
多层网络链路预测研究进展
2021-05-14 03:57王飞程周钰颖
计算机应用与软件 2021年5期
王飞程 周钰颖 闵 勇
(浙江工业大学计算机科学与技术学院 浙江 杭州 310023)
0 引 言
网络中链路预测的目标是根据已知的网络信息预测丢失或潜在的链路。链路预测有着广泛的关注和应用,例如:在生物学领域,其可以预测基因网络和蛋白质网络中的隐藏关系,有助于提高实验成功率,开辟药物开发的新途径;在复杂网络分析中,其可以用作准确分析复杂网络结构的强大补充工具。近年来,链路预测还被用于预测在线社交网络的关系[1]、学术网络的论文类型、犯罪网络中犯罪分子的联系,以及电子商务中客户的偏好等。同时,链路预测有助于理解复杂网络的演化机制发现和利用。由于复杂网络结构的内部特征差距非常大,因此很难比较各种机制的优缺点,而链路预测恰好能为网络演化机制[2]的比较提供一个简单而独特的平台,推动复杂网络演化模型的理论研究。
以往关于链路预测的工作主要集中在单关系网络,即网络中只包含单一类型的关系。然而许多现实世界的关系系统被描述为包含多种联系的多关系网络[3]。在这样的网络中,不同类型的边表示个体之间的不同关系,例如朋友、亲戚、同事。每一对关系之间存在相互影响,且对于不同的关系对,这种影响可能有所不同。例如:一个人与他同事的朋友建立联系会比与他亲戚的朋友建立联系的可能性更高。在这种情况下,“同事”关系对“朋友”关系的影响大于“亲属”关系。对于这种多关系网络的链路预测,需要综合考虑不同关系之间的相关性和影响力。单关系网络的链路预测方法不适用于多关系网络,因为这些方法只考虑单一关系而忽略整个结构以及不同关系之间的影响,期望在多关系的网络中有效地利用多面性来增强链路预测结果。
到目前为止,人们对于单层网络的链路预测已经做了大量的研究和总结,对于多层网络链路预测有了一些可行的方法,但是很少有人进行系统地整理。针对这个问题,本文提出了一个多层网络链路预测方法的分类框架,归纳了现有的多层网络链路预测方法,同时对链路预测一些具有可比性的方法进行了比较。
1 单层网络链路预测技术
考虑一个无向单层网络G(V,E),其中:V是节点集,E是边集。U表示所有可能边的全集U=|V|×(|V|-1)/2,|V|表示节点集V的个数,不存在的边集为U-E。链路预测的任务是预测边集合U-E中存在的一些丢失的边(或者在将来可能存在的边)。为了测试算法的准确性,边集E被分成两部分:被当作已知信息的训练集ET和被当作缺失链接的测试集EP。显然ET∪EP=E,ET∩EP=∅。给定一种链路预测方法,等效地给出每个未观察到的链路(u,v)∈U-ET一个得分Suv,进而将所有未连接的节点对按照分数从大到小排序,排在前面的节点对出现连边的概率最大。
在专业文献中已经提出了大量单层链路预测技术。文献[4]总结并比较了若干具有代表性的单关系网络链路预测方法,包括基于相似性的方法、基于最大似然估计的方法和基于概率模型的算法。基于相似性的方法假定节点倾向于与其他类似的节点形成链接,如果两个节点连接到类似的节点或者根据给定的距离函数在网络中邻近,那么两个节点是相似的。常见的基于相似性的方法包括共同邻居(CN)[5]、Adamic-Adar指标(AA)[5]、资源分配指标(RA)[6]、优先链接指标(PA)[7]、Jaccard指标(JA)[8]、Salton指标[9]、Sorenson、LHN-I指标[10]、局部路径指标(LP)[6,11]和Katz指标[12]等。基于最大似然估计的方法虽然精确度较高,但是不适用于规模较大的网络。基于概率模型的方法通常先建立一个含有一组可调参数的模型,继而使用优化策略寻找最优的参数值,使得所得到的模型能够更好地再现真实网络的结构和关系特征[13]。网络中两个未连边的节点对连边的概率等于在该组最优参数下它们之间产生连边的条件概率,这些概率值可以用来排列潜在的链接,与基于相似性的方法类似。
为了衡量不同算法的优劣,通常使用两个评价指标来量化预测算法的准确性,分别是AUC[14]和Precision[15]。AUC根据整个列表评估算法的性能,从而提供所有未观察到的链接的等级。AUC的值表示每次随机从测试集中选取一条链接与随机选择的不存在的链接比较,测试集EP中的链接得分高于从不存在的链接集合U-E中随机选择的一个链接得分的可能性。在n次独立的比较中,如果有n′次测试集中的链接具有更高的分数,有n″次具有相同的得分,则AUC的值表示为:
(1)
Precision只关注排在前L位的边是否预测准确,定义为在前L个预测链接中被准确预测的比例,精确度越高则表示准确性越高。若有Lr条链接是正确的(Lr条链接在EP集合中),则精确度(P)表示为:
(2)
综上所述,人们对单层网络链路预测进行了较为充分的研究,但是对于多层网络链路预测却面临新的问题和挑战。
2 多层网络
多层网络明确地包含多个连接层,构成由不同关系(活动、类别等)链接互连的系统。每个层包含一种关系(活动、类别),并且相同的节点(实体)可以具有不同类型的交互(每层中不同的邻居集合)。如今,多层网络模型已经应用到许多领域,包括社会科学、技术系统和经济学等。在未来,生物学和生物医学也将会更加充分地利用多层模型。
多层网络相较于单层网络,要考虑的问题更加复杂。单层网络只需要考虑单层网络中的链接,而多层网络不仅要考虑各层的层内链接,还要考虑各个层之间存在的联系和影响,即层间关系,如图1所示。
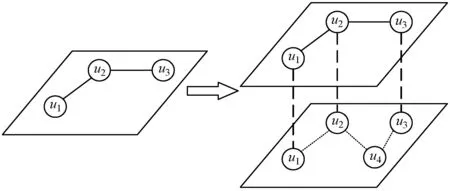
图1 单层网络(左)与多层网络(右)对比
2.1 网络定义
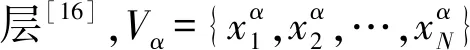
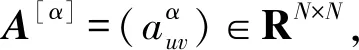
(3)
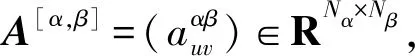
(4)
因此多层网络可以建立数学模型[16],表示为M=(VM,EM),其中:
(5)
(6)
2.2 网络类型
多层网络包括多路复用网络[17]、时序网络[18]、互动网络[19]、多维网络[20]、相互依赖的网络[21]、多级网络[22]和超图[23]等在内的多种类型。由于本文链路预测方法基本上只涉及多路复用网络和时序网络,因此这里只介绍这两种网络类型。
1) 多路复用网络(多重网络)。一个m层的多路复用网络M是所有层{Gα;α∈{1,2,…,m}}的集合,每一层由一个(有向或无向,加权或不加权)图Gα=(V,Eα)构成,其中V=V1=V2=…=Vm,即所有层拥有相同的节点,层间关系Eαβ={(v,v);v∈V}}。
3 多层网络链路预测
3.1 问题描述与评价方法
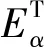
3.2 多层网络链路预测分类
虽然单层网络的链路预测技术已经在不同领域得到了大量的应用,但是对于多层网络的链路预测研究仍然较少。多层网络相较于单层网络,最大的区别在于多层网络在考虑层内关系的基础上还需考虑层间关系。图2为多层网络的链路预测方法技术分类。
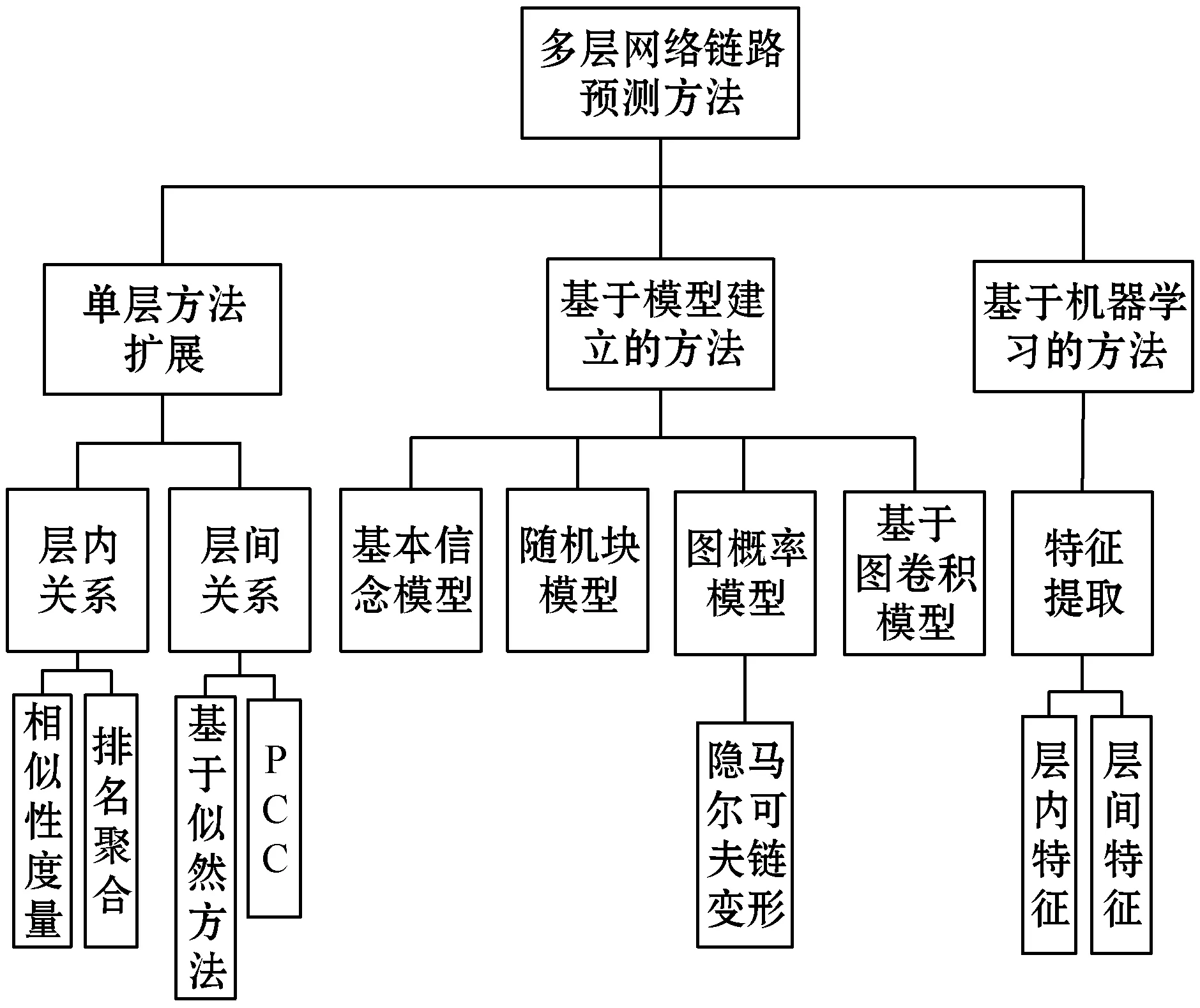
图2 多层网络链路预测方法分类技术
在多层网络链路预测过程中,各个方法都用到了多层网络的特征或属性,表1对现阶段多层网络链路预测方法中运用到的一些具有代表性的属性或特征进行了总结。
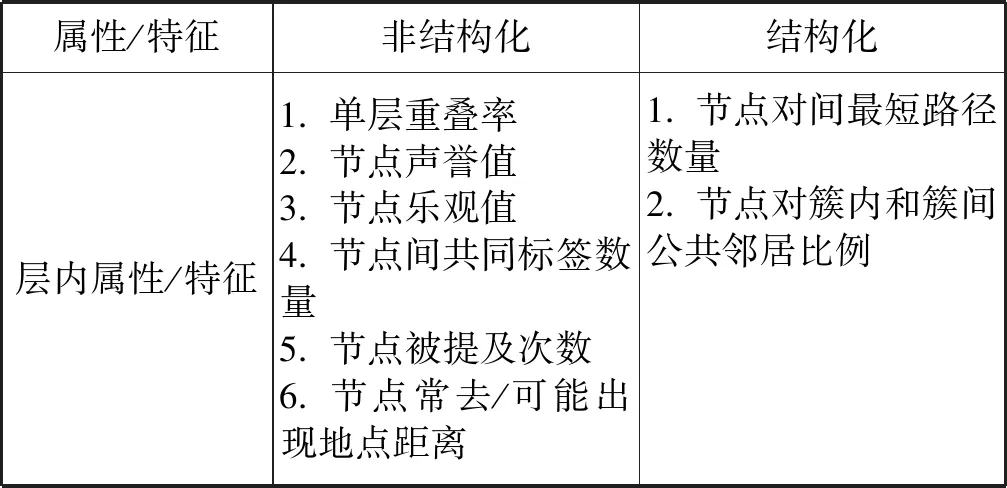
表1 多层网络属性/特征表
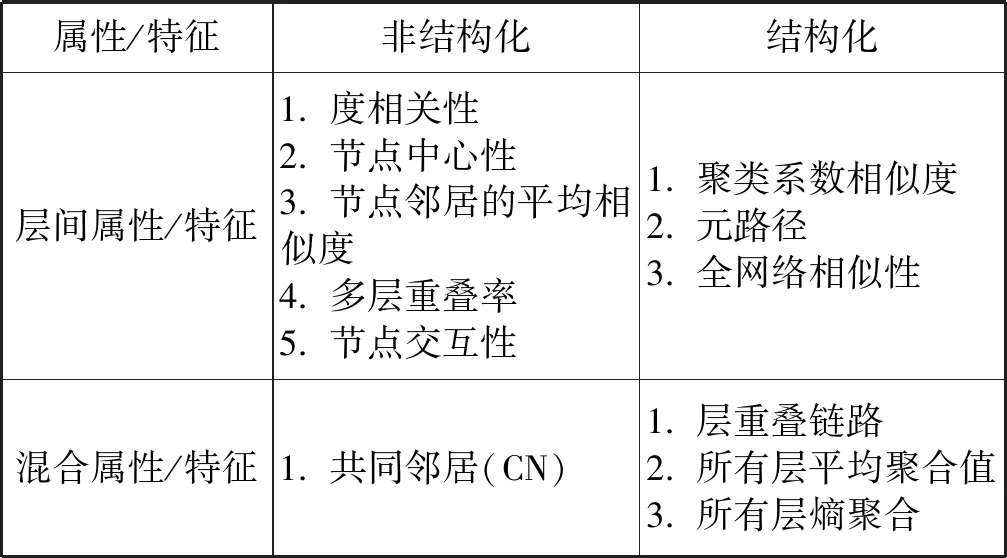
续表1
3.3 基于单层方法扩展
该分类扩展了单层网络链路预测的方法,主要通过预测层与目标层之间的关联,找出预测层对目标层的重要程度(即权重),结合预测层的层间信息和层内信息,对目标层进行链路预测。
3.3.1层内关系提取方法
层内关系提取方法可以基于现有的单层链路预测方法(包括CN、RA和AA等)直接获得,也可以利用多个测量方法得到多个未连接节点对的排序列表,组合排序列表获得单个聚合排序列表,得到节点对层内关系亲密程度的排序。这里介绍几种排序聚合的方法。
1) Borda排序[24]。Borda排序是一种经典的绝对定位排序方法。首先为每个排序列表中的每个节点对分配一个Borda分数,最后整合得到一个聚合排序列表。Borda得分越高,则节点对存在的可能性越高。对于一组排序列表L=[L1,L2,…,Ln],Li表示其中一个测量方法得到的列表,Li(u,v)表示节点对(u,v)在列表Li中的排名,最高排名节点对的值为0,n表示节点对个数,节点对(u,v)在列表Li中的Borda得分为:
BLi(u,v)=n-Li(u,v)
(7)
节点对(u,v)总Borda得分如下,从而得到一个完整的聚合列表:
(8)
2) Kemeny排序[25]。Kemeny排序是一种相对定位方法,主要基于计算两个输入列表中相反排名的元素对的数量。首先通过输入列表或者一些经典聚合方法(如Borda排序)获得初始排列。计算每一个初级排列的得分,该得分等于该排列与所有输入列表之间的距离之和。K(π,Li)表示π和Li两个列表中拥有相反排名的元素对的数量,其中π是初始排列。通过SK(π,L1,L2,…,Ln)衡量排列的优劣,具有最低分数的排列被认为是最佳方案,定义如下:
K(π,Li)=|(x,y) s.t.π(x)<π(y)&Li(x)>Li(y)|
(9)
(10)
3.3.2层间关系提取方法
层间关系即层相关性提取可概括为以下方法和指标。
1) 基于极大似然的方法[26]。该方法在提取层间关系时,将目标层与预测层中的重叠链路(相同节点之间同时存在链接)作为衡量预测层权重的标准,重叠链路越多,则权重越高。根据每条边在所有预测层中的存在性(1表示存在,0表示不存在),结合权重,得到每条边的分数。分数越大,则在目标层中存在的可能性越大。基于极大似然的方法同时提取了层间关系和层内关系。全局重叠方法[27]基于极大似然方法类似,引入了一个全局重叠率(GOR)来提取预测层和目标层之间的层相关性,公式表示为:
(11)
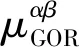
全局重叠方法和基于极大似然的方法都是从预测层和目标层的重叠链接出发,但是方法本质仍然存在差异。基于似然的方法针对单个边,直接通过所有预测层中链接的存在性给目标层的链接分配可能性;而全局重叠方法针对所有的边,得到的仅仅是层间相关性。
2) 皮尔逊相关系数(PCC)[27]。PCC是一种衡量层相关性的方法。将两个层当作被考虑的变量,得到层相关程度。
3) 层重建方法[28]。其将目标层和预测层的信息以邻接矩阵的形式表示,利用特征向量和特征值代表网络结构特征,用两层间相似的特征向量数量量化得到目标层和预测层的层相关性。
4) 度相关性[29]。节点在各层上的度可能不同。从节点的度出发,可以捕获各个层之间的相关性。
5) 中心性[30]。节点的中心性表明了它们在网络中的重要性和生命力,基于节点在节点之间最短路径上出现的次数。
6) 聚类系数相似度[31]。其用来度量网络中节点趋向于聚集在一起的程度。
7) 邻居的平均相似度[29]。对于一个节点u,tα(u)表示节点u在层α中所有的链接数,tβ(u)表示节点u在β中的所有链接数,tαβ(u)表示节点u在层α和层β中同时存在的链接数,k表示节点的度。邻居的平均相似度定义为:
(12)
同时,如果考虑到网络层中链接总数对于ASN值的影响——层包含的链接越多,则它包含的信息很可能相对较多,因此有非对称邻居平均形似度指标定义如下:
(13)
式中:α表示目标层;β表示预测层。
3.4 基于模型建立的方法
3.4.1基本信念模型
基本信念模型[32]以基本信念分配(A Basic Belief Assignment,BBA)的概念来量化边的不确定度,即边存在的可能性,信念值介于0和1之间,量化了链接存在的可能性。首先,将每个层当作独立的数据来源,借鉴共同邻居的方法,从网络的所有层中收集来自相邻节点的数据。然后,根据其可靠性评估从每一层收集来的数据,再根据网络中特定类型的同时链接的分布修改所得到的基本信念分配值。存在未连接节点对(u,v),对于一个预测层,如果目标层中u和v的共同邻居与该预测层中两点的共同邻居完全重合,则采用合取规则修改信念值,表明这个预测层是高度可靠的;如果预测层中只出现部分共同邻居,则使用析取规则,表明这个预测层至少有一部分是可靠的;如果预测层中完全没有出现目标层中的共同邻居,则表明这个层可以被忽略。
3.4.2随机块模型
随机块模型可分为以节点为基本单位和以链接为基本单位的两种模型[33]。该方法基于随机块模型的概率推理[34],同时描述所有层的信息,在预测目标层时充分利用了整个网络中包含的信息。因为两个方法类似,因此下面只介绍基于节点为基本单位的随机块模型。
基于节点为基本单位的随机块模型将节点和层分别分组,每个节点和层可以同时属于多个组,通过节点、层属于某组的概率以及节点对在各个预测层上的互动概率得到目标层上该节点对链路存在的可能性,节点对(u,v)在目标层α中的相似度可表示为:
(14)
式中:θig1表示节点u属于组g1的概率;θvg2表示节点v属于组g2的概率;ηlg3表示层l属于g3的概率;pg1g2g3(α)表示组g1中的节点u与组g2中的节点v在组g3中的层α上联系的概率。
3.4.3马尔可夫模型变形
该模型使用特征级联的无限阶乘隐马尔可夫模型,对各节点在不同层中的隶属关系进行建模[35],从而对层内和层间链路进行预测。
3.4.4 GCN-GAN模型
GCN-GAN模型是一种新的非线性模型,可应用于动态加权网络[36]。该模型利用了图卷积网络(GCN),长短期记忆(LSTM)和生成对抗网络(GAN)。首先利用GCN获取各个时间快照的拓扑结构,然后使用LSTM来表征动态网络的演变特征。在这个过程中,GAN用于增强模型生成下一个加权网络快照的能力。
3.5 基于机器学习的方法
该方法提取预测层层间特征和层内特征以及目标层的层内特征,使用机器学习,包括朴素贝叶斯、逻辑回归、支持向量机、K-近邻算法、决策树等分类器对有无链路进行分类,从而完成链路预测。在此过程中,重点在于特征提取。多层网络的特征多种多样,特征的选取与研究对象、网络特点等密不可分,具有灵活性和可变性,下面列举了一些具有代表性的特征。
3.5.1层内特征
层内特征可概括为以下几部分:
1) 层内特征涵盖了3.3.1节中提到的层内关系以及经典的页面排序算法(PageRank)[37],此处不再赘述。
2) 单层监督排名聚合值。使用多个单层链路预测方法,包括CN、AA和RA等,分别得出链路存在的可能性大小。排名聚合通过使用不同的单层链路预测方法得到多个排名列表,使用排名聚合组合这些排序列表获得单个列表,得到聚合值。
3) 单层重叠率[38]表示为:
(15)
式中:Γ(u)表示节点u的邻居;|Γ(u)|表示节点u的邻居数,即节点的度。
4) 声誉值和乐观值[39]。适用于有向网络,每个链接有相应的符号,任何链接都有正号或者负号,如图3所示。
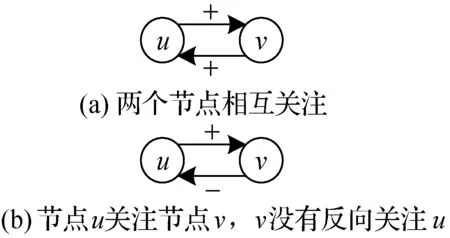
图3 声誉值和乐观值示意图
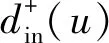
(16)
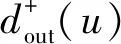
(17)
5) 节点对间最短路径数量[40]。该特征利用广度优先搜索算法[41],在无向网络中确定节点对之间最短路径的数量。该过程迭代进行,在每一个深度,计算并更新到未访问节点的最短路径数。
6) 节点对簇内与簇间公共邻居比例[40]。这里用到了聚类的概念,先用一些已有的聚类方法[42]将节点分成多个不同的小团体,也就是簇,簇中的各个节点联系更为密切。如果两个节点的共同邻居与两个节点属于同一个簇,称其为簇内邻居,否则称其为簇间邻居。
3.5.2层间特征
层间特征与层间关系有些不同,层间关系用来表示全局层间信息,即层与层之间的总体相关性(基于层);层间特征用来定义局部层间信息,即两个未连接节点之间的层间相关性(基于节点)。下面列举特征:
1) 元路径。在多层网络中,两个对象可以通过穿过网络的不同层或包括不同类型的对象的路径进行连接[43]。元路径用来表示两个节点之间的跨层路径。首先确定两个节点之间元路径的长度和类型,然后使用诸如广度优先搜索或深度优先搜索等方式遍历网络找到元路径,从中提取有意义的特征。
2) 多层Adamic/Adar指标。多层网络Adamic/Adar指标是单层链路预测Adamic/Adar指标的扩展,Hristova等[38]在文献中给出定义如下:
(18)
式中:ΓGNi表示多层网络中节点i的所有邻居节点的集合。
3) 多层重叠率(层与层之间边的重叠率)[44]表示为:
(19)
4) 交互性指标[38]表示为:
(20)
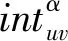
5) 所有层平均聚合值[46]。基于单层监督排名聚合值,用于计算所有层上特征的平均值,定义如下:
(21)
式中:X(u,v)是一个拓扑属性值。
6) 所有层中的值的熵聚合。节点度熵(Product of node degree entropy,PNE)基于度熵[46]。度熵E(u)和节点度熵有如下定义:
(22)
PNE(u,v)=E(u)·E(v)
(23)
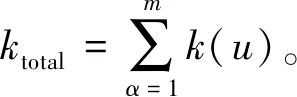
另外,存在一个基于拓扑属性的熵,被称为Xent,表示为:
(24)
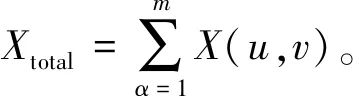
7) 全网络相似性指标。该指标假定两个实体之间的吸引力与它们之间相互作用的重要性成正比[47],具有局限性,适用于社交互动信息网络和地理位置网络结合的多层网络。定义如下:
(25)
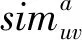
3.6 典型应用
本节呈现了几个多层网络链路预测的具体应用,包括静态多重网络,时序网络和动态多重网络等链路预测。表2对静态多重网络链路预测方法进行了定性地对比,表3对现有的动态多重网络进行了大致的比较。
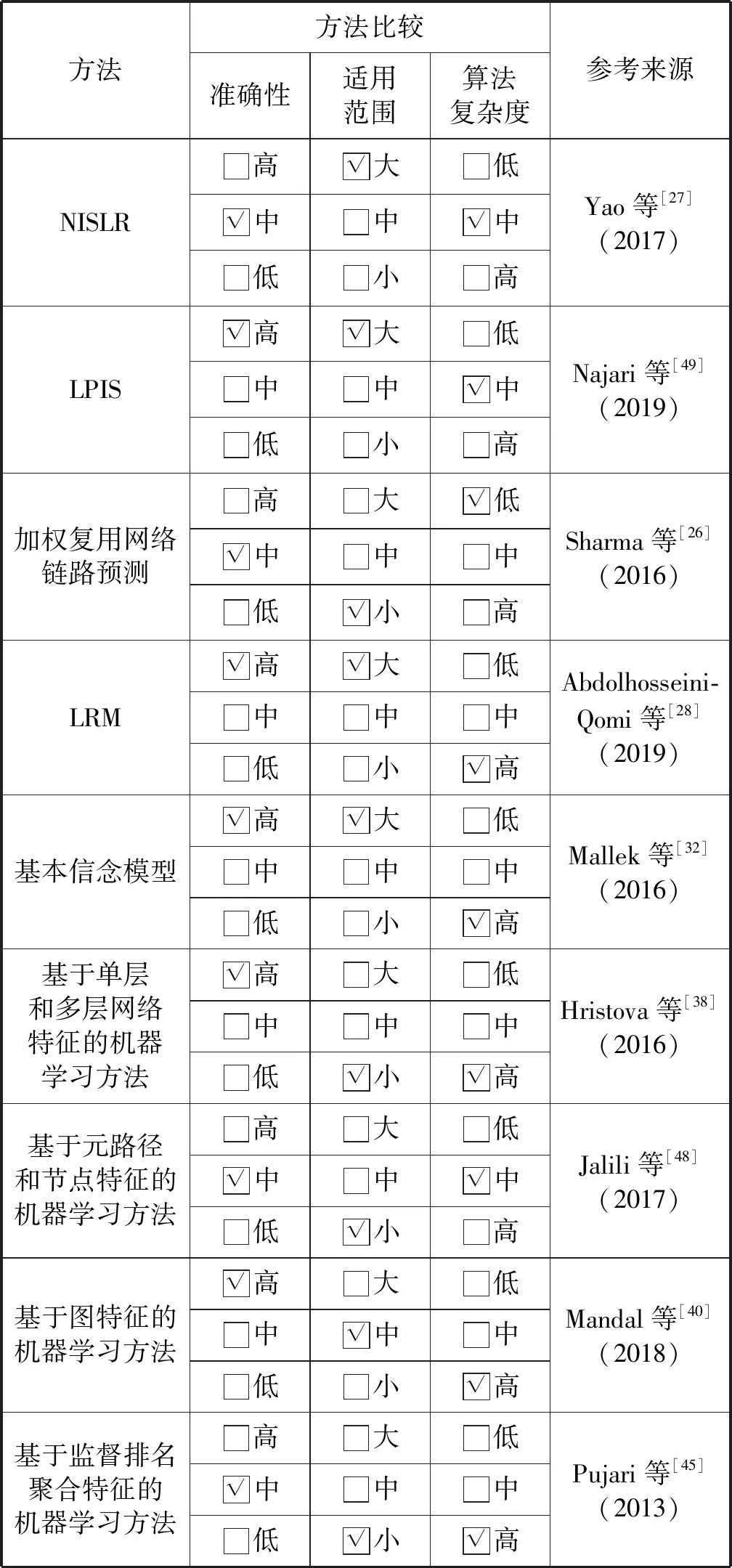
表2 静态多重网络链路预测方法对比表
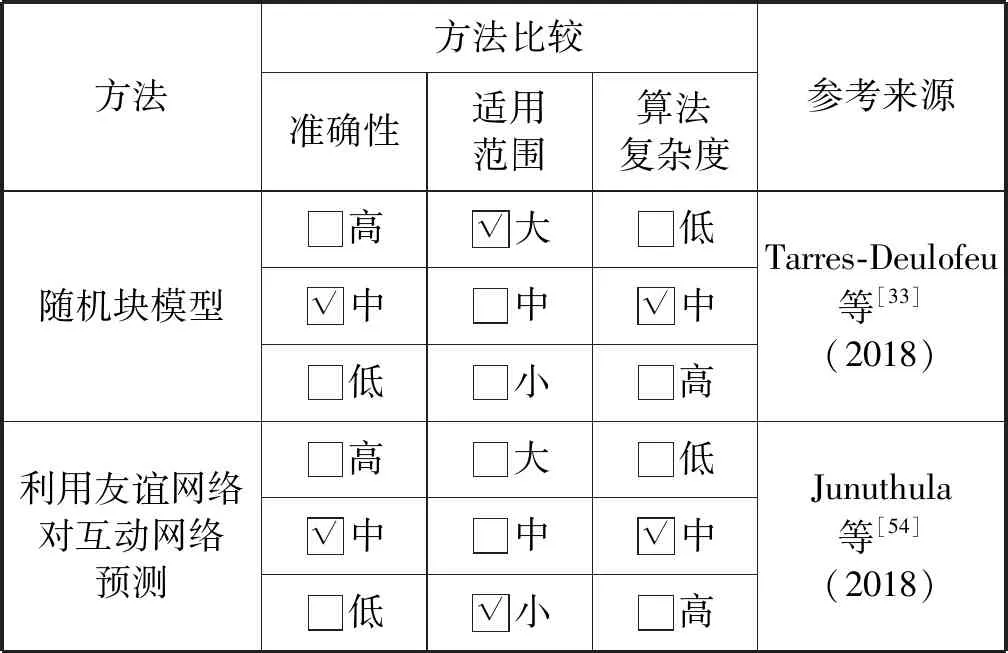
表3 动态多重网络链路预测方法对比表

续表3
3.6.1静态多重网络的应用
针对多重社交网络,Yao等[27]、Abdolhosseini-Qomi等[28]和Sharma等[26]基于单层方法进行扩展;Hristova等[38]、Jalili等[48]、Mandal等[40]采用了机器学习的分类方法,提取不同的特征对链路有无进行了二元分类。其中Hristova等[38]使用随机森林分类器(Random Forest classifier);Jalili等[48]使用并比较了支持向量机(SVM)、K最近邻(KNN)和朴素贝叶斯三种分类算法,实验得出SVM的分类结果较好;Mandal等[40]使用了朴素贝叶斯方法。而Najari等[49]结合了基于单层的方法和机器学习,使用逻辑回归的分类算法进行了链路预测。
Yao等[27]利用层间关系和层内关系,提出了一个基于多重网络层相关性的节点相似度指标(NSILR)用于链路预测。对于一个节点对(u,v)而言,首先根据现有的单层链路预测方法(CN、RA、AA、LP和Katz等)计算每层中该节点对的相似性,包括目标层和预测层。然后通过测量层间相关性,得到节点u和v在目标层中存在链接的可能性大小。
该方法提出的基于多重网络层相关性的节点相似度指标(NSILR)被定义为:
(26)
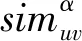
在实验过程中采用时间复杂度较低的局部相似性度量方法和来自其他层的层间信息,获得了比时间复杂度较高的全局和准局部度量更好的性能,同时验证了皮尔逊相关系数(PCC)在某些复用网络中拥有比全局重叠率(GOR)更好的性能。NISLR指数同时考虑了层内信息和层间信息,成功地在一个七层多路复用网络上进行了链路预测。
该方法根据网络的差异,得到层间关系和层内关系在链路预测中的最佳比重,获得较高的预测性能,具有较强的扩展性和灵活性,可以适应较多层静态网络的链路预测。同时其预测性能受限于层相关性,层越相关,则预测性能越高。
Najari等[49]提出了一个基于层间相似性的链路预测框架(Linkprediction Accounting Interlayer Similarity,LPIS),结合了基于单层链路预测方法的扩展和机器学习的方法,提取层内特征,通过度相关性、中心性、聚类系数相似度和邻居的平均相似度等得到层间关系,完成链路预测。层间关系通过式(27)转变为链接存在的可能性:
(27)
最后将层内特征和层间关系相结合,得到节点对存在的可能性:
(28)
对照上述NISLR方法,可以发现两个方法之间有许多相似之处。两者都包含充分的层间信息和层内信息,通过一个可调参数φ来平衡层间关系和层内关系,但是对于层间关系的提取方法存在差异。LPIS方法分别在双层网络Twitter-Foursquare网络和Twitter-Instagram网络、五层线上线下交流网络和37层欧洲航空运输网络中进行了实验,得到了良好的效果,相比NISLR方法具有更高的可信度和可扩展性。
Sharma等[26]研究加权复用网络中的链路预测,使用网络中所有其他层的信息,预测目标层处的链路以及权重[26]。对于所有预测层,可能性是指目标层对于该预测层的依赖程度,使用基于似然的方法被单独计算,目标层中存在链接的可能性是单层可能性的组合。
除了提出链路预测的方法,Sharma等[26]还对权重进行了预测。对于一对将来可能存在的节点对,权重取决于连接该节点对的边和两个节点的邻居[50]。权重的表达式为:
(29)
(30)
(31)
式中:u和v是被权重预测的节点对;A和B分别代表u和v分数最高的邻居;Wuv表示节点对(u,v)的权重;WAu和SAu分别表示A和u之间链接的权重和分数。
Sharma等[26]提出了在加权网络中的链路预测和权重预测方法,预测的权重和实际权重偏差较小,能够应用于一些加权网络的场景。但是局限性较大,预测性能只能在特定的多路复用网络上得到验证,而且没有充分利用预测层的层内信息。
层重建方法[28](Layer Reconstruction Method,LRM)利用层重建指标,使用目标层和预测层的结构特征量化层间关系和层内关系,对目标层进行重建,完成链路预测。该方法最大的优点在于信息冗余,即使链路预测缺失率较高,也能保证链路预测的相对准确性。
Hristova等[38]、Jalili等[48]和Mandal等[40]均使用机器学习研究了Twitter-Foursquare网络,但只是提取了不同的特征。Hristova等[38]提取社交互动网络Twitter的特征包括提及次数[51]、共同标签数、单层重叠率以及单层Adamic/Adar指标;在线地理网络Foursquare的特征包括节点同地点出现的可能性以及节点常去地点之间的距离。多层特征(即层间特征)包括多层Adamic/Adar指标、全网络相似性指标和多层重叠率和交互性指标。该方法提取的特征充分和全面,考虑了每一层的特性以及复合后的多层网络特性,从局部和全局方面进行特征提取,提高了预测性能,但同时增加了算法复杂度。Jalili等[48]提取了每个节点的属性(层内关系)和元路径(层间关系)特征。其中节点的属性包括节点的共同邻居CN、声誉值和乐观值。该方法提出的跨层元路径特征提取简单可行,算法复杂度较低,但性能受限于网络的密集程度,对于稀疏网络,找不到许多公共相邻节点,导致元路径较少,机器学习的分类性能较差。Mandal等[40]利用了共同邻居的数量、节点对之间的边数量、簇内与簇间公共邻居比例和最短路径数量等特征,相较于使用元路径的方法更为简单,准确率也较高。三者仅仅是在Twiiter-Foursquare网络中进行研究和实验,针对性强,对于社交网络的多重网络链路预测启发较大,但同时社交网络的特色较为明显,导致应用范围不广,很难将社交网络存在的特征扩展到不同的网络中。
针对更多层的复合科学合作网络,Pujari等[45]同样通过提取层内特征和层间特征进行链路预测。层内特征包括单层监督排名聚合值,多层特征(即层间特征)包括所有层平均聚合值以及所有层中的值的熵聚合。该方法开创性地在多路复用网络上应用排名聚合来组合多个拓扑测量,提升预测性能,但是算法复杂性较高,对于大型数据集的有效性较低。
3.6.2时序网络的链路预测
时序网络是随着时间动态变化的网络,因此链路预测的过程更为复杂。Hajibagheri等[52]提出了时序网络链路预测框架(Multiplex Link Prediction,MLP)。MLP框架包括边赋值、时间链接结构和排名聚合三个组件。
首先,MLP框架使用基于似然的方法计算跨层依赖性,得到边集的分数(即为边集赋值)。然后,使用时间衰减函数来模拟网络动态,为每个节点相似性度量生成复合时间分数矩阵[53]。给定T时间的网络历史,从而捕获协同进化过程中的时间依赖性。令{simt(i,j),t=t0+1,t0+2,…,t0+T}是由连续时间片T的滑动窗口上的节点相似性度量生成的相似性得分矩阵。聚合加权后的相似性矩阵构造如下:
(32)
式中:参数θ∈[0,1]表示先前时间段的权重,在当前时间t+1之前,根据快照的重要性修改θ的值。
最后采用Borda排序的方法将来自多个拓扑度量的信息收集到一个评分矩阵中,为潜在的链接进行排序。Borda排序利用所有快照中链路的不同排序列表,得到聚合排序。
该方法考虑了网络的动态变化,引入了时间衰减模型,模拟了多路网络协同进化,可以准确地预测时序网络中的链路,有效地融合不同拓扑信息(边和节点的特征、节点相似性等)。进行Borda排名聚合,算法复杂度较低,可应用于许多领域的大规模时序网络,比如在销售领域可以用来分析实时需求寻求企业最大化利润,在工业领域可以智能运维,提高各个环节的稳定性等。
3.6.3加权动态网络的应用
Lei等[36]提出GCN-GAN模型解决加权动态网络中的链路预测问题。该方法同时考虑了动态网络中潜在的非线性特征和链路权重,充分利用加权动态网络的动态性、拓扑结构和演化模式来改善动态链路预测的性能。因为链路权重和动态性在实际网络中都是必不可少的,而如今大部分方法并未将两者结合起来,因此这个方法对于链路预测的发展具有启发性和创新性。
3.6.4动态多重网络的应用
Tarres-Deulofeu等[33]提出的随机块模型,适用于任何多层网络。该方法打破了多层网络链路预测的局限性。
Junuthula等[54]长期研究动态网络,有针对性地研究了友谊网络和互动网络形成的多重网络,利用友谊网络和互动网络之前的快照对互动网络中的未来动态链接进行了预测。该方法在链路预测分析时,需要先分析每个网络的特征。在友谊网络中,链接通常只需要进行一次预测;在互动网络中,链接需要重复交互,也就是说,人们可能会互动一段时间之后停止互动然后又恢复互动。因此,考虑互动网络时,需要同时考虑未来可能形成的边和可能消失的边。虽然Junuthula等[54]研究的同样是友谊网络和互动网络,与Twitter和Foursquare网络类似,但是其不再局限于一个状态下的网络,而扩展为一段时间内产生动态变化的多重网络,考虑到两个网络的不同特性,尤其是互动网络互动的间隔性,导致单独一次链路预测不足以说明问题,需要持续性地预测。该方法考虑到此问题,因此使得分析的结果更为可靠。
Yasami等[35]针对动态多重网络,考察了整个网络演化过程中的层演化过程(层的出生/死亡和生命周期),使用图模型中的马尔可夫模型变形,完成了动态多层网络的链路预测。该方法的全局意识较强,出发点较高,相较Junuthula等[54]方法仅针对性地服务于两个社交网络,其模拟重现各个网络,可应用于大部分动态多重网络。现如今存在的许多网络本质上就是动态多重网络,因此研究分析动态多重网络具有重大的意义。
4 结 语
本文总结了多层网络链路预测方法研究与发展,包括基于单层网络方法的扩展、基于机器学习的方法和建立模型的方法。前两者均考虑了两个方面的因素——层间关系和层内关系。难点在于对层间关系的提取,即衡量层与层之间的关系亲疏。利用极大似然估计、重叠率等方法衡量一个层对另一个层的重要性,从而得到各个预测层对于目标层的重要性差异,可获得好的链路预测结果。也可通过提取多层网络中的多层特征,利用机器学习对链路有无进行分类。建立模型的方法通过模拟、架构整个网络来进行链路预测。其中图概率模型在链路预测中较为常用的是隐马尔可夫模型,因为隐马尔可夫模型不需要模型的状态序列,因此其适应性较强。近几年出现的图卷积神经网络,对于较为复杂的多重网络,能充分地利用网络的各个特性,提高链路预测的质量,虽然如今研究较少,但也是未来发展的趋势。
实验表明,相比逐个分析单一网络,上述的各个方法都表现出更好的预测效果,具有更低的错误率。这些方法已经研究发现了一些多层网络中的特征和属性,并利用这些特征和属性进行链路预测。多层链路预测的结果好坏存在很多原因,虽然主要在于方法的优劣,但与分析的网络性质等也有关系。
现有的大部分研究主要致力于研究静态多重网络,对动态多重网络的研究较少。目前多数方法仅限于对两个网络的分析,且大部分分析偏向于社交网络,分析的数据集较少,样本比较单一,特殊性较强,扩展性较弱,提出的方法很难扩展到其他的网络中。因此,考虑更多层真实的动态大规模网络、进一步整合可用的数据、增强扩展性以及降低算法复杂度都是未来的目标。此外,传统机器学习以及深度学习虽然已经被使用了很长一段时间,并在各种环境下提供了可靠的性能,但其在链路预测领域的应用才刚刚起步,提取的特征人为干预较强,仍值得深入研究以提高其在实际应用中的适用性。
猜你喜欢
分子催化(2022年1期)2022-11-02
科学技术创新(2022年29期)2022-10-26
火力与指挥控制(2022年8期)2022-09-16
南京航空航天大学学报(2022年4期)2022-08-30
移动通信(2021年5期)2021-10-25
学生导报·东方少年(2019年20期)2019-11-27
振动工程学报(2019年2期)2019-05-13
中国建筑金属结构(2018年4期)2018-05-23
科技创新导报(2016年27期)2017-03-14
筑路机械与施工机械化(2016年6期)2016-07-16
