来保持和更新细胞状态,从而有效地克服了RNN在训练过程中出现的梯度消失和梯度爆炸的问题。本文需要结合功能信息句的上下文特征,因此采用BiLSTM提取上下文的信息,这种结构考虑了序列的双向特征,极大地改进了功能信息句的语义表达。针对当前语句内的第i个词,BiLSTM抽取的特征向量为:
xi=(Cl(xi),Cr(xi))
(3)
式中:Cl(xi)是xi左边的专利文本向量;Cr(xi)是xi右边的专利文本向量。
在功能信息句中,每个词对于类别的贡献度也是不同的,例如“用于对酒精浓度的检测”“提高了Cu微晶的耐热性能”等,就需要特别关注“酒精浓度”“检测”“提高”“耐热性”等词语,在BiLSTM层后面增加注意力层[16]可以进一步地提取专利文本之间更深层次的信息。
(4)
式中:ai为每个词语的注意力权重。
(2) CNN提取嵌入特征。CNN在语义建模方面和特征提取方面都有着良好的表现和突破[17-18]。结合专利文本特性,本文需要提取功能信息句序列信息的不同嵌入特征。考虑到卷积核能够捕获文本信息的局部特征,拥有可并行化、运行速度快等优点,本文将不同的局部特征进行整合,得到功能信息句的嵌入特征。CNN首先输入向量化的专利功能信息句,之后是卷积层和池化层,本文采用的是最大池化,对每个卷积核窗口内的输入向量选取最大值构成新向量,公式如下:
C=max{Ci}
(5)
Z={C1,C2,…,Ct}
(6)
式中:t为卷积核的数量,在训练期间,为了防止过拟合现象以及加快训练速度加入了Dropout层,可以屏蔽部分隐层神经元。最后是全连接层,全连接层是把以前的局部特征通过权值矩阵进行重新组装,最终输出CNN文本嵌入特征向量。
(3) WLDA提取主题特征。当前大部分的概率主题模型都以LDA[19]构建的主题模型为基础,它是一个典型的由文档、主题和词汇构成的三层贝叶斯概率生成模型,主要包含文档-主题及主题-词汇这两个狄利克雷-多项式共轭结构。利用LDA可以从文档中发现潜在主题,并使用主题的概率分布描述整个文档,挖掘文档更深层的含义。
陈磊等[20]利用Word2vec词向量与LDA词向量相结合的方式进行主题特征抽取。本文在其基础上,改进了特征抽取的方式:将每个主题的前h个高概率词语作为子集表示主题,然后将它们的概率重新调整为词语的权重;对主题词进行归一化处理,即每个词占主题的权重,将主题词映射到Word2vec向量空间中;测量每个文档到主题的余弦距离,以便获得距离分布,然后将它们的距离重新调整为文档到主题的权重,权重与主题向量的乘积即是WLDA特征向量。
文档集D={d1,d2,…,dn},文档中所有词为{w1,w2,…,wm},训练文档集D,LDA输出主题集{t1,t2,…,tT}下每个词语的概率,第i个词对主题tj的贡献度为θij,使用Word2vec训练文档集D得到每个词语固定维数的空间向量。对于每个主题向量,使用前h个高概率词语表示,同时每个主题下的词语概率被调整为权重,并将主题词映射到向量空间中,公式如下:
(7)
(8)
式中:ωij表示第i个主题下第j个词的权重;v(wz)表示词wz训练后的词向量;v(ti)代表第i个主题在词向量空间下的坐标。接下来计算每篇文档与主题的距离,对距离进行归一化处理得到TDi,将TDi作为主题向量的权重值,则每篇文档的主题特征向量VWL的计算公式如下:
VWL=TDiv(ti)
(9)
(10)
式中:dti表示文档到主题i的距离。
2.4.2功能词语关注层
对功能信息句进行特征提取的过程中,由于句子中包含的词数较少,难以提取关键信息。关键词语对功能聚类十分重要,为了加强这些功能词语在聚类中的作用,本文采用注意力机制直接从词向量的基础上学习每个词的权重分类效果,如表1所示。
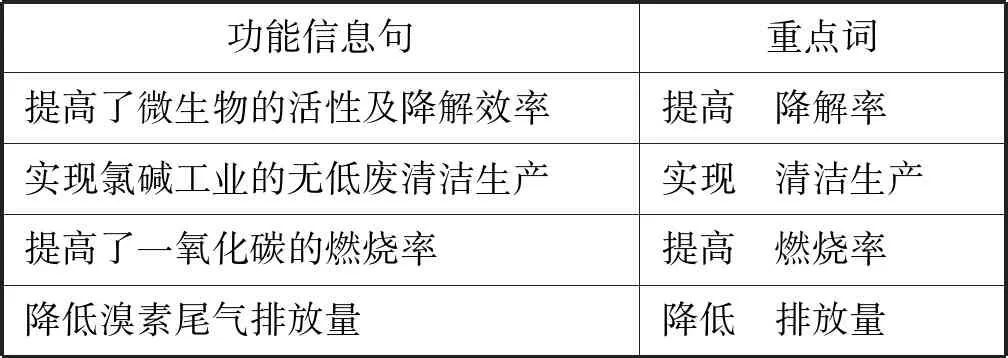
表1 功能重点词分析
上文是将注意力机制与BiLSTM进行串行组合,这部分则从词向量的基础上直接学习得到权重,公式如下:
Vi=tanh(Wxi+bw)
(11)
(12)
式中:aAtt[i]表示第i个词对于当前文本的重要程度;W和Va均为权重矩阵;bw为偏置。得到每个词的权重后,假设句中的词数为A,将词向量按权重求和作为功能词语部分的输出,公式如下:
(13)
2.5 动态聚类算法
在获得专利文本的所有特征语义表示后,本文将最终的所有特征表示提供给聚类层,以实现动态聚类操作。本文应用K-means算法来进行专利文本聚类,由于K-means容易受到初始聚类中心的影响,为了减少其随机选取聚类中心的影响,尽量将初始聚类中心在空间上的分布与实际数据分布相同。本文采用量化的标准对相似数据进行划分。轮廓系数是由Kaufman等所提出,旨在基于距离对聚类效果进行判断。
Si是文本i的轮廓系数,ai是文本i到同类其他文本的平均距离,bi是文本i到最近类别内的所有文本的平均距离。文本数量为N,定义轮廓系数Sc如下:
(14)
(15)
通过特征提取和聚类过程的相互作用动态调整和优化神经网络,将所有神经网络的损失函数定义为轮廓系数倒数的对数,轮廓系数越大,损失函数越小。若轮廓系数的取值范围为[-1,1],轮廓系数越接近1,代表类内平均距离远小于最小的类间平均距离,聚类效果越优。通过最小化损失函数可以将整个神经网络调整到最优结构,且聚类效果最优,公式如下:
(16)
定义损失函数后,可以根据损失函数对神经网络的特征提取过程进行训练,调整和优化网络参数。直到损失函数达到最小,聚类过程结束。
3 实 验
3.1 实验数据
按照国际专利分类的分类标准,本文从无机化学类(C01)共4 336篇专利中人工抽取了5 303条功能信息句,将功能信息句分为9类,每个类代表不同的功能。Lai等[21]通过理论和实验证明,词向量效果与数据的领域性很相关,领域性越强的数据训练得出的词向量表达效果越好,因此本文实验没有添加大量的额外语料进行训练。王飞等[22]的研究表明混合模型算法在训练效果上优于单一模型算法,因此本实验采用Skip-gram+Negative Sampling+Hierarchical Softmax混合Word2vec模型训练词向量。
3.2 聚类评价指标
聚类评价标准有如下三种:(1) Purity即准确率,只需要计算正确聚类的文档数占总文档数的比例,该方法优点是方便计算,缺点是无法对退化的聚类方法做出正确评价。(2) RI是一种利用排列组合原理对聚类进行评价的手段。它将准确率和召回率看的同等重要,无法对不同适用不同场景。(3) F-measure是基于RI方法衍生出的一个方法,可以将准确率和召回率设置不同的权重,适用不同的场景需求。
为了验证本文模型的有效性,本文采用评价标准F-measure。该标准经常被用作衡量聚类方法的精度,是一种平面和层次聚类结构都适用的评价标准,可以结合准确率P和召回率R做出更为综合的评价。其公式如下:
(17)
(18)
(19)
式中:nij表示类Cj中属于Ki的专利文本数。聚类的总体F-measure值则可用每个类的最大F-measure值并采用该类的大小加权之后的综合,公式如下:
(20)
式中:Dj是第j类的专利文本数量。F-measure取值范围为(0,1),某值越大表示聚类效果越好。
3.3 实验参数设置
实验参数的选取直接影响最后的实验结果。通过固定参数的方法,分别比较了100维、150维、200维,卷积核大小为3、4、5、6、7,滑动窗口的数量取16、32、64,Dropout的比例为0.3、0.5、0.6对实验结果的影响。通过对比以上参数对模型准确率的影响,当取表2所示的参数值时CNN模型取得了较好的分类结果。
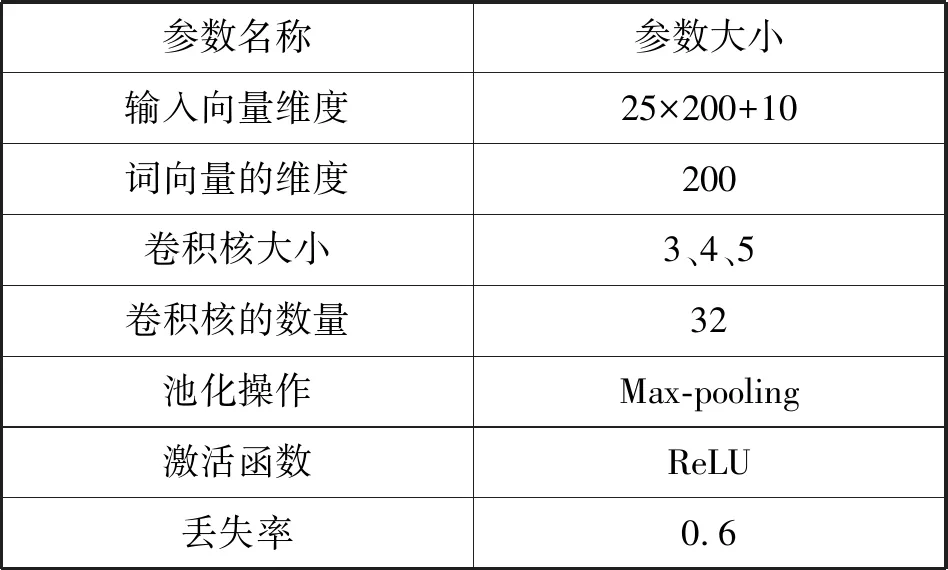
表2 CNN相关实验参数
使用不同大小的卷积核可以抽取句子的不同嵌入特征,对嵌入特征进行合并能够抽取更加全面的特征。卷积层采用ReLU激活函数避免了神经元的失活现象,并且可以加快神经网络的收敛,不会影响卷积层的效果。使用Adam优化算法,计算每个参数的自适应学习率,收敛速度更快,学习效果更有效。
BiLSTM-Attention的参数也使用了同样维度的词向量,层数为2层,隐藏层大小对比了128和256,同时加上Attention层。经过对比,隐藏层大小为128时效果最好,同样使用Adam作为优化算法,不断迭代更新网络参数,加快模型收敛速度。相关参数如表3所示。
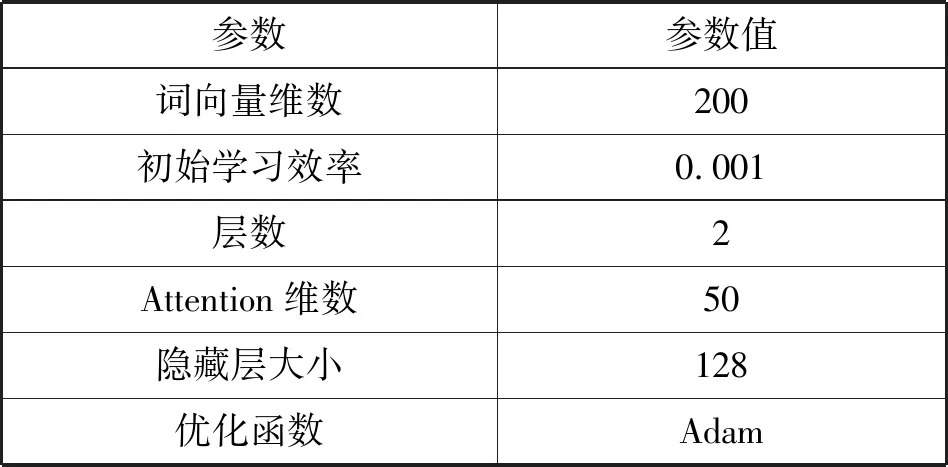
表3 BiLSTM-Attention相关实验参数
3.4 实验结果分析
3.4.1动态聚类有效性验证
为了验证模型动态反馈部分的有效性,本文在相同实验条件下进行了两组不同的实验,实验结果的F-measure值如表4所示。Baseline实验是单独的混合模型,但是并没有加上动态反馈部分;Baseline[Feedback]实验是在Baseline实验的基础上加入了动态反馈部分。
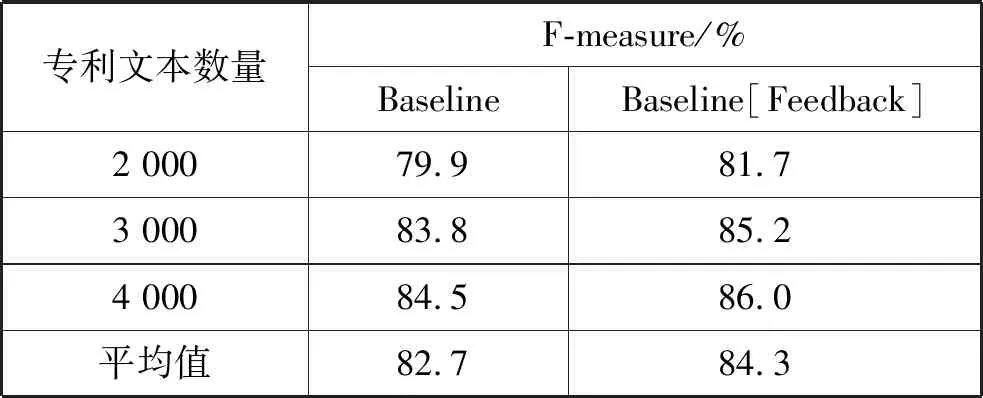
表4 对比实验结果
实验结果表明,随着专利文本数量的增加,模型准确性在逐步提升,聚类性能改善明显,从而证明了动态反馈聚类部分的有效性。同时,专利数量越来越多,两个实验的准确率都得到了不同程度的提升,说明实验中可能存在过拟合现象,增大专利文本数量情况会有所改善。
3.4.2 WLDA抽取主题特征有效性验证
为了验证模型中WLDA抽取主题特征部分的有效性,在相同条件下本文设置了如下对比实验,实验结果如表5所示。Baseline实验是本文提出的基于MAF混合模型动态聚类,并没有引入WLDA部分;Baseline[LDA]实验是在Baseline的基础上,将WLDA部分替换为标准的LDA;Baseline[WLDA]实验是在Baseline的基础上,引入了WLDA部分。

表5 对比实验结果
实验B、实验C与实验A相比F-measure值分别提升了0.4百分点、0.824百分点,证明了引入主题特征对本文混合模型聚类是有效的。同时实验C与实验B相比也有相对提升,也证明了本文提出的WLDA抽取主题特征的有效性,更能对主题进行特征表示。
3.4.3模型有效性验证
为了验证整个混合动态模型的有效性,本文设置了如下对比实验,实验结果如表6所示,其中对比实验解释如下:
TF-IDF+K-means:将功能信息句转换为文本向量,交由K-means完成聚类。
CNN+K-means:采用和混合模型相同的输入,单独利用CNN进行特征提取,交由K-means完成聚类。
BiLSTM-Attention+K-means: 采用和混合模型相同的输入,单独利用BiLSTM-Attention进行特征提取,交由K-means完成聚类。
WLDA+K-means: 采用和混合模型相同的输入,单独利用WLDA进行特征提取,交由K-means完成聚类。
Baseline实验是整个MAF混合动态聚类部分。
Baseline[-BA]实验是去除BiLSTM-Attention部分,利用其提取语义特征,同时加入动态反馈聚类部分。
Baseline[-CNN]实验是去除CNN部分,利用其提取嵌入特征,同时加入动态反馈聚类部分。
Baseline[-WLDA]实验是去除WLDA部分,利用其提取主题特征,同时加入动态反馈聚类部分。
Baseline[-Attention]实验是去除功能词语关注部分,同时加入动态反馈聚类部分。

表6 对比实验结果
本文利用轮廓系数来评估该模型的聚类效果,如图3 所示。
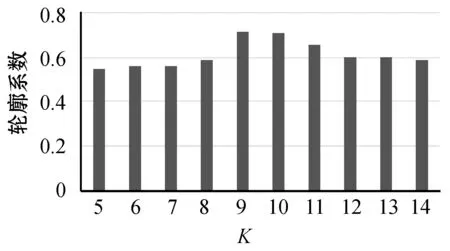
图3 轮廓系数
实验结果表明,本文提出的混合模型对专利文本融合功能信息的聚类有明显提升。实验A与实验B相比表现得并不是很好,因为原始语料中存在很多噪声,CNN对功能信息句进行特征提取可以降低部分噪声,F-measure值得到了提高,同时也减少了聚类时间,证明了CNN对特征提取的有效性。实验A与实验C相比,聚类的F-measure值提高了将近10百分点,聚类时间也缩短了近2 s,证明了BiLSTM-Attention对特征提取的有效性。实验A与实验D相比,F-measure虽然提高有限,但是也间接证明了本文改进的LDA提取主题向量的有效性。
Baseline系列实验与其他实验相比不管是F-measure还是运行效率都得到了不同程度的提升。实验F、G、H证明了深层语义表示部分对聚类效果的有效性;通过实验E和实验I可知,加入功能词语注意部分对聚类效果是有效的。由图3可知,当K=9时轮廓系数也是最高的,也证明了面向功能信息混合模型动态聚类模型的有效性。
4 结 语
本文提出了面向功能信息的相似专利动态聚类混合模型。在词向量的基础上,通过结合深层语义表示部分和功能词语注意部分,生成专利文本的特征表示,并且提出了一种反馈策略来动态调整和优化网络训练。实验结果表明,本文提出的模型表现出较好的性能,证明了其有效性。
特征提取仍然是自然语言处理领域的一个难点,未来将继续完善该模型的特征提取过程,进一步探索特征提取与聚类的深度融合,提高聚类的准确性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
南京理工大学学报(2022年1期)2022-03-17
计算机应用与软件(2021年7期)2021-07-16
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
中国发明与专利(2007年7期)2007-08-09
